Model-Based Learning of Near-Optimal Finite-Window Policies in POMDPs
Abstract: We study model-based learning of finite-window policies in tabular partially observable Markov decision processes (POMDPs). A common approach to learning under partial observability is to approximate unbounded history dependencies using finite action-observation windows. This induces a finite-state Markov decision process (MDP) over histories, referred to as the superstate MDP. Once a model of this superstate MDP is available, standard MDP algorithms can be used to compute optimal policies, motivating the need for sample-efficient model estimation. Estimating the superstate MDP model is challenging because trajectories are generated by interaction with the original POMDP, creating a mismatch between the sampling process and target model. We propose a model estimation procedure for tabular POMDPs and analyze its sample complexity. Our analysis exploits a connection between filter stability and concentration inequalities for weakly dependent random variables. As a result, we obtain tight sample complexity guarantees for estimating the superstate MDP model from a single trajectory. Combined with value iteration, this yields approximately optimal finite-window policies for the POMDP.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Model-Based Learning of Near-Optimal Finite-Window Policies in POMDPs”
1) What is this paper about?
Imagine playing a game where the real state of the world is partly hidden (like a fog-of-war video game). You only get noisy hints about what’s really going on, and you must choose actions step by step. That’s what a POMDP is: a decision-making problem with hidden states and noisy observations.
The paper studies a practical way to act well in such hidden, noisy worlds by using only the last few steps of experience (a “finite window”) instead of remembering everything forever. It shows how to learn a good decision rule from one long playthrough and proves how much experience you need to be confident your learned strategy is close to the best possible strategy of this type.
2) What questions are the researchers asking?
- Can we learn a good “finite-window” policy (one that looks only at the last m actions and observations) from a single run of experience in a hidden, noisy environment?
- How many time steps do we need to watch and collect to learn a nearly best-possible finite-window policy?
- Can we match the best-known sample-efficiency (roughly proportional to 1/ε² for error ε) that’s known in fully observable problems, even though things are partially hidden?
3) How did they do it? (Methods in simple terms)
Key ideas, with plain-language analogies:
- Hidden world with noisy clues (POMDP):
- You can’t see the true state directly, only hints (observations) that can be wrong.
- You pick actions and get rewards based on what you observe.
- Finite window = “recent memory”:
- Instead of using your entire life history, you only look at the last m pairs of (action, observation). Think of this as a short summary or a “snapshot” of recent events that you carry forward.
- The authors treat each such recent-history snapshot as a “superstate.” This turns the original hidden problem into a new, fully observable “superstate MDP” whose states are these windows.
- The estimation challenge:
- You cannot directly sample transitions of the “superstate MDP,” because the real world still runs under hidden states. So how do you learn how likely one window leads to another?
- The authors’ solution: collect one long trajectory by acting randomly (so you explore widely), and then count how often each window is followed by each next window. These counts give empirical estimates of transition probabilities and rewards for the superstate MDP.
- Why counting works despite dependence:
- Consecutive windows overlap, so the samples aren’t independent. Still, if the world “forgets the distant past” quickly enough, averages over time become reliable.
- This “forgetting” is called filter stability: after each step, your uncertainty about the hidden state depends less and less on old history. The paper shows that under some mild conditions (every transition and observation has at least a small chance), the system does forget the past fast enough.
- Planning once you have a model:
- After estimating the superstate model by counting, they run value iteration (a standard dynamic programming method) on that estimated model to find a near-optimal finite-window policy.
In short: explore with random actions → count window transitions and rewards → build an approximate “superstate MDP” → run value iteration → get a policy that uses the last m steps.
4) What did they find, and why is it important?
Main results (why they matter):
- A single long trajectory is enough:
- You don’t need many separate runs or a simulator that lets you reset to any state. One continuous experience stream works, as long as it’s long enough.
- Near-optimal with the right amount of data:
- To get within ε of the best finite-window policy (plus a small extra error due to using only m-step windows), the required trajectory length grows like 1/ε². This matches the best-known rates for fully observable problems and improves on earlier POMDP methods that needed around 1/ε⁴.
- Clear error breakdown:
- Total error has two parts:
- 1) Estimation/planning error (how well you learned the superstate model and solved it), which can be made as small as you want with enough data and iterations.
- 2) Window error (because you only look at m recent steps), which shrinks exponentially fast as m increases if the system forgets the past quickly (filter stability).
- Solid assumptions, clear guarantees:
- They assume:
- Every hidden state can move to others with at least a small chance (prevents getting “stuck”).
- Every observation is possible in every state with at least a small chance (ensures you can explore all windows).
- Under these, they prove tight sample complexity guarantees (how long the trajectory needs to be to achieve a target accuracy with high probability).
- Practical demonstration:
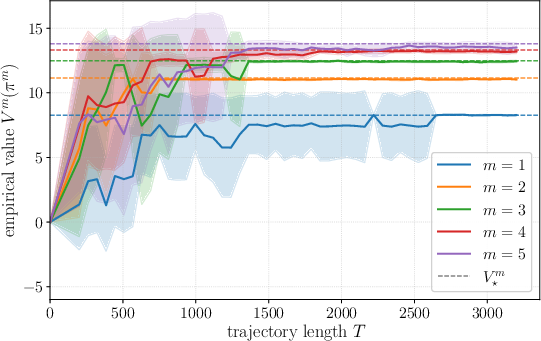
- In a simple test environment (“Probe”), the authors show that as you use more data and increase the window length m, the learned policy’s performance approaches the best possible for that window size.
Why this is important: It narrows the gap between easy-to-learn fully observable problems and the harder partially observable ones—at least for policies that use short memory—by achieving the same desirable 1/ε² scaling for learning time.
5) What’s the impact and why should we care?
- Real-world relevance:
- Many systems (robots with noisy sensors, self-driving cars in fog, assistants with imperfect information) don’t fully observe the true state. Being able to learn good short-memory strategies from one continuous experience is powerful and practical.
- Efficient and principled:
- The approach is simple (count transitions, then plan) and comes with strong theoretical guarantees. It shows that you can get strong learning efficiency even with partial observability, as long as the environment “forgets” the deep past.
- Foundations for future work:
- The paper points to next steps: relaxing the assumptions, scaling to large or continuous spaces with function approximation, and understanding when even better sample or memory bounds can be achieved.
Overall, this work gives a clear, theoretically sound recipe for learning good short-memory strategies in hidden, noisy environments using just one long run of experience—fast, simple, and provably effective.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper makes strong progress on model-based learning of finite-window policies in tabular POMDPs, but it leaves several concrete questions unresolved:
- Assumptions on kernels are strong: the uniform lower bounds on all transition probabilities (Assumption 1) and all observation probabilities (Assumption 2) are restrictive and often unrealistic. Can the results be extended to weaker, more standard mixing conditions (e.g., Doeblin/minorization over multi-step transitions, spectral gaps, Dobrushin coefficients) or to observation models that are only partially supported or only satisfy average-case excitation?
- Filter stability scope: the paper relies on a specific sufficient condition for filter stability (), but does not cover other commonly used stability notions (e.g., contraction in Hilbert metric, observability/controllability-type conditions). Under what broader and verifiable conditions does the finite-window approximation error remain exponentially decaying, and can the constants be improved?
- Parameter regime validity: the stability constant requires for contraction. The paper does not articulate conditions ensuring and how results degrade as . A precise characterization of the admissible parameter ranges and sensitivity of bounds to near-violation would guide applicability.
- Exploration strategy: the analysis assumes a single trajectory generated by uniformly random actions. Can one design more sample-efficient behavior policies (e.g., adaptive exploration, episodic restarts, state-dependent exploration, or optimistic model-directed exploration) that reduce sample complexity while maintaining coverage guarantees?
- Off-policy data and importance weighting: how to extend the estimation and guarantees to non-uniform, possibly deterministic or structured behavior policies using importance sampling or doubly robust corrections, and what is the resulting variance–bias trade-off?
- Single-trajectory dependence: the concentration analysis leverages weak dependence in a single long trajectory; it does not exploit multiple episodes or resets. Would episodic data with resets or multiple shorter trajectories lead to better dependence on mixing parameters (or remove the need for strong uniform positivity)?
- Exponential dependence on window length m: the sample complexity scales as poly(log) times A{2m}O{2m}. Is it possible to obtain polynomial-in-m dependence under filter stability or additional structure (e.g., low-rank dynamics, predictive state representations, PSRs), or to learn only over the support of near-optimal policies to reduce the effective state space?
- Adaptive choice of window size: the method requires fixing m a priori. How can one select m from data to balance approximation error (decaying with m) against estimation and computational costs (growing with m), with statistical guarantees (e.g., structural risk minimization over m)?
- Reward model restriction: rewards are assumed to depend on observations and actions, r(o,a). Many POMDPs have rewards depending on hidden states and actions, r(s,a). How to extend the estimation, analysis, and guarantees to state-dependent (possibly stochastic) rewards observable only via noisy outputs?
- Computational scalability: value iteration over the superstate space of size Θ((AO)m) becomes intractable as m grows. What are the computational complexities and memory requirements, and can one employ approximate planning (e.g., prioritized sweeping, linear function approximation, compressed representations) with provable performance?
- Estimation robustness and zero-count handling: the estimator sets transitions/rewards to zero when a window–action pair is unvisited. Can smoothing, pseudocounts, or confidence sets (e.g., model-based optimism/UCRL-type) improve robustness and finite-sample performance without sacrificing guarantees?
- Confidence-aware planning: the approach plans with point estimates. Would integrating uncertainty (high-probability confidence intervals) into planning (optimism or robust MDPs) yield tighter guarantees, reduce required T, or improve empirical reliability?
- Instance-dependent bounds: the sample complexity is worst-case in the number of windows and actions. Can one derive instance-dependent bounds in terms of occupancy measures under the optimal m-window policy, effective horizon, or transition sparsity to reduce A{2m}O{2m}?
- Unknown discount and horizon variants: the analysis assumes known γ for infinite-horizon discounted problems. How do results extend to average-reward or finite-horizon settings, and can the 1/(1−γ)2 factor be improved (e.g., via span or bias function control)?
- Sensitivity to prior μ: superstate transitions are defined via beliefs computed from μ, yet data-driven estimates implicitly marginalize over actual trajectories. How sensitive is performance to μ, and can one obtain μ-agnostic guarantees or learning that adapts to arbitrary initial beliefs?
- Verification of filter stability from data: the theory assumes stability but offers no method to test or estimate it empirically. Can one design diagnostics or data-driven tests to verify filter stability or to estimate effective contraction rates that guide m selection?
- Extensions beyond tabular: the method is limited to finite S, A, O. How to extend to large/continuous spaces with function approximation while retaining O(ε{-2}) sample dependence and controlling approximation error and stability?
- Structural model learning: the approach estimates the superstate MDP directly. Would learning the underlying POMDP structure (e.g., HMM parameters, PSR features) and then inducing the superstate model reduce data and improve generalization across windows?
- Behavior under assumption violations: if α or β are small or zero for some pairs (near-deterministic transitions or sparse observations), what are graceful degradation guarantees or alternative algorithms that remain consistent?
- Empirical validation breadth: the single simple “Probe” environment does not stress scalability or realism. Evaluations on richer POMDPs (larger S/A/O, varying stability, sparse observations) and comparisons to baseline methods (e.g., TD-based finite-window, PSR-based, model-free) would clarify practical benefits and limitations.
- Tightness of constants: while ε-dependence is O(ε{-2}), constants may be loose due to union bounds and conservative concentration. Can sharper analyses (e.g., localized Rademacher complexities, martingale methods, mixing-time-based bounds) improve dependence on A, O, m, and log factors?
- Online learning and regret: the paper provides PAC-style performance after a batch of random exploration. Can one design online algorithms with sublinear regret and near-optimal steady-state performance under partial observability and finite windows?
Practical Applications
Overview
This paper introduces a model-based method to learn near-optimal finite-window policies in tabular POMDPs by:
- Estimating a finite “superstate” MDP over recent action–observation windows from a single exploratory trajectory.
- Proving tight sample complexity of O(ε⁻²) for model estimation under filter stability, matching fully observable MDP rates up to finite-window approximation error.
- Planning via value iteration on the estimated superstate MDP.
This yields a practical workflow: collect a single, sufficiently long, randomized trajectory; estimate transition/reward models for action–observation n-grams up to window length m; run value iteration; deploy the greedy finite-window policy.
Below are real-world applications derived from these findings, with sector mapping, potential tools/workflows, and feasibility caveats.
Immediate Applications
These can be deployed now when environments can be discretized (tabular), allow safe randomized exploration (or randomized logs exist), and approximately satisfy mixing/noise conditions.
- Robotics and Autonomous Systems (industry; software/robotics)
- Use case: Commissioning/“calibration” phase for robots operating in small, structured, partially observed spaces (e.g., warehouse mobile robots, indoor service robots, AGVs). Run a short randomized policy to collect action–observation sequences, then compute an m-window policy for normal operation.
- Tools/workflows:
- “Superstate MDP estimator” that counts action–observation n-grams and constructs transition/reward tables.
- Value-iteration module to compute m-window policies.
- Window-length tuner that trades off (1−ρ)m approximation error vs. data needs and compute ((AO)m).
- Assumptions/dependencies: Discrete state/action/observation alphabets (or reliable discretization); ability to randomize actions safely during commissioning; sufficiently mixing dynamics and observation support (uniform lower bounds α, β); stationarity during data collection.
- Industrial Automation and Process Control (industry; manufacturing)
- Use case: Learning finite-window controllers for partially observed machine/process states during factory acceptance testing or maintenance windows where action randomization is feasible.
- Tools/workflows:
- Data logging of action–sensor sequences during controlled tests.
- Offline estimation of superstate dynamics; deployment of m-window policy to PLC/edge controllers.
- Assumptions/dependencies: Controlled environment allowing randomized interventions; sensor channels that provide nonzero probability for all observations; tabular abstraction of sensor streams.
- Network Operations and Cloud Systems (industry; networking/software)
- Use case: Policy learning for congestion control or cache management with partial observability by using active probing (akin to “probe” actions in paper’s simulation) and randomized A/B traffic shaping during off-peak periods.
- Tools/workflows:
- Probing action design to ensure observation richness.
- N-gram estimator on action/observation logs; scheduled re-estimation.
- Assumptions/dependencies: Ability to inject randomized actions without violating SLAs; stationarity over the data collection horizon; discretized metrics/actions.
- Software Testing and Interactive Systems (industry; software/QA)
- Use case: Learning test or remediation policies where the true internal state is hidden but observations (logs/UI responses) are available. Randomized test action sequences during CI can provide data to estimate finite-window policies for fault isolation or recovery.
- Tools/workflows:
- CI plugin that randomizes test actions within guardrails and logs observations.
- Offline superstate estimator + policy synthesis for automated remediation steps.
- Assumptions/dependencies: Safe randomized testing; meaningful discretization of observations; repeatable/stationary behavior over logging periods.
- Smart Home and Consumer Robotics (daily life; robotics/IoT)
- Use case: “Calibration mode” for devices like robot vacuums or thermostats with noisy sensors. A brief randomized action routine during setup gathers data to learn a finite-window control policy for navigation or comfort control.
- Tools/workflows:
- Setup wizard that runs a short randomized sequence; on-device counting and value iteration if (AO)m is small.
- Assumptions/dependencies: Short exploration acceptable to users; compact discretization; stable dynamics during setup.
- Academic Research and Benchmarking (academia)
- Use case: Baseline algorithm for tabular POMDPs; reproducible study of finite-window performance vs. m and exploration length.
- Tools/workflows:
- Open-source library implementing the superstate MDP estimator with value iteration.
- Benchmark suites where filter stability (or surrogates) is controllable.
- Assumptions/dependencies: Availability of simulators/logs; interest in provable sample efficiency in tabular settings.
- Experiment Design and Data Collection Guidance (policy/industry/academia)
- Use case: Designing randomized exploration protocols in partially observable environments to enable consistent model estimation (e.g., requiring a minimum degree of action randomization and observation richness).
- Tools/workflows:
- Checklists and tooling to validate α, β proxies and to ensure coverage of m-step windows.
- Assumptions/dependencies: Authority to randomize actions; adequate observability and safety constraints.
Long-Term Applications
These require further research, scaling, or adaptation beyond tabular settings and/or relaxing the strong assumptions.
- Healthcare Decision Support via Digital Twins and Safe Offline Learning (industry/policy/academia; healthcare)
- Use case: In silico training of finite-window decision policies for treatment or triage under partial observability using patient-simulators with randomized trials; deployment after rigorous validation.
- Tools/products:
- POMDP training pipelines integrated with digital twins; counterfactual policy evaluation.
- Dependencies/assumptions: Realistic simulators; ethical and safety constraints precluding randomization on patients; methods to bridge simulation-to-real gaps; continuous/state-rich representations beyond tabular.
- Autonomous Driving and Advanced Robotics in the Wild (industry; robotics)
- Use case: Learning policies for perception–action loops under sensor noise using finite-window approximations, with exploration confined to high-fidelity simulators and then transferred.
- Tools/products:
- Representation learning to induce discrete superstates (vector quantization), windowed policies via deep RL with POMDP-inspired regularizers.
- Dependencies/assumptions: Scalable function approximation replacing tabular superstates; validation of filter stability or alternatives; safe exploration.
- Energy Systems and Smart Grids (industry/policy; energy)
- Use case: Learning finite-window control for grid operations (e.g., storage dispatch) under partial observability, using randomized micro-experiments or natural exogenous variation; deployment during normal operation after testing.
- Tools/workflows:
- “Safe randomization” protocols; offline estimation with drift monitoring; robustification to nonstationarities.
- Dependencies/assumptions: Permission to perturb controls; handling of seasonality and regime changes; discretization or function approximation.
- Finance and Operations Research (industry; finance/logistics)
- Use case: Policy learning for execution or inventory under latent state with partial observability using randomized or historical exploratory logs (e.g., randomized order slices).
- Tools/products:
- Offline superstate estimators with conformal drift detection; risk-aware planning layers.
- Dependencies/assumptions: Regulatory and risk constraints limit randomization; market nonstationarity violates stationarity assumptions; requires robust extensions.
- Education and Personalized Tutoring (industry/academia; education)
- Use case: Learning short-memory tutoring policies from randomized content sequencing to probe student state; improved adaptive strategies with provable sampling efficiency.
- Tools/products:
- Platform features enabling limited randomization; POMDP-based analytics dashboards.
- Dependencies/assumptions: Ethical constraints on randomization; learner populations evolve; requires generalization beyond tabular.
- Scalable Extensions: Continuous Spaces and Function Approximation (academia/industry; software/AI)
- Use case: Replace tabular superstates with learned discrete representations or recurrent models; maintain finite-window structure; extend concentration and filter stability analyses.
- Tools/products:
- Libraries that learn quantized observation embeddings; windowed value iteration or fitted value iteration; uncertainty-aware model estimation.
- Dependencies/assumptions: New theory to justify stability/mixing under function approximation; sample complexity beyond O(ε⁻²) currently unknown.
- Adaptive Experimentation and Regulation for Partial Observability (policy)
- Use case: Crafting guidelines for safe exploration in critical systems to enable learnability (e.g., mandated minimal randomization rates or probing policies during commissioning).
- Tools/workflows:
- Policy templates; auditing tools to assess coverage of m-step windows and estimate filter stability surrogates.
- Dependencies/assumptions: Stakeholder buy-in; codification into standards; balancing safety and learnability.
Cross-Cutting Tools and Workflows That Might Emerge
- Superstate MDP Learning Toolkit:
- Components: n-gram counter over action–observation streams; smoothing/regularization; value iteration/planning; window-length selection; confidence-bound diagnostics.
- Integration: Supports both online commissioning and offline batch learning from logs; drift detection to trigger re-learning.
- Window-Length and Data-Budget Planner:
- Uses the theoretical tradeoff: estimation error O(ε) with O(ε⁻²) samples vs. approximation error decaying as (1−ρ)m, with computational cost ~ (AO)m.
- Suggests m and trajectory length T under constraints (compute, exploration budget).
- Safety-Constrained Exploration Framework:
- Converts uniform random exploration into safe randomized protocols (e.g., randomized among safe actions, or in simulation), while maintaining sufficient coverage of windowed histories.
Key Assumptions and Dependencies Impacting Feasibility
- Tabular representation or reliable discretization of states, actions, and observations; complexity grows exponentially with window length m as (AO)m.
- Ability to collect a (single) long, approximately stationary trajectory with randomized actions (or logs with sufficient randomization).
- Filter stability and regularity:
- Uniform lower bounds α on transition probabilities and β on observation probabilities; practically, this requires mixing dynamics and observation channels that keep all observations possible (or approximations thereof).
- Discounted infinite-horizon setting; value iteration convergence depends on γ and K.
- Domain constraints (safety, ethics, regulation) may restrict randomization; simulators or constrained exploration are often necessary.
- Distribution shift: guarantees assume stationarity; production systems need drift monitoring and periodic re-estimation.
These applications translate the paper’s core innovation—a sample-efficient, model-based finite-window approach to POMDPs—into deployable workflows in settings where partial observability, safe randomized exploration (or simulated exploration), and discrete abstractions are feasible today, and outline a path toward broader, scalable adoption with further research.
Glossary
- Belief: The agent’s posterior distribution over hidden states given a history or window. "we define the belief b(s \mid w) as the probability of reaching state s at the end of w from initial distribution"
- Belief state MDP: An MDP representation whose states are beliefs (distributions over hidden states). "the difference in transition probabilities between the superstate MDP and the belief state MDP "
- Bellman optimality equation: A fixed-point relation characterizing the optimal value or action-value function in an MDP. "which satisfies the Bellman optimality equation for all and :"
- Concentration inequalities: Probabilistic bounds on deviations of random variables (or their functions), used here for dependent sequences. "concentration inequalities for weakly dependent random variables."
- Filter stability: A contraction property whereby belief updates forget initial conditions, making the influence of distant history decay. "Filter stability holds for a POMDP if there exists such that"
- Generative model: An oracle that can sample next observations/rewards given any state-action, used for model-based RL. "does not have access to a generative model or the underlying transition kernel."
- Hidden Markov models: Stochastic models with hidden state processes emitting observations, often used to analyze partial observability. "concentration results for hidden Markov models"
- Linear function approximation: Representing value functions as linear combinations of features for learning and planning. "under linear function approximation."
- Minorization condition: A uniform lower bound of transition probabilities with respect to a reference measure that implies contraction/mixing. "this minorization condition is sufficient for our desired contraction property"
- Probability simplex: The set of all probability distributions over a finite set. "where denotes the probability simplex over~."
- Quasi-polynomial: Growth between polynomial and exponential, e.g., time or sample bounds. "A quasi-polynomial finite-time complexity guarantee for a finite-window approach is established in~\cite{golowich2022learning}"
- Sample complexity: The number of samples required to achieve a desired accuracy or confidence in learning. "and analyze its sample complexity."
- Simulation lemma: A result bounding value differences between two MDPs in terms of model estimation errors. "so-called simulation lemma (see~\cite{kearns2002near}, Lemma~4)"
- Sliding-window approximation: Approximating policies or dynamics using only a fixed-length recent history window. "a tabular POMDP with a sliding-window approximation"
- Superstate MDP: An MDP whose states are finite action–observation history windows constructed from a POMDP. "referred to as the superstate MDP."
- Tabular POMDPs: POMDPs with finite (discrete) state, action, and observation spaces. "We consider tabular infinite-horizon discounted POMDPs"
- Temporal-difference-learning-based policy evaluation: Estimating a policy’s value via TD updates using sampled transitions. "study the finite-time convergence of temporal-difference-learning-based policy evaluation in the superstate MDP under linear function approximation."
- Total variation distance: A metric on probability distributions equal to half the L1 norm of their difference. "their distance in total variation is ."
- Uniformly ergodic: A Markov chain property where convergence to the stationary distribution occurs at a uniform geometric rate. "ensures that, under any policy, the induced Markov chain over hidden states is uniformly ergodic"
- Value iteration: A dynamic programming algorithm that iteratively applies the Bellman optimality operator to compute optimal policies. "Combined with value iteration, this yields approximately optimal finite-window policies for the~POMDP."
- Weakly dependent random variables: Sequences with limited dependence allowing concentration results analogous to the independent case. "weakly dependent random variables."
Collections
Sign up for free to add this paper to one or more collections.