Forecasting Motion in the Wild
Abstract: Visual intelligence requires anticipating the future behavior of agents, yet vision systems lack a general representation for motion and behavior. We propose dense point trajectories as visual tokens for behavior, a structured mid-level representation that disentangles motion from appearance and generalizes across diverse non-rigid agents, such as animals in-the-wild. Building on this abstraction, we design a diffusion transformer that models unordered sets of trajectories and explicitly reasons about occlusion, enabling coherent forecasts of complex motion patterns. To evaluate at scale, we curate 300 hours of unconstrained animal video with robust shot detection and camera-motion compensation. Experiments show that forecasting trajectory tokens achieves category-agnostic, data-efficient prediction, outperforms state-of-the-art baselines, and generalizes to rare species and morphologies, providing a foundation for predictive visual intelligence in the wild.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Forecasting Motion in the Wild”
What is this paper about?
This paper is about teaching computers to predict how animals will move in the next few seconds by watching short clips of them. Instead of trying to predict every pixel in a video (which is very hard), the authors predict the paths of lots of tiny points on the animal’s body. Think of these points like little stickers on the animal’s fur that you follow over time. The paper shows that using these “motion dots” makes prediction more accurate, faster to learn, and works for many different animals—even rare ones.
What questions were the researchers asking?
They wanted to answer a few simple questions:
- Is there a general way to represent motion that works for many kinds of animals, not just humans or one species?
- Can predicting the paths of many small points (instead of pixels or 3D models) make motion forecasting simpler and more accurate?
- Can a model learn from wild, real-world videos (with camera shake, clutter, and rare animals) and still predict believable future motion?
- Does this approach beat other methods at predicting how things will move?
How did they do it?
The researchers used a new representation and a special kind of AI model, and they built a big dataset to train it.
The “motion dots” idea
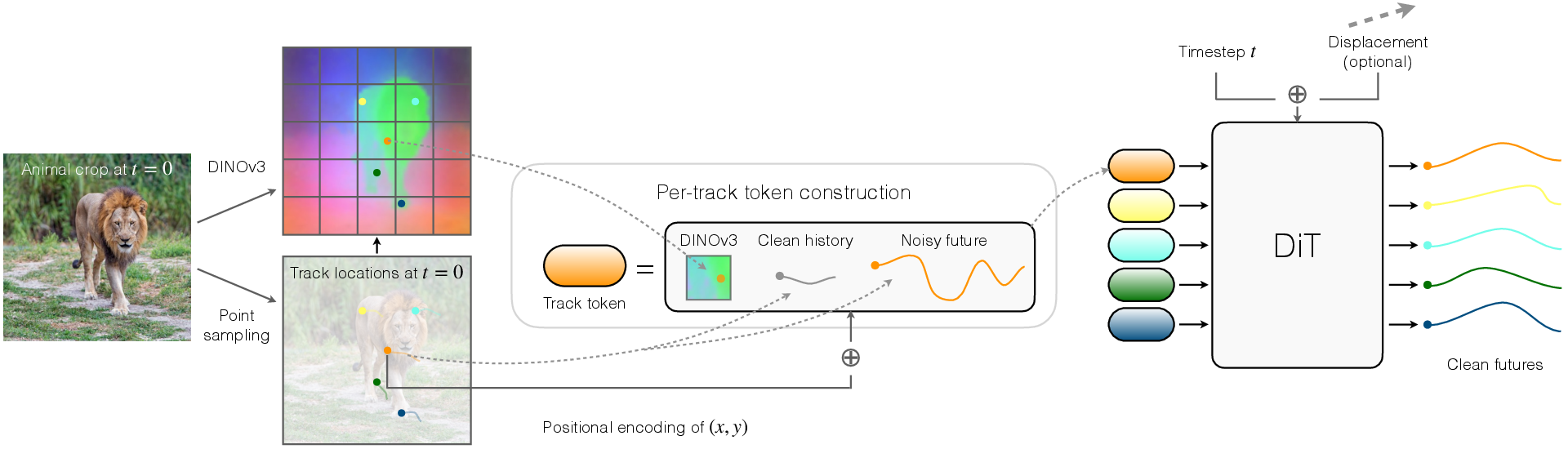
Instead of predicting whole images, the system predicts the future paths of many small points on the animal. Each point has a 2D path across frames (its trajectory). These points act like “visual tokens” for behavior.
Why this helps:
- It focuses on movement itself (not on color, lighting, or background).
- It works for any shape—lions, bears, alpacas—without needing a detailed 3D model for each species.
- It’s more data-efficient than predicting full videos.
The model: a diffusion transformer
- Diffusion: Imagine a blurry, noisy guess of the future paths that the model gradually “cleans up” into a clear prediction. That’s diffusion—start noisy, then denoise step by step.
- Transformer: A transformer is like a team meeting where every point can “pay attention” to other points to decide how to move together (for example, how legs move in sync during a step).
- The model treats each point’s entire path as a token. It also learns when a point is visible or temporarily hidden (occlusion), like when a paw passes behind another leg.
- To make learning easier, the model predicts velocities (how much a point moves between frames), not raw positions. This is like predicting “how it’s moving right now” instead of “exactly where it will be.”
The model can take:
- A single image of the animal at the start
- A short history showing how the animal just moved
- An optional “nudge” arrow that tells the model the overall direction or amount of motion you want (more, less, or in a certain direction)
Building the dataset: MammalMotion
- They collected and processed about 300 hours of animal videos “in the wild.”
- They automatically found animals, tracked many points on them, and stabilized the camera (like digitally holding a shaky camera steady) so the motion reflects the animal, not zooming or panning.
- They focused on diverse species and included rare ones so the model learns many types of movement.
How they checked their work
They compared their method to:
- Simple guesses like “no motion” or “keep moving at the same speed”
- Other track-prediction methods
- Video-generation models that create future frames pixel-by-pixel
They measured how close the predictions were to real motion, how smooth and realistic the motion looked, and how often points landed near the correct places.
What did they find?
- The model predicts animal motion more accurately than other methods on many tests. It especially shines when animals are moving a lot and in complex ways (like walking, turning, or grooming).
- It generalizes to many different species, including rare ones that appear in only a tiny fraction of the data (like polar bears or caribou).
- You can “prompt” it with a motion hint—ask for more motion, less motion, or motion in another direction—and it will adjust its predictions in a believable way.
- It performs better than video models that predict pixels, because those models get distracted by appearance, lighting, and background details. This model focuses purely on motion.
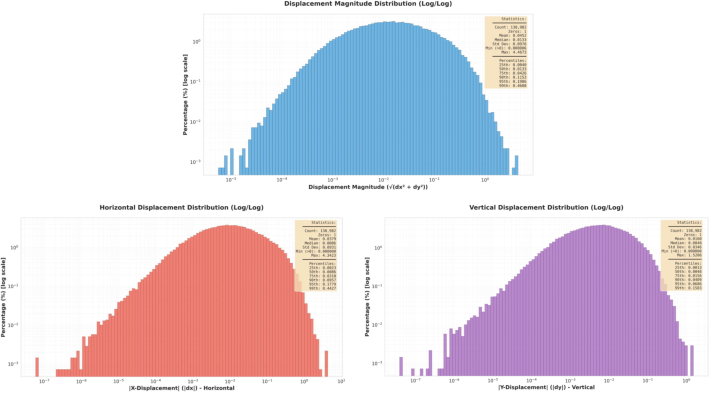
- In studying the dataset, they found a neat real-world pattern: animal movement distances follow a log-normal distribution. In simple terms, most movements are small, but sometimes you see bigger moves; the sizes of these moves, when you take the log, look nicely bell-shaped. This pattern popped out automatically from their large, diverse dataset.
Why is this important?
- It’s a step toward machines that truly understand and anticipate behavior in real-life settings—not just for humans but across the animal world.
- It could help in wildlife research (studying natural behavior at scale without hand-labeling), nature documentaries, and safety systems that need to predict movement.
- For robotics and animation, this approach offers a way to plan or generate realistic motions without needing a detailed 3D model of every creature.
- The idea of “motion dots” as general tokens could become a foundation for broader “predictive visual intelligence”—models that watch, understand, and forecast what happens next in the world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and limitations the paper leaves unresolved, organized by theme to guide future research.
Representation and modeling
- 2D-only motion representation: The method forecasts 2D trajectories in a camera-stabilized image plane, without explicit 3D reasoning. How would incorporating depth, multi-view cues, monocular 3D priors, or layered depth order improve prediction, occlusion handling, and generalization?
- No explicit physical or kinematic constraints: The model does not enforce limb articulation, contact dynamics, or energy/acceleration limits. Can adding structured priors (e.g., articulated templates, learned kinematic constraints, physics-inspired losses) reduce implausible motions?
- Unordered set modeling without topology: Treating tracks as independent tokens ignores body topology/connectivity. Would introducing graph structures (e.g., attention constrained by limb/body part graphs) improve coordinated motion predictions?
- Occlusion as continuous target without dedicated loss: Occlusions are denoised as scaled continuous values and thresholded implicitly. How accurate is occlusion timing, and would discrete objectives or calibration improve visibility prediction?
- Short motion horizons: Experiments predict ~2 seconds (28 steps at 15 FPS). What degrades over longer horizons (e.g., drift, mode collapse) and which architectural changes (hierarchical or multi-scale forecasting) extend temporal coherence?
- Limited conditioning control: A single 2D displacement vector controls global motion. Can richer controls (text prompts, behavior/action labels, pose seeds, trajectory waypoints, scene affordances) enable goal-directed or semantically guided forecasting?
- Denoising target choice and loss: The model predicts clean velocities and occlusions with L1 loss. Do alternative parameterizations (e.g., epsilon-prediction, v-prediction), noise schedules, or mixed losses (e.g., L2, Huber) improve stability and fidelity?
- Token scaling with point count: The computational and quality trade-offs as the number of tracks grows (attention cost, memory) are not characterized. What are optimal token counts and sampling strategies for coverage vs. efficiency?
Data processing and assumptions
- Camera stabilization via homographies: The method assumes small parallax/planarity; failure modes in scenes with strong parallax, zoom, or rolling shutter are not analyzed. How robust is forecasting when stabilization is imperfect?
- Segmentation and tracking noise: The pipeline uses Grounding-DINO, VideoSAM, and BootsTAPIR, but the impact of segmentation/tracking errors on training and inference is not quantified. Can robustness be improved via noise-aware training or data cleanup?
- Single-animal focus: The dataset and model effectively target a single segmented animal. How to handle multi-animal scenes (group behaviors, occlusions, interactions) and identity switches in crowded settings?
- Bias toward thin structures: Point selection prioritizes thin structures; the effect on motion statistics, coverage of core body parts, and stability is not evaluated. What is the optimal sampling policy for anatomical and motion coverage?
- World-coordinate approximation: “World coordinates” are approximated by stabilization and normalization. Would explicit scene geometry (SLAM, factorized background/foreground motion) yield better invariances and motion realism?
Dataset and statistics
- Dataset coverage and bias: MammalMotion is derived from MammalNet and filtered; the species/behavior distribution, long-tail coverage, and recording biases (e.g., human-centric filming) are not fully quantified. Provide per-species/behavior breakdowns and analyze imbalance effects.
- Generalization to non-mammals/humans: OOD behavior is shown qualitatively for a few examples (e.g., butterfly, robot) without quantitative evaluation. How well does the model generalize across phyla and artificial agents?
- Validation of log-normal motion distribution: The log-normal fit for displacement is suggested but not rigorously tested across species, behaviors, and motion scales. Are there species/behavior-specific deviations or multimodal patterns?
- Train/val/test leakage risks: Shot detection and web video sources may produce near-duplicates; safeguards against cross-split leakage and their effectiveness are not reported.
Evaluation and analysis
- Limited biological plausibility metrics: Metrics focus on displacement errors and motion statistics (velocity/acceleration, FVMD). Add assessments of gait cycles, inter-limb coordination, contact events, and biomechanical plausibility.
- No occlusion evaluation: Occlusion prediction accuracy (onset/offset, duration, false positives/negatives) is not measured. Introduce explicit visibility metrics and ablations.
- Diversity vs. fidelity trade-off: Best-of-K metrics and FD/FVMD partially assess distributions, but mode coverage, calibration, and sample diversity are not deeply analyzed. Use coverage/precision metrics and diversity measures across seeds.
- Fairness and scope of baselines: Some baselines are zero-shot or trained on subsets. A standardized, compute-matched comparison (architectures, training budgets, data) and ablations (e.g., absolute vs. velocity diffusion, positional encodings) would clarify gains.
- Failure-case analysis: The paper lacks systematic error/failure cases (e.g., limb sliding, self-intersection, background-following due to poor stabilization). Provide a taxonomy of errors and conditions triggering them.
Control, semantics, and downstream utility
- From motion tokens to behavior semantics: The approach claims potential for computational ethology but does not demonstrate behavior discovery or labeling (e.g., walking, grooming, foraging) from predicted tracks. Can unsupervised clustering on trajectories recover ethograms?
- Goal-conditioned forecasting: Beyond the displacement vector, can the model plan toward targets (e.g., food source) or avoid obstacles? Explore integration with scene affordances, targets, and multi-step goals.
- Text or multimodal conditioning: No text or audio conditioning is explored. Can multimodal prompts generate specific behaviors (“sit,” “pounce,” “graze”) consistently and controllably?
Robustness, scalability, and efficiency
- Real-time inference and resource profile: The method uses ~100 DDIM steps; runtime and memory requirements (as a function of track count and image size) are not reported. What accelerations (e.g., distillation) maintain quality?
- Sensitivity to frame rate and resolution: The model is trained/evaluated at fixed FPS and resized crops. How does performance vary with FPS changes, motion blur, or low-light/night-vision footage?
- Transfer learning and scaling laws: The paper hints that training on diverse species helps Panthera performance, but scaling trends (data size, species diversity, curriculum) and negative transfer risks are not explored.
Reproducibility and release
- Reproducibility details: Full training hyperparameters, point sampling policies, and stabilization thresholds are partially referenced to the supplement; reproducibility would benefit from code release for processing, training, and evaluation.
- Licensing and provenance: Dataset licensing constraints, video provenance, and redistribution policies are not detailed; clarify legal/ethical considerations for large-scale releases.
These gaps suggest concrete next steps: incorporate 3D/structure-aware priors; develop stronger occlusion, biology-informed, and diversity metrics; expand conditioning interfaces; rigorously evaluate robustness and generalization; and deepen dataset documentation and reproducibility.
Practical Applications
Immediate Applications
The following use cases can be deployed now with reasonable engineering effort, leveraging the paper’s trajectory-token representation, diffusion transformer forecaster, and the MammalMotion dataset and processing pipeline.
- Wildlife monitoring and conservation
- Sector: Healthcare/Conservation/Ecology; Public sector/NGOs
- What: Use trajectory forecasting to anticipate animal motion in camera-trap or drone footage for proactive camera control (e.g., auto-panning/zooming), event triage (flag likely high-motion or rare-behavior segments), and anti-poaching patrol cueing.
- Tools/products/workflows:
- “Trajectory Forecasting Service” that ingests a first frame + short motion history from camera traps and outputs predicted tracks + occlusions.
- Dashboard visualizing displacement histograms, predicted paths, and confidence; alerting when high-motion or pursuit-like patterns occur.
- Pipeline bundling BootsTAPIR + Grounding-DINO + VideoSAM + stabilization + forecaster (as described in the paper).
- Assumptions/dependencies:
- Camera motion must be stabilizable with low parallax; tracking must be reliable (good lighting, contrast).
- Model trained largely on mammals; OOD generalization to other taxa is promising but partial.
- Latency acceptable for near-real-time if DDIM steps are reduced and accelerated on GPU/edge.
- Livestock and animal-welfare monitoring
- Sector: Agriculture/AgTech
- What: Detect anomalies (e.g., lameness, restlessness, separation) by comparing predicted vs. observed trajectories in barns/pastures; anticipate herd flow at gates/feeding stations.
- Tools/products/workflows:
- Barn cameras feed a forecaster that flags deviations (residuals between predicted and actual tracks); integration into farm dashboards.
- Simple rule-based alerting on motion magnitude distributions (log-normal priors can inform healthy vs. abnormal ranges).
- Assumptions/dependencies:
- Requires adaptation to specific barn environments (occlusions, crowding).
- 2D projections may be insufficient for 3D behaviors (jumping, piling) without multi-view or depth.
- Academic computational ethology at scale
- Sector: Academia/Research
- What: Data-efficient, category-agnostic motion descriptors for behavior discovery, cross-species comparison, and hypothesis testing (e.g., validating/discovering displacement distributions like the reported log-normal fit).
- Tools/products/workflows:
- Use MammalMotion dataset and the open pipeline to compute trajectory tokens, distributional metrics (FD on velocity/acceleration), and cluster behaviors without manual labels.
- Assumptions/dependencies:
- Relies on high-quality tracks; manual verification still needed for novel behavior discovery.
- World-coordinate interpretation is approximate without 3D reconstruction.
- Video editing and VFX previsualization
- Sector: Media/Software
- What: “Motion preview” overlays that translate image patches along predicted trajectories (no pixel generation) to quickly preview plausible futures; assist rotoscoping and motion-guided edits.
- Tools/products/workflows:
- NLE/Compositor plugin (e.g., After Effects, DaVinci Resolve) that forecasts trajectories from a still + short clip and lets artists adjust “motion prompting” (via the optional displacement conditioning).
- Assumptions/dependencies:
- Works best with visible subjects and stabilizable shots; complex camera moves need additional tracking or 3D.
- AR/VR tracking stabilization and frame extrapolation
- Sector: Software/AR/VR
- What: Use occlusion-aware trajectory forecasts to bridge dropped frames, reduce latency, and stabilize tracked animal/human features in live experiences or educational apps.
- Tools/products/workflows:
- SDK integrating the forecaster as a low-latency predictor on tracked points for short-term extrapolation.
- Assumptions/dependencies:
- Edge compute constraints; prune diffusion steps and/or distill model for mobile; requires robust initial tracks.
- Motion-based video retrieval and indexing
- Sector: Software/Search
- What: Index footage by learned motion patterns (e.g., grazing, pouncing-like acceleration signatures) using trajectory-token statistics and FVMD-like descriptors.
- Tools/products/workflows:
- Search engine that extracts trajectory embeddings per clip and supports motion-pattern queries or similarity search.
- Assumptions/dependencies:
- Mapping from low-level trajectories to semantic labels requires additional weak supervision or user-defined templates.
- Robotics situational awareness in homes and labs
- Sector: Robotics
- What: Predict short-horizon motion of pets/humans (non-rigid parts) to reduce collisions and improve social navigation around animals.
- Tools/products/workflows:
- ROS node that converts short motion histories into predicted occupancy/trajectories for local planners.
- Assumptions/dependencies:
- Real-time constraints; 2D forecasts should be fused with depth for safe planning; limited by training domain (mainly mammals) and indoor clutter.
- Education and public outreach
- Sector: Education/Museums
- What: Interactive exhibits/apps showing predicted future motion from a single frame and short history, illustrating principles of animal behavior and motion.
- Tools/products/workflows:
- Web demos using the released dataset + forecaster to visualize and compare species’ motion patterns.
- Assumptions/dependencies:
- Ethical curation of content; simplified UI and hardware acceleration for smooth demos.
Long-Term Applications
These use cases require further research, scaling, integration with additional sensors or systems, or significant engineering for reliability, safety, or regulatory approval.
- Animal-aware ADAS and autonomous driving
- Sector: Automotive/Transportation
- What: Predict roadside animal motion (deer, elk, livestock) to reduce collisions; fuse trajectory tokens with LiDAR/Radar for robust anticipatory braking and path planning.
- Tools/products/workflows:
- Perception stack module that outputs multi-modal forecasts and uncertainty for animals; integrated with planner costmaps.
- Assumptions/dependencies:
- Requires domain-specific training (roadside scenes, night, weather), 3D localization, and rigorous safety validation.
- General-purpose predictive perception for embodied AI
- Sector: Robotics/Consumer Electronics
- What: Robots that anticipate non-rigid motion of humans, pets, and deformable objects to plan better interactions (handoffs, social cues, clothes/rope handling).
- Tools/products/workflows:
- Combined 2D trajectory tokens + learned 3D priors for deformables; policy learning atop forecasted motion distributions.
- Assumptions/dependencies:
- Needs 3D-aware extensions, real-time performance, and robust occlusion handling in crowded settings.
- Wildlife corridor planning and environmental policy
- Sector: Policy/Urban Planning/Conservation
- What: Use large-scale motion forecasts from distributed camera networks to infer flow patterns, informing placement of wildlife crossings, fences, and protected areas.
- Tools/products/workflows:
- Spatially aggregated trajectory statistics (e.g., displacement, directionality) calibrated to geo-referenced coordinates; scenario simulations (pre/post infrastructure).
- Assumptions/dependencies:
- Requires mapping 2D stabilized tracks to geography, long-term multi-camera identities, and integration with ecological models; governance for data sharing and ethics.
- Codec and streaming innovations using trajectory tokens
- Sector: Software/Media/Telecom
- What: Motion-as-tokens video coding where initial frames + predicted trajectories + patch warping substitute for full pixel streams in low-motion scenes; hybrid with residuals for occlusions/new content.
- Tools/products/workflows:
- Prototype codec integrating tokenized motion layers and occlusion maps; encoder/decoder standardization efforts.
- Assumptions/dependencies:
- Research needed on bitrate/quality trade-offs, occlusion synthesis, standards compliance, and failure modes.
- Cinematography/drone autopilots with anticipatory control
- Sector: Media/Drones
- What: Gimbal/drone controllers that preemptively reframe based on forecasted subject movement (animals, athletes), improving shot stability without manual intervention.
- Tools/products/workflows:
- Onboard inference + real-time stabilization and trajectory-to-camera-control mapping.
- Assumptions/dependencies:
- Low-latency predictive control and safety; handling fast parallax, 3D motion, and severe occlusions.
- Clinical gait and movement prognosis
- Sector: Healthcare
- What: Forecast patient motion patterns (gait cycles, tremors) from short histories to assist diagnosis or rehab planning; compare predicted vs. observed deviations over time.
- Tools/products/workflows:
- Clinically validated, human-adapted models; integration with pose-estimation pipelines in hospital settings.
- Assumptions/dependencies:
- Requires human-specific datasets, regulatory approval, and domain shift mitigation; privacy safeguards.
- Controllable video generation guided by motion prompts
- Sector: Media/Creative Tools
- What: Combine trajectory-token forecasts (with displacement “prompts”) with video diffusion to produce controllable, physically reasonable animal/human motion in generated clips.
- Tools/products/workflows:
- “Motion-guided video generator” where users specify motion vectors or patterns and the system enforces them during synthesis.
- Assumptions/dependencies:
- Tight integration between trajectory predictors and pixel generators; addressing hallucinations and appearance-motion disentanglement.
- Public safety and crowd forecasting (with strong safeguards)
- Sector: Public Safety/Smart Cities
- What: Predict short-horizon non-rigid human motion (gestures, crowd flow) for proactive crowd management and hazard detection.
- Tools/products/workflows:
- Privacy-preserving, aggregate motion analytics using trajectory statistics rather than identity.
- Assumptions/dependencies:
- Ethical and legal frameworks, bias audits, and transparency; robust performance in dense crowds and complex camera setups.
- Cross-ecosystem behavior modeling and climate impact studies
- Sector: Academia/Policy
- What: Model how motion/behavior distributions shift with seasons, climate stressors, or habitat change by continuously monitoring trajectories across regions and years.
- Tools/products/workflows:
- Longitudinal datasets; standardized pipelines for motion statistics (e.g., FD on velocities/accelerations, FVMD).
- Assumptions/dependencies:
- Requires sustained data collection, harmonization across sites, and ecological ground truth for attribution.
Notes on feasibility across applications:
- The core contributions—trajectory tokens, occlusion-aware diffusion transformer, and scalable in-the-wild pipeline—enable data-efficient, category-agnostic motion forecasting, but many applications demand:
- Stronger 3D reasoning than the paper’s 2D, homography-stabilized setup (especially with parallax, elevation changes).
- Real-time inference and model distillation for edge devices.
- Domain-specific retraining (humans, sports, roadside animals, indoor pets).
- Sensor fusion (depth/LiDAR/Radar) for safety-critical contexts.
- Ethical safeguards and governance for surveillance-adjacent uses.
Glossary
- ADE (Average Displacement Error): A trajectory accuracy metric measuring mean distance between predicted and ground-truth points over time. "Average Displacement Error (ADE)"
- AdaLN (Adaptive Layer Normalization): A conditioning mechanism that modulates layer normalization with learned embeddings to inject conditioning signals. "through AdaLN"
- Any Trajectory Modeling (ATM): A regression-based baseline that treats each point track as a token to predict future coordinates. "Any Trajectory Modeling (ATM)."
- bilinear interpolation: A method to sample image features at non-integer locations using weighted averages of neighboring pixels. "using bilinear interpolation."
- biological motion: The perception of movement patterns (often from sparse points) revealing structure and intent in living agents. "biological motion studies"
- BootsTAPIR: A state-of-the-art point tracking method used to extract dense tracks from videos. "with BootsTAPIR"
- camera stabilization: Removing camera motion (e.g., panning/zooming) to approximate motion in a consistent world frame. "camera stabilization"
- conditional generative distribution: A probability model that generates future trajectories conditioned on observed history and inputs. "conditional generative distribution"
- DDIM sampling algorithm: A deterministic sampling procedure for diffusion models allowing fewer inference steps. "DDIM sampling algorithm"
- DDPM: Denoising Diffusion Probabilistic Models; a framework for generative modeling via iterative noising and denoising. "Following DDPM"
- DINOv3: A self-supervised vision transformer producing image features used as per-point visual context. "DINOv3"
- DiT (Diffusion Transformer): A transformer architecture adapted for diffusion models to predict denoised targets. "DiT-based architecture"
- diffusion process: The forward–reverse noising framework modeling complex data distributions through denoising steps. "a diffusion process."
- FDE (Final Displacement Error): A trajectory metric measuring endpoint distance at the final timestep. "Final Displacement Error (FDE)"
- Fréchet distance (FD): A distribution-level metric comparing two multivariate Gaussian approximations of data. "Fréchet distance"
- Fréchet Video Motion Distance (FVMD): A metric comparing distributions of motion features to assess temporal coherence. "Fréchet Video Motion Distance (FVMD)"
- forward diffusion process: The noise-adding procedure that progressively corrupts data in diffusion models. "forward diffusion process"
- Grounding-DINO: An open-vocabulary detection model used to obtain initial animal segments. "Grounding-DINO"
- homography: A planar projective transformation used to align frames for camera-motion compensation. "homography"
- latent diffusion models: Diffusion models operating in a compressed latent space rather than directly on raw inputs. "latent diffusion models"
- log normal distribution: A distribution where the logarithm of the variable is normally distributed; observed in animal displacements. "log normal distribution"
- multivariate Gaussian distributions: Joint Gaussian models used to approximate sets of features for distributional comparison. "multivariate Gaussian distributions"
- non-Markovian forward process: A process where the next state depends on more than the immediate previous state (as in DDIM). "non-Markovian forward process"
- non-rigid agents: Entities whose shape deforms over time (e.g., animals), requiring flexible motion representations. "non-rigid agents"
- occlusion indicator: A binary variable denoting whether a tracked point is visible or hidden at a given time. "occlusion indicator"
- Oracle Velocity Baseline: A baseline that uses ground-truth average velocity to extrapolate future positions. "Oracle Velocity Baseline."
- parallax: Apparent motion differences of objects at varying depths due to camera viewpoint changes. "parallax"
- permutation invariance: A model property where outputs are unchanged by reordering input tokens. "permutation invariance"
- position encoding: An additive embedding that injects spatial location information into token representations. "position encoding"
- Points Within Threshold (PWT): The fraction of predicted points within specified pixel distances of the ground truth. "Points Within Threshold (PWT)."
- RANSAC: A robust estimation method used to fit models (e.g., homographies) while rejecting outliers. "RANSAC"
- sinusoidal embedding: An encoding that maps continuous values (e.g., velocities) into sinusoidal feature representations. "sinusoidal embedding"
- Stable Video Diffusion: A video-generation diffusion model used for qualitative comparison. "Stable Video Diffusion"
- stratified sampling: Sampling that ensures balanced representation across predefined categories (e.g., species × behaviors). "stratified sampling"
- Track2Act: A diffusion-based point-track forecasting model from robotics, used here as a learned baseline. "Track2Act"
- Video Motion Distance (VMD): An example-level metric measuring the Euclidean distance between motion feature vectors. "Video Motion Distance (VMD)."
- VideoSAM: A video segmentation model used to track animal masks across frames. "VideoSAM"
- visual tokens: Discrete or structured units used to represent behavior/motion for modeling and prediction. "visual tokens for behavior"
- WHN (What Happens Next): A general-purpose point-track forecasting baseline evaluated zero-shot. "What Happens Next (WHN)."
- world coordinates: A camera-independent coordinate frame aligned with the scene, simplifying motion prediction. "world coordinates"
Collections
Sign up for free to add this paper to one or more collections.

