- The paper introduces a novel stochastic attention mechanism that exponentially expands receptive fields using random token permutations applied to sliding-window attention.
- It presents a gated SA+SWA architecture that integrates global context and local coherence, achieving efficient linear-time performance with minimal computational overhead.
- Empirical evaluations demonstrate enhanced accuracy and speed in long-context tasks, making the approach a promising upgrade for large-scale Transformer models.
Stochastic Attention: Connectome-Inspired Randomized Routing for Expressive Linear-Time Attention
Motivation and Biological Inspiration
The paper addresses the problem of efficient information routing in Transformer models, focusing on augmenting sliding-window attention (SWA) mechanisms. SWA restricts each token’s receptive field to a local neighborhood, which is an architectural bottleneck for tasks requiring global context or long-range dependency integration. The authors ground their proposal in connectomics, referencing the Drosophila melanogaster brain connectome: a sparse yet highly efficient biological network with over 130,000 neurons and an average shortest path length of 4.4, achieved via broadly distributed stochastic long-range shortcut connections between brain regions. The fruit fly's connectome demonstrates that sparse, random global shortcuts layered atop strong local structure enable robust, scalable global communication.
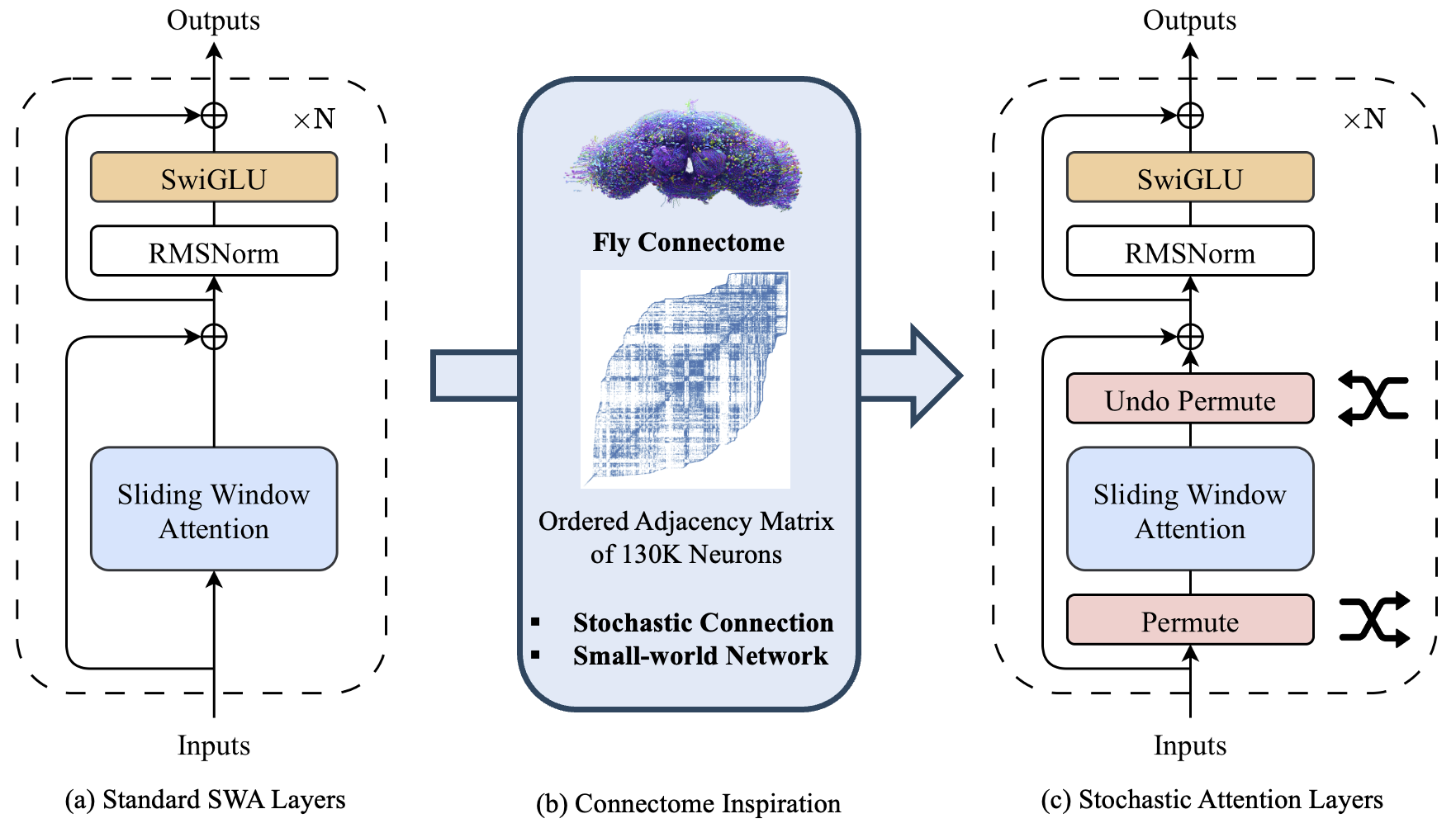
Figure 1: SA layer architecture; illustrates stochastic permutation prior to windowed attention, producing shortcut connections analogous to the fruit fly connectome.
Methodology
Stochastic Attention (SA)
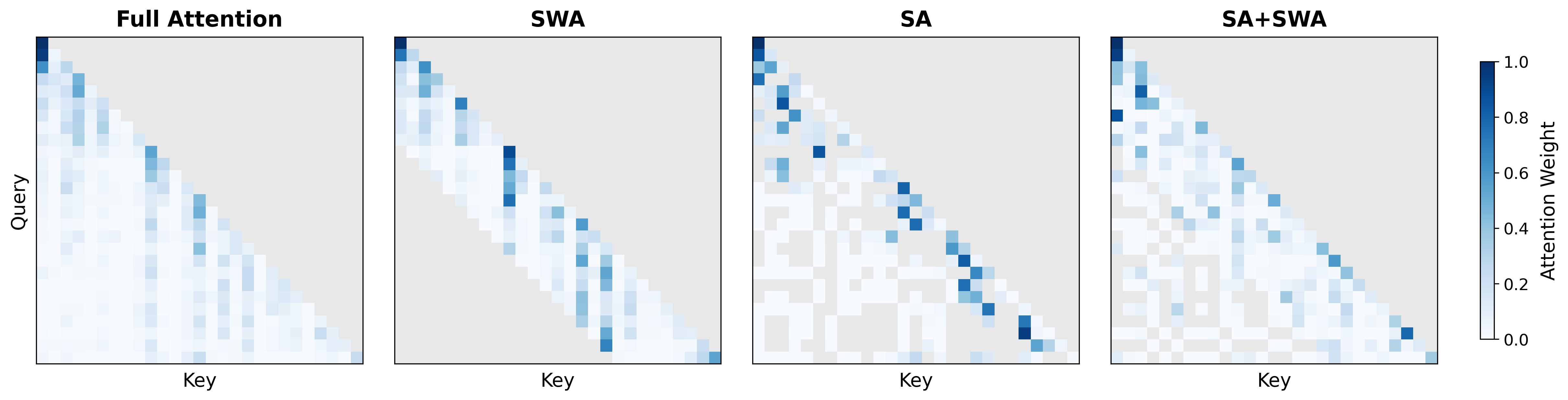
Stochastic Attention transforms the fixed local window of SWA into a stochastic global window, implemented by applying a random permutation to the token sequence before windowed attention and then restoring the original order afterward. In each layer, the permutation is resampled, leading to exponential expansion of receptive fields across depth. If the window size is w and sequence length n, SA achieves full coverage in O(logwn) layers, as opposed to the O(n/w) depth required by standard SWA. Notably, the mechanism introduces no learnable parameters in the attention, only O(n) index-permutation overhead.
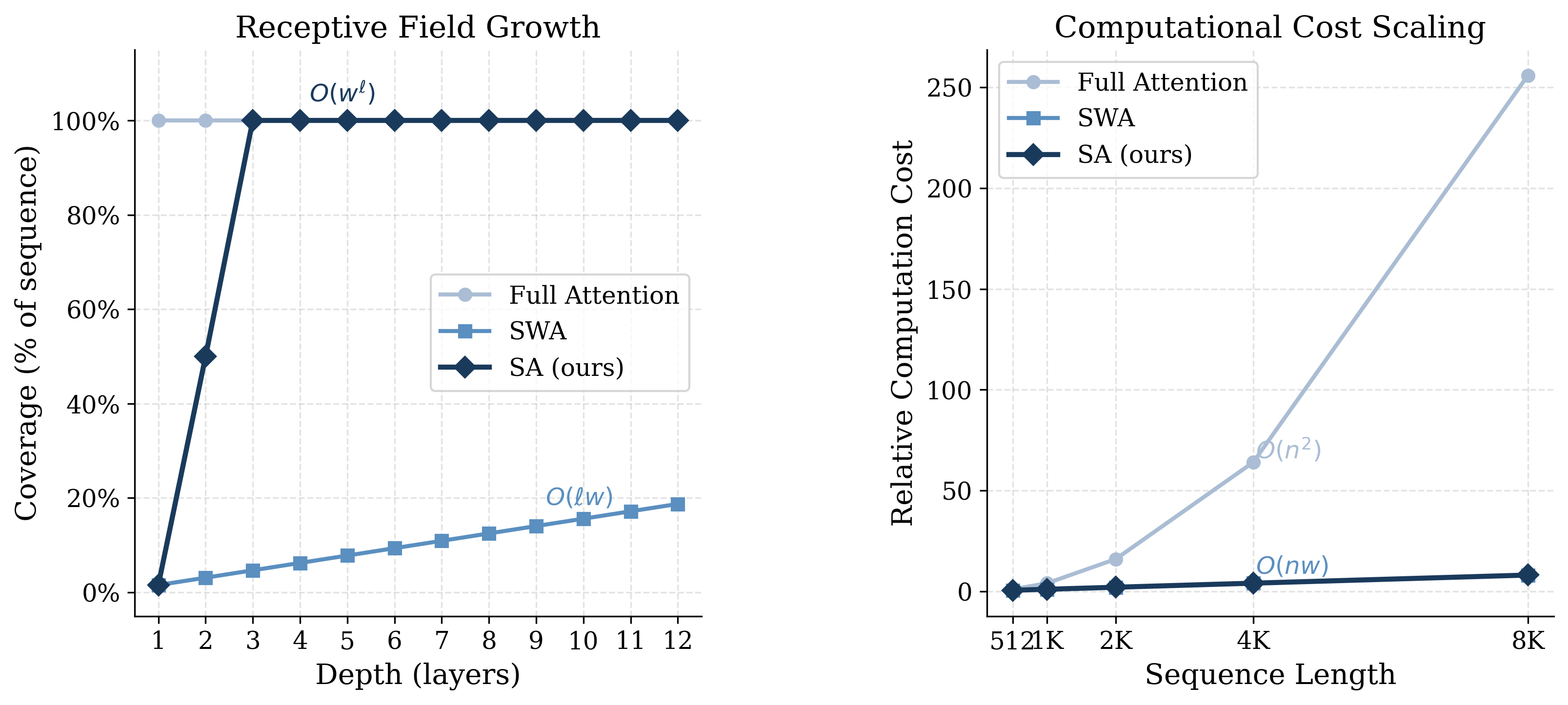
Figure 2: Exponential receptive field coverage with SA versus linear growth in SWA; both maintain linear compute complexity, but SA delivers more rapid global mixing.
SA + SWA Gated Combination
To maintain the complementary strengths of local coherence (SWA) and global coverage (SA), the authors propose a gated architecture where outputs from both mechanisms are fused via learned sigmoid gates. This dual-path architecture preserves clustering while introducing a provable bias-variance trade-off—a gate can up- or down-weight each path per token and dimension, paralleling the connectome’s small-world structure.
Theoretical Analysis
SA is shown to be an unbiased estimator of full attention under uniform weighting, with bias O(1/w) and variance O(B2/w). Layer-wise independent permutations rapidly break SWA’s slow spectral mixing, allowing global information flow to emerge efficiently.
Empirical Evaluation
Pretraining
Models of ∼360M parameters were pretrained on 6B tokens with a 24-layer decoder-only Transformer, comparing Full Attention, SWA, SA, and SA+SWA variants. Zero-shot evaluation across downstream benchmarks (WikiText, LAMBADA, PIQA, HellaSwag, WinoGrande, ARC-Easy) demonstrates:
Training-Free LLM Inference
SA was deployed at inference (no retraining) in Qwen3-8B and Qwen3-30B-A3B models, compared against SWA and MoBA (Mixture of Block Attention) as efficient alternatives. Key findings:
- SA recovers full-attention performance more rapidly as window size increases, consistently outperforming SWA and matching or exceeding MoBA at comparable compute budgets.
- At small windows (w=32), SA drastically improves accuracy on tasks requiring global context (e.g., MMLU, BoolQ) compared to SWA, confirming effective global information flow.
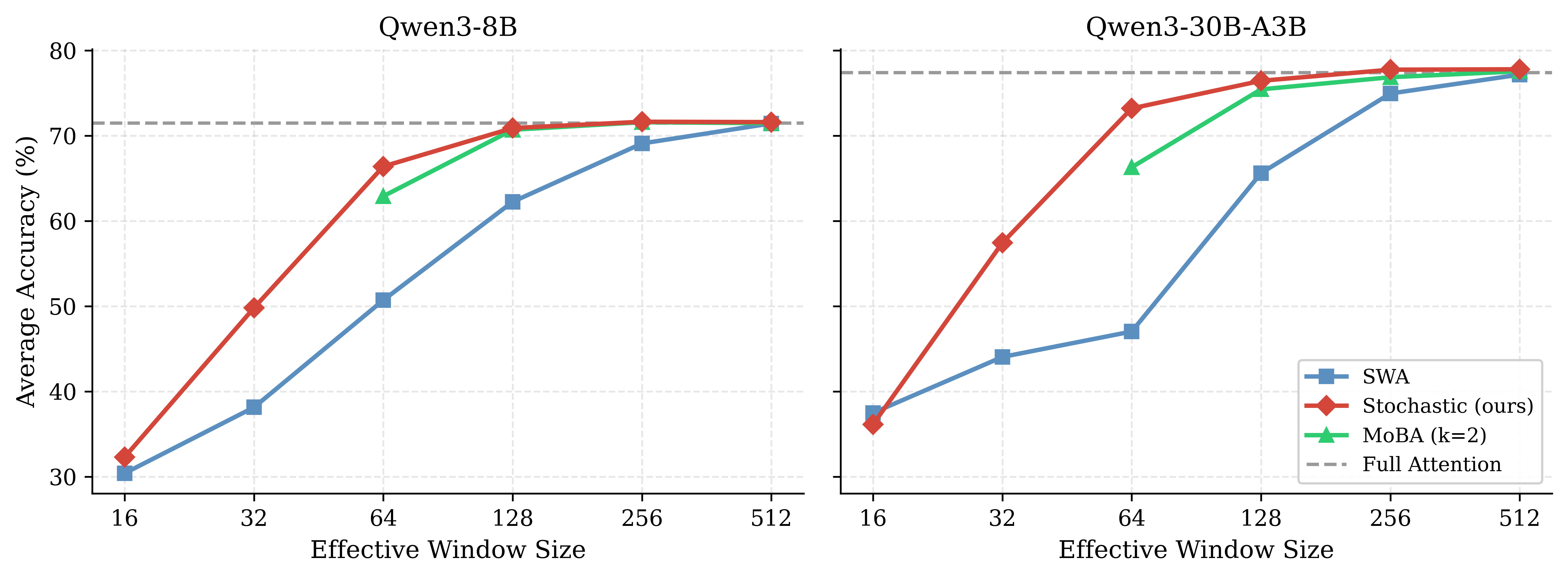
Figure 4: Average accuracy across benchmarks versus window size; SA consistently achieves superior performance under strict compute constraints.
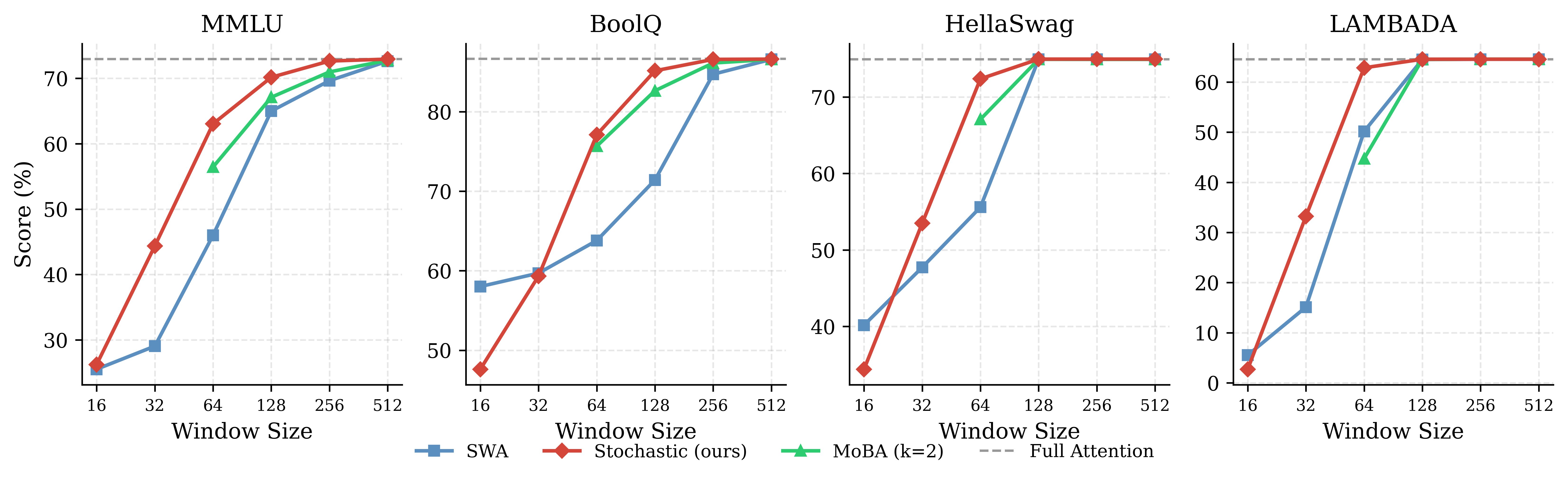
Figure 5: Per-task SA scaling for Qwen3-8B; SA enables rapid convergence to full-attention accuracy on heterogeneous benchmarks.
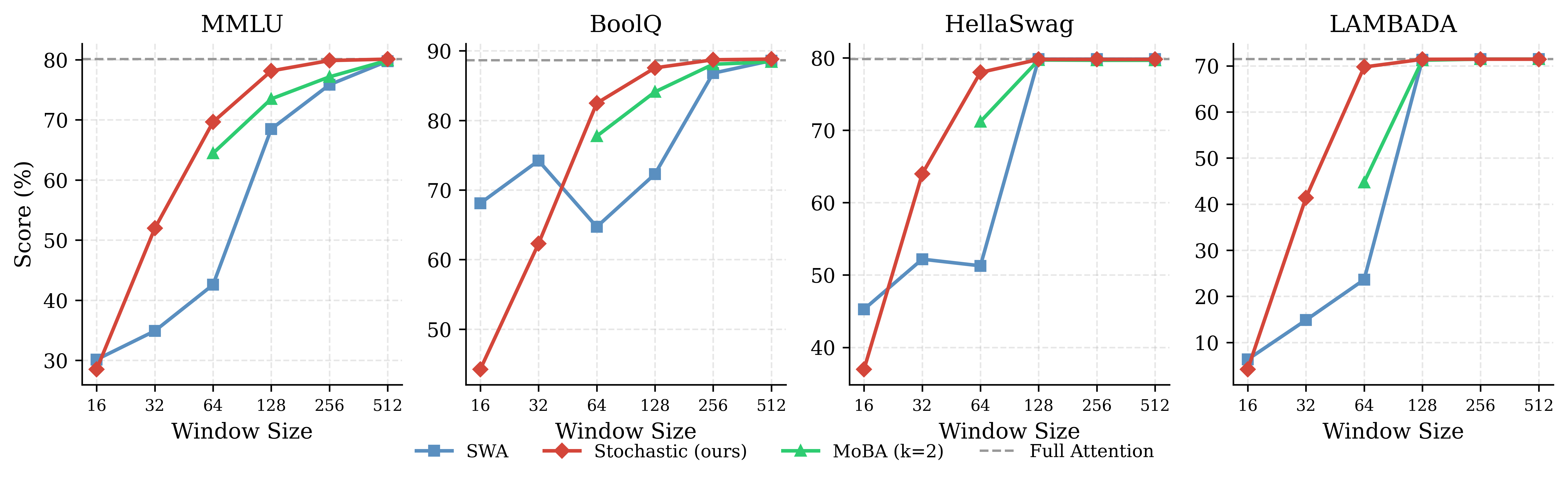
Figure 6: Per-task scaling for Qwen3-30B-A3B; SA outpaces SWA and matches MoBA, demonstrating robustness across model scales.
Efficiency
Benchmarking with compiled FlexAttention demonstrates that SA maintains O(nw) scaling, achieving 28x speedup at sequence length 32K compared to full attention for both forward and backward passes. The dual-path SA+SWA incurs an additional attention layer cost but retains linear scaling and significant speedup at practical window sizes.
Implications, Future Work, and Theoretical Perspective
Stochastic Attention amplifies the expressive capacity of windowed attention mechanisms with negligible architectural complexity, leveraging principles of distributed random shortcut routing as observed in biological neural networks. As windowed attention is thoroughly adopted in production-scale LLMs (e.g., Mistral, Gemma~2), SA provides a direct pathway to upgrading global information flow without retraining or algorithmic overhaul.
Theoretically, SA bridges the gap between full attention long-range expressivity and linear-time efficiency, suggesting that facilitated mixing via random permutation layers can yield near-optimal functional coverage. The bias-variance decomposition, spectral mixing analysis, and connectome analogy open avenues for further exploration in hybrid architectures, adaptive routing, and context-efficient design—possible directions include dynamic or learned permutations, task-specific coupling, and integration with state-space models.
In neuroscience-inspired ML, this work strengthens the case for sparse, distributed shortcut mechanisms as scalable primitives for both global reasoning in language and vision, and for biologically plausible architectures in neuromorphic computing and brain-like AI.
Conclusion
The paper formalizes and empirically validates Stochastic Attention as a biologically inspired, efficient, and highly expressive enhancement to sliding-window attention. The proposed permutation-based stochastic routing achieves exponential receptive field expansion, robust global information flow, and strong empirical performance across both pretraining and inference, with minimal computation overhead. Practical deployment of SA in long-context LLMs and other sequential models is anticipated to deliver significant gains in efficiency, coverage, and adaptability, catalyzing further developments in efficient Transformer architectures (2604.00754).