- The paper introduces an RL framework that autonomously selects between CVODE and QSS solvers, reducing computational cost while enforcing error constraints.
- It leverages a CMDP formulation with a two-layer MLP actor-critic and PPO to achieve mean speedups of 3.13x and up to 10.58x in zero-dimensional simulations.
- The RL policy generalizes zero-shot to 1D PDE simulations, offering a promising method for accuracy-constrained, multiphysics reactive flow simulations.
Reinforcement Learning-Based Adaptive Solver Selection for Stiff Chemical Kinetics
Introduction and Problem Context
The simulation of complex reactive flows, especially in combustion applications, is computationally dominated by the solution of stiff systems of ODEs arising from detailed chemical kinetics. Standard approaches employ robust implicit integrators (e.g., CVODE, based on BDF methods) for stability across regimes of high stiffness, but at considerable computational cost per step. Efficient explicit or quasi-steady-state (QSS) solvers are available but can be unreliable or unstable in highly stiff/gradient-rich regions, resulting in the enduring challenge of how to dynamically select the optimal solver based on local stiffness and accuracy requirements.
Existing adaptive/hybrid approaches in reacting flow simulation predominantly rely on hand-tuned heuristic or supervised rules, which do not adequately address the non-stationary and trajectory-dependent nature of error accumulation and computational cost. They generally lack the capacity to learn long-term trade-offs between solver choice, accuracy, and efficiency across spatiotemporally varying stiffness.
This work presents a formal constrained reinforcement learning (RL) framework for problem-adaptive, autonomous solver selection that optimizes computational efficiency subject to explicit error constraints in detailed chemistry integration.
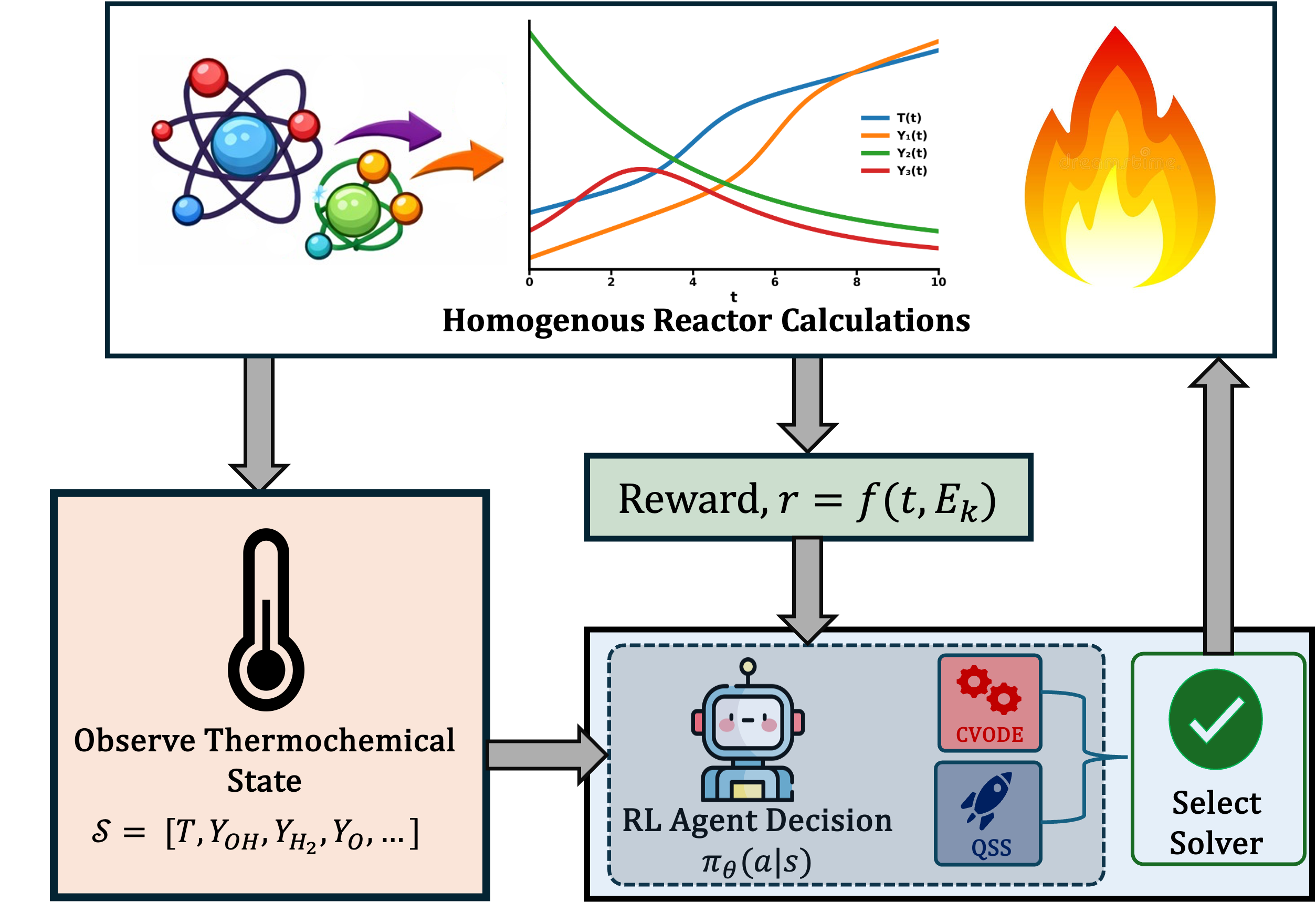
Figure 1: The reinforcement learning-based adaptive solver selection architecture, where the agent observes the evolving thermochemical state and chooses between candidate solvers (CVODE or QSS) at each integration step.
Methodology
The chemistry integration task is framed as a constrained Markov Decision Process (CMDP), where at each time step, the RL agent observes a state vector comprising normalized thermochemical variables (e.g., T, key radical/stable species, local rates of change) and selects one of two actions: implicit integration via CVODE, or explicit QSS-based integration. The agent seeks to minimize cumulative normalized cost, while ensuring that solution error (relative to a high-fidelity reference) does not exceed a prescribed tolerance ϵ on average.
The approach leverages a Lagrangian primal-dual formulation, with the reward defined as the negative sum of normalized computational cost and a constraint violation penalty scaled by a learned dual variable. The dual variable is updated online to enforce the CMDP constraint.
Policy Architecture and Training
A two-layer MLP actor-critic architecture (128 units per layer, orthogonal initialization) provides cheap and near-constant inference overhead regardless of state size. Policy optimization is performed via PPO, collecting rollouts from ensembles of 0D ignition conditions. The policy receives immediate feedback in terms of normalized solver cost and local error violation, facilitating empirical exploration of accuracy-efficiency trade-offs during training.
Results: Zero-Dimensional Reactor Simulations
Efficiency and Accuracy Gains
Evaluation over a comprehensive grid of homogeneous reactors confirms the RL-adaptive policy obtains a mean speedup of 3.13×, with individual cases achieving up to 10.58× acceleration relative to full CVODE integration, while rigorously maintaining solution accuracy (ignition delay error <2.6%, temperature RMSE <110 K). The approach generalizes well across parameter ranges: at low temperatures and pressures, where QSS is typically accurate, the RL policy predominantly selects QSS; at high temperature/pressure, where stiffness is ubiquitous, implicit integration is preferred.
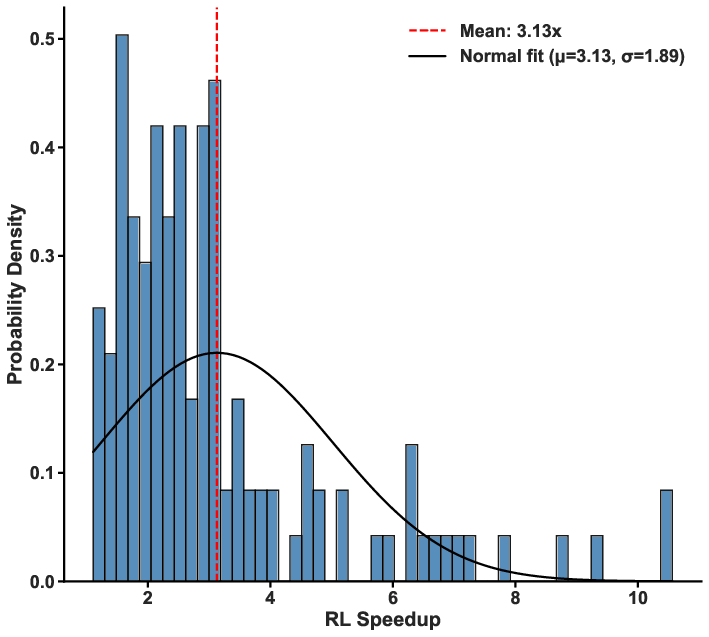
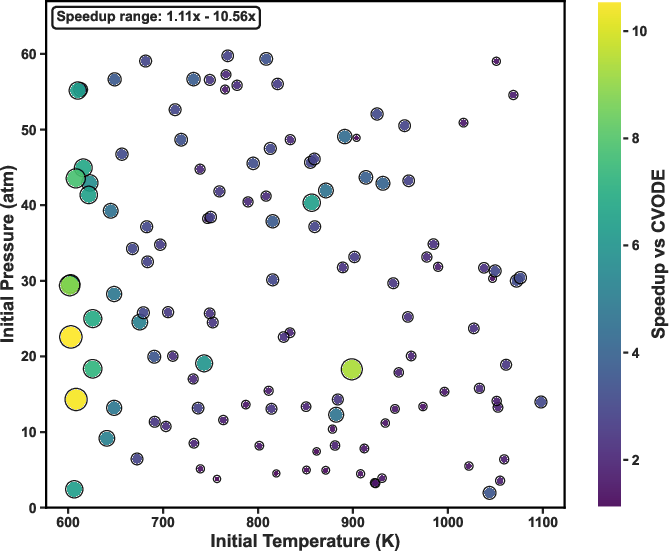
Figure 2: Distribution of computational speedup achieved by the RL policy over a suite of zero-dimensional conditions; red dashed line: mean speedup.
Trajectory-Wise Solver Allocation
Analysis of specific cases reveals that the RL agent applies CVODE selectively within critical ignition transients, minimizing its usage elsewhere. For a representative low-temperature, low-pressure case (650K, 1.0 atm), only 5.4% of steps are integrated with CVODE, yet overall ignition delay and temperature profiles remain within ≲0.5% of reference.
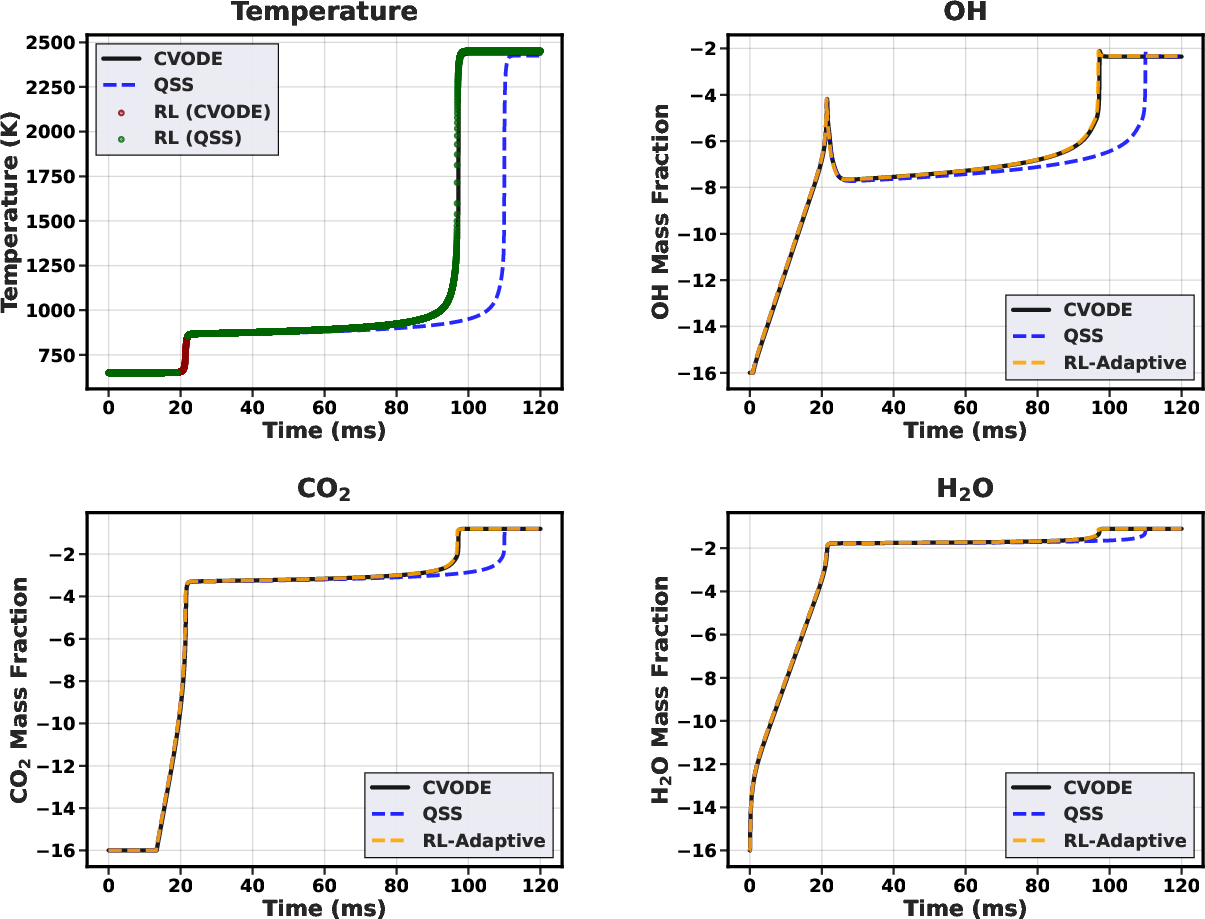
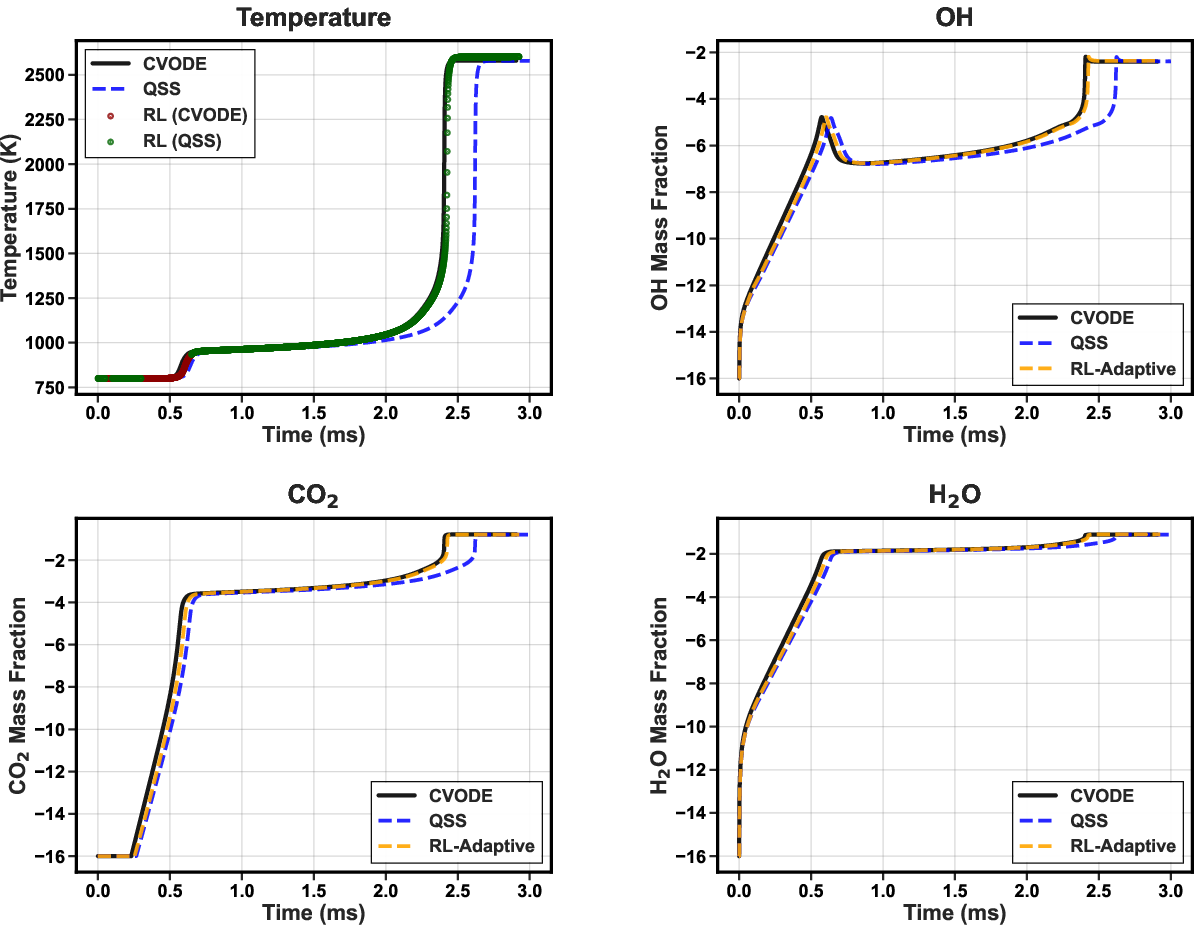
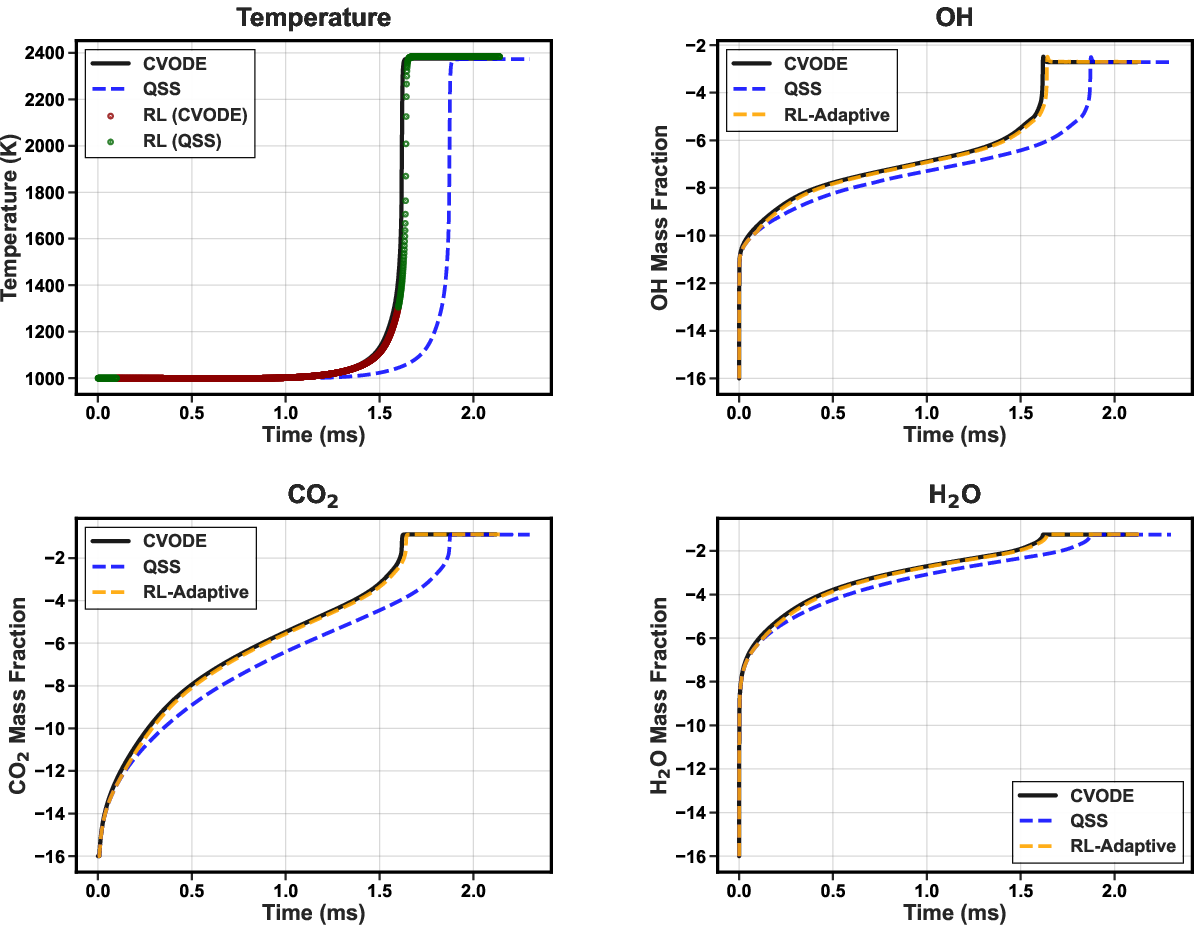
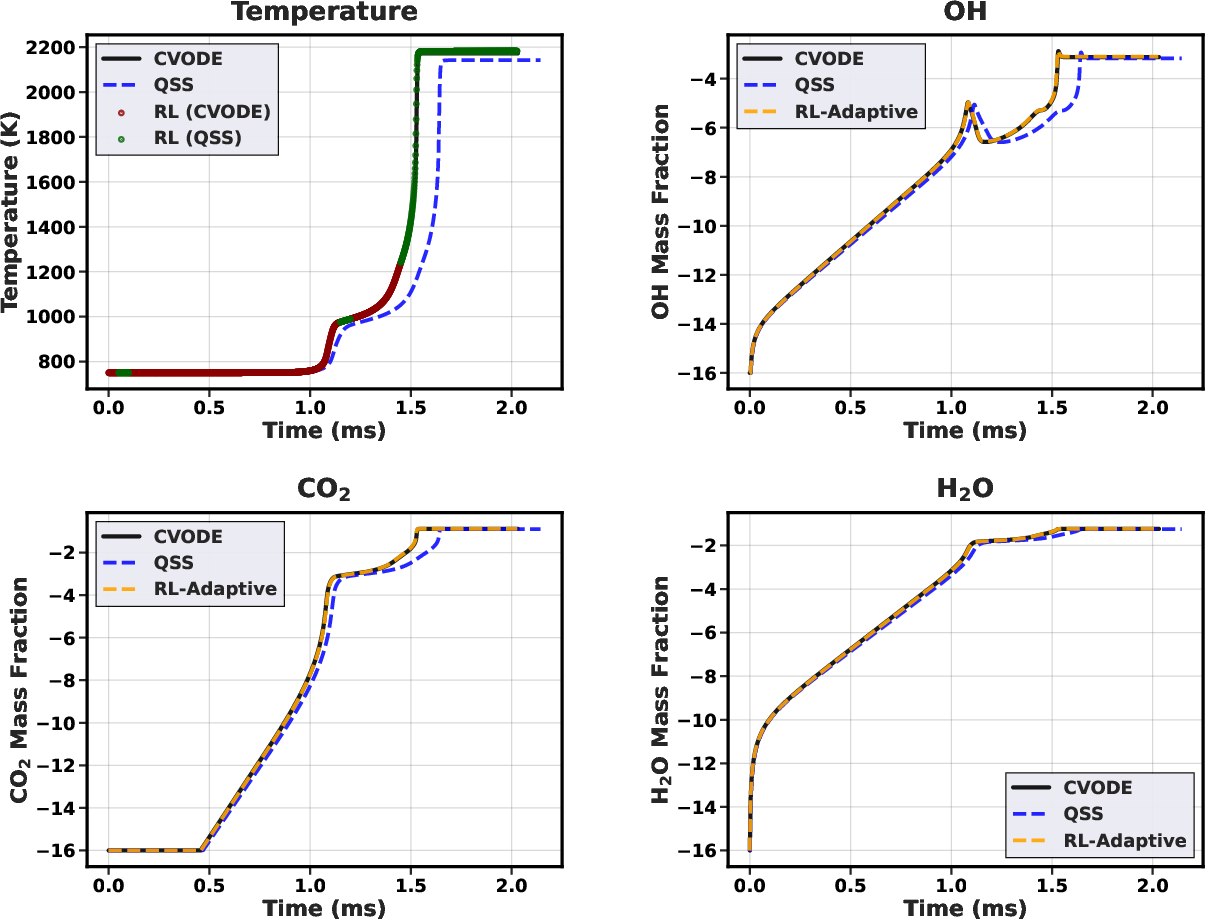
Figure 3: Temperature trajectory (condition: 650K, 1.0 atm) with overlaid solver choices (red: CVODE; green: QSS). CVODE is invoked primarily near the sharp ignition transition.
Policy Interpretability and Robustness
Notably, the RL policy’s decisions are not based purely on instantaneous state—by exploiting trajectory context (encoded via time derivatives and transient features), it effectively limits error accumulation and circumvents the pathological failure modes of static hybrids or greedy supervised classifiers.
Results: One-Dimensional Counterflow Diffusion Flames
Zero-Shot Generalization
A crucial outcome is the demonstrated zero-shot transfer of the policy trained on 0D reactors to 1D counterflow flame simulations over a wide range of strain rates (10–2000 s−1), without any retraining. In these PDE-based scenarios, where spatial transport dynamics substantially alter the distribution of local states and stiffness, the RL policy maintains near-reference accuracy (ignition delay error <2.5%, temperature RMSE <2.5 K) with ϵ0 mean computational speedup.
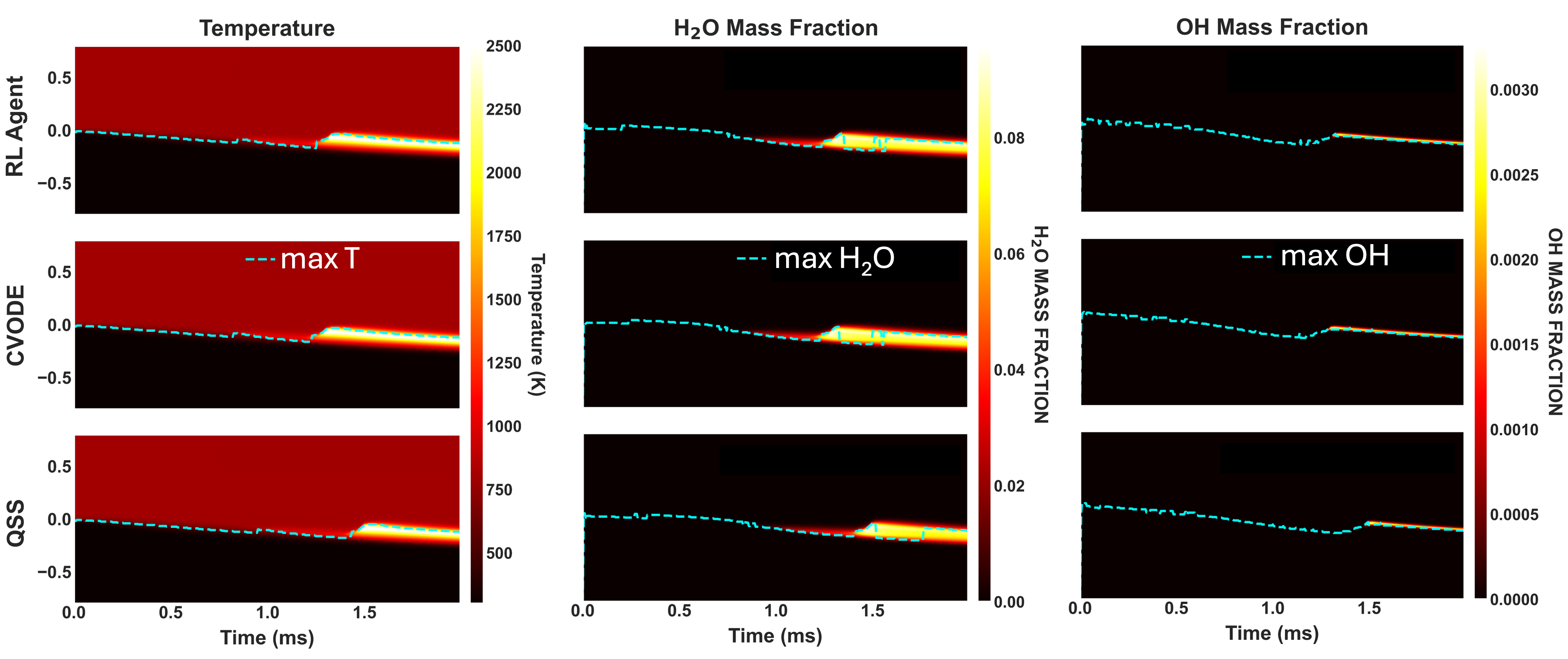
Figure 4: Space-time evolution of temperature and selected species (Hϵ1O, OH) in 1D counterflow, illustrating close alignment of the RL-adaptive and CVODE reference solutions, and error incurred by QSS-only integration.
Spatiotemporal Structure of Solver Deployment
Solver utilization maps reveal strong physical consistency: the RL agent applies implicit CVODE near ignition fronts and high-stiffness flame zones, while defaulting to QSS in less reactive regions.
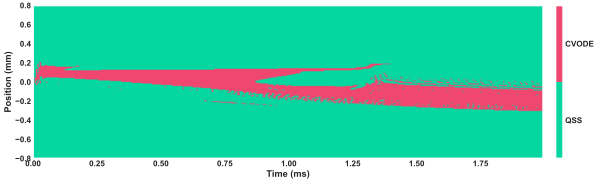
Figure 5: Deployment of CVODE (red) versus QSS (turquoise) by the RL policy in 1D flames at 2000 sϵ2. Implicit integration is highly localized around ignition/flame fronts.
Implications and Discussion
This study establishes the viability of CMDP-based RL for chemistry integration in multiphysics simulation. The RL agent autonomously discovers physically consistent solver allocation strategies, achieving performance unattainable by static or greedy approaches. The empirical results are robust across both ODE and PDE configurations—highlighting that the learned policy captures a genuine relationship between local state, error propagation, and computational cost that does not overfit to the training manifold.
Practically, the minimal policy inference overhead (typically ϵ33% of wall-clock time) and generic state-feature construction permit seamless integration with operator-splitting CFD codes. The framework provides a principled mechanism to interpolate between maximally-accurate, high-cost (all CVODE) and maximally-cheap, low-accuracy (all QSS) modes via user-tunable accuracy constraints.
Theoretically, the work illustrates how RL approaches—specifically, constraint-aware policy learning—can transcend the limitations of purely heuristic or supervised approaches, especially in non-stationary scientific computing settings with long-horizon objectives.
Future Perspectives
Future directions include expanding the action set to incorporate dynamic tolerance tuning and reduced-order solvers, scaling to multi-fuel or multi-stage chemistry, and deploying in higher-dimensional/turbulent regimes. The integration with other adaptive simulation mechanisms (e.g., AMR control, mesh coarsening) using coordinated RL decision layers is also a promising avenue for holistic optimization of large-scale reactive CFD workflows.
Conclusion
The RL-driven adaptive solver selection framework demonstrates that it is possible to autonomously achieve computational efficiency gains in stiff chemical kinetics integration while enforcing rigorous solution accuracy. The presented methodology opens pathways toward self-optimizing, accuracy-constrained simulation frameworks for complex multiphysics systems with spatially and temporally heterogeneous stiffness profiles.