Solving Problems of Unknown Difficulty
Abstract: This paper studies how uncertainty about problem difficulty shapes problem-solving strategies. I develop a dynamic model where an agent solves a problem by brainstorming approaches of unknown quality and allocating a fixed effort budget among them. Success arrives from spending effort pursuing good approaches, at a rate determined by the unknown problem difficulty. The agent balances costly exploration (expanding the set of approaches) with exploitation (pursuing existing approaches). Failures could signal either a bad idea or a hard problem, and this uncertainty generates novel dynamics: optimal search alternates between trying new approaches and revisiting previously abandoned ones. I then examine a principal-agent environment, where moral hazard arises on the intensive margin: how the agent explores. Dynamic commitment leads contracts to frontload incentives, which can be counteracted by the presence of learning. The framework reflects scientific discovery, product development, and other creative work, providing insights into innovation and organizational design.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Solving Problems of Unknown Difficulty”
What this paper is about
This paper asks a practical question: how should someone tackle a big, tricky problem when they don’t know how hard it is? Think of inventing a new technology, finding a scientific breakthrough, or building a startup. The author builds a model of how a person (or team) should split their time between:
- exploring new ideas, and
- pushing forward on ideas they already have, when they can’t tell if failures mean “this idea is bad” or “this problem is just really hard.”
The main questions in plain language
The paper focuses on five easy-to-understand questions:
- When you don’t know how hard a problem is, how should you balance trying new approaches versus sticking with current ones?
- How do repeated failures change what you should do next?
- Is it ever smart to go back to an old idea you previously abandoned?
- How do these choices change if you know the problem is easy or hard from the start?
- If an investor funds a problem-solver (like a startup founder), how should rewards be split over time to encourage smart exploration?
How the study works (with simple analogies)
The author builds a step-by-step model, like a “thought experiment,” to see what a careful problem-solver would do.
- Imagine you’re trying to open a locked door with a pile of unknown keys.
- Some keys are “valid” and could open the door.
- Most keys are “flawed” and will never work.
- If you have a valid key, trying it longer makes success more likely—but you don’t know how long it will take because the lock itself might be easy or hard.
- You have limited effort and can:
- keep trying a key you already have (exploitation), or
- spend time to find a new key (exploration), which costs energy/time.
The model tracks:
- your list of approaches (the keys you’ve tried),
- how long you’ve tried each one,
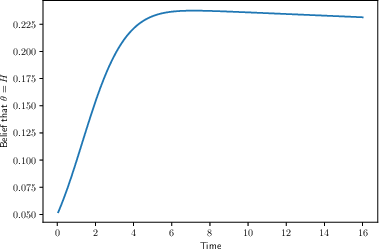
- what you learn from not succeeding yet,
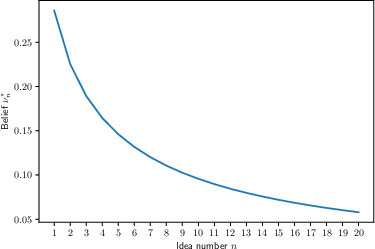
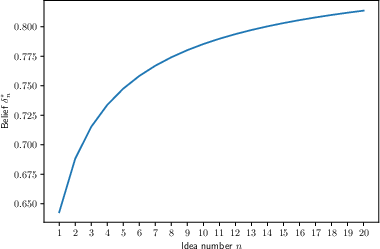
- and how your beliefs change about whether a key is good and whether the lock is easy or hard.
This setup is similar to a classic “multi-armed bandit” problem (like testing different slot machines to see which pays out), with a twist: all “machines” are influenced by the same hidden factor—the overall difficulty of the problem. That common factor makes everything interdependent: trying one approach teaches you about all the others.
To make the results usable for contracts and teamwork, the author also builds a smoother version of the model where there are “many tiny possible approaches” instead of a small number. This helps analyze how incentives (like equity shares for a founder) should change over time.
What the study found and why it matters
Here are the main takeaways, with short explanations of why they’re important:
- Unknown difficulty changes everything
- If you already know how hard the problem is, the best plan is simple: try one approach for a fixed amount of time, then move on; never split attention, and never go back to old ideas.
- If you don’t know the difficulty, failures are ambiguous. Now the best plan is more dynamic:
- you sometimes split effort across a few promising approaches,
- you alternate between trying new ideas and revisiting old ones,
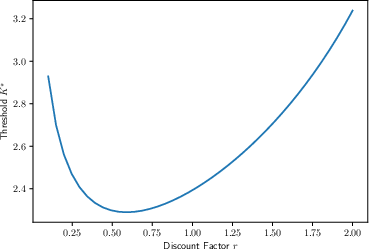
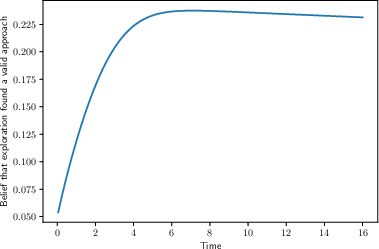
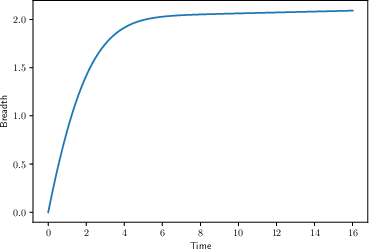
- and you raise your “patience threshold” as you explore more. In other words, the more ideas you’ve generated, the longer you’re willing to test each before moving on.
- Why revisiting old ideas can be smart
- Early failures might mean the problem is just harder than you thought, not that the idea is bad. As you learn more (say, you try other ideas and they also don’t work quickly), an old idea can look better again. So, “false starts” and “pivots back” are not mistakes—they can be optimal.
- How costs and speed affect your choices
- If it’s more costly to brainstorm a new idea, you spend longer on each idea before moving on.
- If successful ideas pay off quickly, you switch to new ideas sooner.
- Time pressure has a surprising effect: being a little more rushed can make you brainstorm more; being too rushed can make you procrastinate on exploring. Creativity often peaks at “medium” time pressure.
- When the problem might be impossible
- If a “hard” version of the problem literally never pays off, then there’s a limit to how many new ideas it makes sense to generate. The best plan eventually focuses on what you have.
- Designing incentives for teams and startups
- In a principal–agent setting (think: investor and founder), the conflict isn’t about working hard or shirking; it’s about how to work—how broad to search (try new ideas) versus how deep to dig (keep pushing one idea).
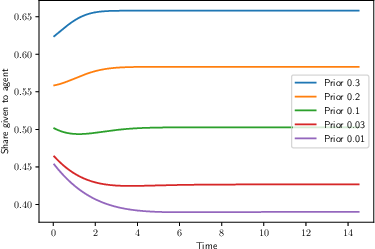
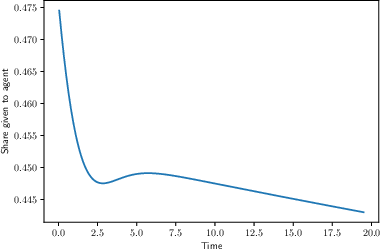
- Entrepreneurs tend to search too narrowly on their own, sticking with ideas for too long and pivoting too little.
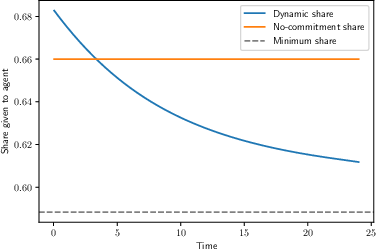
- Optimal contracts can fix this by changing the founder’s equity share over time:
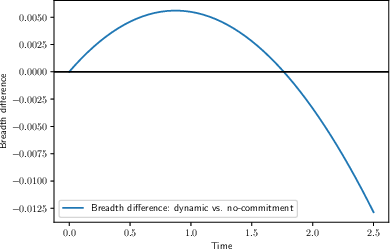
- Without learning, the best contract “frontloads” incentives: give the founder a higher share early to encourage broader early exploration, which boosts future progress even if early attempts don’t work.
- With learning, there’s a counterforce: as everyone becomes more pessimistic after long failure, increasing the founder’s share later can help keep exploration going.
- Result: the best contract can move up and down over time and may even reward or tolerate early failure, to keep the right kind of exploration alive.
Why this matters in the real world
- For students and researchers: Don’t treat failure as a sure sign your idea is bad. Sometimes the problem is just tough. Track how much effort you’ve spent on each idea, try new ones, and don’t be afraid to revisit a promising old idea later.
- For startups and innovators: Plan for cycles—explore, focus, revisit, and explore again. Early “false starts” can be part of the smartest path.
- For managers and investors: Structure rewards so people explore broadly early on, then adjust as you learn about the problem’s difficulty. Tolerating early failure can be exactly what keeps the project moving toward success.
In short, when you don’t know how hard the problem is, the smartest way to search looks less like a straight line and more like cycles of trying, learning, switching, and sometimes circling back. And the right incentives can make those cycles happen at the right times.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that can be deployed now, drawing directly from the paper’s findings on optimal search under unknown difficulty, alternating exploration and revisitation, and intensive-margin contracting.
- R&D project management workflows (software, biotech, materials, hardware)
- Application: Implement an “breadth–depth” search workflow that alternates between brainstorming new approaches and revisiting previously abandoned ones, with a policy to:
- Equalize effort across the least-tested approaches (“best” approaches are those with minimal cumulative effort).
- Use increasing pivot thresholds: require more cumulative effort per approach before greenlighting new brainstorming as the project progresses.
- Tools/products:
- Breadth–Depth Tracker (JIRA/Trello plugin) that logs per-approach cumulative effort and recommends when to brainstorm vs revisit based on rising thresholds.
- Pivot Threshold Calculator (simple spreadsheet) to operationalize the idea that the revisit/pivot threshold increases with the number of explored approaches.
- Assumptions/dependencies: Ability to track time/effort per approach; team discipline in logging; suitable when approaches are ex-ante similar and failure is an imperfect signal.
- AI/ML research and AutoML pipelines (software, AI)
- Application: Modify hyperparameter/architecture search to periodically revisit previously dropped configurations when accumulated failures suggest the task may be harder than expected. Allocate compute to equalize effort across least-tested candidates rather than chasing only recent “winners.”
- Tools/products: AutoML scheduler that enforces equalization across least-tested models and injects scheduled revisit cycles; logging modules to estimate “difficulty” via survival rates.
- Assumptions/dependencies: Instrumented pipelines with per-trial logs; sufficiently large candidate pool; compute budgets; approximation of success arrival as stochastic.
- High-throughput screening and re-screening protocols (biotech, materials, energy)
- Application: Adjust screening campaigns to:
- Re-screen previously discarded hits later in the campaign if early failures suggest higher underlying difficulty.
- Allocate instrument time to equalize cumulative exposure across least-tested compounds or configurations.
- Tools/products: Revisit cadence SOPs; dashboards showing cumulative exposure by compound/material and recommending next batch composition.
- Assumptions/dependencies: Sample availability, cost per screening run, robust tracking; appropriate when many candidates are ex-ante undifferentiated.
- Agile product development and innovation teams (software/hardware)
- Application: Sprint policies that:
- Timebox effort per prototype, then brainstorm a new prototype if the least-tested pool has hit a threshold.
- Schedule “revisit sprints” to retest abandoned prototypes after additional failures on new ones (interpreting failures as potentially due to difficulty, not just bad design).
- Tools/products: Sprint templates with increasing pivot thresholds; backlog analytics to identify least-tested items.
- Assumptions/dependencies: Granular effort logging; management buy-in to revisit decisions; suitable in environments where success is binary or milestone-based.
- Venture capital and corporate innovation contracts (finance, entrepreneurship)
- Application: Frontload incentives to induce broader early exploration (e.g., higher early equity, milestone bonuses for new-approach generation), with provisions that tolerate or reward early failure (reflecting the paper’s result that intensive-margin moral hazard calls for frontloading; learning can later temper this).
- Tools/products: Exploration Equity Designer (term-sheet templates with time-varying founder equity; milestone bonuses tied to breadth metrics); “failure bonus” micro-grants for documented pivots.
- Assumptions/dependencies: Legal feasibility of time-varying equity; measurable exploration breadth; cultural acceptance of rewarding early failure.
- Public funding and grants program design (policy, academia)
- Application: Stage-gated grants that:
- Frontload funding and flexibility to expand breadth early.
- Include “revisit vouchers” to revisit previously unsuccessful directions when accumulated evidence suggests higher difficulty.
- Use portfolio metrics like Breadth Index and Revisit Rate in reporting.
- Tools/products: Grant Frontloader policy templates; reviewer guidelines that recognize optimal alternation and revisit.
- Assumptions/dependencies: Administrative capacity to track breadth/depth; fair and transparent metrics; applicable to fundamental research with uncertain difficulty.
- Academic advising and lab management (academia)
- Application: Research planning that:
- Alternates exploration and revisitation; uses increasing thresholds for moving on.
- Logs cumulative effort per idea; schedules revisit cycles; educates students that failures ambiguously signal approach quality vs problem difficulty.
- Tools/products: Breadth–Depth logbooks; lab SOPs for alternating phases; simple calculators for threshold increases as projects expand.
- Assumptions/dependencies: Willingness to maintain effort logs; many ex-ante similar ideas; acceptance of “false starts” as part of optimal strategy.
- Personal problem-solving and productivity (daily life)
- Application: Timeboxing with planned revisits:
- Equalize time across least-tried strategies.
- Increase the timebox threshold before trying new strategies as you add more strategies.
- Revisit earlier strategies after additional failures to avoid prematurely discarding good ideas on hard problems.
- Tools/products: Spreadsheet or app that tracks strategy timeboxes and auto-schedules revisit sessions.
- Assumptions/dependencies: Consistent logging; problems where success is rare and difficulty uncertain (e.g., creative writing, algorithmic puzzles).
Long-Term Applications
The following applications require further research, parameter estimation, scaling, or organizational and regulatory development before widespread deployment.
- Model-based decision-support platforms for R&D portfolio optimization (software for cross-industry R&D)
- Application: A platform that estimates , , , , from historical data, computes rising thresholds , and recommends when to brainstorm, split effort across least-tested approaches, and when to revisit.
- Tools/products: Breadth–Depth Scheduler with Bayesian difficulty learners; APIs for lab notebooks, issue trackers, and automation.
- Assumptions/dependencies: Reliable data to estimate parameters; validation in different domains; user trust in probabilistic recommendations.
- Adaptive, non-monotonic incentive systems for VC and corporate R&D (finance, entrepreneurship)
- Application: Contracts that algorithmically adjust founder/agent equity or bonus shares over time, frontloading to induce breadth and selectively backloading when learning indicates sustained difficulty, potentially including failure reward clauses.
- Tools/products: Contract analytics that co-optimize exploration breadth and principal’s dilution; templates that encode learning-triggered adjustments.
- Assumptions/dependencies: Legal adaptability, regulatory approval, accurate measurement of exploration behaviors; cultural acceptance.
- Healthcare diagnostics decision support (healthcare)
- Application: Systems that allocate diagnostic effort across differential diagnoses, equalizing effort across least-tested hypotheses and revisiting earlier hypotheses as ongoing failure suggests high difficulty, with guardrails for safety and ethics.
- Tools/products: Diagnostic effort allocators integrated into EHR; policy rules for revisit cadence when uncertainty about difficulty persists.
- Assumptions/dependencies: Clinical validation; adaptation from single-breakthrough to multi-outcome settings; strong safety and regulatory oversight.
- AI lab governance and compute allocation (AI, research infrastructure)
- Application: Compute schedulers that implement breadth-first allocation early, enforce equalization across least-tested experiment families, and algorithmically schedule revisits as evidence accumulates about problem difficulty.
- Tools/products: Cluster-level breadth–depth controllers; telemetry to estimate survival probabilities and difficulty over time.
- Assumptions/dependencies: Robust telemetry, parameter learning; integration with job schedulers; buy-in from research leadership.
- Automation in materials and energy discovery (robotics, materials, energy)
- Application: Autonomous labs that blend high-throughput exploration with planned revisits based on learned difficulty, dynamically adjusting batch selection to equalize cumulative exposure and increasing thresholds over campaign duration.
- Tools/products: Lab automation orchestrators with embedded breadth–depth strategies; interfaces to characterization tools.
- Assumptions/dependencies: Advanced robotics; live parameter estimation; domain-specific adaptations to non-Poisson success and correlated validity.
- Education and pedagogy for problem solving (education)
- Application: Curricula that teach “problems vs exercises,” alternating exploration and revisitation, and the ambiguity of failure; classroom tools to log effort and schedule revisits with increasing thresholds.
- Tools/products: Lesson modules; student dashboards tracking breadth–depth; instructor guidelines.
- Assumptions/dependencies: Teacher training; curriculum time; assessment frameworks that value breadth and learning dynamics.
- Government innovation policy for frontier science (policy, national innovation systems)
- Application: Programs for AGI, fusion, superconductivity, etc., that explicitly frontload exploration budgets, maintain revisit funds, and tolerate early failure as a feature of optimal search under unknown difficulty.
- Tools/products: Policy playbooks; metrics (Breadth Index, Revisit Rate) for portfolio oversight.
- Assumptions/dependencies: Political will; robust monitoring; alignment with long-run societal objectives.
Cross-cutting assumptions and dependencies
- Ex-ante similarity of approaches and independent validity draws (can be relaxed with correlation, but requires model adaptation).
- Success modeled as a one-time breakthrough with Poisson arrival; some sectors may need multi-stage or repeated-payoff adaptations.
- Effort can be fractionally allocated and reliably logged; survival (no success) is an informative but imperfect signal.
- Unknown difficulty acts as a common factor across approaches; failures update beliefs system-wide.
- Intensive-margin moral hazard (how to explore) is the relevant frication; environments with extensive-margin shirking may need different contracts.
- Organizational and legal feasibility of time-varying equity/bonus schedules and “failure bonuses.”
- Cultural acceptance of revisiting previously abandoned ideas and tolerating early failure as optimal behavior under uncertainty.
Collections
Sign up for free to add this paper to one or more collections.