- The paper demonstrates that ES pretraining accelerates convergence in simple, low-dimensional tasks by effectively biasing parameter initialization.
- It shows that ES struggles in high-dimensional and continuous control settings where end-to-end, gradient-based learning is crucial.
- The study highlights the need for hybrid architectures to bridge the gap between black-box ES and gradient-based DRL methods.
Evolution Strategies as Pretraining in Deep Reinforcement Learning: An Empirical Assessment
Introduction
This paper systematically investigates the use of Evolution Strategies (ES) as both a standalone approach and a pretraining mechanism for Deep Reinforcement Learning (DRL), focusing on the practical efficacy of such hybridization across tasks of varying complexity. The work provides a rigorous, empirical head-to-head comparison between black-box derivative-free ES and established gradient-based RL methods, namely Deep Q-Networks (DQN) for discrete control and Proximal Policy Optimization (PPO) for continuous control, within Flappy Bird, Breakout, and MuJoCo environments (2604.00066).
Methodological Framework
The ES implementation follows the scalable variant introduced by Salimans et al., utilizing Monte Carlo gradient estimation with population parameter perturbations and reward-based fitness assignment. Core DRL models are canonical: DQN for pixel and RAM-based arcade games, and PPO for MuJoCo continuous control, with compatible MLP or CNN-based architectures to facilitate parameter transfer during ES→DRL pretraining.
The main empirical objectives are:
- Comparing sample efficiency and final performance of ES vs DRL,
- Evaluating the effect of ES-based parameter initialization on DRL training speed and robustness to hyperparameter and seed variation,
across environments scaling from low to high observation and action dimensionality.
Empirical Results
Flappy Bird: Simple Environments
ES demonstrates strong capability to rapidly find highly survivable policies in Flappy Bird, converging stably with low sensitivity to hyperparameters. DQN ultimately outperforms ES in final reward, but exhibits notable instability characterized by abrupt reward drops and poor recovery. Critically, initializing DQN with ES-pretrained weights leads to accelerated convergence, clearly reducing required steps to competitive policy quality.
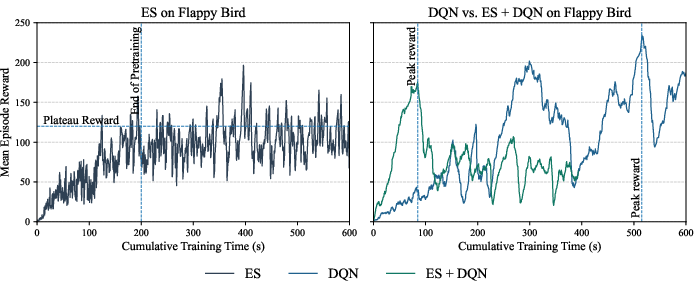
Figure 1: Training dynamics comparison for ES, DQN, and ES-pretrained DQN demonstrate the clear pretraining benefit in Flappy Bird.
This result highlights the utility of ES for robust exploration and stable parameter-space search in sparse-reward, low-dimensional settings, and its potential as a practical pretraining scheme for tabular-to-moderate sized RL.
Breakout: High-dimensional Discrete Control
When addressing the image-based Breakout task, DQN (with CNN policy) yields consistently higher mean reward (~30) than ES, which is unable to scale and plateaus far below competitive returns (mean ~1.5). In simpler RAM-based tasks, ES achieves higher initial gains (mean reward ~4) but stalls quickly, failing to approach DQN's capability.
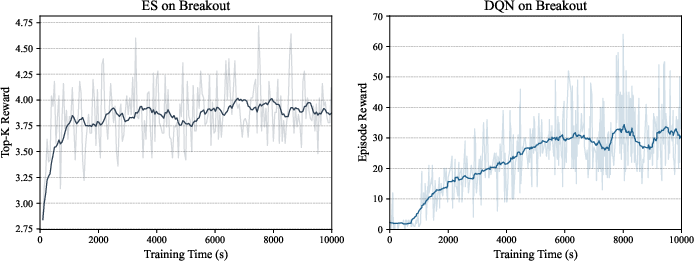
Figure 2: DQN significantly outperforms ES in pixel-based Breakout, with ES unable to escape early plateaus.
The findings indicate that ES struggles to extract meaningful spatial and temporal representations in high-dimensional observation spaces, and that its data efficiency and reward structure scaling are inadequate for these settings. DQN's temporal-difference mechanisms and end-to-end representation learning deliver a clear advantage.
MuJoCo: Continuous Control
For continuous control tasks, ES is signficantly slower to converge (e.g., 20x slower in HalfCheetah) and cannot achieve PPO’s best performance within comparable wallclock time. Although ES is robust—exhibiting lower variance across seeds and runs—its learning progress is generally subpar relative to PPO, which achieves strong performance rapidly in some tasks but suffers from marked instability and hyperparameter sensitivity elsewhere.
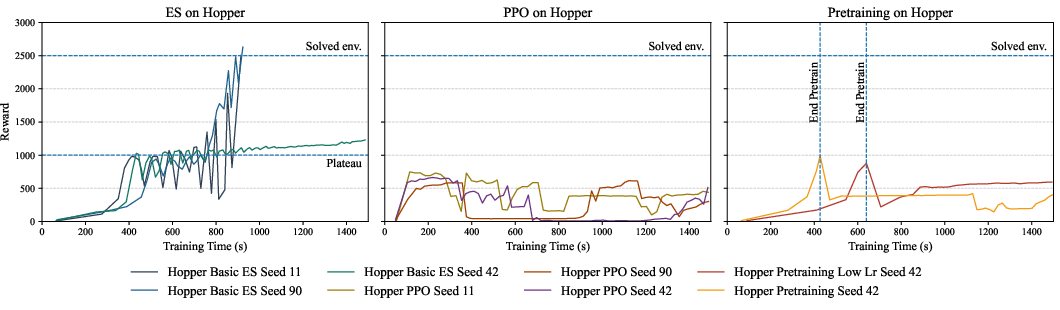
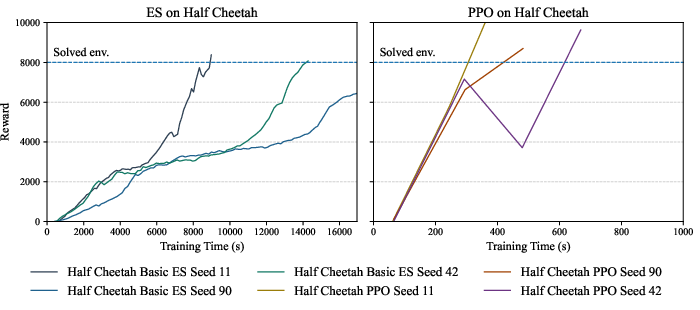
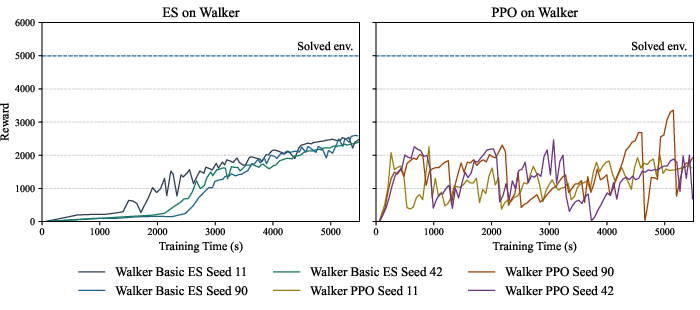
Figure 3: ES, PPO, and ES-pretrained PPO compared on Hopper; ES pretraining confers no clear advantage in convergence speed or final policy robustness.
ES pretraining does not improve PPO convergence speed or robustness. These results generalize across Hopper and Walker2d; PPO performance in these tasks is largely unaffected by initial actor weights derived from ES, with instability and oscillatory dynamics persisting regardless of initialization.
Analysis and Discussion
The results demonstrate that the effectiveness of ES, either as an independent optimizer or as a pretraining mechanism, is strictly environment-dependent. In low-dimensional, sparse-reward settings, ES provides stable optimization and can bias DRL algorithms into favorable regions of parameter space; in higher-complexity visual or continuous control tasks, ES is systematically limited by its inability to leverage end-to-end differentiability for representation learning.
DRL approaches remain highly sensitive to optimizer choices, reward scaling, and value estimation stability, yet ultimately achieve higher asymptotic performance where the environment demands hierarchical feature extraction and temporal abstraction. The incompatibility of ES actor-only pretraining for actor-critic architectures such as PPO limits transfer, as the critic remains randomly initialized and optimization objectives are not aligned. The lack of benefit from ES in complex RL underscores the need for hybrid architectures that explicitly bridge policy/value, gradient-based/gradient-free dichotomies.
Implications and Future Directions
From a practical standpoint, the study rigorously invalidates the hypothesis that ES is broadly useful as a DRL pretraining accelerator in real-world, high-dimensional RL scenarios. Theoretical implications include the demonstration of ES’s sensitivity to environmental reward structure and representation complexity, and the architectural misalignment between ES and typical actor-critic RL.
Future work should focus on:
- Developing hybrid optimization architectures that align value and policy representations, or permit progressive mutual adaptation between ES and gradient-based methods;
- Leveraging modular or shared latent representations to enhance transferability;
- Exploring ES-augmented RL only in domains where black-box optimization complements sparse or non-differentiable reward structure.
Conclusion
The evidence clearly supports the claim that ES-based pretraining only accelerates DRL in simple, low-dimensional environments, and fails to generalize as a training or robustness enhancement tool in high-dimensional or continuous control domains. While ES remains attractive for black-box optimization where environmental gradients are unavailable or unreliable, its applicability as a component in scalable DRL for challenging AI tasks is fundamentally limited by representation and architectural constraints. Hybrid, architecture-aware methods present the most promising avenue for future advances.
(2604.00066)