- The paper introduces ReTriP, a unified framework that employs chain-of-thought reasoning and reinforcement learning to optimize retrosynthetic routes.
- The paper details a novel path-coherent representation method that maintains structural alignment and minimizes representational drift in multi-step synthesis.
- The paper demonstrates state-of-the-art performance on RetroBench, achieving a Top-1 accuracy of 45.5% and robust long-horizon planning.
Reinforced Reasoning for End-to-End Retrosynthetic Planning: A Technical Essay
Introduction and Motivation
Retrosynthetic planning is a central problem in computational chemistry, requiring the transformation of a target molecule into a set of purchasable precursors through a plausible sequence of chemical reactions. The combinatorial complexity of this task is substantial due to the exponential growth of the synthetic search space with increasing pathway depth. Traditional AI approaches hierarchically decompose this challenge, relying on decoupled predictive engines and heuristic search, which, despite their modularity, fracture the logical flow between local reaction modeling and global synthesis goals.
The "Reinforced Reasoning for End-to-End Retrosynthetic Planning" (ReTriP) framework advances the field through a fully unified, end-to-end generative paradigm that aligns local rationality with global retrosynthetic utility using a Chain-of-Thought (CoT) reasoning formalism augmented by path-coherent molecular representations and a progressive, reinforcement-driven training curriculum (Figure 1).
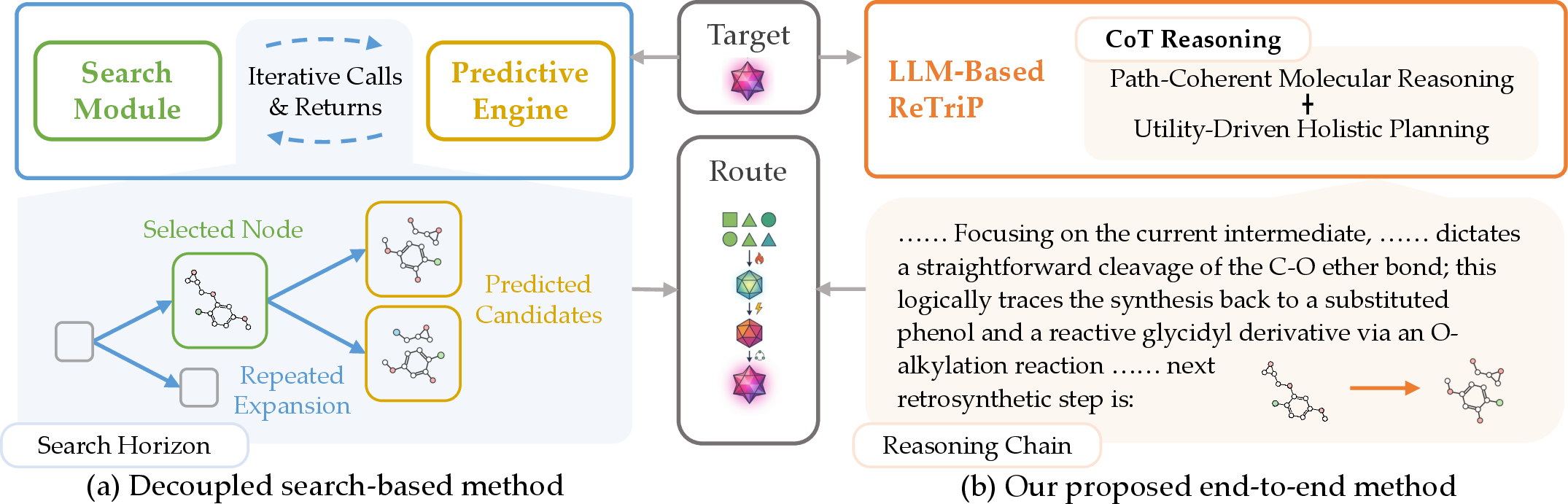
Figure 1: Comparison of retrosynthetic paradigms. (a) Decoupled search-based method; (b) The unified ReTriP framework.
Methodological Innovations
Path-coherent Representation and Alignment
A longstanding technical bottleneck arises from inconsistent atom indexing and context-insensitive SMILES notations, which undermine the model's ability to retain fragment-level correspondence along multi-step reaction routes. ReTriP introduces a path-coherent notation scheme, implementing iterative, root-aligned SMILES anchoring that ensures direct structural mapping from products to precursors throughout the entire planning trajectory. This approach decouples the representational layer from chemical logic, enabling the model to focus on meaningful reaction transformations rather than syntactic permutations.
Once a retrosynthetic route is linearized from its underlying DAG structure, alignment propagates topological correspondence stepwise, and notational augmentation is employed to increase the model's exposure to permissible representational variants, thereby minimizing overfitting to spurious string patterns (Figure 2).
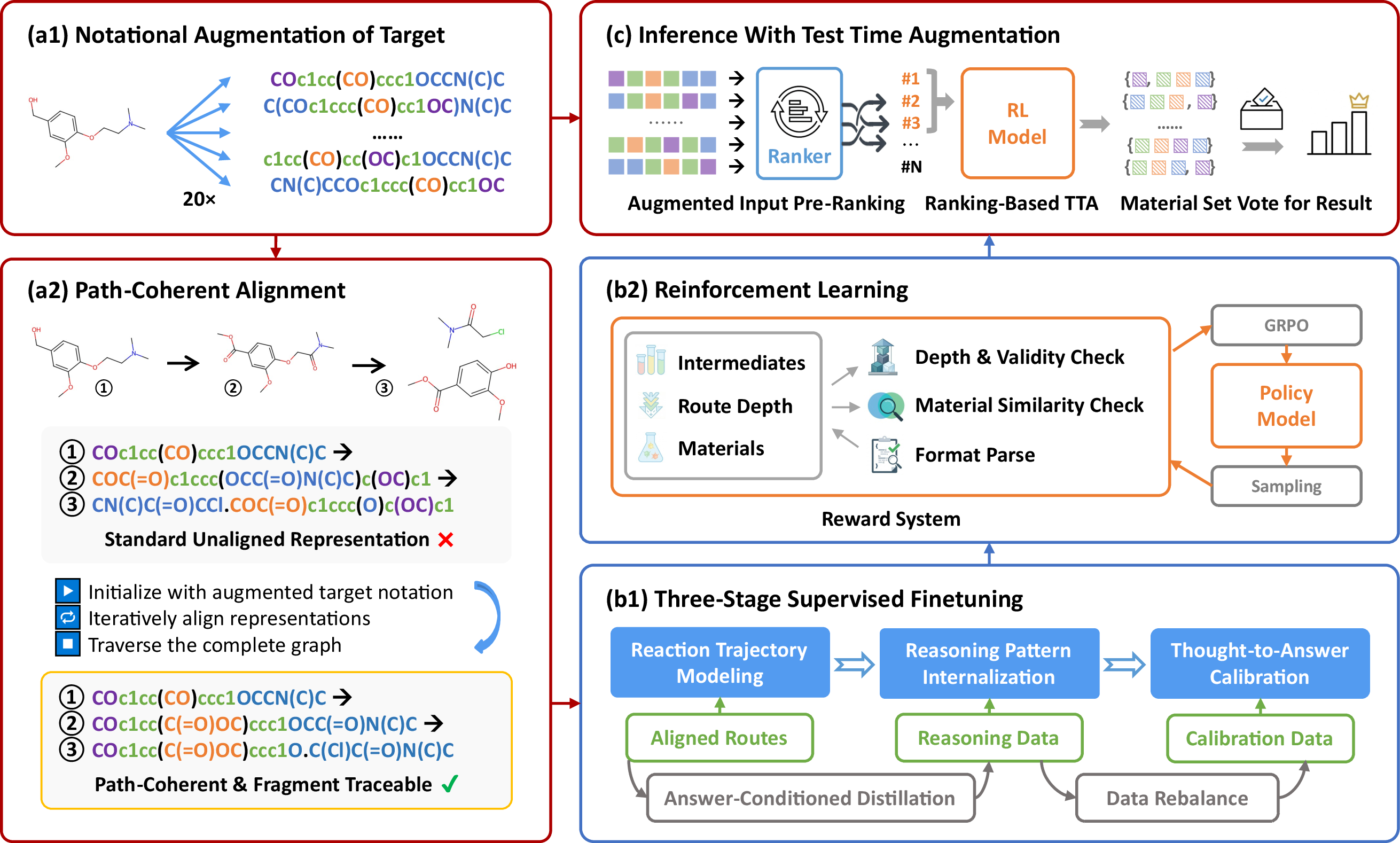
Figure 2: The ReTriP pipeline integrates path-coherent data construction, a progressive training curriculum (SFT and RLVR), and inference scaling through ranking-guided TTA and consensus voting.
Progressive Training Curriculum
ReTriP adopts a multi-phase training protocol:
- Stage 1 (Trajectory Modeling): The LLM is trained to model long-range, path-coherent retrosynthetic sequences, internalizing the statistical priors governing feasible reaction trajectories.
- Stage 2 (CoT Reasoning Distillation): Explicit stepwise rationales are distilled from a teacher LLM conditioned on ground-truth plans, supplying the model with interpretable chemical reasoning templates essential for correct long-horizon inference.
- Stage 3 (Loss Rebalancing): The curriculum employs a weighted combination loss to mitigate the gradient imbalance between high-entropy linguistic reasoning and low-entropy molecular output space, preserving accuracy in answer segments.
Reinforcement Learning with Verifiable Rewards (RLVR)
Central to ReTriP's utility-oriented optimization is RLVR, which incentivizes plans that terminate in valid, purchasable precursors, penalizes invalid routes, and rewards parsimony and format adherence. Rewards are hierarchically structured to prefer exact precursor matches but supply gradients for partial progress. An explicit capacity to penalize over-complexity via route depth and to discount invalid intermediates further encourages manageable, efficient plans. RLVR reshapes the model policy to maximize practical, rather than solely imitative, synthetic utility.
Inference-time Notational Pre-ranking and TTA Scaling
ReTriP employs a MolFormer-based scoring model to rank notational variants of targets, thereby initializing the LLM with the most informative starting representation for retrosynthetic planning. At inference, multiple high-scoring notational seeds are expanded in parallel (test-time augmentation, TTA), and consensus is used to select robust precursor sets, reliably surfacing valid but rare synthetic strategies.
Empirical Results
On the challenging RetroBench benchmark, ReTriP establishes a new SOTA with a Top-1 accuracy of 45.5%, outperforming prior LLM-based and classical hybrid search approaches by 3.4 percentage points. Under the Top-5 metric, performance reaches 57.6%, highlighting robust coverage across notational and chemical space.
Depth-wise Robustness
A marked advantage is observed in long-horizon planning (route depth ≥5). Whereas baseline methods experience degradation due to cascading representation error and search myopia, ReTriP sustains approximately 40% Top-1 accuracy, a manifestation of its ability to maintain coherent structural alignment during deep reasoning (Figure 3).
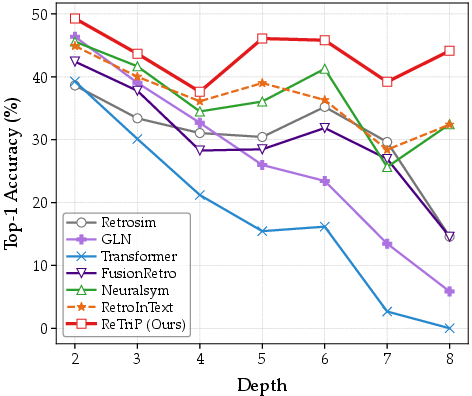
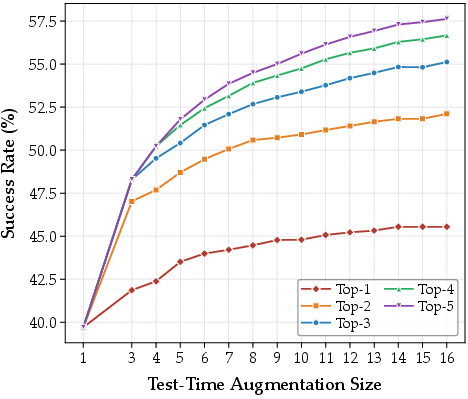
Figure 3: Top-1 accuracy across different synthetic route depths.
Planning Traceability and Coherence
Path-coherent alignment minimizes normalized Levenshtein distance (NLD) between the initial target and right-hand side species at each retrosynthetic step, empirically demonstrating reduced representational drift compared to canonical SMILES strategies (Figure 4).
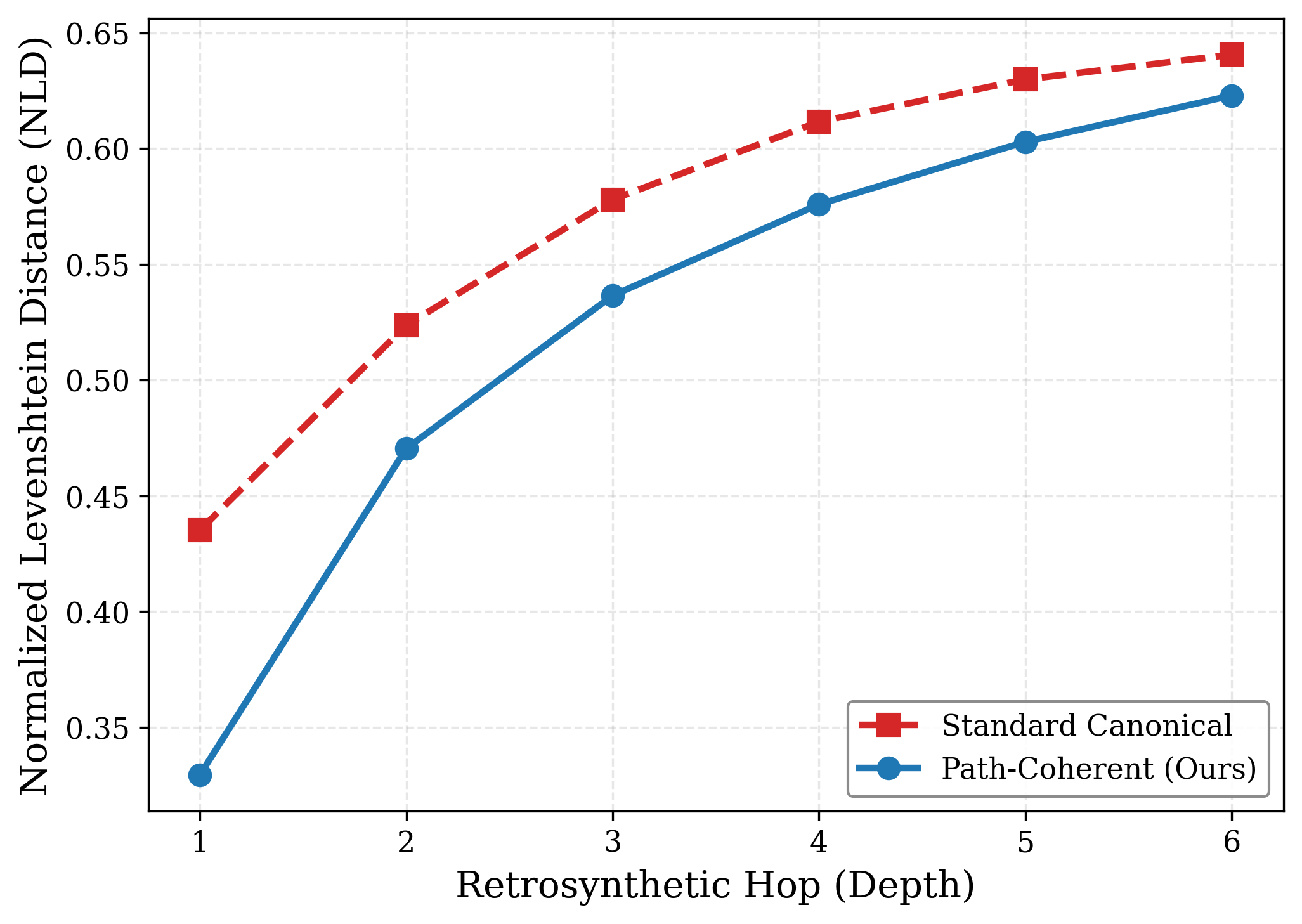
Figure 4: The NLD metric versus retrosynthetic depth, showing consistently lower divergence for ReTriP’s path-aligned notation.
Qualitative Reasoning
ReTriP generates interpretable, multi-step CoT rationales elucidating strategic disconnections for complex targets, concretely supporting convergent synthesis strategies and stereochemical logic (Figure 5).
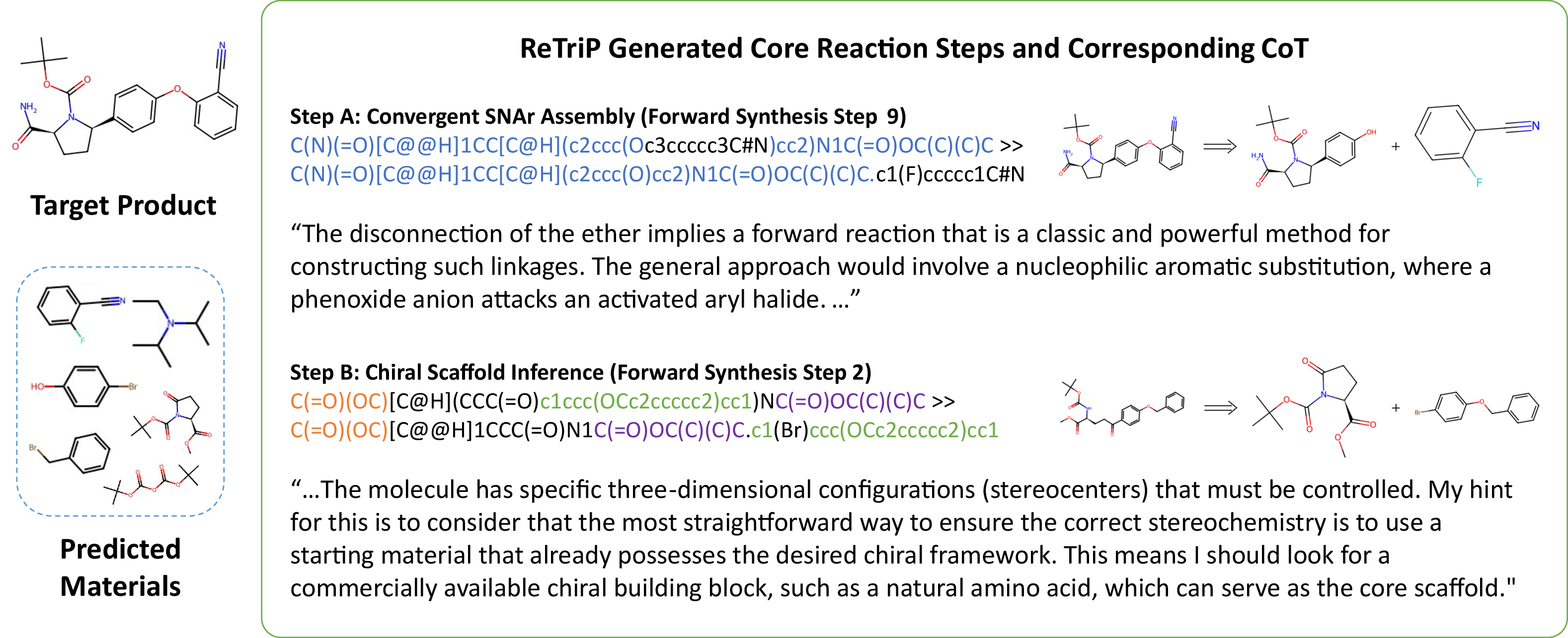
Figure 5: Qualitative case study. A generated 9-step plan with integrated CoT reasoning at critical steps.
Optimization Efficiency
Training reward curves (Figure 6) confirm rapid RLVR convergence and efficient internalization of synthetic constraints, while TTA analysis indicates monotonic performance gains with scaling, underscoring the benefit of representational diversity during inference.
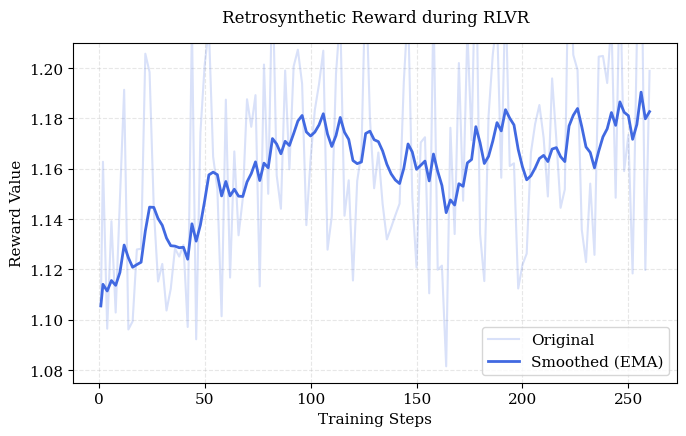
Figure 6: Training reward curves for RLVR phase of ReTriP indicate effective alignment between reasoning and synthetic utility.
Ablation and Analysis
Systematic ablation studies demonstrate that each methodological component—path-coherent alignment, CoT reasoning, RL alignment, and notational pre-ranking—contributes cumulatively and sub-additively to final accuracy, with no single element solely responsible for SOTA performance. Notably, vanilla transformer LLMs, even those with extensive molecular pretraining, perform at chance on unmodified RetroBench, emphasizing that ReTriP's technical advances are fundamental, not incremental.
Implications and Future Directions
By bridging the architectural gap between local reaction logic and global synthetic objectives, ReTriP signals a transition toward fully autonomous, strategy-aware retrosynthetic planning. Its unified and interpretable route generation pipeline obviates the need for externally orchestrated search heuristics, enabling direct policy optimization via chemically meaningful reward structures. Practically, this reduces cumulative error, increases route plausibility, and simplifies downstream verification—a requirement for intelligent, human-in-the-loop chemical design systems.
Theoretically, ReTriP sets a precedent for chemically-grounded, reasoning-intensive LLM pipelines and provides a blueprint for AI systems that seek to unify domain-specific latent representations with flexible, verifiable control policies. The explicit integration of path coherence and RLVR could extend to other symbolic or graph-based scientific planning tasks.
Future research should examine transferability to broader domains (e.g., photochemistry, materials synthesis), integration of physical constraints (yield, cost minimization), and the development of agentic chemistries where ReTriP-like planners coordinate with experimental automation platforms.
Conclusion
ReTriP represents a significant advancement in retrosynthetic planning, setting a new standard for accuracy and robustness through the unification of representation, reasoning, and reward optimization. Its success demonstrates that chemically interpretable, CoT-driven LLMs, when combined with path-coherent notation and goal-aligned RL, are capable of outperforming modular search-based systems and provide a scalable foundation for future developments in autonomous chemical synthesis and molecular discovery.