- The paper presents a novel framework combining DMPs with STT-based safety to ensure forward invariance and rapid convergence in dynamic HRI tasks.
- It integrates formal control theory with learning-based motion generation, eliminating runtime optimization while maintaining robust obstacle avoidance.
- Experimental results demonstrate improved safety margins and lower recovery error compared with heuristic and optimization-based baselines across simulation and hardware trials.
Introduction
The deployment of robots in dynamic and uncertain human environments imposes strict requirements on both robustness to disturbances and formal safety guarantees, particularly for real-time human-robot interaction (HRI). While Dynamic Movement Primitives (DMPs) are widely used for learning robust, attractor-based motion from demonstration, they lack mechanisms to enforce provable, closed-form safety in the presence of both static and dynamic obstacles. In contrast, methods grounded in formal control theory—such as those using Control Barrier Functions (CBFs)—provide strong theoretical safety but require heavy, online optimization, limiting their practicality for high-frequency, real-time operation.
SafeDMPs, introduced in "SafeDMPs: Integrating Formal Safety with DMPs for Adaptive HRI" (2603.29708), present a unified framework that combines the efficiency, generalizability, and inherent robustness of DMPs with strong, non-optimization-based formal safety via Spatio-Temporal Tubes (STTs). This integration yields a real-time-capable system that guarantees forward invariance within provably safe envelopes during execution, even in highly dynamic, collaborative settings.
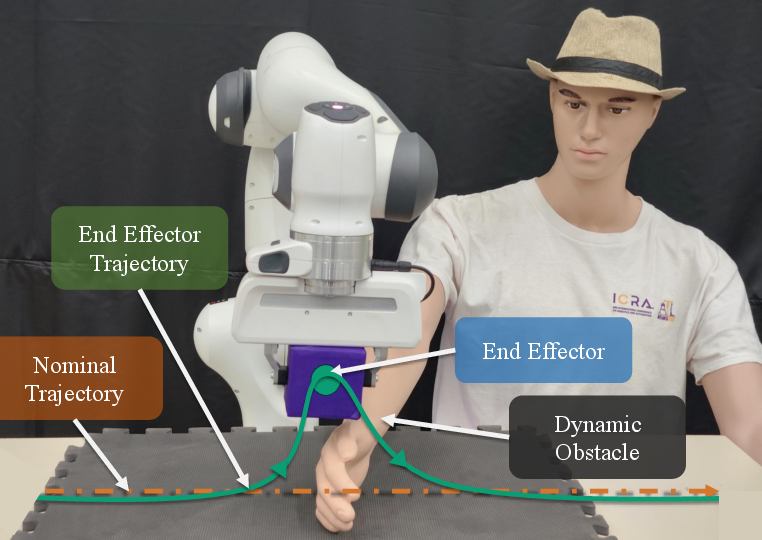
Figure 1: Hardware setup featuring the Franka Research 3 robot equipped for human-robot interaction tasks; illustration of SafeDMPs for adaptive HRI in response to dynamic interference.
Technical Framework
DMPs as Nominal Motion Generators
DMPs encode motion as stable, second-order dynamical systems modulated by learned nonlinear forcing terms. This formulation enables faithful reproduction of demonstrated trajectories, robust goal convergence, and flexible spatial/temporal adaptation. DMPs offer several key properties:
- Goal attractor dynamics maintain stability under perturbation.
- Temporal and spatial scaling allow rapid adaptation to new tasks.
- Real-time execution due to closed-form computation.
However, DMPs are agnostic to safety constraints and, without augmentation, have no mechanism to avoid unsafe states in the presence of unforeseen obstacles.
The core innovation in SafeDMPs is augmenting DMP execution with STT-based safety modulation. Each coordinate is constrained within a time-varying envelope (the tube), parameterized by explicit bounds. The STT controller computes a normalized error and applies a logarithmic corrective control law that diverges rapidly near tube boundaries, strictly enforcing invariance without requiring numerical optimization at runtime.
Safety envelopes are efficiently deformed online; if an obstacle enters the workspace, the envelope is contracted, and the end-effector is smoothly rerouted within a collision-free tube, always ensuring convergence to the nominal path when the disturbance clears. This guarantees provable avoidance of static and dynamic obstacles under practical actuator constraints.
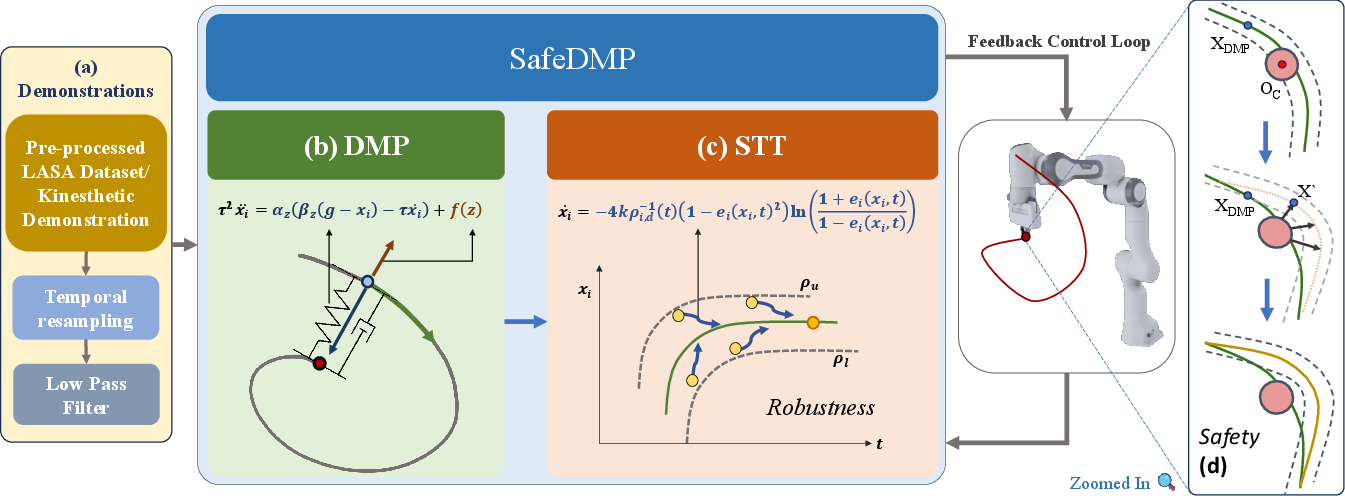
Figure 2: SafeDMPs pipeline—(a) demonstration capture, (b) DMP encoding, (c) STT envelope construction, (d) online trajectory deformation and safety enforcement.
The SafeDMP controller synthesizes DMP outputs with STT-based corrections, forming a new, closed-form dynamical system that inherits both robustness and provable safety:
τ2x¨=αz(βz(g−x)−τx˙)+f(z)+fSTT(z,x,O)
where fSTT ensures the end-effector always remains in the dynamically safe envelope as dictated by the currently perceived obstacle configuration.
Additionally, SafeDMPs adapt the temporal scaling parameter τ as a function of deviation from the nominal trajectory. When the robot deviates due to safety constraints, τ is increased (slowing the motion and facilitating recovery), and vice versa, leading to smooth and efficient convergence without abrupt transitions.
Experimental Validation
Simulation Environment
The framework was validated using a simulated 7-DOF Franka Emika Panda manipulator executing benchmark motion imitation and avoidance tasks within a 3D workspace containing both static and dynamic obstacles.
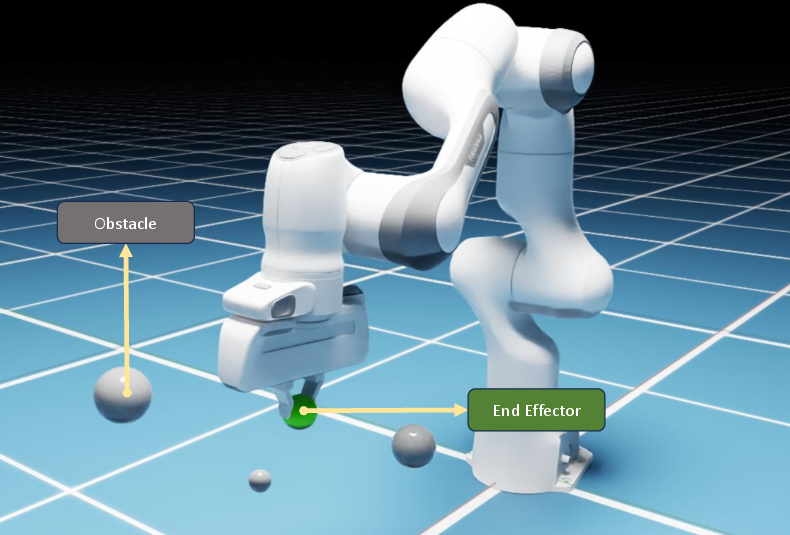
Figure 3: Simulation setup—Franka Panda performing tasks in an obstacle-rich workspace.
Evaluation Metrics
Key metrics include execution time per control step, memory footprint, mean absolute error (MAE) under nominal and perturbed conditions, and convergence time after obstacles/perturbations. SafeDMPs were compared against NODE-CLF-CBF (formal safety via optimization) and DMP-APF (DMPs with heuristic artificial potential fields).
Robustness to Perturbations
SafeDMPs exhibited bounded, monotonic recovery under impulsive disturbances, always reconverging to the nominal path significantly faster than NODE-CLF-CBF and with lower error compared to both baselines.
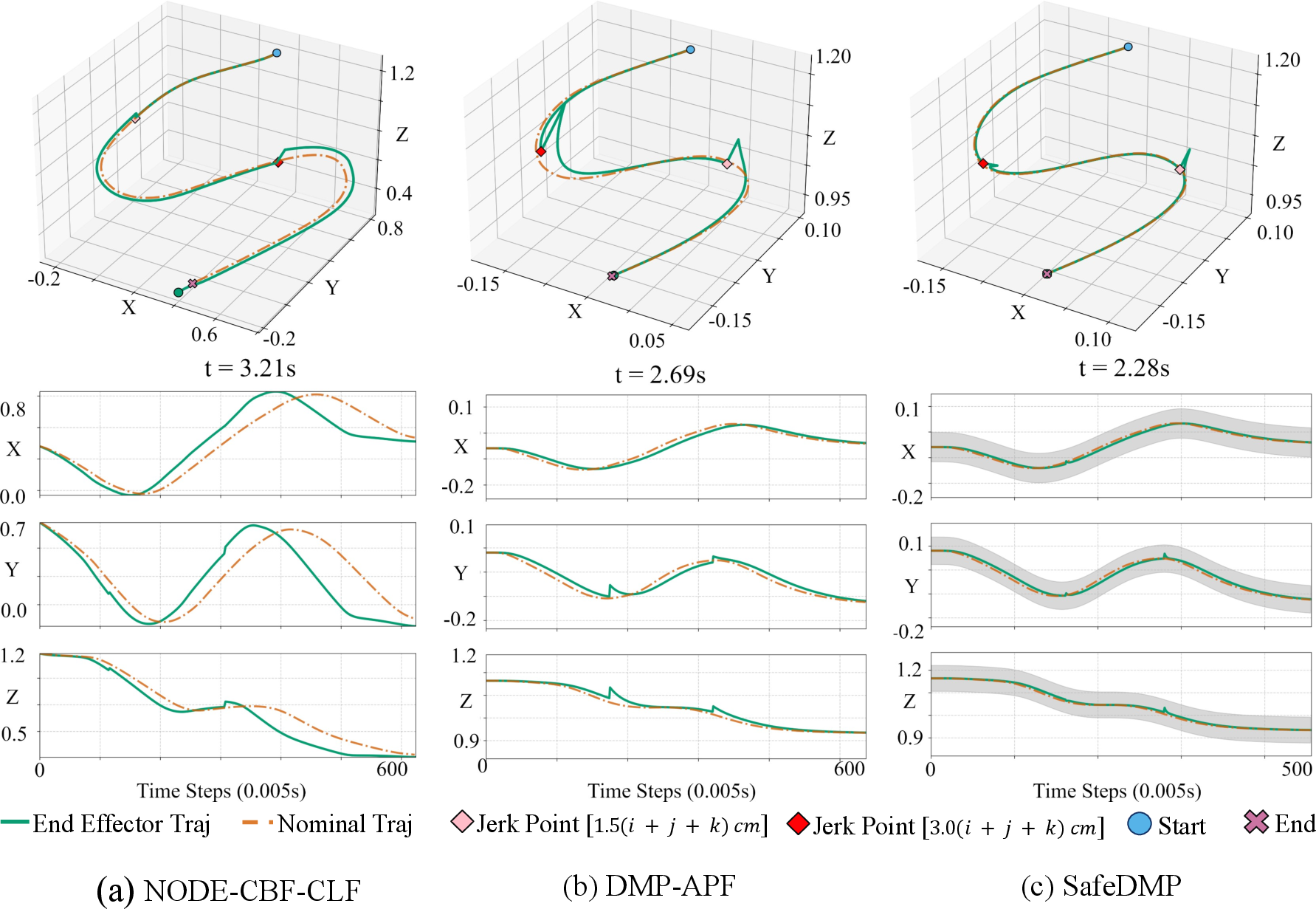
Figure 4: Perturbation response—SafeDMPs ensure bounded, rapid convergence under external disturbances.
Static Obstacles
SafeDMPs navigate around static obstacles with smooth, predictable trajectory deformation, maintaining explicit safety margins. In contrast, DMP-APF frequently suffers from oscillations and local minima, while NODE-CLF-CBF, though safe, exhibits minimum-clearance detours and occasionally non-smooth behaviors.
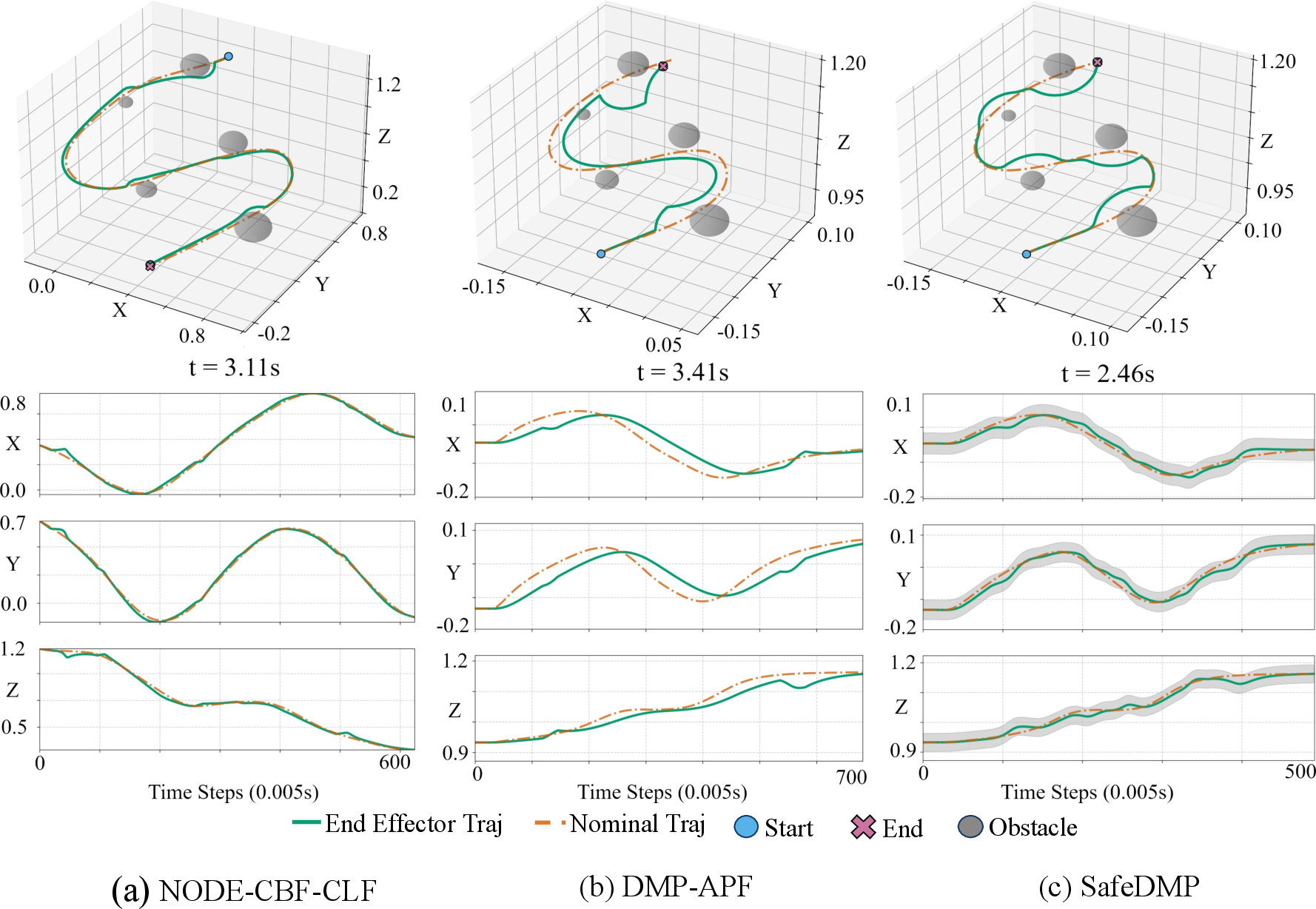
Figure 5: Trajectory evolution for static obstacle avoidance—SafeDMPs maintain margin and smoothness.
Dynamic Obstacles
SafeDMPs reliably avoid moving obstacles, modulating the envelope and rerouting the trajectory proactively. Other methods either risk collision or generate abrupt path deviations.
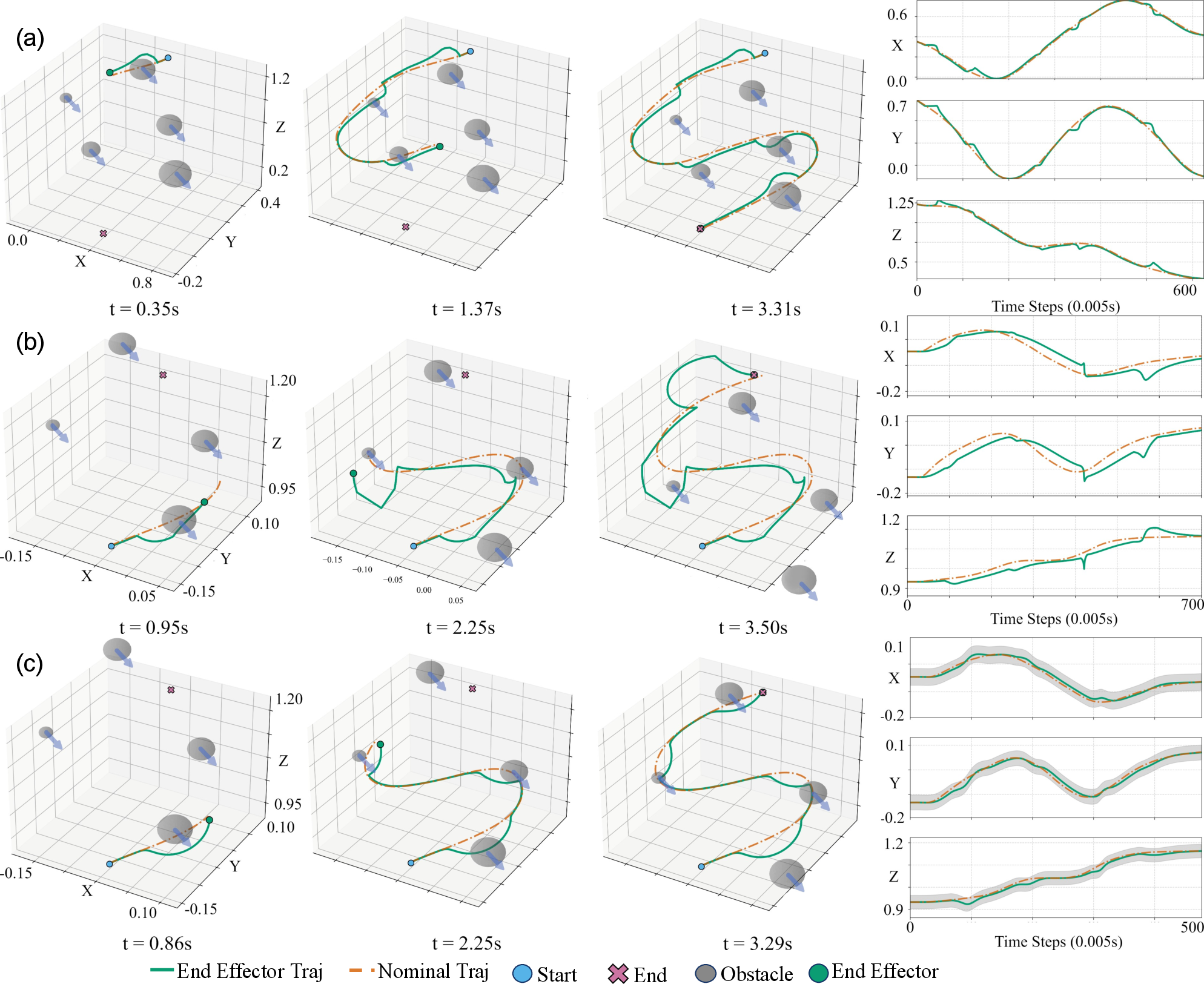
Figure 6: Obstacle avoidance with dynamic obstacles—SafeDMPs yield smooth, anticipatory maneuvers compared with baselines.
Hardware Results
On a physical Franka Robot, SafeDMPs were validated across diverse human-robot interaction scenarios:
- Pick-and-Place with human hand intrusion
- Assistive wiping with intermittent obstruction
- Cluttered whiteboard cleaning
The system adaptively maintained safety margins, avoided human contact, and reconverged to the nominal trajectory in all cases.
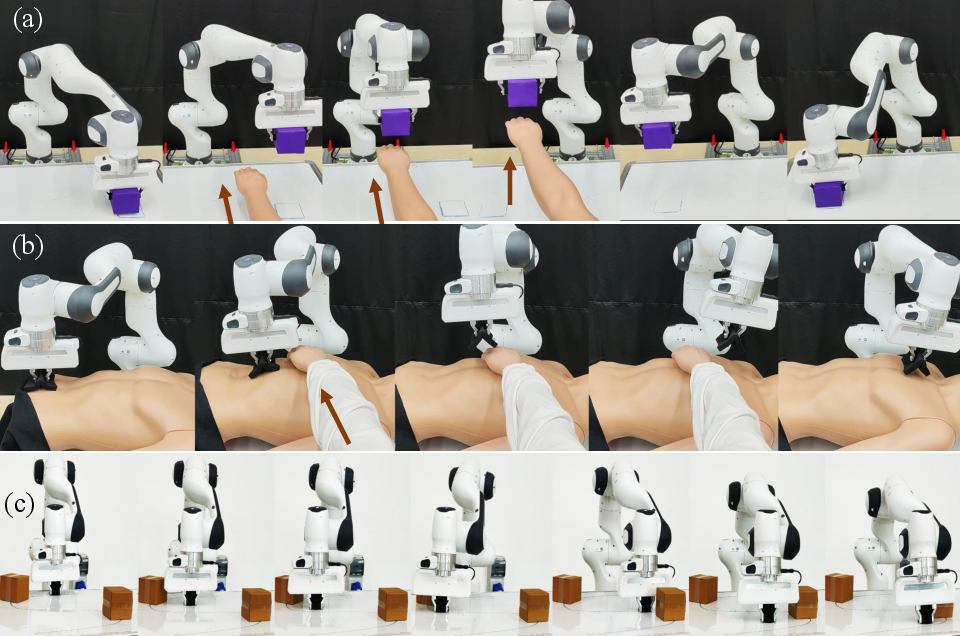
Figure 7: Hardware validation—(a) Pick-and-Place avoidance, (b) Assistive Wiping, (c) Whiteboard cleaning with clutter.
Implications and Future Prospects
SafeDMPs establish a compelling paradigm for practical, formally safe, and robust robot motion in interactive environments. The key implication is the elimination of runtime optimization for safety, dramatically improving real-time responsiveness, stability, and power efficiency, which are necessary for HRI and collaborative applications.
From a theoretical perspective, SafeDMPs offer a modular pathway to integrate other types of learning-from-demonstration (LfD) policies with closed-form, provable safety envelopes, suggesting new avenues for scalable, verifiable safe imitation learning. The framework suggests future extensions such as automated adaptive envelope reconfiguration, incorporation of whole-body safety constraints, and integration with spatio-temporal logic task planners.
Conclusion
SafeDMPs deliver a formally grounded, closed-form framework for generating robust and safe robot motions in dynamic, human-shared spaces. By tightly integrating DMPs with STT-based safety envelopes and adaptive timing, the method achieves several orders of magnitude improvement in computational speed and trajectory accuracy over optimization-based and heuristic baselines, while retaining strong guarantees of forward invariance and real-world applicability. The approach is poised to accelerate the deployment of collaborative robotics across assistive, industrial, and service domains where stringent safety and adaptability are non-negotiable.

