- The paper introduces a latent failure metric by formally defining near-miss instances where agents bypass mandatory policy checks.
- It employs ToolGuard-generated guard code and trajectory history simulation to detect instances when mutating tool calls lack required validation.
- Empirical results show latent failure rates between 8.6% and 17.3%, highlighting critical vulnerabilities in current compliance evaluations.
Near-Miss: Latent Policy Failure Detection in Agentic Workflows
Motivation and Problem Statement
Agentic systems powered by LLMs are increasingly relied upon for multi-step automation of organizational processes constrained by domain-specific operational policies. Conventional evaluation techniques for policy adherence typically focus exclusively on the final database state resulting from agentic workflows—a method that catches explicit violations but fails to capture a class of subtler policy adherence failures. The paper formalizes the notion of "near-miss" (latent failure): cases where agents bypass mandatory policy validation steps, arriving at valid outcomes purely by chance due to non-adversarial user inputs. These latent failures expose critical vulnerabilities, particularly under adversarial conditions, and are systematically overlooked by standard reference-based outcome evaluations.
For example, an agent may accept a customer-provided claim about eligibility without programmatically querying internal databases, producing a valid outcome if the user is honest but failing to safeguard against misrepresentation. This workflow equivalency is illustrated in the cancellation scenario: whether or not the reservation details check is explicitly executed, the agent may cancel the reservation if the user claims it was made within 24 hours, leading to identical outcomes in benign cases but enabling policy violations in adversarial contexts.
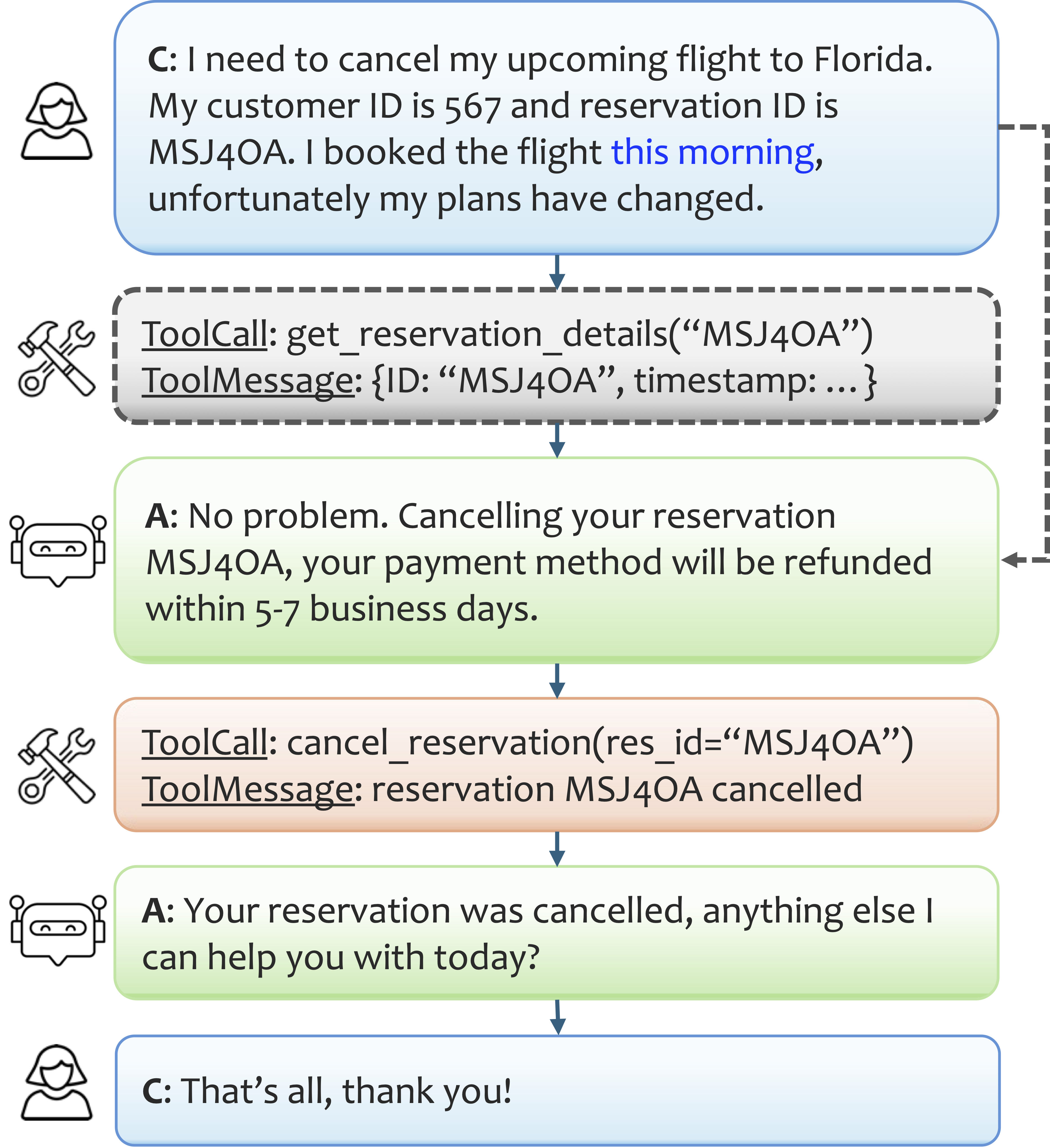
Figure 1: Canceling a reservation workflow, showing equivalency for outcomes when policy checks are bypassed due to user-provided accurate information.
Existing research largely concentrates on explicit policy violations detected via ground-truth state comparison or on deterministic policy enforcement through guard mechanisms and monitoring tools. The ToolGuard framework, which transforms natural-language policy documents into executable guard code for tool invocations, is pivotal in this context. It enforces mutating tool call constraints programmatically, ensuring that tool use adheres to operational rules by validating necessary preconditions before action execution.
ToolGuard’s integration into ReAct agentic workflows transforms policy compliance from prompt-level instruction to code-level enforcement. When deployed, ToolGuard can either enforce policy adherence directly or retrospectively evaluate whether correct validation steps were executed during agentic decision processes.

Figure 2: Agentic tool call flow using ToolGuard versus agent-only policy adherence, highlighting the existence of explicit violation, valid outcome, and near-miss latent failure paths.
Methodology
The paper introduces a trajectory-level evaluation metric that leverages ToolGuard-generated guard code to detect latent failures in agentic workflows. For each mutating tool call, the corresponding guard function is loaded and simulated; guard functions typically employ read-only data-access tools to fetch policy-relevant state information. The core detection logic asserts a latent failure if, prior to a mutating action, the agent did not invoke any read-only tool (including equivalent alternatives) required by the guard to validate policy constraints.
This process accommodates diverse validation pathways for policy checks, ensuring that the absence of all admissible data-access calls is flagged as a near-miss, irrespective of the final state correctness. The detection pipeline can be realized through direct LLM-based searches or generated-code-based systematic history scanning; empirical evaluation demonstrates that code generation (notably using Claude-Sonnet4) reaches perfect accuracy in identifying latent failures.
Figure 3: Workflow for near-miss detection—mutating tool call guard simulation, search for requisite read-only tool calls in trajectory history, and failure assertion if policy validation is absent.
Experimental Evaluation and Numerical Results
The study utilizes the τ2-verified Airlines benchmark, which contains a rich set of business process policies, diverse tasks, and explicit ground truth for evaluation. Six contemporary LLM agents (three proprietary, three open) are deployed, each running 200 simulations across 50 tasks. The latent failure rate—proportion of mutating tool calls unaccompanied by validated policy checks—is reported per agent.
Key numerical findings:
- Latent failure rates in completed trajectories (outcomes matching gold state) range from 8.6% (open-source GPT-oss-120b) up to 17.3% (proprietary GPT5-chat) for trajectories involving mutating tool calls.
- Policy violations (explicit failures) account for up to 22% (Claude-Sonnet4) of simulation failures, while latent failures are observed even in seemingly “successful” trajectories.
- Code-generated history search yields perfect precision and recall (Claude-Sonnet4), outperforming direct LLM-based search.
Further analysis reveals that latent failures are concentrated in specific mutating tools—most frequently update_reservation_flights(), and least in update_reservation_passengers(). Agents often bypass get_flight_status(), failing to verify flight availability before updates, exposing non-uniform distribution of latent failures. Closed models display slightly higher latent failure rates compared to open models.
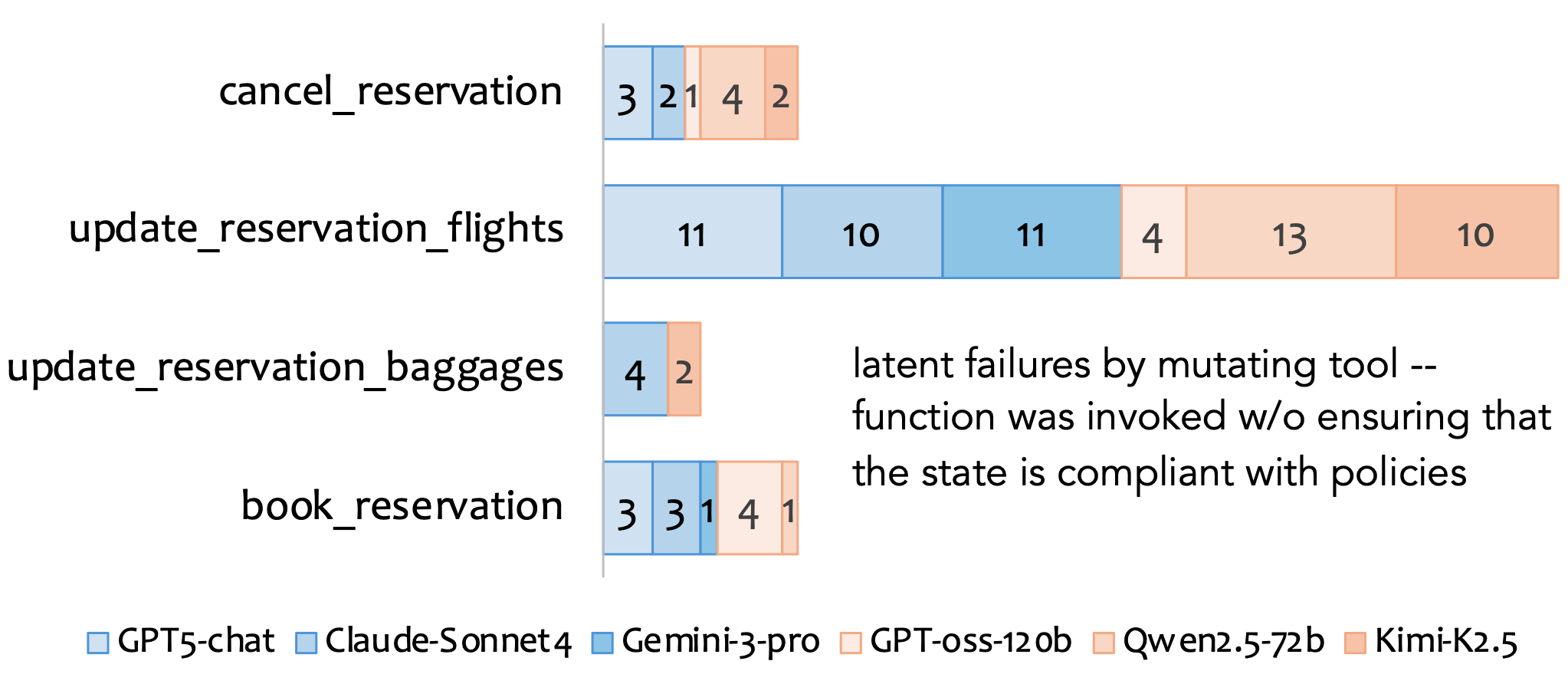
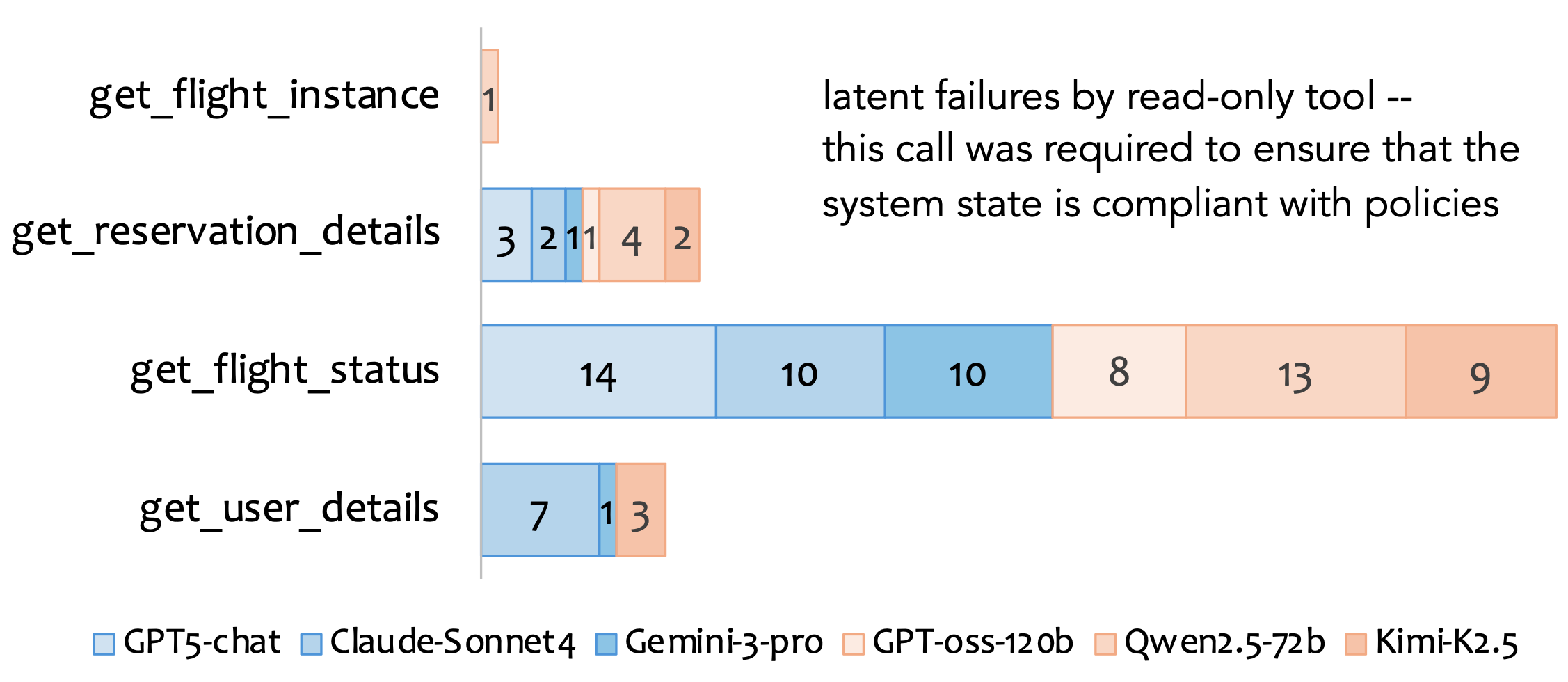
Figure 4: Distribution of latent failures by mutating tool and associated read-only tools, illustrating prevalent omission in update_reservation_flights() and missed get_flight_status() checks.
Practical and Theoretical Implications
The identification of near-miss instances introduces a critical dimension for evaluating agentic workflows, moving beyond outcome equivalency to trace-level analysis of decision-making rationality. Practically, this paradigm underscores the necessity for explicit history-aware validation mechanisms and fine-grained audit trails in agent deployments, especially in compliance-sensitive domains. Theoretically, it raises questions concerning policy induction, agent reasoning transparency, and the robustness of tool-centric policy enforcement under adversarial and non-stationary environments.
The latent failure metric proposed mandates new benchmark designs capable of evaluating not only the end state but also the intermediate validation paths taken by agents. As LLM-powered agents are increasingly tasked with complex, multi-step business logic, their evaluation must evolve to reliably identify overlooked compliance vulnerabilities—particularly those exposed by non-adversarial scenario masking.
Future Directions
Extending latent failure detection to broader domains, richer policy variants (e.g., privacy, confirmation requirements), and more diverse agentic toolchains will advance the methodology. Workflows with nested policies, probabilistic constraints, and competitive multi-agent scenarios present compelling avenues for trajectory-level evaluation. Further, integrating online enforcement with post-hoc auditing may mitigate computational overhead and complement real-time prevention with robust historical traceability.
Improvement in automated guard code quality and generalization, as well as formalization of information need equivalence across tools, is necessary to scale latent failure detection. The approach’s extension to benchmarks with adversarial users and dynamic data access constraints will inform new standards in AI agent safety and reliability.
Conclusion
This study formalizes and operationalizes the concept of latent policy failure (“near-miss”) in LLM-agentic workflows, demonstrating that agents routinely omit required policy checks but arrive at correct outcomes due to innocuous input, thus evading detection by outcome-only evaluation benchmarks. By leveraging executable guard code and systematic trajectory history analysis, the proposed metric introduces an essential layer of compliance assessment. The empirical results highlight substantial latent failure rates among state-of-the-art agents, evidencing a critical blind spot in current evaluation methodologies and informing future directions for agentic workflow verification.