- The paper reveals that approximately 54% of video benchmark samples can be solved via shortcut strategies, questioning genuine spatio-temporal evaluation.
- It introduces a systematic diagnostic suite that decouples visual and temporal cues using blind, audio, and temporal tests to isolate true video-native challenges.
- Empirical results show state-of-the-art models perform only marginally above chance on distilled tasks, underscoring the need for enhanced reasoning and adaptive training methods.
Video-Oasis: Systematic Diagnostic Audit of Video Understanding Benchmarks
Motivation and Problem Analysis
Despite the proliferation of video understanding benchmarks, the field suffers from critical ambiguities regarding whether evaluation gains are driven by genuine spatio-temporal visual reasoning, shallow text-based priors, or auxiliary knowledge. A primary issue identified is that existing benchmarks contain a significant proportion of tasks solvable without leveraging core video dependencies—either visual modality or temporal context—leading to artificially inflated model scores and masking the true limitations of current architectures.
As quantified using a diagnostic analysis suite, approximately 54% of benchmark samples across 14 curated datasets are solvable through shortcut strategies that bypass proper video and temporal understanding. State-of-the-art (SOTA) Video-LLMs, when restricted to samples where full video understanding is required, perform only marginally above chance (e.g., 27–47% for Gemini 2.5 Pro; random baseline ≈25%), indicating that true spatio-temporal reasoning remains elusive for current methods (Figure 1).
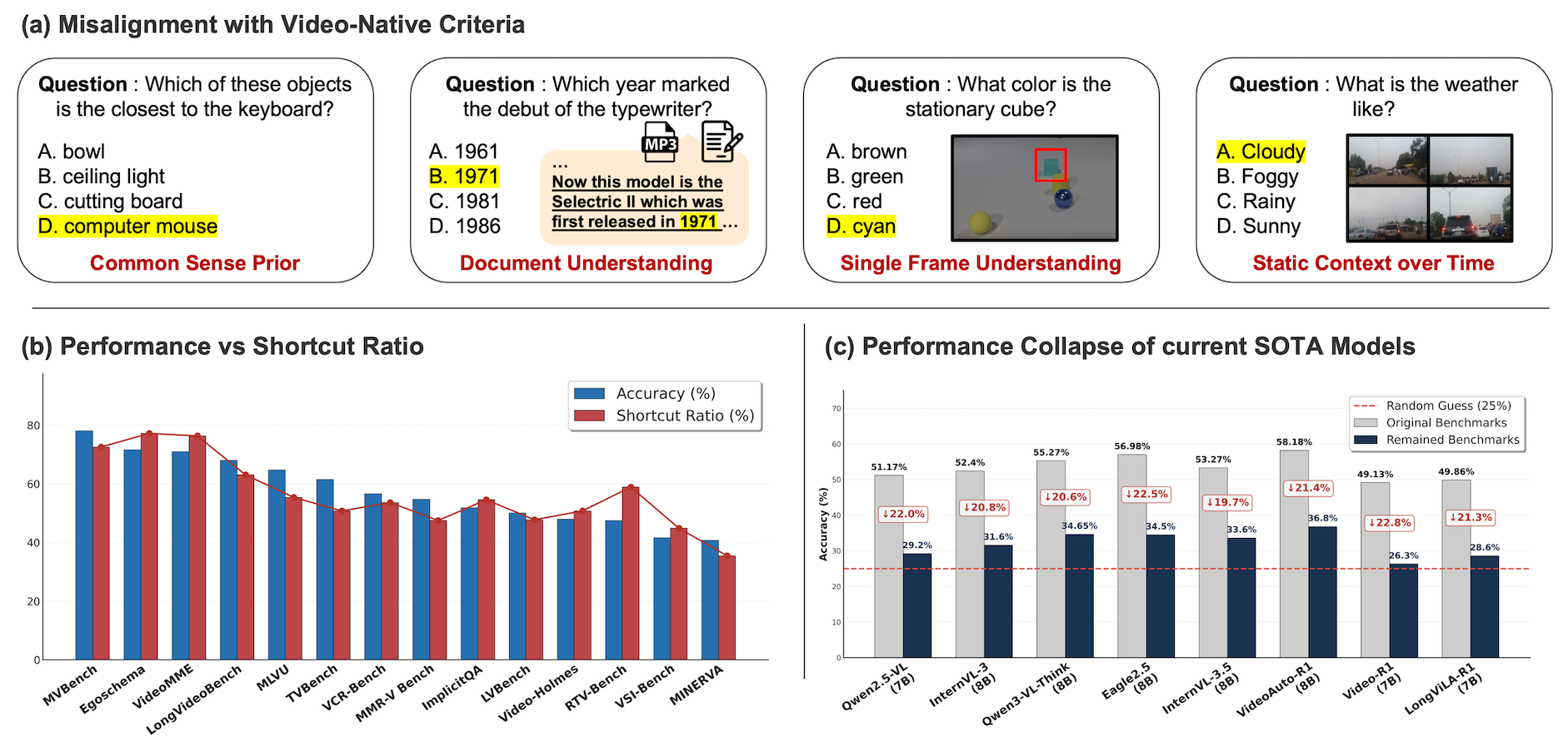
Figure 1: (a) Examples where video-QA instances can be solved without video understanding; (b) inflated video-QA scores with higher shortcut ratios; (c) SOTA models' drastic drop on video-native challenges, underscoring the difficulty of robust spatio-temporal understanding.
The Video-Oasis Diagnostic Suite
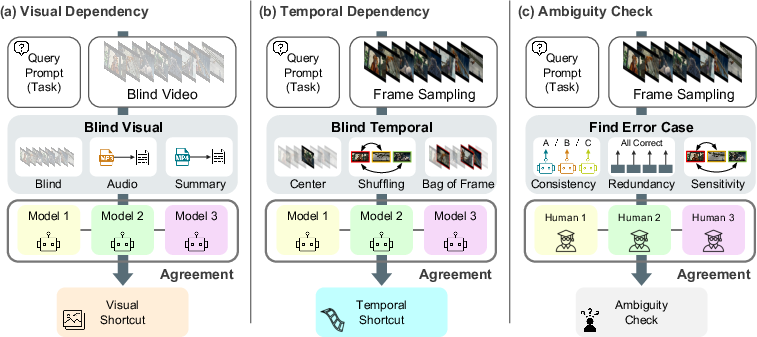
To address these deficits, Video-Oasis (V-Oasis) introduces a reproducible, model-agnostic diagnostic suite for auditing video benchmarks. The diagnostic process decomposes each sample by systematically decoupling visual and temporal dependencies and detecting tasks answerable via:
Ambiguities and annotation inconsistencies—such as redundancy (same answer from different video segments) and disagreement among multiple strong models—are detected via consensus analysis and manual human audit (Figure 3). Such ambiguity filtering is critical to avoid penalizing models for legitimate entailed alternatives or ill-posed queries.

Figure 3: (a) Redundancy/consistency-based annotation errors; (b) questions improperly filtered by temporal tests but requiring manual verification.
Distilled Video-Native Challenges
Post-diagnosis, V-Oasis isolates five core challenge categories essential to genuine video understanding:
- Fine-Grained Perception: Recognition/categorization requiring spatio-temporal evidence accumulation.
- Spatial World Understanding: Aggregating multi-view/contextual cues to infer scene geometry, 3D relationships, or navigation.
- Temporal Dynamics and Tracking: Maintaining temporal order for action/event recognition or object state changes.
- Causality and Logical Reasoning: Inferring underlying causes, intentions, or physical/logical dependencies beyond superficial frame matching.
- Global Narrative: Integrating information across long video horizons for summarization or semantic inference.
These challenges emerge as a data-driven taxonomy after filtering shortcut-prone samples, not as manually imposed categories but as the irreducible core of video tasks that persistently require true spatio-temporal modeling (Figure 4).
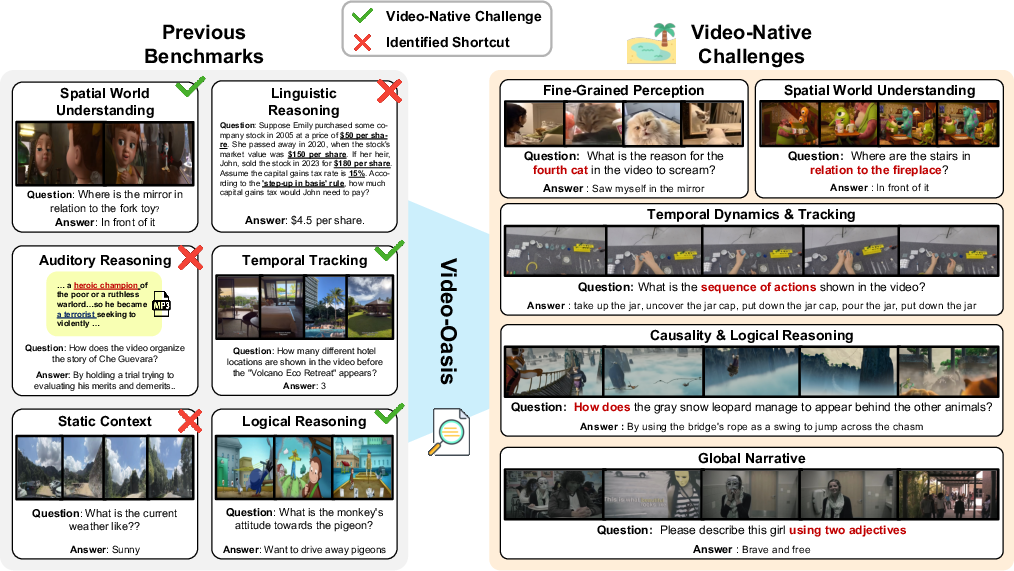
Figure 4: Video-native challenges extracted after shortcut removal, including temporal continuity, causal-interaction, and multi-event narratives.
Empirical Evaluation and Findings
Benchmark Analysis
From an initial 24,416 QA pairs (5,199 videos), V-Oasis filtering condenses the set to 11,332 samples (46%) that cannot be solved by shortcut strategies. Evaluation of SOTA models on this subset demonstrates:
- Even the frontier Gemini 2.5 Pro achieves only ~47% average accuracy.
- Open-source video-LLMs (Qwen3-VL, Eagle2.5) perform 25–37% on overall distilled challenges.
- Agentic systems (VideoTool, VideoTree), which orchestrate iterative reasoning and task decomposition, yield modest gains but do not close the gap.
- The deepest deficiency is on “Global Narrative” tasks, exposing the inability to sustain coherent aggregation over extended temporal sequences.
Quantitative Results
Comprehensive results under shortcut-suppressed (video-native) conditions show negligible advantage over random baselines for most models, revealing the fragility of high previous benchmarks scores. For example:
- On the Blind, Audio, or Narrative tests alone, MLLMs still achieve 30–50% accuracy (where random guessing is ~25%), confirming pervasive shortcut exploitation.
Algorithmic Analysis
Temporal Localization
Temporal localization—precisely mapping user queries to the correct temporal window in video—provides marginal performance improvements under realistic retrieval pipelines. However, with oracle (ground-truth) localization, model accuracy jumps significantly (by ~15% for distilled challenges), unlike in shortcut-prone samples. This implicates both the need for stronger grounding mechanisms and that current failures are not solely due to flawed selection of frames.
Reasoning Strategies and “When-to-Think”
Deeper chain-of-thought (“thinking mode”) reasoning, especially adaptive reasoning strategies that calibrate when and how much reasoning to apply (as opposed to always-on or always-off) is markedly more effective. Using an oracle voting ensemble (choosing the best between shallow and deep reasoning) approaches the performance of much larger proprietary LLMs, suggesting that dynamic modulation of reasoning is as determinant as model scale.
Training Paradigms
Supervised fine-tuning (SFT) with large-context optimization outperforms naïve RLVR (reinforcement learning with verifiable reward) on general spatio-temporal tasks, but RLVR provides greater benefit on "Global Narrative" categories, indicating complementary strengths and highlighting the open question of how to optimally balance or combine these strategies for holistic video understanding.
Qualitative Analysis
V-Oasis not only exposes benchmark fragility but provides a suite of qualitative cases that illustrate its diagnostic power:
- Revealing tasks that are solvable using world knowledge or biases without video input (Figure 5).
- Identifying cases where a single salient frame or permutation-invariant cues suffice, thus invalidating claims of temporal reasoning.
- Demonstrating truly video-native cases requiring comprehensive modeling, e.g., object tracking across occlusion, multi-event integration, or causal chaining (Figures 5–9).
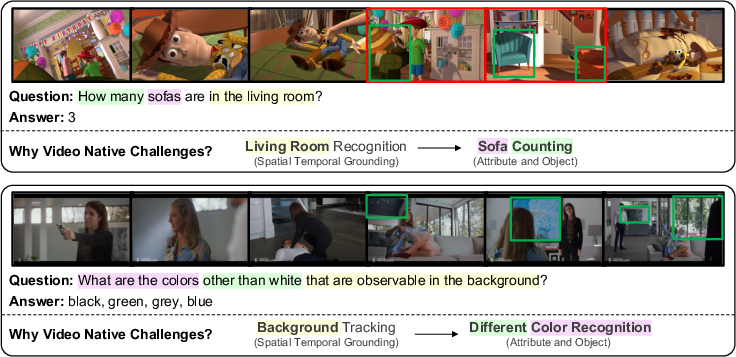
Figure 6: Examples requiring fine-grained, dynamic perception across space-time.

Figure 7: Tasks that demand composition and reasoning over 3D spatial context.

Figure 8: Explicit tracking of temporal object and event transitions.

Figure 9: Non-trivial causality and logical deduction scenarios.

Figure 10: Challenges with long-term global narrative aggregation.

Figure 5: Shortcut-problem samples identified via V-Oasis diagnostic filtering.
Implications and Future Directions
Practically, this work sets a new bar for reproducible, sustainable video understanding benchmark design. V-Oasis functions both as a diagnostic auditing toolkit for dataset creators and as a rigorous filter to challenge model developers. The presence of diagnostic shortcuts in even recent benchmarks emphasizes that reported progress may not translate to real-world perception-reasoning capacity.
Theoretically, the results support the hypothesis that genuine video understanding—i.e., robust, explainable, spatio-temporal reasoning and narrative integration—remains unsolved. V-Oasis further motivates a shift from brute-force scaling and shallow multimodal alignment toward research in:
- Integrated temporal grounding, not just context extension.
- Adaptive and model-internal regulation of reasoning effort.
- Targeted reward and supervision paradigms combining SFT and RLVR.
- Designing new benchmark samples and datasets that actively suppress and detect shortcut exploitation, ensuring evaluation strictly reflects core multimodal reasoning.
Conclusion
V-Oasis exposes that more than half of tasks in prominent video understanding benchmarks are answerable without full video dependency, leading to overestimated progress in the field. The diagnostic suite provides a methodology for probing, auditing, and filtering spurious sample types, thereby enabling precise measurement of model advances on the remaining hard core of spatio-temporal video-native challenges. Empirical ablation across input strategies, reasoning regimes, and training methods not only reveals current model limitations but also sets a roadmap for algorithmic and evaluation innovation, advocating for a paradigm shift towards truly holistic video understanding.
Reference
"Video-Oasis: Rethinking Evaluation of Video Understanding" (2603.29616)