- The paper presents the first diffusion-based classifier for FER that leverages Adaptive Margin Discrepancy Training.
- It employs a conditional diffusion framework that dynamically adjusts sample-wise margins to enhance class separation and robustness.
- Experiments demonstrate significant performance gains and strong cross-dataset generalization, even under adverse conditions.
Emotion Diffusion Classifier with Adaptive Margin Discrepancy Training for Facial Expression Recognition
Introduction and Motivation
This paper investigates the application of generative diffusion models, specifically the Stable Diffusion model, for facial expression recognition (FER), a shift from the prevailing discriminative paradigm. The authors introduce the Emotion Diffusion Classifier (EmoDC), leveraging diffusion-based generative modeling for robust FER in the wild. Discriminative classifiers, while achieving state-of-the-art FER accuracy, are highly susceptible to shortcut learning and adversarial vulnerability. Recent findings highlight that such classifiers rely disproportionately on spurious features, resulting in overconfident predictions and reduced robustness under distribution shift. By contrast, generative classifiers inherently capture core and spurious features jointly, yielding better out-of-distribution reliability.
EmoDC, the first diffusion-based classifier targeted at FER, adopts a conditional diffusion model and optimizes the model to distinguish between correct (“positive prompts”) and incorrect (“negative prompts”) category descriptions. However, standard denoising diffusion training strategies do not maximize the categorical margin and are insufficient for optimal performance. The paper’s primary contribution is the development of Adaptive Margin Discrepancy Training (AMDiT): a training approach that dynamically adjusts sample-wise margins to maximize separation between positive and negative pairs, addressing shortcomings in fixed-margin triplet-like learning objectives.
Diffusion Classifiers for FER
Diffusion models perform data generation via a two-stage process: the forward process incrementally corrupts an image with Gaussian noise, while the reverse process iteratively denoises to reconstruct an image. Conditional diffusion models can be converted into classifiers by evaluating the expected noise-prediction error for every class-conditioned prompt and selecting the class with the minimum error expectation.
Discriminative classifiers compute p(c∣x), whereas generative diffusion classifiers estimate p(x∣c) and use Bayes’ rule for prediction; the inference process, detailed in (Figure 1), entails class-conditional noise estimation over multiple timesteps and sampled noises.
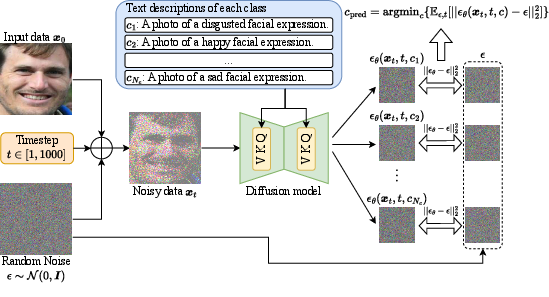
Figure 1: The diffusion classifier inference pipeline for FER; each category prompt conditions noise prediction across multiple timesteps to obtain a class prediction.
While class-conditional generative classifiers like diffusion models have demonstrated strong robustness and zero-shot generalization for natural images, their direct application to FER exhibits severe limitations due to the mismatch between the pre-trained model distribution (e.g., Stable Diffusion’s training on general images/text) and the FER domain. Moreover, the computation required for evaluating all class-prompted predictions across multiple timesteps makes diffusion classifiers orders of magnitude slower than discriminative alternatives.
Discrepancy and Margin-Based Training for Diffusion FER
The paper introduces several fine-tuning paradigms for bridge the gap between generative pretraining and discriminative FER performance:
- Contrastive Noise Discrepancy Training (CoDiT): This approach penalizes low noise-prediction error for negative prompts. While this boosts discriminative capacity over vanilla training, model improvement is limited by the instability and sensitivity to the weighting hyperparameter for negative-pair penalties.
- Margin-based Discrepancy Training (FMDiT): Inspired by triplet loss, this method enforces a fixed margin between noise-prediction errors for positive and negative prompts, increasing performance and stability. However, a static margin cannot adapt to the heterogeneous difficulty across FER samples.
- Adaptive Margin Discrepancy Training (AMDiT): Here, a dynamic, sample-wise margin is set proportional to the error on a non-negative prompt (e.g., the positive, null, or class-agnostic description), allowing the model to deploy higher margins for hard samples and lower ones for easy samples. This results in strong category separation, improved per-class balance, and rapid learning.
The AMDiT framework is visualized and compared to fixed margin alternatives in (Figure 2).
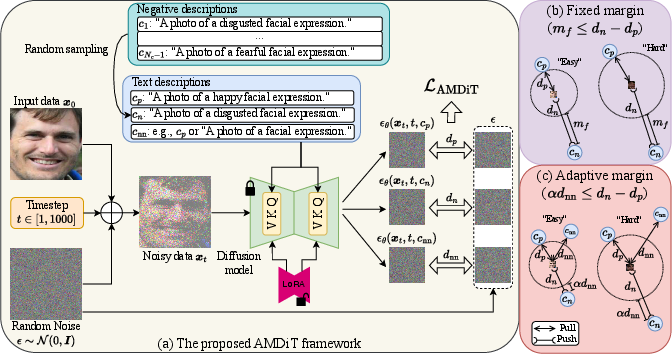
Figure 2: The proposed AMDiT method: (a) noise-prediction errors for different image-text pairs drive the sample-wise adaptive margin; (b) analysis of fixed versus adaptive margin strategies.
Analysis of noise-prediction error correlation between positive, negative, and non-negative prompts is presented in (Figure 3), demonstrating that non-negative errors provide a stable, sample-specific estimation of prediction difficulty, thus well-suited for adaptive margin calculation.
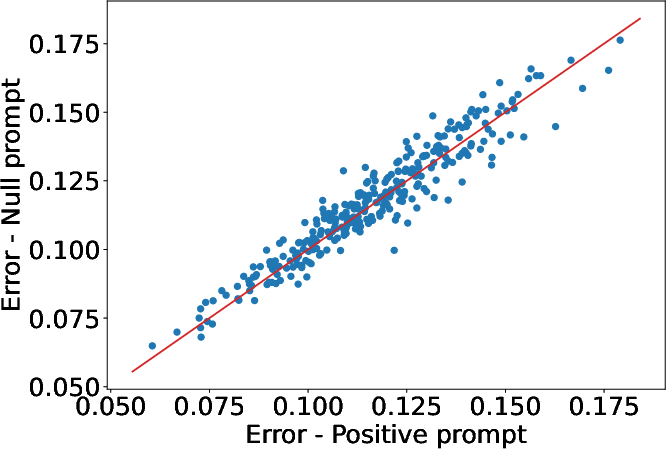
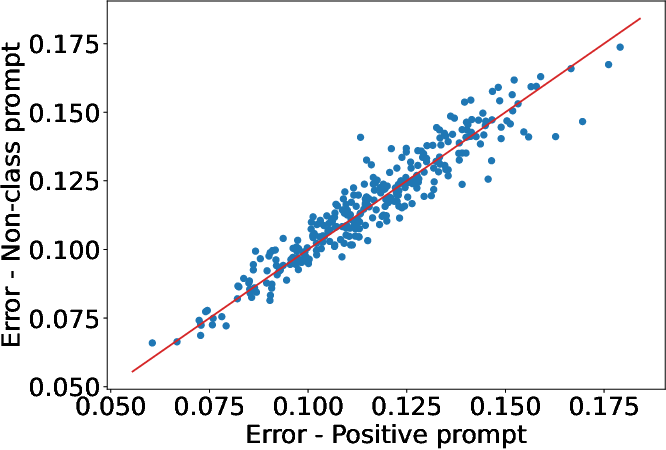
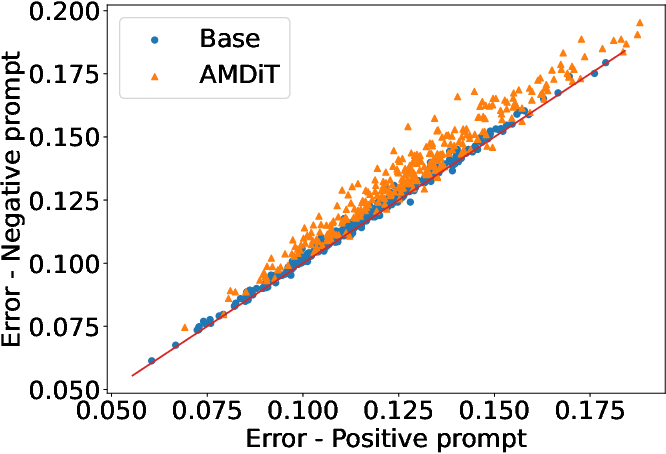
Figure 3: Positive vs. null/non-class prompt error correlations; linear relationship (slope =1) justifies using non-negative prompt errors as adaptive margins.
Experimental Results
The empirical evaluation spans four challenging facial expression datasets: RAF-DB (basic, compound), SFEW-2.0, and AffectNet. The authors conduct comprehensive ablations, margin analyses, confusion matrix studies, robustness tests, and cross-dataset generalization evaluations.
Incremental Ablation and Class Balance
AMDiT (with adaptive margins) consistently outperforms baseline fine-tuning, CoDiT, and FMDiT across all datasets, with gains of up to 16.3% on the compound RAF-DB set and significant boosts on challenging, low-resource datasets. The confusion matrices in (Figure 4) show improved mean class accuracy and reduced bias, especially for minority or difficult classes, when using AMDiT.
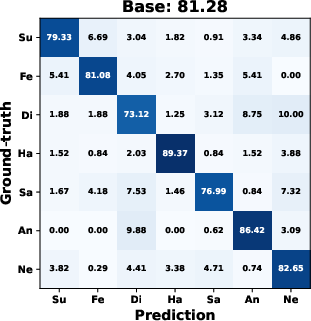
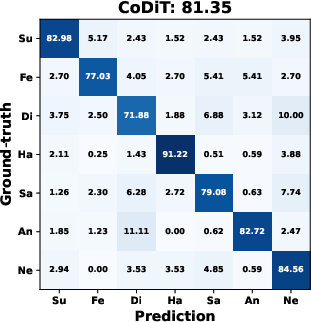
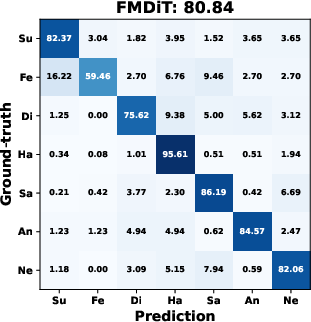
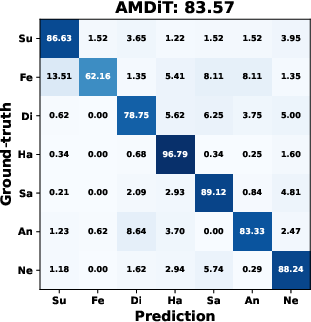
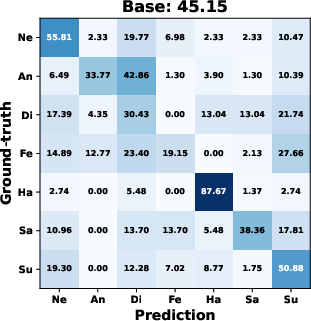
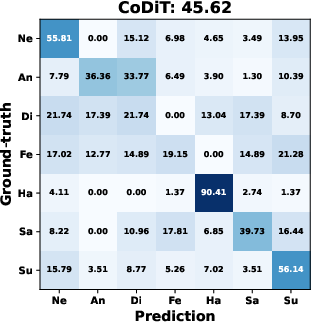
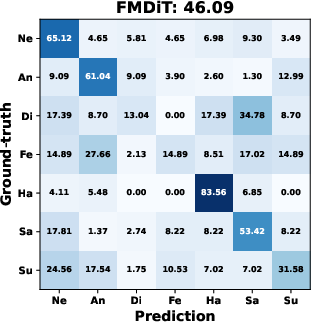
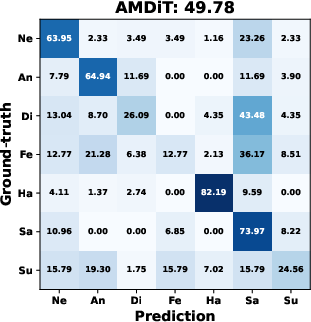
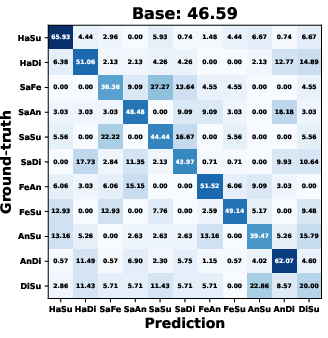
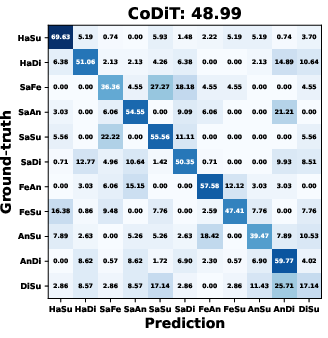


Figure 4: Confusion matrices for four EmoDC variants on three datasets in 100-step evaluation; AMDiT offers superior class balance and per-class accuracy.
Inference Speed and Robustness
Margin-based objectives—most notably AMDiT—dramatically narrow the accuracy gap between 1-step and multi-step (up to 1000-steps) inference, enabling high accuracy within a single iteration, as highlighted in (Figure 5). Consequently, real-time or near-realtime applications become tractable.
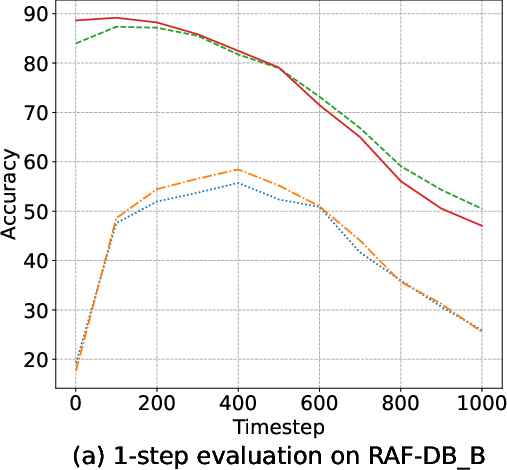
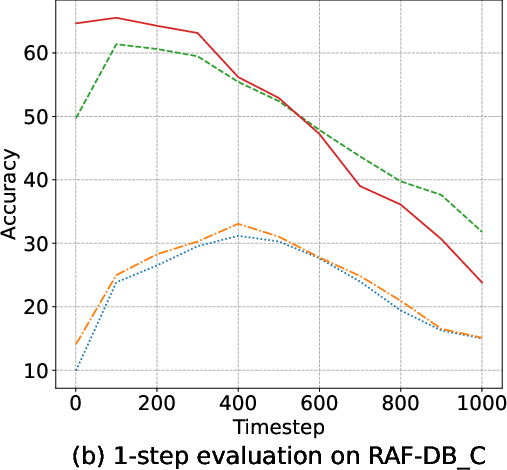
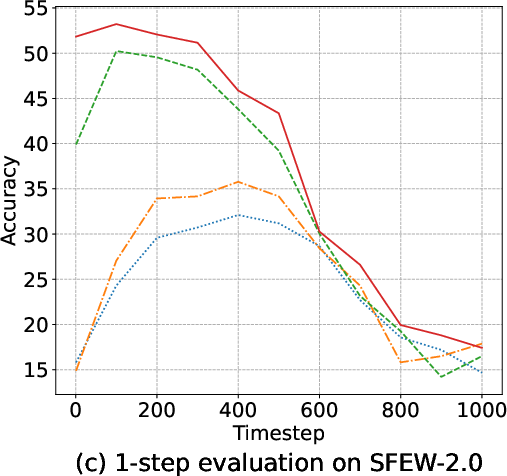
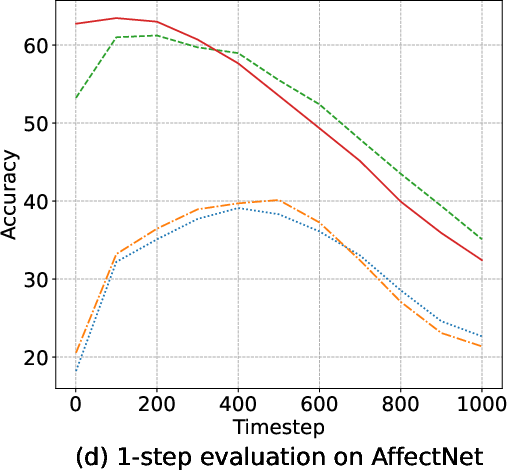
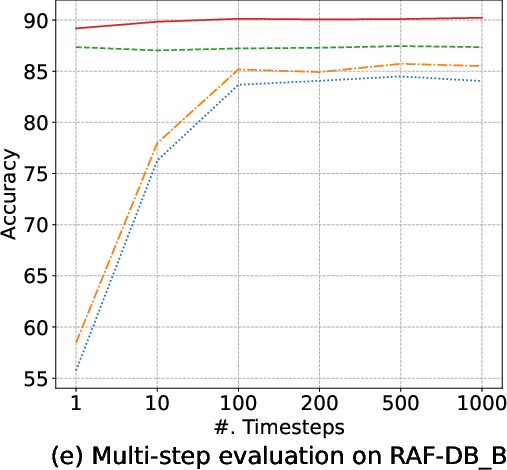
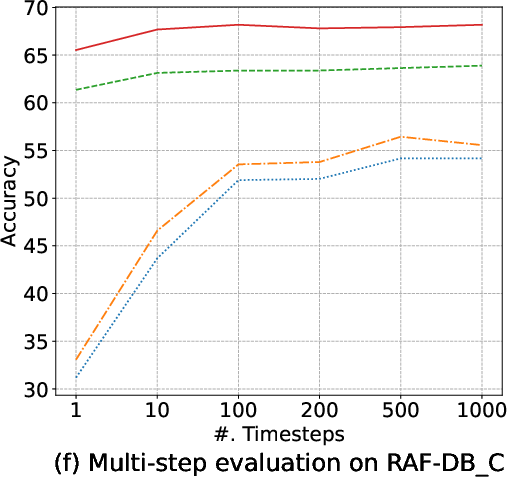
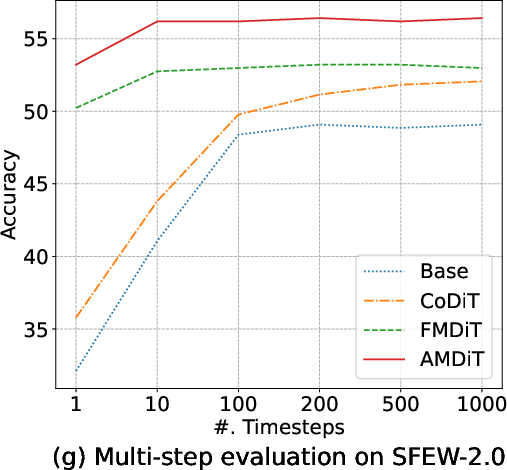
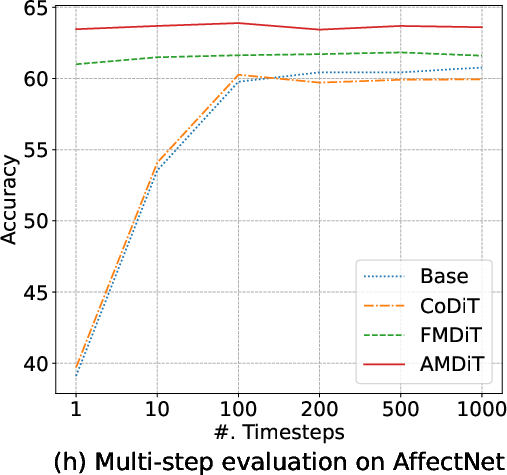
Figure 5: Accuracy of four EmoDC variants evaluated with varying numbers of inference steps across datasets; AMDiT nearly closes the 1-step vs. 100-step gap.
AMDiT-based models also deliver enhanced robustness against noise and blur, regularly surpassing SOTA discriminative models (e.g., POSTER, APViT) at higher perturbation levels. Unlike discriminative models, generative diffusion classifiers show gradual degradation rather than catastrophic failure.
State-of-the-Art Comparison
EmoDC with AMDiT achieves state-of-the-art results on the compound RAF-DB set and highly competitive accuracy on basic RAF-DB, SFEW-2.0, and AffectNet. While it trails the very best discriminative models (e.g., APViT, POSTER++) on some benchmarks, it excels in robustness and cross-dataset generalization. The classifier also displays shape bias, supporting findings in recent diffusion classifier studies.
Generalization and Generation
AMDiT-trained EmoDC generalizes better than discriminative peers when evaluated in a cross-dataset setup, reflecting improved domain robustness. Importantly, the generative nature of EmoDC enables faithful synthesis of diverse facial expressions (Figure 6), which aids model interpretability, data augmentation, and understanding of learned facial affect representations.

Figure 6: Samples of facial expression images generated by EmoDC with AMDiT, demonstrating expressivity and fidelity across emotion categories.
Implications and Future Directions
The paper demonstrates that diffusion-based generative models, when equipped with margin-driven discriminative objectives, provide strong, robust, and interpretable alternatives for FER. In contrast to discriminative SOTA models, EmoDC with AMDiT delivers reliable recognition under various real-world corruptions and superior generalization to unseen data distributions.
Nevertheless, the increased computational cost of diffusion-based inference—principally due to larger backbone size and the requirement for multiple class-conditional passes—remains a limitation for many applications. Real-time FER is viable with optimized, single-step evaluation, but further research on model distillation, efficient sampling, and backbone scaling is warranted.
The generalization of AMDiT to other domains, especially multi-modal or continuous affect recognition, and its extension to temporal/video-based diffusion classifiers, are promising avenues for future research. Finally, integrating co-optimized generation and recognition heads in a unified generative model could enable synergistic advances across data synthesis and robust classification.
Conclusion
This work establishes the effectiveness of generative diffusion classifiers, specifically the Emotion Diffusion Classifier with Adaptive Margin Discrepancy Training, for robust, high-accuracy facial expression recognition. AMDiT bestows powerful discriminative capacity while preserving the generative interpretability and robustness of the diffusion paradigm. The study opens new perspectives for the deployment of generative models in vision-understanding systems, rendering them not only competitive with but in many respects superior to conventional discriminative models under real-world conditions.