MemFactory: Unified Inference & Training Framework for Agent Memory
Abstract: Memory-augmented LLMs are essential for developing capable, long-term AI agents. Recently, applying Reinforcement Learning (RL) to optimize memory operations, such as extraction, updating, and retrieval, has emerged as a highly promising research direction. However, existing implementations remain highly fragmented and task-specific, lacking a unified infrastructure to streamline the integration, training, and evaluation of these complex pipelines. To address this gap, we present MemFactory, the first unified, highly modular training and inference framework specifically designed for memory-augmented agents. Inspired by the success of unified fine-tuning frameworks like LLaMA-Factory, MemFactory abstracts the memory lifecycle into atomic, plug-and-play components, enabling researchers to seamlessly construct custom memory agents via a "Lego-like" architecture. Furthermore, the framework natively integrates Group Relative Policy Optimization (GRPO) to fine-tune internal memory management policies driven by multi-dimensional environmental rewards. MemFactory provides out-of-the-box support for recent cutting-edge paradigms, including Memory-R1, RMM, and MemAgent. We empirically validate MemFactory on the open-source MemAgent architecture using its publicly available training and evaluation data. Across both in-domain and out-of-distribution evaluation sets, MemFactory consistently improves performance over the corresponding base models, with relative gains of up to 14.8%. By providing a standardized, extensible, and easy-to-use infrastructure, MemFactory significantly lowers the barrier to entry, paving the way for future innovations in memory-driven AI agents.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MemFactory: A simple explanation for teens
What is this paper about?
This paper introduces MemFactory, a “build-it-like-Lego” toolkit for teaching AI assistants how to remember and use information over time. Instead of being just chatbots that forget past conversations, these AIs keep notes, update them, and pull them back when needed—like a student with a well-organized notebook. MemFactory gives researchers a single, easy place to plug in memory parts, train them with feedback, and test how well they work.
What questions are the researchers trying to answer?
In plain terms, the paper asks:
- How can we make it much easier to build AI agents that remember important things over long periods?
- Can we train these agents to manage their memory (what to save, what to delete, what to use) using rewards—like practicing a game and getting points for good moves?
- Can one common toolkit support different memory styles from recent research, so people don’t have to rebuild everything from scratch each time?
How did they build and test it?
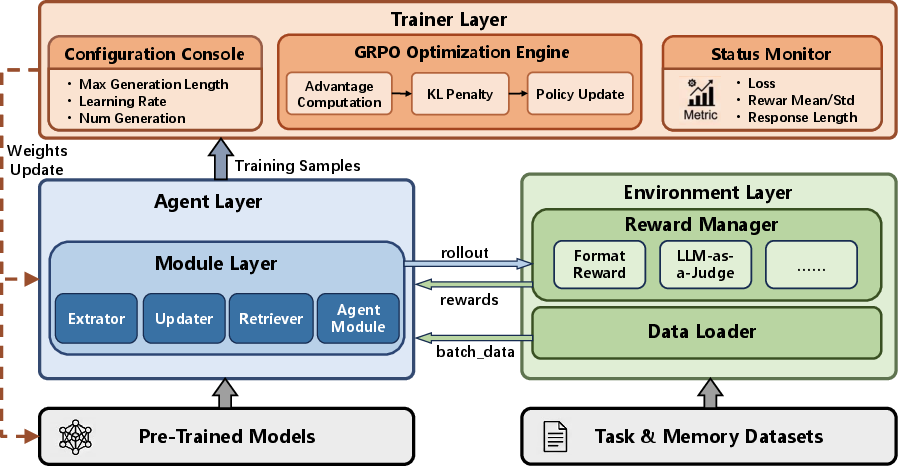
The team designed MemFactory as a unified framework with four main parts. Think of it like organizing a workshop with clear stations:
- Module Layer: Small “tools” that do core memory jobs:
- Extractor: pulls useful facts from a conversation (like highlighting key points in a textbook).
- Updater: decides to add, delete, or change a memory (like editing your notes).
- Retriever: finds the most relevant memory when answering (like flipping to the right page).
- Agent Module: an all-in-one option for memory styles that update and use memory in one go.
- Agent Layer: Puts the tools together into a full AI “worker” that runs the memory strategy.
- Environment Layer: Feeds in tasks and judges the agent’s actions with rewards (scores), both for long-term memory banks and very long conversations.
- Trainer Layer: Teaches the agent using a reinforcement learning method called GRPO.
What is reinforcement learning (RL)? It’s like training a player in a game: the AI tries actions, gets rewards if the outcome is good, and learns to make better choices next time. Here, the “game” is memory management—when to extract, update, or retrieve.
What is GRPO (Group Relative Policy Optimization)? Imagine you try several answers to the same question and then compare each answer to the group average. You learn from what did better or worse than the group without needing a separate “judge model.” This saves computing power and still gives clear signals about which choices were good.
They also made MemFactory work out-of-the-box with several popular memory approaches from other papers:
- Memory-R1: treats memory like a database you can add to, update, or delete from.
- MemAgent: keeps a compact “state” that summarizes the past, so it doesn’t need to read everything again.
- RMM: focuses on better picking and ranking which memories to use.
For testing, they used MemAgent-style agents and trained them with two open-source LLMs (Qwen3-1.7B and Qwen3-4B-Instruct). They evaluated on:
- “In-domain” tests (similar to training tasks)
- “Out-of-distribution” tests (different from training tasks, like surprise questions)
Everything ran on a single high-end GPU, showing that the setup is practical and reproducible.
What did they find, and why does it matter?
The key result: training memory behavior with MemFactory improved performance.
- With the smaller model (Qwen3-1.7B), the average score improved by about 14.8%.
- With the larger model (Qwen3-4B-Instruct), the average score improved by about 7.3% and was more consistent—even on surprise (OOD) tests.
Why this matters:
- It shows that a single, unified toolkit can make complex memory training easier and still deliver better results.
- It proves that reinforcement learning (with GRPO) can effectively teach an AI when and how to store or use memory.
- It lowers the barrier for researchers to experiment, mix, and match memory strategies without heavy engineering.
What’s the bigger impact?
MemFactory could speed up progress in building smarter, long-term AI assistants—ones that remember useful facts, keep notes tidy, and personalize over time. By making the “memory brain” easy to assemble and train, it helps researchers focus on new ideas instead of rebuilding basic parts. Over time, this could lead to AI that’s more helpful in tutoring, customer support, planning, and personal assistants that truly remember what matters to you.
Knowledge Gaps
Unresolved knowledge gaps, limitations, and open questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved in the paper, framed to guide future research:
- Limited empirical scope: only the MemAgent-style recurrent memory policy is evaluated; no experiments validate MemFactory on the other “out-of-the-box” agents (Memory-R1, RMM) despite claiming support.
- Algorithmic comparison missing: GRPO is the only RL algorithm implemented/evaluated; there is no head-to-head comparison with PPO, REINFORCE, DPO/RLHF hybrids, or critic-free alternatives under identical settings.
- Reward design opacity: the paper mentions “multi-dimensional rewards” (Format Rewards and LLM-as-a-Judge) but does not specify exact reward definitions, weighting, normalization, or how module-level credit is assigned within a trajectory.
- Credit assignment across modules: it remains unclear how GRPO advantages are attributed to specific atomic operations (extract/update/retrieve) in multi-step pipelines, or how delayed task rewards are backpropagated to individual memory decisions.
- Sensitivity to GRPO hyperparameters: no ablations on group size G, sampling temperature, advantage normalization, or KL penalties to assess training stability and sample efficiency for long-horizon memory tasks.
- Exploration strategy: the framework does not describe exploration mechanisms (e.g., entropy bonuses, top-k/top-p sampling choices) or their effects on policy learning in memory-intensive settings.
- Evaluation breadth: only MemAgent datasets are used; generalization to other memory tasks (e.g., knowledge-intensive QA, multi-session personalization, tool-augmented agents) is untested.
- OOD robustness gap: the 1.7B model shows a performance drop on the OOD set; there is no analysis of why, nor strategies to mitigate overfitting or improve transfer (e.g., curriculum learning, regularization, data augmentation).
- Lack of statistical rigor: results are averaged over four trials but report no confidence intervals, significance tests, or variance across random seeds; robustness claims are therefore uncertain.
- Training data alterations: contexts are shortened to one-third the original length for efficiency, which may change task difficulty; the impact of this change on validity and comparability to prior work is not evaluated.
- Baseline completeness: there is no comparison to original MemAgent training pipelines, heuristic memory baselines, or non-RL fine-tuning (e.g., SFT/DPO) within MemFactory to isolate the contribution of GRPO.
- Module-level ablations: no experiments show how swapping extractors/updaters/retrievers affects performance, limiting evidence for the claimed “Lego-like” benefits and guiding principles for module selection.
- Reward model reliability: reliance on LLM-as-a-Judge is not audited for bias, drift, or prompt sensitivity; no calibration against human judgments or generative reward models is provided.
- Long-horizon credit leakage: the framework does not address potential temporal credit assignment issues in very long contexts (e.g., whether early extraction errors are correctable and how).
- Memory quality diagnostics: there is no analysis of memory bank health over time (redundancy, contradiction rates, decay, versioning), nor tools/metrics to quantify memory consolidation quality.
- Robustness to noise and adversaries: the framework does not study memory poisoning, conflicting information, low-quality retrievals, or adversarial prompts, and offers no defenses (e.g., trust scoring, provenance tracking).
- Scalability limits: latency, throughput, and memory footprint for large banks/contexts are not reported; the impact of FlashAttention-2 and vLLM on end-to-end agent latency is unmeasured.
- Cost of reranking with LRMs: the RerankRetriever uses LRMs but the compute and cost trade-offs versus simpler rerankers (bi-encoders, cross-encoders) are not quantified.
- Vector database and storage back-ends: the framework abstracts retrieval but does not evaluate or integrate diverse storage/indexing options (e.g., HNSW, FAISS, disk-backed stores) or their impact on training/inference.
- Multi-modal and tool-augmented memories: the design’s applicability to non-text modalities (vision/audio) or tool outputs (APIs, code) remains unexplored.
- Non-stationary environments: how MemFactory handles evolving user profiles, shifting reward functions, or changing knowledge bases (continual learning) is unspecified.
- Safety, privacy, and compliance: there is no discussion of PII handling, retention policies, redaction, or compliance safeguards in long-term memory agents.
- Interpretability and controllability: the framework lacks mechanisms to introspect, edit, or constrain memory operations (e.g., human-in-the-loop approvals, rule constraints, or explanations for add/update/delete).
- Reproducibility details: training time, wall-clock costs, exact seeds, and hardware variability are not reported; claims of “reproducible on a single A800 80GB” need broader hardware validation.
- Benchmark standardization: no unified, public benchmark suite or evaluation protocol for memory agents is proposed to enable cross-paper comparisons using MemFactory.
- Extensibility beyond discrete operations: the module interfaces target discrete CRUD/retrieval steps; support for differentiable or continuous memory representations (e.g., key-value differentiable memory, recurrent state spaces) is unclear.
- Hierarchical or multi-agent policies: the framework does not address hierarchical RL for multi-level memory control or shared memory policies across collaborating agents.
- Catastrophic forgetting and stability: there is no study of whether fine-tuning memory policies via GRPO induces forgetting of base model capabilities or destabilizes generation quality.
- Deployment readiness: guidance on productionization (caching, streaming updates, online learning, monitoring drift) and operational best practices is absent.
Practical Applications
Below is an overview of practical, real-world applications derived from the MemFactory framework, its methods, and its empirical findings. The items are grouped into immediate and longer-term opportunities, with sector linkages, potential tools/workflows, and feasibility notes.
Immediate Applications
- Standardized research and prototyping for memory-augmented agents
- Sectors: academia, AI labs, AI tooling vendors
- Tools/workflows: out-of-the-box agents (MemoryR1Agent, MemoryAgent, MemoryRMMAgent); Module/Agent/Environment/Trainer layers; GRPO-based trainer; SwanLab dashboards; Transformers + FlashAttention-2 + vLLM
- Assumptions/dependencies: access to open LLM checkpoints (e.g., Qwen3), single-GPU or similar compute; availability of long-context datasets; basic RL expertise; reliable reward functions (format checks, LLM-as-a-judge)
- Rapid reproduction and benchmarking of Memory-RL baselines
- Sectors: academia, evaluation platforms, enterprise AI research
- Tools/workflows: MemoryBankEnv and LongcontextEnv for standardized dataloading/rewards; plug-and-play extract/update/retrieve modules; avg@4 evaluation; OOD test sets
- Assumptions/dependencies: community adoption of common metrics; careful prompt/reward design to avoid reward hacking
- CX chatbots with consistent, deduplicated long-term memory
- Sectors: software (customer support), e-commerce, telecom
- Tools/workflows: NaiveExtractor + NaiveUpdater to maintain concise memory banks; RerankRetriever to improve retrieval precision; integration with CRM and ticketing systems
- Assumptions/dependencies: privacy compliance (GDPR/CCPA), user consent; secure storage (encryption, access control); domain-specific reward signals (e.g., resolution/CSAT proxies)
- Enterprise knowledge copilots that remember projects and decisions
- Sectors: enterprise productivity, knowledge management, project management
- Tools/workflows: MemAgent-style RecurrentMemoryModule for fixed-length, recurrent state across sessions; role-based access control; A/B testing of updater policies via Lego-like module swaps
- Assumptions/dependencies: integration with enterprise systems (wikis, code repos, docs); information security and SSO; policy for retention and deletion (DEL operation)
- Retrieval-augmented generation (RAG) pipelines with RL-tuned reranking and memory hygiene
- Sectors: developer tools, internal search, documentation assistants
- Tools/workflows: RerankRetriever with LRM reranking as a post-retrieval stage; updater-driven deduplication and conflict resolution; vector DB or knowledge graph backends
- Assumptions/dependencies: availability and cost of LRM or strong reranker; latency budgets; retrieval evaluation signals (clicks, citations, exact-match)
- Data-labeling-lite optimization for memory policies
- Sectors: startups, SMEs, internal AI teams
- Tools/workflows: GRPO with rule-based and LLM-as-a-judge rewards to fine-tune memory extraction/update/retrieval without dense human labels
- Assumptions/dependencies: judge reliability and calibration; safeguards against exploitation of judge prompts; periodic human audits
- Personal productivity agents with cross-session memory
- Sectors: consumer productivity, email/calendar assistants
- Tools/workflows: inference-only agents assembled from MemFactory modules; lightweight memory bank for contacts, tasks, preferences; updater-driven “forgetting” policies
- Assumptions/dependencies: user consent and local-first storage when possible; on-device or edge inference constraints; simple rewards (task completion, reminders success)
- Education pilots: tutors that track learner progress and misconceptions
- Sectors: education technology
- Tools/workflows: MemoryBankEnv to store learner profiles; retrieval/reranking for lesson content; GRPO rewards from quiz outcomes and rubric scores
- Assumptions/dependencies: aligned curricula; COPPA/FERPA compliance; bias monitoring across student subgroups
- Evaluation harness for product teams
- Sectors: product analytics, MLOps
- Tools/workflows: map business KPIs (resolution rate, time-to-answer) into reward functions; SwanLab tracking; A/B tests by swapping modules and hyperparameters
- Assumptions/dependencies: careful KPI-to-reward translation; offline replay vs. online RL choice; guardrails for customer-facing experiments
- Cost-efficient single-GPU RL fine-tuning for memory behaviors
- Sectors: broad (SMEs, independent researchers)
- Tools/workflows: GRPO (no critic) to reduce memory footprint; batch padding/masking routines provided by MemFactory’s Trainer
- Assumptions/dependencies: stable reward distributions; hyperparameter tuning; reproducibility across GPUs/models
Long-Term Applications
- Consumer assistants with multi-month, privacy-preserving memory at scale
- Sectors: consumer software, smart home
- Tools/workflows: advanced Updater policies (ADD/UPDATE/DEL/NONE) that enforce retention schedules and forgetting curves; MemOS-style orchestration
- Assumptions/dependencies: longitudinal datasets; scalable storage; robust privacy controls (user dashboards, revocation APIs); evaluation beyond short horizons
- Clinical assistants that maintain longitudinal patient context
- Sectors: healthcare
- Tools/workflows: MemoryBankEnv integrated with EHR; retrieval over structured medical knowledge graphs; RL-tuned memory policies anchored to clinical outcomes
- Assumptions/dependencies: HIPAA/GDPR-H; clinical validation and safety; bias and fairness audits; model risk management
- Compliant financial advisors with auditable client memory
- Sectors: finance/wealth management, insurance
- Tools/workflows: structured CRUD with audit trails; DEL operations for “right to be forgotten”; RL rewards tied to suitability checks and compliance rules
- Assumptions/dependencies: regulatory approval (SEC/FINRA), documentation for audits; robust red-teaming and adversarial testing
- Long-horizon memory for autonomous robots and embodied agents
- Sectors: robotics, logistics, manufacturing
- Tools/workflows: extend Agent/Module layers to multimodal memory (sensor, vision); RL in simulated/real environments; retrieval from maps/task graphs
- Assumptions/dependencies: multimodal model support; real-time constraints; safety/reliability in physical settings; sample-efficient reward design
- Lab and R&D assistants that track experiments, hypotheses, and findings
- Sectors: pharmaceuticals, materials, academic research
- Tools/workflows: structured memory schemas aligned with ELNs; Updater rules to resolve conflicting results; OOD generalization checks
- Assumptions/dependencies: integration with lab instruments/LIMS; factual grounding and provenance; human-in-the-loop review
- Memory governance standards and policy toolkits
- Sectors: policy/regulation, compliance, standards bodies
- Tools/workflows: MemFactory as a testbed for retention/deletion/right-to-be-forgotten policies; policy-driven reward shaping; transparency reporting
- Assumptions/dependencies: consensus on definitions and metrics of “memory quality” and “harm”; cross-jurisdictional alignment
- Shared organizational memory for multi-agent collaboration
- Sectors: enterprise collaboration, project management, software engineering
- Tools/workflows: concurrent MemoryBankEnv with access control, versioning, and conflict resolution; RL for retrieval under multi-user constraints
- Assumptions/dependencies: database design for concurrency; identity and permissions; clarity on ownership and traceability
- Reward modeling for memory quality at scale
- Sectors: AI research, platform providers
- Tools/workflows: replace LLM-as-a-judge with learned Generative Reward Models tailored to memory (faithfulness, utility, recency); GRPO/VERL-like training stacks
- Assumptions/dependencies: curated datasets for reward model training; compute resources; methods to prevent reward misspecification
- Edge/on-device personal memory agents
- Sectors: mobile, IoT, automotive
- Tools/workflows: quantized small LLMs; low-footprint GRPO or periodic federated updates; encrypted local memory stores
- Assumptions/dependencies: device compute and energy limits; privacy-preserving telemetry; efficient update schedules
- Cross-modal, lifelong memory for assistive and creative tools
- Sectors: accessibility, education, media/creative software
- Tools/workflows: extend extractors/retrievers to images/audio/video; unified memory schemas across modalities; multimodal rewards
- Assumptions/dependencies: strong multimodal base models; datasets spanning modalities and long horizons; evaluation protocols
- Safety-first memory policies (sensitive data avoidance and selective forgetting)
- Sectors: security, compliance, public sector
- Tools/workflows: safety classifiers integrated into Updater to prevent storing sensitive PII; RL penalties for retaining prohibited content; automated deletion workflows
- Assumptions/dependencies: reliable detection of sensitive content; explainability/auditability; alignment with legal definitions
- Community benchmarks and leaderboards for memory agents
- Sectors: academia, industry consortia, evaluation platforms
- Tools/workflows: standardized MemFactory tasks/environments (in-domain and OOD); long-horizon metrics and robustness tests
- Assumptions/dependencies: broad adoption; maintenance of datasets and metrics; neutral hosting and governance
These applications leverage MemFactory’s core innovations—modular “Lego-like” memory operations, unified environments and rewards, and compute-efficient GRPO—to lower engineering barriers and accelerate real-world deployment of memory-augmented agents across sectors. Feasibility hinges on responsible reward design, privacy/compliance, dataset availability, and integration with production-grade storage and MLOps.
Glossary
- Advantage (RL): The estimated benefit of an action over a baseline in policy-gradient methods, used to weight updates. "Specifically, the advantage for the -th candidate with reward is calculated as:"
- Agent Layer: The component that composes modules and executes the policy to produce interactions. "The Agent Layer builds upon the Module Layer and serves as the central policy executor"
- Agent Module: A module type that encapsulates end-to-end memory policies without separate extract/update phases. "we introduce an additional Agent Module class within this layer."
- Answer Agent: A model component trained to transform or distill memory into answers or summaries. "and an Answer Agent for memory distillation."
- AutoClasses (Transformers): Factory utilities from Hugging Face Transformers to automatically load model/tokenizer classes. "we use AutoClasses from the Transformers library"
- Baseline (policy gradient): A reference value subtracted from rewards to reduce variance in gradient estimates. "estimates the baseline through intra-group reward normalization."
- CRUD operations: Discrete data-management actions—Create, Read, Update, Delete—used here for memory editing. "discrete CRUD operations (e.g., ADD, UPDATE, DELETE)"
- DAPO: A reinforcement-learning optimization method (mentioned as Multi-Conversation DAPO) used to learn memory overwrite policies. "It employs Multi-Conversation DAPO to learn an optimal ``overwrite'' policy"
- Direct Preference Optimization (DPO): An alignment algorithm that optimizes models directly from pairwise preferences. "alignment algorithms (e.g., SFT, DPO)"
- Environment Layer: The component that prepares data into states and computes reward signals for the agent. "The Environment Layer serves as the interface between the agent and the task."
- Exact-match reward: A rule-based reward that grants credit when outputs exactly match targets. "particularly when optimizing rule-based or outcome-driven rewards (e.g., exact-match or LLM-as-a-judge scores)"
- FlashAttention-2: An optimized attention algorithm that accelerates and reduces memory use for long-sequence transformers. "we integrate FlashAttention-2"
- Format Rewards: Reward signals that assess whether model outputs follow a prescribed structure or format. "including Format Rewards and LLM-as-a-Judge evaluations."
- Group Relative Policy Optimization (GRPO): A PPO-style algorithm that removes the value model by normalizing rewards within sampled groups. "MemFactory natively integrates Group Relative Policy Optimization (GRPO) to fine-tune the agent's internal memory management strategies"
- Intra-group reward normalization: The technique of normalizing rewards across a sampled group to compute advantages without a critic. "estimates the baseline through intra-group reward normalization."
- Large Reasoning Models (LRMs): Models specialized for complex reasoning, used here to rerank retrieved memories. "the RerankRetriever leverages Large Reasoning Models (LRMs) to re-evaluate and rerank the initially retrieved memories"
- LLM-as-a-Judge: An evaluation paradigm where an LLM scores model outputs for quality or correctness. "including Format Rewards and LLM-as-a-Judge evaluations."
- LLM attribution signals: Signals indicating whether retrieved content influenced the model’s output, used as supervision. "It leverages unsupervised LLM attribution signals (i.e., whether a retrieved memory was actually cited)"
- Memory bank: A persistent, updatable store of extracted facts and experiences for long-term use. "ensuring that the memory bank remains concise and highly accurate during prolonged user interactions."
- Memory Extractor: A component that parses raw context to produce structured memory entries. "The primary function of the memory extractor is to parse the raw contexts into structured memory pieces."
- Memory Retriever: A component that fetches relevant memories from the memory bank to condition responses. "The memory retriever is tasked with fetching the most relevant memory from the memory bank"
- Memory Updater: A component that compares candidate memories with existing ones and decides how to modify the store. "the updater assigns one of four operations to manage the memory states"
- MemAgent: A recurrent-memory paradigm that treats memory as a latent state and learns overwrite policies via RL. "MemAgent \cite{yu2025memagent}"
- Memory-R1: A framework that trains a memory manager to execute discrete memory operations with RL. "Memory-R1 \cite{yan2026memoryr1}"
- Memory-RL: The use of reinforcement learning to optimize memory extraction, updating, and retrieval in agents. "unique paradigm of Memory-RL."
- Module Layer: The layer that defines standardized, plug-and-play atomic memory operations. "The Module Layer operates as the fundamental core of the framework"
- Out-of-distribution (OOD): Data that differs from the training distribution, used to test generalization. "one out-of-distribution (OOD) dataset (eval_fwe_16384)."
- Parameter-Efficient Fine-Tuning (PEFT): Techniques that fine-tune small subsets of parameters or adapters rather than the full model. "Parameter-Efficient Fine-Tuning (PEFT)"
- Proximal Policy Optimization (PPO): A popular on-policy RL algorithm using clipped objectives and typically a value critic. "While Proximal Policy Optimization (PPO) is the prevailing algorithm"
- REINFORCE algorithm: A Monte Carlo policy-gradient method that updates policies using sampled returns. "via the REINFORCE algorithm."
- Retrieval-Augmented Generation (RAG): A method that retrieves external context to ground generative model outputs. "static Retrieval-Augmented Generation (RAG) paradigms"
- Retrospective Reflection: A retrieval refinement approach that updates retrieval policies by reflecting on whether memories were cited. "via ``Retrospective Reflection.''"
- Reranker: A lightweight model that reorders retrieved candidates based on relevance signals. "update a lightweight reranker online via the REINFORCE algorithm."
- Reranking: A post-retrieval process that reorders candidates to improve precision. "Reranking is a widely adopted post-retrieval technique"
- RerankRetriever: A retriever variant that applies a reranking step to initial retrieval results. "we also provide the RerankRetriever."
- Recurrent state: A latent vector carried across segments to summarize and compress long histories. "treats a fixed-length latent memory variable as a recurrent state across text segments."
- RecurrentMemoryModule: An implementation of end-to-end recurrent memory policies following the MemAgent design. "we implemented the RecurrentMemoryModule following its design."
- Rollout trajectories: Sequences of states, actions, and rewards generated by the agent for training. "enabling researchers to seamlessly construct custom memory agents via a ``Lego-like'' architecture. Furthermore, the framework natively integrates Group Relative Policy Optimization (GRPO) to fine-tune internal memory management policies driven by multi-dimensional environmental rewards." [Note: use a more direct occurrence:] "and generate rollout trajectories during interaction."
- Sample efficiency: The effectiveness of learning from limited sampled trajectories or rewards. "while maintaining high sample efficiency"
- SFT (Supervised Fine-Tuning): Fine-tuning on labeled input-output pairs to align model behavior. "alignment algorithms (e.g., SFT, DPO)"
- SwanLab: A training monitoring and visualization toolkit integrated into the framework. "natively integrates SwanLab"
- Trainer Layer: The optimization engine that applies GRPO to fine-tune memory policies. "The Trainer Layer serves as the core optimization engine"
- vLLM: A high-throughput LLM inference engine optimized for efficient serving. "such as vLLM"
- Value network (critic): The model that estimates the expected return for states or state-actions in actor–critic methods. "it requires an auxiliary value network (critic) comparable in size to the policy model."
- VERL: A specialized library for scalable RL pipelines supporting high-throughput training. "specialized libraries like VERL \cite{Sheng_2025} offer high-throughput infrastructures specifically optimized for large-scale Reinforcement Learning (RL) pipelines."
Collections
Sign up for free to add this paper to one or more collections.