- The paper introduces a token-level perplexity analysis to assess if LLMs rely on genuine linguistic cues rather than spurious shortcuts.
- It employs minimal pairs and computes plain and normalized proportions to quantify the contribution of pivotal tokens in language tasks.
- Results indicate that high benchmark accuracy often masks reliance on non-transparent heuristics, challenging standard evaluation methods.
Interrogating LLM Behavioral Validity via Token-Level Perplexity Analysis
Introduction
The standard paradigm for evaluating LLMs relies heavily on benchmark accuracy, often using minimal pairs that differ by a few targeted linguistic features. However, this protocol is agnostic as to whether models leverage the intended linguistic mechanisms or adopt spurious, task-specific shortcuts. The paper "Is my model perplexed for the right reason? Contrasting LLMs' Benchmark Behavior with Token-Level Perplexity" (2603.29396) introduces a principled interpretability methodology grounded not in post-hoc feature attribution (which is known to be unstable and sometimes misleading), but instead in a direct token-level analysis of changes in model perplexity across minimal pairs. The framework aims at elucidating whether LLMs' correct outputs in controlled benchmarks arise for linguistically appropriate, token-centric reasons, or instead reflect unidentified heuristics.
Methodology
The proposed approach begins with minimal pairs—matching sentences differing only in a few "pivotal" tokens (as established by the benchmarks' controlled design). The authors define two target behavioral criteria for LLMs:
- The model should assign lower sequence-level perplexity (PPL) to the linguistically correct/minimally perturbed member of each pair.
- The difference in sequence-level PPL (ΔPPL) should be largely or entirely attributable to the pivotal tokens that define the linguistic phenomenon in question.
To operationalize the second criterion, the authors compute both "plain proportion" and "normalized proportion" metrics: these quantify the share of total ΔPPL explained by the pivotal tokens compared to all others, and normalize for sentence length and effect directionality.
This approach is executed across four open-weight LLMs (Gemma3-4B, Mistral0.3-7B, Llama3.2-3B, Qwen2.5-7B) and five tasks—ranging from artificial nonsense-word controls to naturalistic phenomena (BLiMP anaphor/animacy, CrowS-Pairs stereotypes, DUST ambiguity/underspecification).
Empirical Findings
Sanity Checks and Controlled Tasks
On the nonsense words task, where all context is noise except for one inserted real word, pivotal tokens explain nearly the entire difference in perplexity distribution between the minimal pairs, as intended.
Figure 1: Pivotal tokens in the nonsense-word task are the primary drivers of ΔPPL, although rarely reaching the maximum theoretical value due to contextual perturbations on rare tokens.
Fine-Grained Linguistic Contrasts
For natural language benchmarks (e.g., BLiMP animacy/anaphor, stereotypes, DUST), the framework exposes substantial divergence from the formal linguistic expectation: pivotal tokens explain at most ∼50% of the perplexity difference (never all), and at times, punctuation or other non-pivotal tokens absorb significant explanatory variance.
Figure 2: On BLiMP animacy, pivotal tokens explain a larger share of perplexity shift than other tokens, but only up to ∼50%.
Figure 3: In BLiMP anaphor agreement, pivotal tokens' contribution saturates below 50\%, with periods also attracting nontrivial PPL shifts.
Figure 4: Stereotype-controlling nouns in CrowS-Pairs explain only a part of the PPL shift, with periods and context tokens participating unexpectedly.
Ambiguity and Context Sensitivity
The DUST ambiguity task is an outlier: here, pivotal tokens approach full explanation of perplexity differences, indicating that certain tasks with strong local cues more successfully isolate the intended mechanism.
Figure 5: In DUST, pivotal tokens are almost entirely accountable for ΔPPL—the only setting where this holds consistently.
Benchmark Accuracy vs. Token-Level Analysis
A critical and contradictory finding is the lack of correlation between correct benchmark classification and explanation by pivotal tokens. LLMs can achieve high accuracy while relying on patterns outside the hypothesized linguistic features—a direct challenge to the assumption that benchmark performance equates to true linguistic competence.
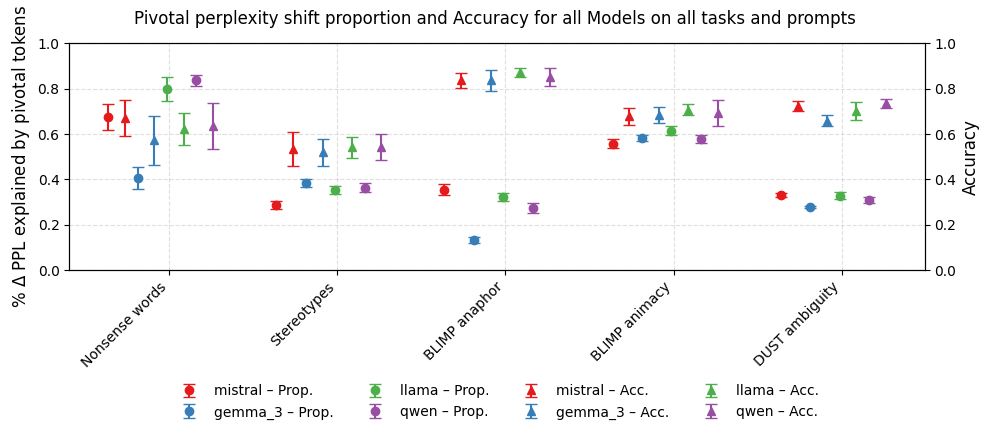
Figure 6: Aggregate results showing discrepancies between accuracy and the proportion of ΔPPL explained by pivotal tokens.
Implications
Interpretability and Alignment
The study demonstrates that conventional sequence-level evaluation can occlude key details about model operation: achieving high accuracy on controlled linguistic tasks does not imply reliance on the specified linguistic mechanisms. Incorporating token-level PPL analysis provides a diagnostic for determining if and when LLMs depend on the correct tokens for their decisions—vital for alignment and robust generalization. This framework can help expose when models rely on confounding secondary cues or dataset artifacts.
Task and Model Dependency
Results exhibit that the ability to attribute perplexity differences to pivotal tokens is highly task-dependent. For tasks with more diffuse or distributed cues (stereotypes, animacy), LLMs' behavior is less localized, suggesting implicit reliance on global heuristics or non-transparent interaction effects, even in models with otherwise strong benchmark performance.
Architectural and Training Insights
The findings suggest limitations in current training paradigms for LLMs, where global objectives and large training corpora may encourage extraction and use of features that are statistically robust but not linguistically transparent. Token-level PPL analysis can serve as a regularization or diagnostic signal in training regimes emphasizing interpretability or controllability.
Limitations and Future Directions
The study is limited to a subset of LLM architectures and narrowly construed benchmarks that afford explicit identification of pivotal tokens. Tasks where linguistic cues are distributed or contextually entwined may not align with the current framework. Also, the analysis is contingent on the definition and identification of pivotal tokens, which may be non-trivial for more complex linguistic phenomena.
Further research could extend token-level perplexity analysis to broader families of models, incorporate alternative local interpretability metrics (e.g., surprisal, attention attribution networks), and test whether integrating such analyses during training can systematically suppress reliance on non-transparent heuristics. There is also open potential for meta-benchmarking: evaluating the degree of token-level transparency across a family's benchmarks or languages as a formal property of models.
Conclusion
This paper provides robust evidence that LLM performance on controlled linguistic benchmarks does not reliably indicate the use of linguistically appropriate mechanisms as measured by token-level perplexity. The application of plain and normalized proportion metrics reveals non-trivial reliance on non-pivotal tokens, even when accuracy is high, thereby challenging the validity of accuracy-based conclusions regarding LLM linguistic understanding. The proposed interpretability framework constitutes a valuable tool for model audit and alignment, and indicates avenues toward more principled evaluation practices in LLM development (2603.29396).