BuildArena: A Physics-Aligned Interactive Benchmark of LLMs for Engineering Construction
Abstract: Engineering construction automation aims to transform natural language specifications into physically viable structures, requiring complex integrated reasoning under strict physical constraints. While modern LLMs possess broad knowledge and strong reasoning capabilities that make them promising candidates for this domain, their construction competencies remain largely unevaluated. To address this gap, we introduce BuildArena, the first physics-aligned interactive benchmark designed for language-driven engineering construction. It contributes to the community in four aspects: (1) a highly customizable benchmarking framework for in-depth comparison and analysis of LLMs; (2) an extendable task design strategy spanning static and dynamic mechanics across multiple difficulty tiers; (3) a 3D Spatial Geometric Computation Library for supporting construction based on language instructions; (4) a baseline LLM agentic workflow that effectively evaluates diverse model capabilities. On eight frontier LLMs, BuildArena comprehensively evaluates their capabilities for language-driven and physics-grounded construction automation. The project page is at https://build-arena.github.io/.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces BuildArena, a new “obstacle course” for testing whether LLMs—smart AIs that read and write text—can build working machines and structures from plain English instructions while obeying real-world physics. Think of it like asking an AI to “build a car,” “make a bridge,” or “launch a rocket,” and then checking if those creations actually work in a realistic virtual world.
What questions did the researchers ask?
The team wanted to know:
- Can LLMs turn words into working 3D designs that follow physics?
- What kinds of building tasks are easy or hard for today’s AIs?
- How do different LLMs compare when asked to plan, design, and assemble complex things step by step?
- What tools and testing setups are needed to fairly and repeatedly evaluate these skills?
How did they test it?
They built a full testing setup (a benchmark) with three key parts: tasks, a building system AIs can use, and a physics simulator to check if the designs work.
The tasks
The benchmark includes three types of building challenges, each with Easy (Lv.1), Medium (Lv.2), and Hard (Lv.3) difficulty. The difficulty increases by requiring bigger structures, more precise fits, more parts, and less direct hints.
- Transport (horizontal movement): Build something that moves across a flat surface. At hard levels, it must carry cargo and the instructions become less specific.
- Bridge Support (static stability): Build a bridge that spans a gap and holds increasing weight without collapsing.
- Rocket Lift (vertical movement): Build a rocket or rocket-powered aircraft that can lift off and reach a certain height. At higher levels, the rocket must be assembled from multiple parts and carefully aligned.
They judge performance using simple measures:
- Transport: How far it moves.
- Bridge: How much weight it holds.
- Rocket: At Lv.1, whether thrust beats weight (thrust-to-weight ratio, or TWR). At Lv.2–3, how high it climbs.
The building system and physics
- The physics world: They use Besiege, a popular building game with realistic physics (gravity, collisions, heat, etc.). It’s like LEGO plus real physics rules.
- A language-to-building library: Because Besiege doesn’t have a direct API for AIs to “type” build commands, the team made a 3D geometry library that mimics the game’s building rules. This lets the AI say things like “attach a wheel here” or “rotate this part,” and the system checks for problems like parts overlapping, wrong connections, or breaking physics rules.
The AI “team” approach
To make the AI work more like engineers, they organized the building process into roles. The same LLM plays different roles by following different prompts:
- Planner: Writes a high-level plan.
- Designer: Drafts the design details.
- Reviewer: Checks the design and suggests fixes.
- Builder: Turns suggestions into exact build commands.
- Guide: Gives step-by-step building guidance and decides when it’s done.
- Controller (used in movement tasks): Defines how to control the machine (e.g., which keys trigger wheels or engines).
The building goes through loops of planning, drafting, reviewing, and then building step by step, with checks at each stage.
How they measured success
For each model and task, they:
- Ran 64 build attempts to get reliable averages.
- Measured success rate, performance indicator (distance, load, height/TWR), and number of parts (simpler is often better).
- Tracked “cost” (how many tokens the AI read/wrote and how many times it was called), to see if longer thinking leads to better results.
They tested eight well-known LLMs (like GPT‑4o, Claude‑4, Grok‑4, Gemini‑2.0, DeepSeek‑3.1, Qwen‑3, Kimi‑K2, Seed‑1.6).
What did they find?
- LLMs can build simple, working machines: Models often managed basic moving vehicles, simple bridges, and rockets that sometimes lifted off.
- Difficulty matters: As tasks got more complex—bigger builds, multiple parts, precise alignments—success rates dropped sharply for most models.
- Grok‑4 stood out: It was generally the strongest, especially for precise, robust builds that are sensitive to small mistakes.
- Common failure reasons: Most failures were due to spatial mistakes—attaching parts to the wrong surface, overlapping parts, or not tracking the structure’s changing shape during the build.
- Creativity shows up: Some models tried clever solutions, like using wheels’ built-in brakes to stabilize a bridge or building truss-like patterns similar to real engineering.
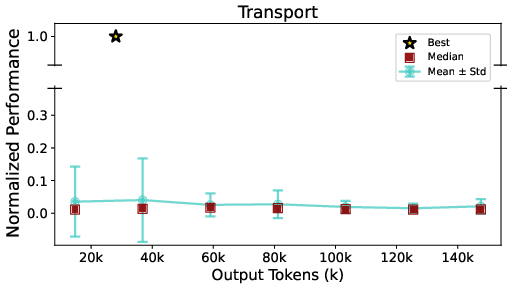
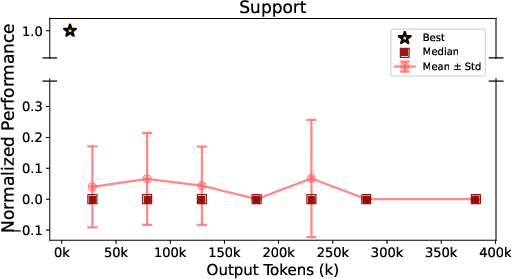
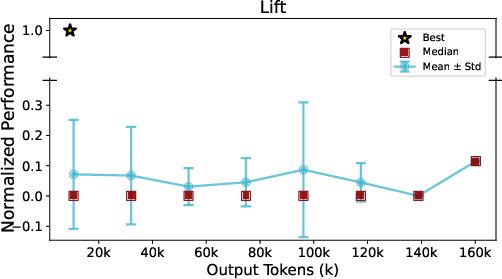
- Longer outputs don’t guarantee success: Using more tokens (longer conversations) didn’t reliably improve the builds. Smart, focused steps beat endless text.
Why does this matter?
BuildArena is a practical, physics-aware way to test whether AIs can follow instructions to create real, working things—not just text or code. This matters because:
- It pushes AIs toward real-world engineering skills: spatial reasoning, precision, multi-step assembly, and safe design.
- It reveals what today’s AIs are missing: better spatial memory, exact part placement, and handling multi-part builds without getting confused.
- It guides improvement: Model developers can focus on the hardest areas (precision, robustness, compositional building).
- It opens the door to useful tools: Future AIs could help engineers prototype machines, plan assembly, and even test designs before building them in real life.
The authors note that future versions could add a “feedback loop” where the AI learns from simulation results to refine designs, and expand the parts library so AIs can build an even wider variety of structures.
In short, BuildArena is a big step toward AIs that don’t just talk about building—they actually build, while following the laws of physics.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper’s benchmark, methodology, and findings.
- Physics fidelity to real-world engineering: No quantitative validation that Besiege’s physics (materials, joints, friction, damping, tolerances, failure modes) approximates engineering-grade simulators (e.g., FEA, multibody dynamics). Future work should cross-validate against Autodesk/SimScale/MuJoCo/Isaac Gym and report error bounds.
- Equivalence of the Spatial Geometric Computation Library to Besiege: The library is said to “mirror” Besiege’s closed-source build logic, but there is no systematic alignment study (coverage, edge cases, regression tests). Provide a test suite with pass/fail parity metrics for all actions, constraints, and collision/attachment results.
- Generalization across engines and domains: The benchmark is tied to Besiege; portability to other physics engines or CAD/robotics stacks (e.g., URDF/SDF, ROS, Onshape, IFC-based BIM) is untested. Demonstrate adapters and evaluate cross-engine consistency.
- Limited task scope: Only three categories (dynamic horizontal transport, static bridge support, rocket vertical lift). Missing engineering tasks include tolerance stack-up, fastening/joint selection, load path analysis, kinematic chains, compliant materials, thermal/fluids, electrical and control integration, and multi-step assembly/scheduling.
- Absence of ground-truth solutions: No canonical reference designs or optimal baselines per task level. Release verified solutions (including parametric CAD and bill of materials) to calibrate difficulty, measure suboptimality, and support standardized comparisons.
- Metrics may not capture engineering quality: “Number of parts” as a proxy for simplicity can conflict with robustness/redundancy. Add metrics for safety factors, robustness under perturbations, reliability, maintainability, and resource/cost (e.g., material mass, joint count, structural redundancy).
- Robustness under uncertainty: Evaluation uses fixed conditions; sensitivity to disturbances (e.g., ±5–10% parameter noise, surface friction variability, load placement changes) is not assessed. Introduce controlled perturbation sweeps and report robustness curves.
- Statistical rigor and reproducibility: Results averaged over 64 runs lack confidence intervals, variance, or statistical tests. Report seeds, run-to-run variability, and significance testing; publish all logs to enable exact replication.
- Token cost comparability: Token counts are reported but not normalized across different tokenizers and pricing models. Include standard cost-normalized metrics (tokens normalized to bytes/chars, runtime latency, total dollar cost) and compute utilization.
- Control versus structure confound: Failures may stem from poor control policies rather than structural design. Separate evaluation of structural feasibility (passive stability) from controller quality (closed-loop performance with PID/MPPI) and allow controller optimization baselines.
- Outer-loop improvement is absent: The paper notes missing closed-loop refinement. Implement and test simulator-driven iterative improvement (e.g., CMA-ES/RL over action sequences or design parameters, self-play curricula) and quantify gains.
- Workflow ablation and heterogeneity: All agent roles use the same LLM with fixed prompts; there is no ablation on role composition, prompt variants, or heterogeneous ensembles. Evaluate role-specialized models, tool-use vs. no tool-use, and debate/verification contributions.
- Open-source model coverage: Only closed-source frontier models were evaluated. Include strong open-source LLMs (e.g., Llama 3.x, DeepSeek-R1, Qwen variants with tool-use) to broaden accessibility and replicability.
- Memory and state tracking: Spatial conflicts dominate failures, yet there is no evaluation of state memory mechanisms (scratchpads, scene graphs, explicit 3D coordinate maps). Benchmark methods that maintain symbolic/graphical scene state and measure conflict reduction.
- 3D representation choice: Natural-language command interfaces may limit precision; programmatic/constraint-based representations (e.g., parametric CAD, CSG, ShapeAssembly, constraint solvers) are not compared. Test alternative representations’ effects on accuracy and precision-sensitive tasks.
- Limited module diversity: The module library restricts expressivity. Expand component sets (materials, joints, actuators, sensors) and quantify how module diversity affects solvability, creativity, and generalization.
- Human baselines and expert evaluation: No human baseline (novice/expert) or expert rating of design quality and safety. Add human comparisons to calibrate difficulty and verify real-world plausibility.
- Ambiguity dimension realism: “Ambiguity” is varied via prompt changes, but the naturalistic complexity of engineering specifications (incomplete, conflicting, multi-objective) is not modeled. Introduce realistic spec corpora (requirements, constraints, trade-offs) and measure performance under ambiguity and contradictions.
- Safety and ethical considerations: There is no assessment of unsafe or non-compliant designs (e.g., unstable rockets, bridges beyond safe load). Define safety criteria and failure penalties; include safety factor thresholds and compliance checks.
- Failure taxonomy to mitigation: While failure reasons are tallied, there is no tested mitigation (e.g., constraint solvers, lookahead collision checks, explicit occupancy maps). Evaluate interventions that target the dominant failure modes.
- Real-to-sim transfer and physical deployment: The benchmark remains virtual; no validation on physical assembly or robot execution. Explore sim-to-real protocols, hardware pilots, and discrepancies (tolerances, material variability).
- Long-horizon planning and scheduling: Engineering construction involves temporal sequencing, resource allocation, and logistics; these are not benchmarked. Add tasks with multi-stage dependencies, procurement constraints, and time/resource budgets.
- Multi-agent coordination: The framework does not evaluate collaboration among multiple agents (e.g., assembly teams, robots). Test coordinated task decomposition, conflict resolution, and synchronization.
- Tool-use integration: Although tool-use is cited, agents do not leverage external solvers (FEA, CAD kernels, optimization). Benchmark tool-augmented workflows and measure improvements in precision and robustness.
- Vision and multimodality: Agents do not perceive simulator outputs (images/trajectories) directly. Evaluate multimodal pipelines that ingest visual state and use perception for closed-loop adjustments.
- Benchmark comparison table clarity: The comparison criteria (e.g., “Spatial Reasoning”, “Interactive Environment”) are not operationalized, and table entries are opaque. Define measurable properties and standardized scoring procedures for cross-benchmark comparisons.
- Task success criteria nuance: For rocket tasks, Level 1 uses thrust-to-weight ratio (), while Levels 2–3 use maximum height; this impedes comparability. Harmonize criteria or provide dual metrics (launch feasibility and altitude) across levels.
- Import/export reliability: The pipeline converts final states into “runnable files,” but conversion robustness, schema compliance, and failure rates are not reported. Measure import/export success and fidelity across complex assemblies.
- Curriculum and generalization: Models struggle at higher difficulties, but there is no curriculum evaluation. Study staged curricula and transfer learning from simple to hard tasks; quantify sample efficiency and learning curves.
- Standardized leaderboard and governance: The project site is mentioned, but there is no formal leaderboard, submission protocol, or auditability guidelines. Establish a public evaluation harness, versioning, dataset/task registry, and governance for updates.
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s released benchmark (BuildArena), Spatial Geometric Computation Library, and baseline LLM agentic workflow. Each item lists sectors, potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
- Physics-aligned evaluation of LLM “engineering co-pilots”
- Sectors: software, robotics, engineering R&D
- What emerges: a standardized “LLM Physical Construction Scorecard” that teams use to compare models’ spatial reasoning, planning, and precision against physically grounded tasks (transport, bridge support, rocket lift).
- Assumptions/dependencies: access to the BuildArena codebase and Besiege sandbox; representative tasks reflect real needs; model API cost/logging support.
- Internal QA gate for AI agents that propose build/assembly steps
- Sectors: manufacturing, civil infrastructure, automotive prototyping
- What emerges: a pre-deployment QA workflow that runs agents through BuildArena tasks and flags common failure modes (spatial overlap conflicts, misusing faces, poor precision) before agents are allowed to assist shop-floor planning.
- Assumptions/dependencies: mapping benchmark performance to a threshold relevant for the enterprise; ongoing maintenance of test suites; sandbox-only validation (no direct real-world guarantees).
- Educational sandbox for engineering design and physics reasoning
- Sectors: education (K–12, university engineering), maker communities
- What emerges: browser-accessible labs where students issue natural-language build instructions and observe physics outcomes; lesson modules on statics/dynamics; graded assignments using success criteria and performance indicators (e.g., maximum load, maximum displacement).
- Assumptions/dependencies: availability of an easy-to-use front end; classroom computational resources; licensing for Besiege or an equivalent simulator.
- Rapid prototyping of language-to-geometry assembly pipelines
- Sectors: robotics, digital twins, CAD research
- What emerges: a minimal viable “language-to-build” pipeline that iteratively translates textual plans into discrete geometry actions (attach/remove/rotate/shift/connect), verifies constraints via the library, and outputs runnable simulation files.
- Assumptions/dependencies: fidelity of library’s physics/alignment with Besiege construction logic; limited module diversity; porting needs to other simulators or CAD suites.
- Benchmark-driven model selection and fine-tuning recipes
- Sectors: AI model development, enterprise AI platforms
- What emerges: workflows that test multiple LLMs (e.g., GPT-4o, Claude, Grok) against BuildArena tasks, choose a model based on precision/robustness/magnitude/ambiguity profiles, and fine-tune prompts/agents to reduce spatial conflicts and precision errors.
- Assumptions/dependencies: access to different LLMs; repeatable evaluation (64-run sampling); cost tracking via token logs.
- Creative design exploration under physical constraints
- Sectors: product design, game modding, maker tools
- What emerges: “physics-aware ideation assistants” that propose unconventional yet feasible constructions (e.g., wheel-stabilized bridges, propulsion carriers), validated in simulation and iteratively refined via the Draft–Review–Build–Guidance loop.
- Assumptions/dependencies: constraints match realistic design goals; tolerance for sandbox-specific artifacts; supervision to avoid risky designs.
- Policy-aligned pre-certification tasks for AI agents operating in physical domains
- Sectors: public policy, standards bodies, procurement
- What emerges: procurement checklists requiring AI agents to pass physics-aligned benchmarks (precision and robustness tiers) before use in tasks that affect safety; audit artifacts from detailed logs (token counts, conversation turns, failure reasons).
- Assumptions/dependencies: acceptance of sandbox benchmarks as partial evidence; translation of success criteria to policy language; governance frameworks for model updates.
- Failure-mode taxonomies and unit tests for physical reasoning
- Sectors: software QA, AI safety
- What emerges: “Physical Reasoning Unit Tests” that isolate overlap conflicts, face occupation errors, excess connections, and control misconfigurations; regression testing as models or prompts change.
- Assumptions/dependencies: stable test definitions; alignment of test failures with real-world risk; ongoing benchmarking upkeep.
- Lightweight tools for hobbyists and DIY builders
- Sectors: daily life, maker communities
- What emerges: a “Build Coach” that converts instructions (e.g., “make a 4-wheeled cart that carries a load”) into constrained build steps and warns when actions would violate physics constraints; shareable, simulation-ready files.
- Assumptions/dependencies: simplified UIs; community support; model costs manageable for individuals.
Long-Term Applications
The following applications require further research, scaling, module/library extensions, and integration with industrial-grade tools and robots. Each item lists sectors, potential tools/products/workflows, and assumptions/dependencies.
- Autonomous, language-driven construction planning for civil infrastructure
- Sectors: civil engineering, transportation, public works
- What emerges: “AI Construction Planner” that translates high-level specs (e.g., bridge spans, loads, sequencing) into build plans, modular assemblies, and on-site procedures, validated via physics simulation and digital twins.
- Assumptions/dependencies: enlarged module libraries (materials, joints, tolerances), high-fidelity simulators (FEA, multi-physics), integration with BIM/IFC standards and site logistics; closed-loop iteration from simulation to plan revision.
- CAD integration and design-to-fabrication automation
- Sectors: software (CAD/CAE), manufacturing, aerospace
- What emerges: plugins bridging the agentic workflow with parametric CAD (e.g., Autodesk, SolidWorks) and FEA platforms (e.g., SimScale), producing manufacturable geometries, material specs, tolerances, and assembly drawings from natural-language specs.
- Assumptions/dependencies: robust CAD APIs, accurate geometry/constraint mapping, material models, code compliance, and post-processing for fabrication (CAM, tool-path generation).
- Real-world robotic assembly guided by language and simulation
- Sectors: robotics, industrial automation
- What emerges: “Sim-to-Real Assembly Agents” that plan, verify, and execute assembly sequences with multi-robot coordination (leveraging approaches like DART-LLM), using the Draft–Review–Build–Guidance loop plus sensor feedback to adapt on-site.
- Assumptions/dependencies: perception and manipulation reliability, calibrated control stacks, safety envelopes, sim-to-real transfer of constraints, certified collision avoidance and fail-safe routines.
- Digital twin–driven closed-loop optimization
- Sectors: construction tech, smart manufacturing, operations
- What emerges: an outer loop that uses simulation telemetry (e.g., structural stability, control performance) to automatically refine designs and workflows (reinforcement learning or Bayesian optimization), continuously updating the build plan to meet targets (load, precision, cost).
- Assumptions/dependencies: scalable compute for iterative simulation, well-instrumented digital twins, robust metrics linking simulation outcomes to real performance, data governance.
- Safety, compliance, and certification frameworks for AI-in-the-physical-world
- Sectors: policy/regulation, insurance, procurement
- What emerges: standard “Physics-Aligned AI Certification” frameworks that test agentic systems on precision/robustness/compositionality before deployment; insurance underwriting informed by benchmark profiles and failure-mode distributions.
- Assumptions/dependencies: consensus among regulators and industry, accepted mappings from sandbox tasks to real-world safety cases, periodic re-certification protocols.
- Enterprise “Construction Agent as a Service” platforms
- Sectors: SMEs in fabrication, modular housing, renewable energy
- What emerges: cloud services that take specs (e.g., solar mount frames, small bridges, site vehicles), generate physics-validated designs, assembly sequences, and costed bills of materials; optional field-robot interfaces.
- Assumptions/dependencies: sector-specific module libraries and codes, integration with supply-chain data, robust cost models, vendor-neutral APIs.
- Human–AI collaborative CAD studios with multi-agent debate
- Sectors: product design, architecture, mechanical engineering
- What emerges: team-facing environments where AI agents (Planner, Drafter, Reviewer, Builder, Guide) co-create with humans, handling long-horizon planning, constraint checks, and precision alignment; versioned design artifacts tied to simulation outcomes.
- Assumptions/dependencies: UX that supports multi-agent collaboration and traceability; conflict resolution protocols; model accountability mechanisms.
- Standards for physics-aligned LLM benchmarking and tool interoperability
- Sectors: AI tooling, academic benchmarking, standards bodies
- What emerges: open task schemas, action/constraint ontologies, and logging formats enabling cross-simulator, cross-platform evaluation; reference suites for spatial reasoning, compositional assembly, and precision under sensitivity.
- Assumptions/dependencies: community governance, contributions of diverse modules and tasks, sustained maintenance.
- Assistive design for healthcare devices and lab infrastructure
- Sectors: healthcare, biomedical research
- What emerges: physics-validated conceptual designs for lab rigs, mountings, and simple medical device housings; language-driven iteration to meet ergonomic and load specifications.
- Assumptions/dependencies: specialized modules/materials, regulatory constraints (ISO, FDA), biomedical safety standards, high-fidelity biocompatibility models.
- Educational accreditation and adaptive curricula in engineering
- Sectors: higher education, vocational training
- What emerges: accreditation-aligned, physics-grounded assessments of students’ ability to specify and validate builds via language; adaptive learning pathways that adjust difficulty profiles (quantification, precision, robustness, ambiguity) per learner.
- Assumptions/dependencies: alignment with accreditation bodies, accessible simulation infrastructure at scale, teacher training and content development.
These immediate and long-term applications are enabled by the paper’s core innovations: a customizable physics-aligned benchmark (BuildArena), an open Spatial Geometric Computation Library that reproduces construction logic and constraint checks, and a baseline multi-entity LLM workflow that decomposes planning, drafting, review, build, and guidance into an iterative, traceable loop. Feasibility hinges on assumptions about simulator fidelity, module diversity, integration with industrial software and robots, governance and safety standards, and sustained community maintenance.
Glossary
- 3D Spatial Geometric Computation Library: An open-source library that mirrors the simulator’s building logic to enable language-based 3D construction operations. "We develop a key framework module: a 3D Spatial Geometric Computation Library."
- Besiege: A physics-based construction sandbox game used as the simulation environment for evaluating engineered builds. "Besiege is a popular construction sandbox game with realistic physics simulation, widely validated by world-wide player community to align with human physical intuition."
- CAD: Computer-Aided Design; software and methods for programmatically creating and modifying 3D engineering models. "research in programmatic 3D or CAD generation has advanced generation performance but rarely validates whether the generated designs yield executable assemblies under realistic physical conditions"
- Closed-loop improvement: An iterative evaluation-and-refinement process that uses outcomes to improve subsequent construction attempts. "Addressing this gap would involve designing an evaluation framework that enables closed-loop improvement driven by evaluation results."
- Collision avoidance: Ensuring new components do not intersect existing ones during assembly to maintain physical feasibility. "physical feasibility (e.g., collision avoidance) is continuously verified"
- Compositional constructions: Building complex structures by assembling multiple interdependent substructures. "the models ability to cope with compositional constructions is generally weak."
- Construction sandbox game: An open building environment where users assemble parts under physics constraints. "Besiege is a popular construction sandbox game with realistic physics simulation"
- Control configuration: The mapping of controls and sequences required to operate a constructed machine in simulation. "The LLM agent must specify a control configuration and sequence—invalid or missing controls cause immediate failure."
- Differential steering: A vehicle steering method using varied wheel speeds (typically left vs. right) to turn. "Remarkably, structures mirroring real-world engineering practices are constructed by LLMs, such as steel trusses in bridges and differential steering in vehicles"
- Load-bearing capacity: The maximum load a structure can support without failing in simulation. "it can place loads on bridges to test their load-bearing capacity and offer conditional support for the entire launch process of rockets."
- LLM agentic workflow: A multi-entity, tool-using process where an LLM plans, drafts, reviews, and builds through coordinated roles. "We design an LLM agentic workflow that effectively evaluates diverse model capabilities."
- Module space: The set of available structural and functional components that can be attached to form complex builds. "It has a rich modules space, a complete collection of basic structural and functional module types that can be combined to build complex objects"
- Module trajectories: Recorded paths of components during dynamic simulation to evaluate movement and performance. "with module trajectories and cannons’ heating status recorded for evaluation during a fixed window."
- Payload: An added weight or cargo used to test transport systems or structural support in simulation. "A payload of gradually increasing weight is placed on the structure, and the simulation measures whether the machine can support and stabilize the load"
- Physics-aligned interactive benchmark: An evaluation framework that aligns tasks and scoring with realistic physics constraints through interaction. "we introduce , the first physics-aligned interactive benchmark designed for language-driven engineering construction."
- Physics-grounded construction automation: Automated building guided by language that is validated within realistic physics simulations. "On eight frontier LLMs, comprehensively evaluates their capabilities for language-driven and physics-grounded construction automation."
- Sequential dependencies: Ordered assembly requirements where certain components must be placed before others to ensure feasibility. "their assembly follows sequential dependencies with strict feasibility constraints"
- Simulation protocols: Task-specific procedures for configuring, running, and measuring outcomes in the physics simulator. "Simulation environments are based on the Besiege sandbox, with task-specific simulation protocols."
- Single points of failure: Critical components whose malfunction causes the entire system to fail. "the presence of multiple single points of failure (engine placement, structural balance)"
- Spatial conflict: An invalid build action where components overlap or occupy the same attachment face. "Spatial conflict is the most difficult mistake to avoid."
- Steel trusses: Triangulated frameworks used in bridges to provide strength and distribute loads. "Remarkably, structures mirroring real-world engineering practices are constructed by LLMs, such as steel trusses in bridges and differential steering in vehicles"
- Thrust-to-weight ratio (TWR): The ratio of a vehicle’s thrust to its weight, indicating whether it can accelerate upward; success requires . "TWR 1 represents the feasibility of providing effective thrust and marks successful construction."
- Water cannons: Propulsive modules in the simulator whose heating status is tracked to assess thrust in rocket tasks. "Lv.1 records water cannons’ heating status to calculate TWR"
Collections
Sign up for free to add this paper to one or more collections.