- The paper introduces a GPU-accelerated primal-dual interior point method for quadratic conic programs, achieving speedups up to 70x on large-scale instances.
- It leverages direct sparse LDLᵀ factorization via cuDSS and custom CUDA kernels to parallelize cone operations efficiently.
- The modular design allows seamless switching between CPU and GPU backends, enhancing integration with Python APIs like CVXPY.
QOCO-GPU: Large-Scale Quadratic Objective Conic Optimization with GPU Acceleration
Introduction
QOCO-GPU introduces a GPU-accelerated backend for the QOCO solver, targeting large-scale quadratic objective second-order cone programs (SOCPs). The solver implements a primal-dual interior point method (PDIPM) with a focus on direct sparse LDL⊤ factorization of the KKT system on NVIDIA GPUs via cuDSS, combined with custom CUDA kernels for parallel cone operations. The architecture features a modular backend design, enabling seamless switching between CPU and GPU execution. This work demonstrates that with sufficient parallelism and modern GPU libraries, second-order methods can achieve speedups up to 70× versus multithreaded CPU implementations as problem sizes scale.
The class of problems addressed is
xmin 21x⊤Px+c⊤xs.t.Gx⪯Kh, Ax=b
where K is a Cartesian product of non-negative orthants and second-order cones. The approach leverages QOCO’s primal-dual IPM, which is robust to problem conditioning but traditionally bottlenecked by sparse KKT factorizations.
The architectural innovation centers on a unified abstraction for matrix/vector storage and a backend interface covering factorization and cone operations. In the GPU backend, data structures reside natively on the device, and all cone operations (Jordan products, Nesterov-Todd scaling, projections) are parallelized with CUDA kernels. This allows the decoupling of solver logic from computation backend, exposing CPU and GPU options at runtime (including through a pybind11-powered Python API and CVXPY).
Exploiting GPU Capabilities
For each IPM iteration, QOCO-GPU factors the KKT system using cuDSS, which is split into three phases: (1) Analysis (symbolic reordering/factor pattern on CPU), (2) Numeric factorization, (3) Triangular solves. While cuDSS delivers significant speedups in matrix operations, minimizing CPU-GPU memory transfers is critical for overall performance. Thus, all persistent data is pre-loaded to GPU memory before solving, and all computation takes place on device until the final extraction of primal/dual solutions.
The modular codebase ensures that switching between CPU-based QDLDL and GPU-accelerated cuDSS for the KKT system (and corresponding cone routines) is entirely transparent to users and high-level APIs.
Empirical evaluations were conducted on a broad suite of QPs and SOCPs, including Huber regression, (multi-period) portfolio optimization, group lasso, and total variation denoising. Problems ranged up to 108–109 KKT nonzeros.
The key numerical findings are:
- For KKT matrices with ≳105 nonzeros, the GPU backend outperforms the CPU backend.
- On extremely large problems, QOCO-GPU is $50$–70× faster than single-threaded QOCO and $2$–×0 faster than other GPU direct factorization-based solvers (e.g., CuClarabel) in some cases.
- Compared to multi-threaded commercial solvers (MOSEK, GUROBI), QOCO-GPU dominates at the largest scales tested.
- For smaller problems, GPU kernel launch cost and PCIe transfers outweigh the benefits of GPU compute.
The following performance profile succinctly summarizes the solver landscape:
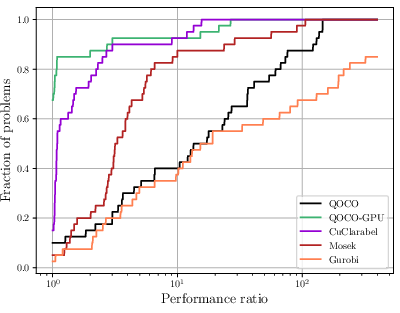
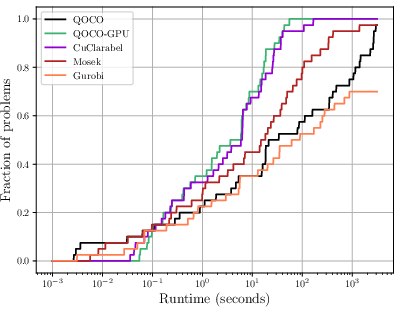
Figure 1: Relative performance profile of QOCO-GPU, QOCO, CuClarabel, Mosek, and Gurobi, highlighting regime shifts in solver dominance as problem size increases.
The shifted geometric mean of runtime is lowest for QOCO-GPU, with zero failures observed across the benchmark set.
A performance-ablation analysis identified GPU parallelism of cone operations as a strict requirement: without bespoke parallel CUDA kernels, cone operations dominate solve time due to GPU inefficiency in serial workloads.
Practical and Theoretical Implications
The principal practical implication is that robust, high-accuracy IPMs are now viable for extremely large-scale conic QPs/SOCPs in timeframes previously limited to first-order or decomposition-based algorithms. The modular design and full integration with CVXPY and Python lowers the barrier to applying high-performance conic optimization in data science, finance, and engineering domains.
From a theoretical standpoint, the results challenge the typical heuristic that only simple first-order algorithms scale to the largest problems on GPUs. Instead, the combination of sparse direct solvers (cuDSS) and paradigm-appropriate parallelism can make second-order methods competitive or superior, provided the core bottlenecks (primarily symbolic analysis and factorization) map efficiently to GPU hardware.
Parametric/embedded optimization is a salient use-case, as the cuDSS analysis phase is amortized for fixed sparsity patterns across repeated solves.
Limitations and Directions for Future Work
The dominant limitation is the cost and memory growth associated with direct sparse factorization, including fill-in and potential out-of-memory scenarios for the largest instances. The symbolic analysis stage of cuDSS remains CPU-bound and can constitute 75% or more of the end-to-end runtime for extremely large instances, although this cost can be amortized in parametric solve contexts.
For small to medium problems, the CPU backend remains superior due to kernel/memory latency overheads. Potential directions for further research include GPU acceleration of symbolic analysis, hybrid direct/iterative approaches to KKT solves, and automatic selection of backend based on problem instance profiling.
Conclusion
QOCO-GPU establishes that primal-dual IPMs for quadratic objective conic problems can strongly benefit from GPU acceleration, provided both direct sparse linear algebra and cone operations are efficiently parallelized. It outperforms established CPU and even other GPU solvers on sufficiently large-scale problems while providing a unified API for rapid prototyping and integration. Future advances in GPU sparse matrix analysis and broader support for diverse conic structures will further expand the capabilities of large-scale conic optimization.