- The paper demonstrates that the microeconomic framework endogenizes automation intensity as a continuous choice based on scaling law costs and task entropy.
- It quantifies labor displacement using entropy measures, revealing that partial automation frequently achieves optimal cost savings compared to full automation.
- Empirical findings indicate that deployment scale and task complexity significantly influence the shift towards human–AI collaboration as the cost-optimal equilibrium.
Economics of Partial vs. Full Automation: Task-Optimality in Human–AI Collaboration
Introduction
“Economics of Human and AI Collaboration: When is Partial Automation More Attractive than Full Automation?” (2603.29121) presents a formal, empirically calibrated microeconomic framework for assessing optimal automation intensity at the task level. Rejecting the classic binary automation paradigm, the paper analyzes automation as a continuous decision, parameterized by AI system accuracy, which is endogenously chosen to minimize cost under realistic scaling-law constraints. The framework integrates supply-side scaling law production for model quality with entropy-based measures of task complexity on the demand side, enabling rigorous quantification of both full and partial automation and their cost-effectiveness across the economy.
Technical Framework for Automation Intensity
The core analytic advance is the endogenization of automation intensity as a continuous firm choice. On the supply side, model performance (accuracy) is a convex function of investment in data, training steps, and model size—central features of deep learning scaling laws. The demand side models task complexity as entropy, mapping accuracy improvements to the substitutability of machine for human labor in executing subtasks. This enables direct computation of the proportion of labor displaced for any given quality of AI, formalizing the spectrum from no automation to partial (human-in-the-loop) to full automation.
The theoretical structure admits three solution regimes:
- No Automation: Fixed and marginal costs always exceed labor savings.
- Partial Automation: Convex cost function intersects marginal benefit prior to the required accuracy for full substitution, incentivizing interior solutions where AI optimally addresses the cost-effective portion of the task, with humans responsible for the high-entropy remainder.
- Full Automation: For low-complexity cases or at very large deployment scales, investment up to (and beyond) human-level accuracy is economically warranted.
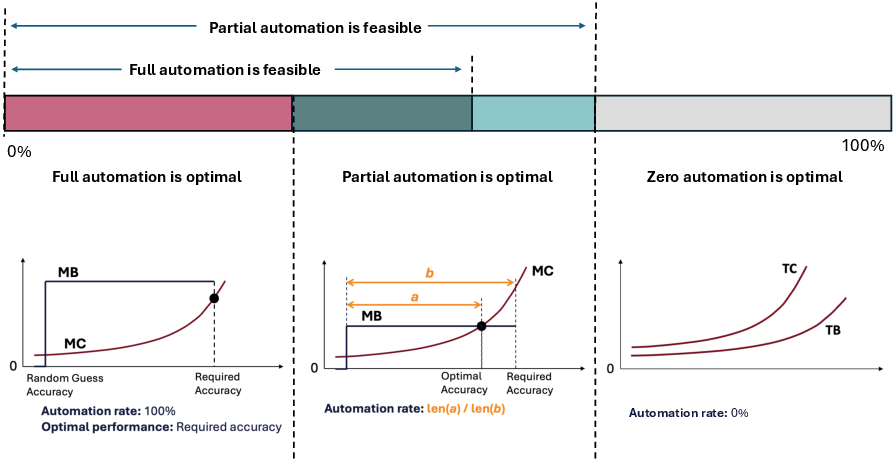
Figure 1: Breakdown of occupation compensation by task-level automation type: the cost-minimizing equilibrium frequently manifests as partial automation due to the convexity of scaling-law costs.
Entropy-Based Modeling of Labor Substitution
The mapping from model performance to labor displacement is operationalized via information theory. Each task is decomposed into discrete classification decisions, and the reduction in cross-entropy loss achieved by the AI is proportional to the fraction of labor displaced. If the model's performance equals required accuracy, full automation (r=1) is achieved; otherwise, partial automation ($0 < r < 1$) is optimal.
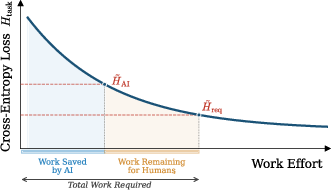
Figure 2: The division of work between AI and humans is quantified by comparing residual entropy after AI processing to task entropy, establishing the direct labor savings from accuracy improvements.
Empirical evidence on the linear relationship between entropy and human processing time underpins the modeling assumption that the effective labor time required post-AI is strictly proportional to the unresolved uncertainty (entropy gap) in the task.
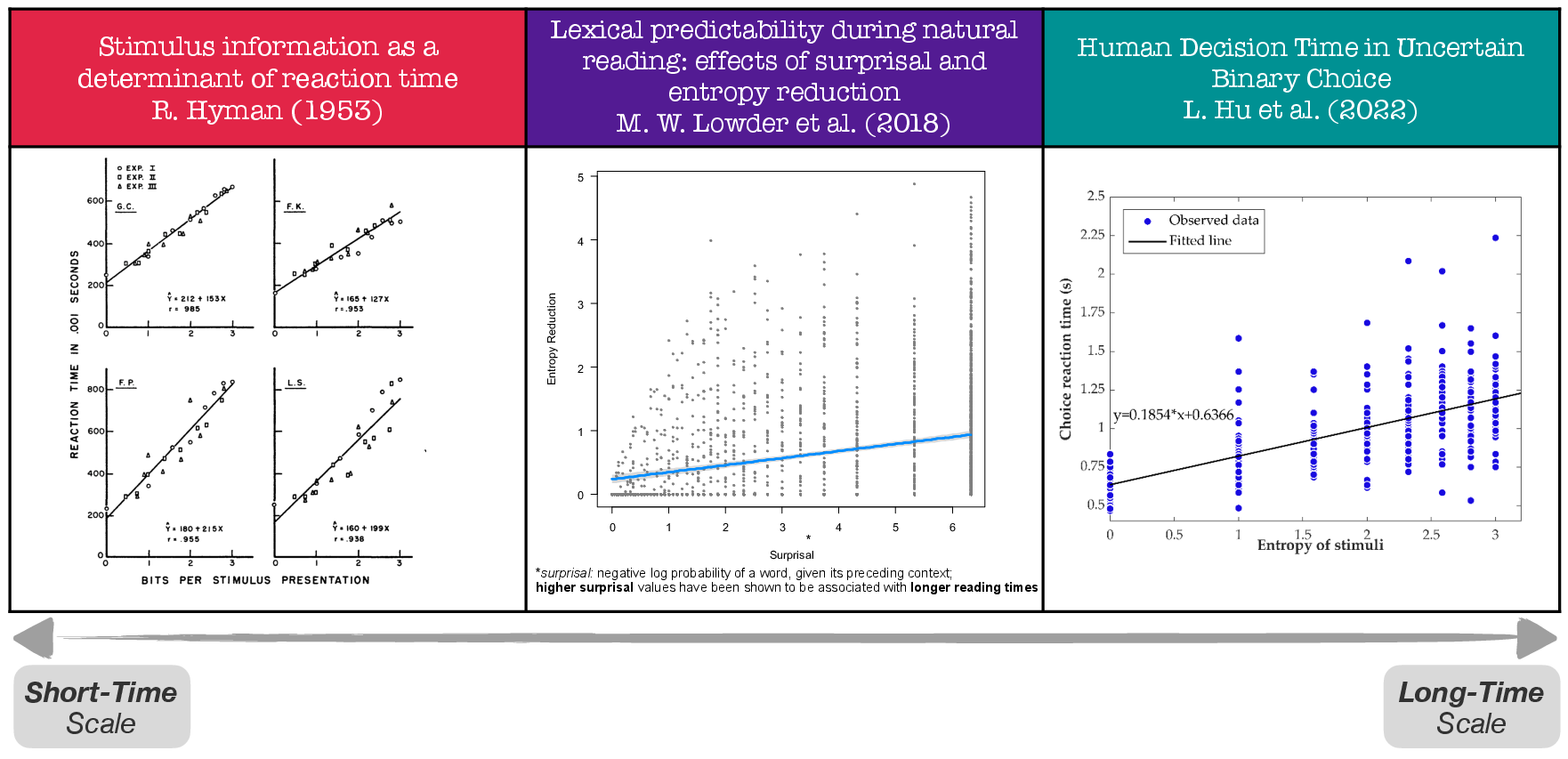
Figure 3: Empirical studies confirm that human processing time in choice or classification tasks scales with entropy across multiple time scales, validating the modeling approach.
Empirical Implementation: Scaling Laws and Task Calibration
The supply-side production function for AI quality is estimated via fine-tuning experiments on a vision transformer backbone (Swin Transformer), calibrated to a suite of classification problems with systematic variation in data, model size, training steps, and class count (task complexity). The empirically fitted scaling law departs from standard economic CES (constant elasticity of substitution) forms, instead capturing diminishing and complementary returns as model accuracy improves and task complexity increases.
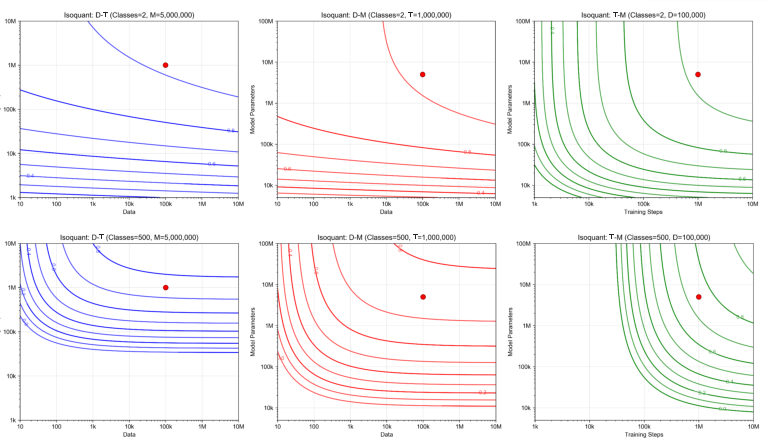
Figure 4: Isoquant contours demonstrate that as task complexity (number of classes) increases, the substitutability among data, training steps, and model size decreases, deepening complementarity among resources required for further accuracy gains.
Fine-grained task complexity metrics (subtask count, class granularity, and vision dependence) are extracted from O*NET task definitions, validated by GPT-4o decomposition and human coders, and linked to labor force and wage data to ground the economic calculations.
Quantitative Results: Automation Intensity and Scale Effects
The partial automation result is quantitatively robust: for the overwhelming majority of computer-vision-exposed labor, the convexity of the scaling-law cost structure means full automation is not optimal at the firm level. Empirically, only around 2–3% of labor compensation on vision-exposed tasks is fully automatable under current cost structure and scale; about 11% is economically attractive for partial automation. As deployment scale expands—from single firm to industry group, sector, or the entire economy—fixed costs become negligible, sharply increasing the economically viable automation share. In the limit, with broad AI-as-a-Service, nearly all technical feasible CV tasks become economically attractive to (partially or fully) automate.
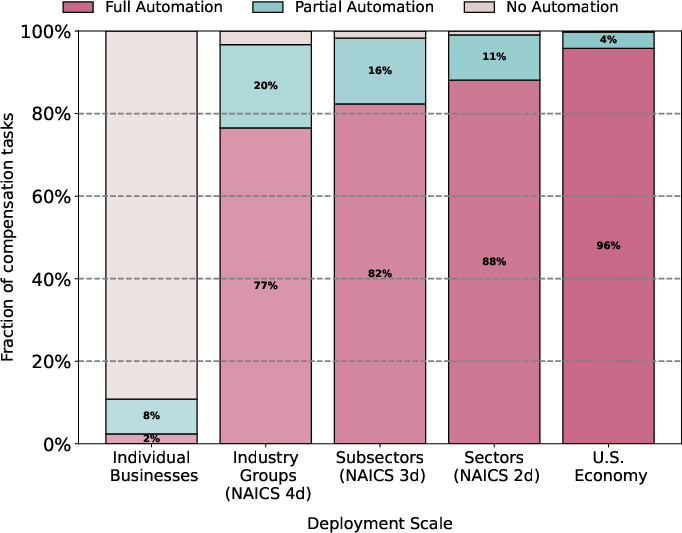
Figure 5: At small scale, nearly all economically attractive computer vision automation occurs via partial automation; with larger deployment scale, full automation becomes increasingly economical but partial remains critical.
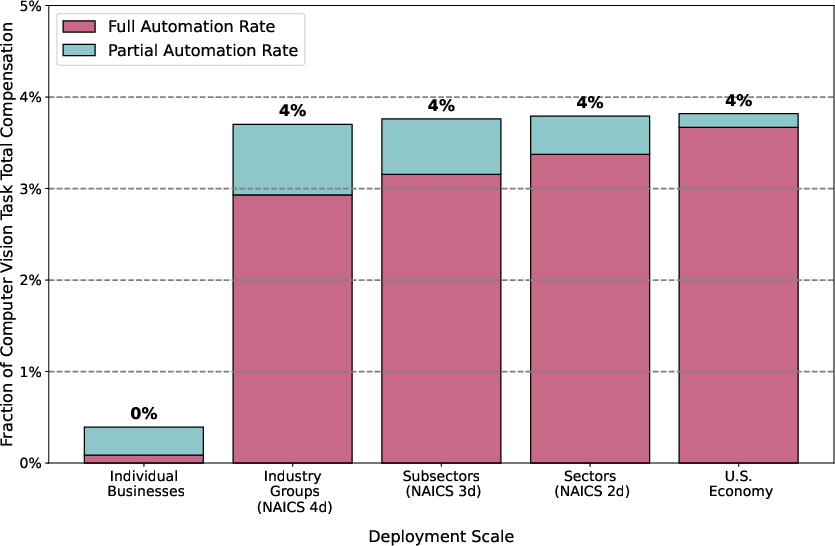
Figure 6: The fraction of total computer vision task compensation that is economically attractive to automate rises steeply with deployment scale, but never approaches aggregate labor compensation due to modality limits.
Notably, even with maximal scale, vision-exposed tasks form only a modest fraction (<4%) of total U.S. labor compensation—highlighting the gap between technical possibility and economic viability at the macro scale.
Majority adoption of automation is concentrated in large firms or standardized tasks (where fixed costs can be amortized), and among those who automate, the intensity is high: most automated tasks reach >90% automation intensity even when full automation is not optimal.
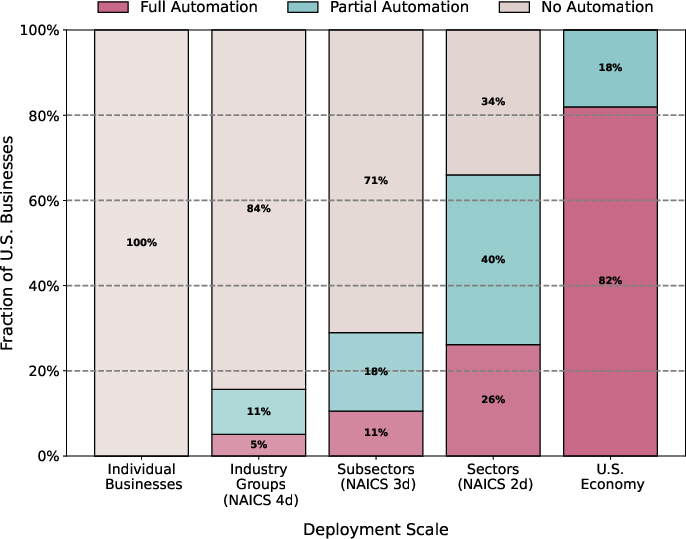
Figure 7: Most U.S. businesses, dominated by small firms, do not find automation cost-effective unless costs are shared at large scale.
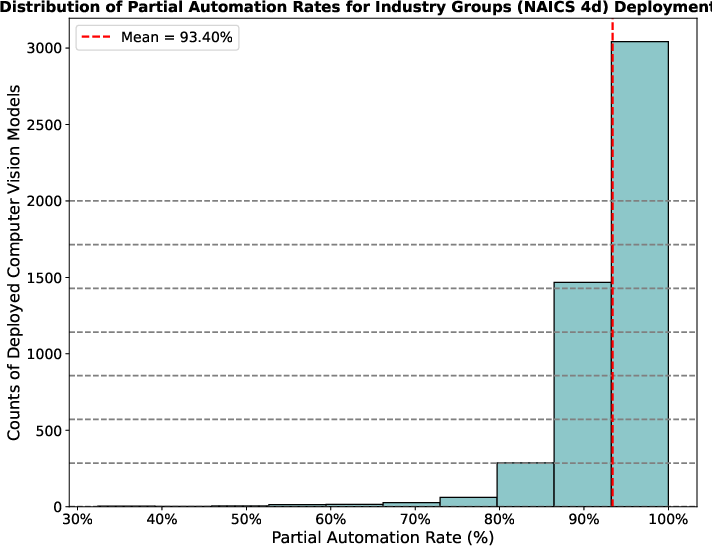
Figure 8: Among active computer vision deployments at industry group scale, the distribution of partial automation intensity is right-skewed; adoption typically equates to near-total automation of the vision component.
Occupational Heterogeneity and Task Profiles
At the occupation level, high automation rates concentrate in roles such as Transportation Security Screeners and Orthodontists, whose work involves standardized, low-complexity visual classification. In contrast, high-complexity, high-variability roles such as Zoologists remain resistant to full automation, and see only modest partial automation.
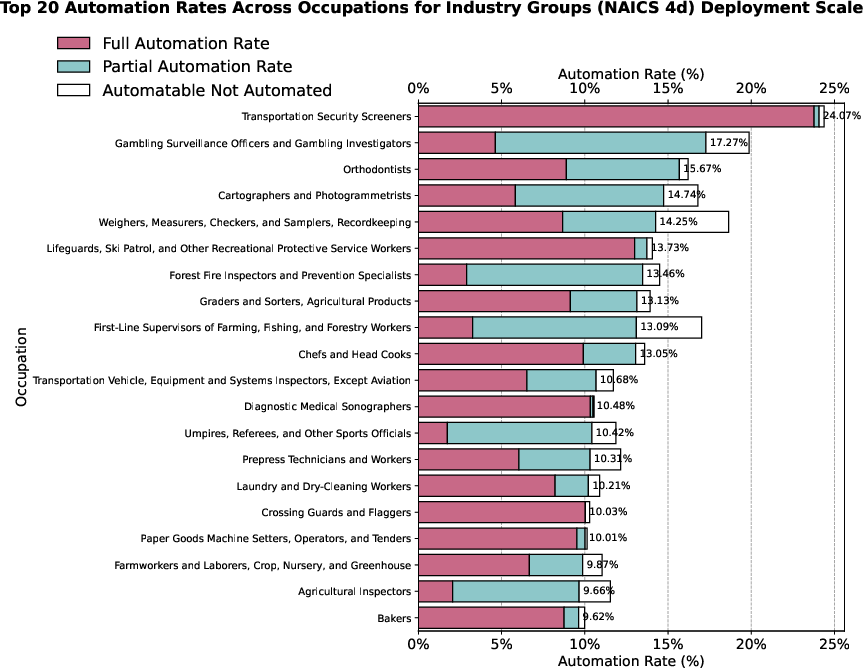
Figure 9: The top 20 occupation-level automation rates (industry group scale) show large heterogeneity, with the highest rates in occupations characterized by standardized, vision-focused tasks and low complexity.
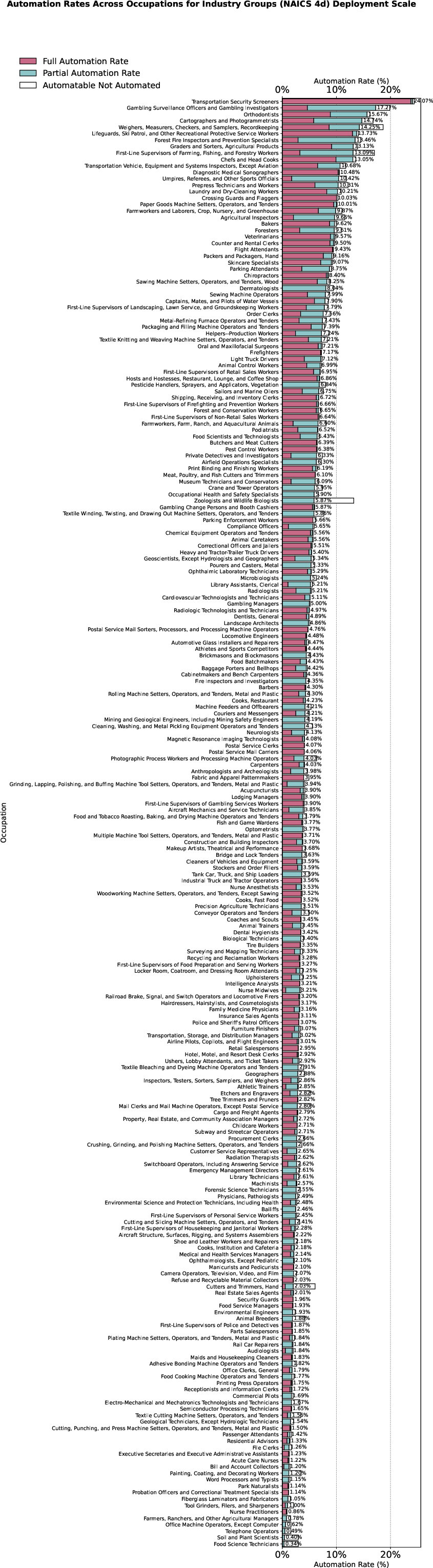
Figure 10: Full occupation-level automation rates show that many occupations have zero or minimal economic automation potential, validating the importance of task composition and complexity in constraining adoption.
Implications and Broader Impact
The analysis provides a rigorous microfoundation for the persistent empirical observation that human–AI collaboration dominates pure automation in real-world deployment. The convexity and strong complementarity of scaling-law cost functions imply that:
- Partial automation is a fundamental, not a transitional, equilibrium—for prevailing model economics, the marginal cost of closing the final gap to full automation is not justified by marginal labor savings for most tasks.
- Task complexity sharply contracts the feasible frontier for automation: tasks with many subtasks and classes face rapidly escalating costs, favoring human retention for the residual “high-entropy” workload.
- Deployment scale is pivotal: Economies of scope (AI-as-a-Service, AI agents) can strongly shift the economic boundary, but do not eliminate diminishing returns for high-complexity, nonstandardized tasks.
Qualitatively, the findings generalize to LLM, multimodal, and other foundation model settings that obey analogous scaling law behavior and entropy-constrained task models. The results reinforce that the long-term impact of AI on labor markets depends as much on economic as technical factors. Scenarios with expanded agentic scale will see a broader economic reach, but across all cases, the human-in-the-loop paradigm remains the cost-optimal mode for the majority of tasks.
Conclusion
The paper formalizes a microeconomic theory of automation intensity that integrates information-theoretic and scaling law constraints into cost-minimization. It demonstrates that partial automation emerges as the default rational equilibrium across a wide range of tasks and modalities, especially at realistic deployment scales. The framework provides both technical and economic clarity for predicting automation boundaries, suggests caution in macro extrapolation from exposure-based metrics, and supplies a robust platform for future inquiry into multimodal and dynamic task structures as AI capabilities and deployment models evolve.