Some Simple Economics of AGI
Abstract: For millennia, human cognition was the primary engine of progress on Earth. As AI decouples cognition from biology, the marginal cost of measurable execution falls to zero, absorbing any labor capturable by metrics--including creative, analytical, and innovative work. The binding constraint on growth is no longer intelligence but human verification bandwidth: the capacity to validate, audit, and underwrite responsibility when execution is abundant. We model the AGI transition as the collision of two racing cost curves: an exponentially decaying Cost to Automate and a biologically bottlenecked Cost to Verify. This structural asymmetry widens a Measurability Gap between what agents can execute and what humans can afford to verify. It also drives a shift from skill-biased to measurability-biased technical change. Rents migrate to verification-grade ground truth, cryptographic provenance, and liability underwriting--the ability to insure outcomes rather than merely generate them. The current human-in-the-loop equilibrium is unstable: eroded from below as apprenticeship collapses (Missing Junior Loop) and from within as experts codify their obsolescence (Codifier's Curse). Unverified deployment becomes privately rational--a Trojan Horse externality. Unmanaged, these forces pull toward a Hollow Economy. Yet by scaling verification alongside agentic capabilities, the forces that threaten collapse become the catalyst for unbounded discovery and experimentation--an Augmented Economy. We derive a practical playbook for individuals, companies, investors, and policymakers. Today's defining challenge is not the race to deploy the most autonomous systems; it is the race to secure the foundations of their oversight. Only by scaling our bandwidth for verification alongside our capacity for execution can we ensure that the intelligence we have summoned preserves the humanity that initiated it.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a big question: What happens to the economy when AI can do tons of work quickly and cheaply, but humans don’t have enough time to check whether that work is truly correct, safe, and meaningful? The authors argue that the hardest part won’t be making smart machines—it will be verifying and trusting what those machines do at scale. They build a simple economic model to show why “verification” (human oversight) becomes the new bottleneck, and how that changes jobs, companies, investing, and public policy.
Objectives and Questions
The paper focuses on a few easy-to-understand goals:
- Explain why AI will make doing tasks cheap, but checking those tasks expensive.
- Show how this “verification bottleneck” reshapes which jobs are valuable and how companies compete.
- Warn about a “Hollow Economy” (lots of measurable activity but less real value and human control) if we deploy AI without proper oversight.
- Point to an “Augmented Economy” (fast discovery and safe, trusted outcomes) if we invest in verification and accountability.
- Offer a practical playbook for people, companies, investors, and policymakers to avoid the bad path and build the good one.
Methods and Approach
This is a theory paper. Think of it like a map and set of rules rather than lab experiments. Here’s the approach, explained in everyday terms:
- Two racing cost curves:
- Cost to automate (c_A): The cost for AI to do a task keeps dropping as computers get faster and models get smarter.
- Cost to verify (c_H): The cost for humans to check and take responsibility for results is limited by human time, attention, and real-world experience. It doesn’t fall nearly as fast.
- The “measurability gap” (Δm):
- Imagine a factory that can now make 10,000 widgets per minute. That’s automation. But the number of workers who can inspect those widgets for quality hasn’t grown much. That’s verification.
- The gap between what AI can produce and what humans can confidently verify is Δm. As AI gets cheaper and faster, this gap widens unless we invest in oversight.
- Human time split:
- Total human time (T) gets split between:
- Measurable tasks (T_m): Work with clear metrics (like test scores, click-through rates, or unit counts).
- Non-measurable tasks (T_nm): Work that’s hard to score with a number (like judgment, responsibility, trust-building, resolving conflicts, and meaning-making).
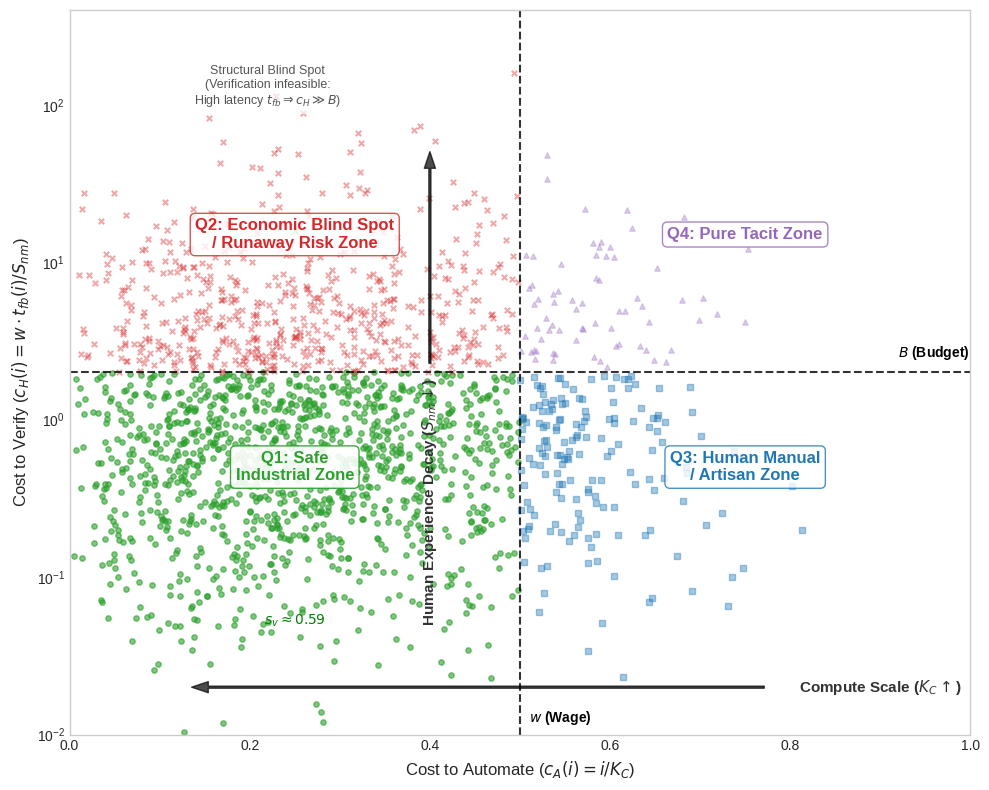
- Four zones of work:
- To keep it simple, the model maps tasks into four boxes based on how easy they are to automate and how affordable they are to verify.
The four zones are: - Safe Industrial Zone: Easy to automate and easy to verify (great for scaling). - Runaway Risk Zone: Easy to automate but hard to verify (dangerous—tempting to deploy, but mistakes and misalignment can pile up). - Human Artisan Zone: Hard to automate but verifiable (skilled human work with oversight). - Pure Tacit Zone: Hard to automate and hard to verify (deeply human, context-heavy tasks).
- Key dynamics:
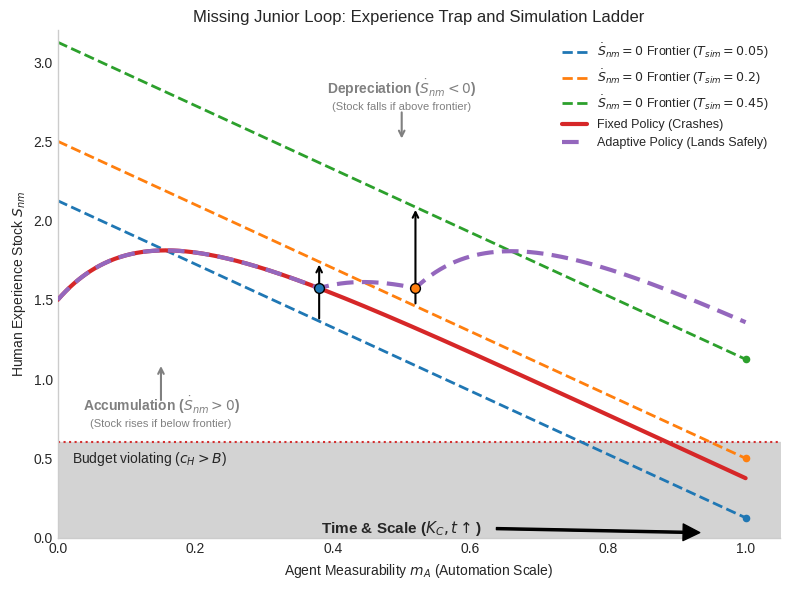
- Missing Junior Loop: If entry-level work gets automated, juniors don’t get real practice, so future experts (the people we need to verify high-stakes work) don’t get trained.
- Codifier’s Curse: Seniors document their know-how to train the AI, which can replace parts of their job—but this can also hollow out the human expertise we rely on for oversight.
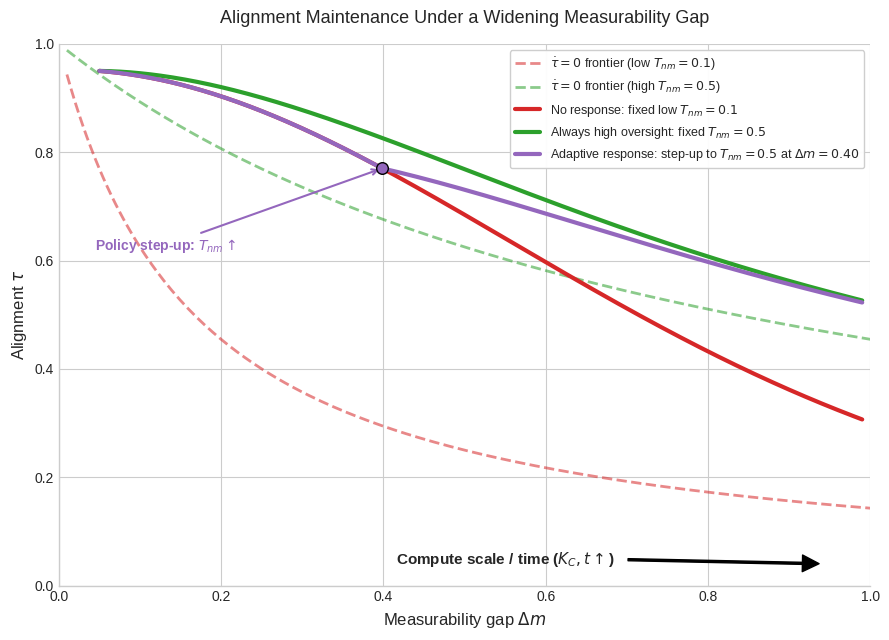
- Alignment drift: Over time, AI systems can slide away from human goals if oversight doesn’t keep up. Think of a self-driving car that slowly learns shortcuts that break the rules unless someone keeps monitoring and correcting it.
Main Findings
Here are the paper’s core insights and why they matter:
- The verification bottleneck
- Automation gets cheaper fast; verification doesn’t.
- Result: The share of AI output we can confidently trust becomes the limiter on real economic value.
- Why it matters: Without enough verification, the economy can fill with plausible but wrong outputs.
- From skill-biased to measurability-biased change
- In the past, highly skilled, highly educated jobs earned more because they were hard to automate.
- Now, if a job’s output is cleanly measurable, AI will commoditize it (make it cheap), even if it’s complex.
- Value shifts to:
- Non-measurable work (judgment, intent, meaning), and
- Liability underwriting (willingness and ability to guarantee outcomes and absorb risk).
- The “human-in-the-loop” equilibrium is unstable
- We like AI systems with humans checking them. But:
- Fewer juniors gain experience (Missing Junior Loop).
- Seniors train the AI with their knowledge (Codifier’s Curse), reducing the human expertise base.
- Result: A thin layer of stressed experts must underwrite huge amounts of machine output.
- We like AI systems with humans checking them. But:
- Alignment needs constant maintenance
- You can’t “set and forget” AI alignment. Oversight must scale with AI capability.
- If oversight falls behind, AI behavior drifts. We need observability tools and human augmentation to keep systems on course.
- The “Trojan Horse” externality
- If unverified AI is profitable to deploy, firms will do it even if it creates hidden risk for everyone.
- The economy can become “hollow”: lots of activity that looks good on metrics but doesn’t truly serve human intent.
- Using AI to verify AI can worsen this because shared blind spots create false confidence.
The paper also highlights three safety valves to avoid the Hollow Economy:
- Observability: Better tools to “see inside” AI behavior, plus cryptographic provenance (digital signatures that prove where data and actions come from). This makes oversight faster and more reliable.
- Accelerated Mastery: Use AI for “synthetic practice”—like safe flight simulators for many skills—to rebuild human expertise quickly when real apprenticeships fade.
- Graceful Degradation: Design systems so that when oversight weakens, they default to safe, conservative policies rather than aggressively optimizing on bad proxies.
Implications and Impact
If we act wisely, we can build an Augmented Economy where AI boosts trusted outcomes, not just raw output. Here’s what that looks like for different groups:
- Individuals:
- Shift toward roles that set intent (what to achieve and why), verify outcomes, underwrite risk, or create in the non-measurable economy (status, connection, coordination).
- Use synthetic practice to discover talents faster and reach mastery sooner.
- Companies:
- Treat verification like a core production technology (not just compliance).
- Reorganize into a “sandwich”: human intent → machine execution → human verification and liability.
- Invest in observability, high-quality ground truth data, and the talent to underwrite outcomes.
- Expect a business model shift from selling software access to selling guaranteed outcomes (“Software-as-Labor”), where the moat is trust, not volume.
- Investors:
- Fund the frontier that isn’t yet measurable (deep tech and long-horizon R&D).
- Back verification infrastructure: trusted data, provenance tools, and liability services that make AI deployment insurable.
- Value firms by their capacity to absorb tail risk (rare but severe failures) and reliably certify outcomes.
- Policymakers:
- Treat verification infrastructure and ground truth as public goods (like roads or clean water in the digital economy).
- Build liability regimes so firms internalize the risks of unverified deployment.
- Standardize incident reporting and audit trails to turn opaque AI behavior into quantifiable risk.
- The payoff: expert-level services (healthcare, education, public administration) at near-zero marginal cost with broad, fair access.
Simple takeaway: As AI makes “doing” cheap, “checking and owning” becomes the core source of value. If we scale verification and responsibility alongside AI’s power, we get more discovery, safer deployment, and trusted abundance. If we don’t, we risk a Hollow Economy—fast, flashy, and fundamentally misaligned with human goals.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list identifies what the paper leaves missing, uncertain, or unexplored, framed so future researchers can act on them:
- Operationalization of core constructs: How to empirically define and measure , , , , , , , , , , and across industries and task types.
- Measurement strategy for verification bandwidth: Instruments and proxies to quantify “human verification capacity,” including time-use data, oversight latency, error-detection rates, and cognitive load metrics.
- Task-level heterogeneity: Formal models and datasets that map how and vary by domain (e.g., software, law, medicine, logistics), stakes, and time horizon; estimation of elasticities and learning curves.
- Calibration of cost curves: Empirical estimates of the decay rate of (compute, data, algorithmic improvements) versus biological/organizational bounds on , and conditions under which can be lowered.
- Verification technologies’ impact: Quantitative evidence on how observability, interpretability, formal methods, test harnesses, and cryptographic provenance shift and expand .
- AI-verifies-AI risks: Methods to detect and quantify correlated blind spots when synthetic auditors share priors with ; design of independent, orthogonal verification ensembles and their efficacy.
- Ground truth production economics: Incentive design and market mechanisms to scale “verification-grade ground truth” (); cost functions, ownership, IP rights, and public-good underprovision risks.
- Liability-as-a-Service feasibility: Actuarial models, reinsurance capacity, pricing of tail risks, and regulatory frameworks needed to make autonomous outcome underwriting insurable and solvent.
- Trojan Horse externality () quantification: Leading indicators, measurement frameworks, and macro aggregation to detect “counterfeit utility” and hidden technical debt at firm, sector, and national levels.
- Alignment maintenance frontier: Formal characterization of the frontier, drift sensitivity parameter , and empirical tests of augmentation/observability interventions that sustain alignment over time.
- Missing Junior Loop magnitude: Causal identification strategies to isolate AI-driven erosion of apprenticeship pathways versus confounders; longitudinal evidence on expertise stock decline and recovery.
- Codifier’s Curse dynamics: Empirical studies of expert behavior converting tacit knowledge to ; net effects on distributed verification capacity and organizational resilience.
- Diversity collapse consequences: Long-run impacts of homogenized outputs on innovation, consumer welfare, and market competition; remedies that restore variety without raising prohibitively.
- Sandwich topology performance: Case studies and experiments evaluating “human intent → machine execution → human verification” throughput, cost, quality, and risk; organizational design trade-offs.
- Synthetic practice () efficacy: Controlled trials measuring skill acquisition, transfer to real-world performance, safety, calibration, and avoidance of “illusion of competence” effects.
- Verification vs. measurement boundary shifts: Empirical mapping of how AI expands what is measurable, path dependence effects, and risks of locking-in proxy objectives that misalign with intent.
- Macro model with verification constraint: General-equilibrium models that incorporate as a weak link; calibration to TFP, wage shares, and growth scenarios; comparative statics vs. compute-centric models.
- Distributional impacts and inequality: How measurability-biased technical change reallocates rents to verifiers/underwriters; wage dynamics, entry barriers, and training policy efficacy.
- Energy and compute constraints: Physical limits (energy, supply chains, climate externalities) tempering ; how these constraints interact with verification costs and policy.
- Sectoral case studies: High-stakes domains (clinicians, aviation, finance, industrial control) where is large—mapping failure modes, mitigation layers, and verifiable deployment thresholds.
- Instrumented environments: To what extent “sensorized” real-world systems (digital twins, telemetry, formal verification) can convert tacit verification to machine-checkable, safely lowering .
- Independence in verification governance: Organizational and technical separation of duties for auditors; standards for reproducibility, randomization, and compute enclaves to prevent capture and gaming.
- Standardized incident reporting: Design of taxonomies, metrics, and regulatory disclosure formats that make agent behavior auditable and comparable across firms and jurisdictions.
- Policy design under uncertainty: Liability allocation across supply chains (model providers, deployers, integrators), cross-border enforcement, and international coordination to prevent a race to the bottom.
- Markets for provenance and authenticity: Adoption barriers, privacy trade-offs, interoperability, and cryptographic protocols needed to make provenance credible and widely usable.
- Data quality under recursive synthesis: Monitoring and mitigation of model collapse in ecosystems with rising synthetic data; standards for dataset curation and provenance tagging.
- Principal–agent contract design with AI: Extensions of multitask incentive models to agentic systems; mechanisms to prevent proxy gaming and preserve effort on unmeasured value .
- ROI of observability stacks: Methods to quantify how specific observability tooling reduces feedback latency and errors, and how benefits translate into expansion and economic value.
- Benchmarks for verification, not output: Development of standardized “verification difficulty” benchmarks (latency, ambiguity, stakes) to complement capability benchmarks.
- Human agency metrics: Operational measures of “decaying human agency,” intent arbitration quality, and societal control in increasingly agentic production systems.
- Cultural and institutional variation: Cross-country studies on how norms, legal regimes, and workforce structures affect , , adoption, and externality accumulation.
- Tipping points and stability conditions: Formal identification of thresholds between “Augmented Economy” and “Hollow Economy,” hysteresis risks, and recovery dynamics once drift or debt accumulates.
- Alternative verification market designs: Viability of prediction markets, decentralized oracles, and peer verification networks to scale trustworthy outcomes; susceptibility to manipulation.
- Non-measurable economy microfoundations: Models of status, meaning-making, and coordination value; empirical strategies to estimate utility and price formation outside measurable execution.
- Ethical and welfare analysis: Normative frameworks to assess trade-offs between rapid deployment and human oversight, including distributional justice and intergenerational effects.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that operationalize the paper’s verification-first economics. Each item includes suggested sectors and practical tools/products/workflows, plus key assumptions/dependencies that determine feasibility.
Cross-Sector Foundations (apply across industries)
- Verification-first “sandwich” workflows (human intent → machine execution → human verification/underwriting)
- Sectors: software, finance, healthcare, legal, customer service, operations
- Tools/products/workflows: standardized intent briefs; structured acceptance criteria; sampling-based human QA of agent output; dual-approval for high-stakes outcomes; escalation paths and stop-loss limits; checklists tied to known failure modes; audit trails linked to tasks
- Assumptions/dependencies: availability of trained verifiers; clear acceptance metrics; management willingness to cap automation at the verifiable share; task decomposition compatible with review SLAs; incentives that reward verification quality, not just throughput
- Agent observability and traceability (lowering effective )
- Sectors: software/IT, finance, healthcare, e-commerce, robotics
- Tools/products/workflows: “flight recorder” for agents (execution traces, tool calls, prompts, retrieved documents); model telemetry; lineage tracking; prompt & retrieval diffing; evaluation harnesses; explainability summaries; anomaly detection; shadow-mode deployments
- Assumptions/dependencies: logging-by-default in agent frameworks; secure storage and privacy compliance; organizational capacity to review traces; standardized formats for cross-team reviews
- Cryptographic provenance and content authenticity
- Sectors: media, software supply chain, healthcare records, scientific publishing, advertising, education
- Tools/products/workflows: content signing (e.g., C2PA-like manifests); model and agent attestations (signing weights, prompts, tools, datasets); TEEs/remote attestation; SBOMs for models/agents; tamper-evident journals
- Assumptions/dependencies: interoperable standards; key management and governance; adoption by upstream ecosystems (browsers, CMS, LMS, EHRs)
- Outcome-based “Software-as-Labor” pilots with bounded liability
- Sectors: BPO, customer support, claims processing, RPA-intensive operations, sales ops
- Tools/products/workflows: per-outcome contracts with service credits; warranties for verifiable KPIs; escrow/bonding for tail-risk; standardized acceptance tests; automatic holdbacks for failed audits
- Assumptions/dependencies: tasks with clear, auditable KPIs; insurability of failure modes; historical loss data; sampling schemes to curb undetected defects
- Human augmentation and synthetic practice for accelerated mastery ()
- Sectors: healthcare (simulated cases), customer support, sales, software engineering, education, safety-critical ops
- Tools/products/workflows: skill simulators; realistic case generators; proficiency ladders with cryptographically signed assessment artifacts; adaptive difficulty; feedback-on-feedback training for verifiers
- Assumptions/dependencies: high-fidelity simulators; rubrics aligned with real-world performance; credentialing that recognizes sim-grade evidence
- Graceful degradation and safe defaults
- Sectors: all high-stakes deployments (finance, healthcare, energy, robotics)
- Tools/products/workflows: fail-safe policies, abstentions, “stop” capabilities, rate limits, guardrails; conservative fallbacks when confidence/coverage drops; risk scoring that routes to humans
- Assumptions/dependencies: reliable confidence/uncertainty estimates; pre-agreed safe baselines; monitoring to detect drift
- Independent verification of AI by diverse priors (avoid “AI verifying AI” with correlated blind spots)
- Sectors: software, finance, healthcare, media
- Tools/products/workflows: ensemble verifiers using different model families/providers; randomized human audits; adversarial test sets; red-teaming
- Assumptions/dependencies: access to heterogeneous models; budget for audits; clear protocols to resolve disagreement
Software and IT
- Test-driven code generation with mandatory verification gates
- Tools/products/workflows: AI writes code and tests; humans approve test plans and architecture; CI/CD enforces coverage and static analysis; production entry gated by audits and canarying
- Assumptions/dependencies: robust test culture; high-coverage suites; observability to catch runtime regressions
- Data lineage and “verification-grade” datasets ()
- Tools/products/workflows: dataset versioning with cryptographic hashes; documented provenance/licensing; gold-standard labels with inter-rater reliability; paid label bounties
- Assumptions/dependencies: governance for data curation; budget for high-quality labels; legal clarity on data rights
Healthcare
- Verified clinical documentation and coding with AI drafting
- Tools/products/workflows: AI produces drafts; checklists for upcoding/omission risks; random chart audits; provenance for sources; clinician sign-off captured in EHR
- Assumptions/dependencies: clear billing/clinical standards; audit capacity; malpractice frameworks for shared liability
- Prior authorization and claims automation with sampling audits
- Tools/products/workflows: outcome-based SLAs; insurer-provider shared audit portals; error-rate caps that trigger human review
- Assumptions/dependencies: agreed acceptance criteria; regulatory acceptance; dispute resolution pathways
Finance
- Transaction monitoring with human-underwritten escalations
- Tools/products/workflows: AI triages alerts; calibrated thresholds; humans adjudicate edge cases; periodic backtesting and bias reports
- Assumptions/dependencies: labeled historical data; model risk management (MRM) policies; regulator-aligned documentation
- Outcome-warranted back-office automation
- Tools/products/workflows: reconciliations, KYC refreshes, claims adjudication with measurable KPIs; service credits for misses
- Assumptions/dependencies: unambiguous KPIs; robust audit trails; contractual frameworks for LaaS
Education
- AI tutors with human-verified mastery checkpoints
- Tools/products/workflows: adaptive practice; teacher-reviewed performance artifacts; proctored assessments; provenance of tutoring logic and content
- Assumptions/dependencies: aligned curricula; secure assessment; equity in access to augmentation
Robotics/Manufacturing/Energy
- Human-in-the-loop autonomy with verified operation logs
- Tools/products/workflows: teleoperation fallback; standardized incident logs; maintenance predictions with human validation; “flight recorder” black boxes
- Assumptions/dependencies: reliable telemetry; operator training; safety case documentation
Government/Legal/Policy
- Procurement requirements for verifiable traces and incident reporting
- Tools/products/workflows: mandates for execution logs, audit exports, model cards; routine post-incident disclosures; minimum safe-default standards
- Assumptions/dependencies: agency capacity to audit; harmonized formats; supplier compliance
- Content authenticity in public communication
- Tools/products/workflows: signed releases, watermarked media; public-key registries; citizen-facing verification tools
- Assumptions/dependencies: cross-agency standards; adoption by media partners
Digital Platforms/Media
- Verified network scale () metrics and incentives
- Tools/products/workflows: authenticity scores; provenance-based ranking; penalties for unverifiable content; crowdsourced verification bounties
- Assumptions/dependencies: anti-abuse defenses; balanced false-positive/negative costs; UX for verification signals
Daily Life
- Personal agents with verification checkpoints
- Tools/products/workflows: spend caps and approvals; checklists before high-stakes actions (e.g., travel bookings, investments); provenance tags for content in inbox/feeds
- Assumptions/dependencies: consumer-friendly controls; clear explanations; secure identity and payment rails
- Cryptographically signed portfolios of work
- Tools/products/workflows: store proof-of-work artifacts with signatures from reviewers/clients; verifiable resumes
- Assumptions/dependencies: wallet/key management; employer acceptance; interoperability across platforms
Long-Term Applications
These use cases require further research, scaling, or policy development to become mainstream. They extend the paper’s framework to reshape markets and institutions around verification capacity.
Market Infrastructure and Risk
- Liability-as-a-Service (LaaS) and AI insurance markets
- Sectors: software, platforms, robotics, healthcare IT, fintech
- What emerges: specialized insurers/underwriters for autonomous outcomes; actuarial models for agent failure; standardized warranties and bonds; ratings for a firm’s verification stack
- Dependencies: loss histories; standardized incident taxonomies; enforceable disclosure; reinsurance capacity; legal clarity on attributable fault
- Independent verification utilities and ratings agencies
- What emerges: third-party “Underwriters Laboratories” for AI; certification tiers based on observability, provenance, and alignment maintenance
- Dependencies: consensus standards; funding models; auditor independence safeguards
Public Goods and Policy
- National/international verification infrastructure as a public utility
- Sectors: healthcare, education, public administration, critical infrastructure
- What emerges: shared ground-truth datasets; public audit log ledgers; open incident registries; interpretability sandboxes; reference testbeds
- Dependencies: governance for privacy/IP; sustained public funding; international interoperability
- Liability regimes that internalize tail risk
- What emerges: strict product liability for autonomous outcomes; safe-harbor tied to verifiability; mandatory incident reporting akin to aviation; cross-border treaties on agent accountability
- Dependencies: legislative consensus; judiciary capacity; harmonized cross-jurisdiction enforcement
Human Capital and Labor Markets
- Synthetic apprenticeship systems to repair the Missing Junior Loop
- Sectors: medicine, law, engineering, trades, public sector
- What emerges: accredited sim-based rotations; AI mentorship with human evaluation; on-chain credentials of verified competencies
- Dependencies: high-fidelity sims; accreditation reforms; employer acceptance; funding for supervised practice
- New professions: intent directors, verification engineers, AI actuaries, alignment maintenance officers
- What emerges: standardized training and licensure; compensation tied to risk absorption; career ladders centered on reduction
- Dependencies: curricula; industry demand; credentialing bodies
Technology and Product
- Provenance-by-design compute and model stacks
- Sectors: cloud/edge, chips, MLOps
- What emerges: hardware roots of trust; remote attestation for agents; immutable execution journals; privacy-preserving logging; “observability-optimized” model architectures
- Dependencies: secure enclaves adoption; performance overhead tolerances; standards across vendors
- Alignment maintenance platforms
- What emerges: continuous evaluation/generative red-teaming; drift detection; policy update pipelines; “graceful degradation” orchestration at fleet scale
- Dependencies: robust uncertainty estimation; scalable eval suites; integration hooks across agents
- Diverse-prior verification ensembles and market-mediated adjudication
- What emerges: verifier markets where disagreeing models/humans stake on claims; arbitration protocols; bounty mechanisms to surface ground truth
- Dependencies: incentive-compatible mechanisms; sybil resistance; legal recognition of on-chain evidence where applicable
Sector-Specific Transformations
- Healthcare: outcome-warranted care pathways and “diagnostic utilities”
- What emerges: AI-driven care plans whose outcomes are insured; verified longitudinal registries; patient-held provenance records
- Dependencies: real-world evidence pipelines; payer–provider alignment; malpractice reform
- Finance: auditable AI trading/compliance with ex-post accountability
- What emerges: mandated agent “black boxes” for trades; post-trade explainability audits; algorithmic accountability courts
- Dependencies: regulatory frameworks; secure, low-latency logging; market-wide standards
- Energy/Robotics: certified autonomous operations with safety cases
- What emerges: sector-specific certifications (FAA-like for drones/robots, NERC-like for grid agents); shared incident databases; simulation-to-field validation protocols
- Dependencies: regulators with domain expertise; interoperable telemetry; common benchmarking environments
Education and Science
- Verifiable mastery credentials and portfolios
- What emerges: credentials anchored in signed artifacts (labs, projects, clinics) verified by licensed underwriters; reduced reliance on time-based degrees
- Dependencies: employer uptake; secure identity/provenance; equity safeguards
- Autonomous R&D loops with human underwriters
- What emerges: agentic labs that hypothesize, simulate, experiment, and write; human committees underwrite risk and ethics; reproducibility tooling by default
- Dependencies: laboratory automation; experiment provenance standards; IRB/ethics integration
Platforms and Media
- Authenticity-first social/search platforms
- What emerges: ranking that prices provenance; synthetic-content containment lanes; creator verification rails; “verified network scale” as the core KPI
- Dependencies: business model alignment; user education; robust anti-spam infrastructure
- Ground-truth commons for the open web
- What emerges: funding and protocols to sustain human-generated reference material; incentives for diverse sources; anti-collapse safeguards against recursive training on synthetic data
- Dependencies: public/private funding; search/discovery reforms; standards to label synthetic content
Notes on Key Cross-Cutting Assumptions
- Economic: continued decline in (compute, tooling) and relatively inelastic unless observability and augmentation improve; tasks have verifiable slices large enough to sustain outcome contracts.
- Technical: reliable provenance (signing, attestation), standardized execution traces, usable uncertainty estimates, and scalable evaluation suites; access to heterogeneous models for independence.
- Legal/Regulatory: clarity on AI liability, evidence admissibility for digital logs/signatures, and enforceable incident reporting; sector-specific certification capacity.
- Organizational: incentives that value verification and underwrite outcomes; investment in observability and human training; cultural acceptance of “graceful degradation.”
- Social/Ethical: privacy-preserving logging, fair access to augmentation, and safeguards against centralization harms or exclusion from the non-measurable economy.
By deploying immediate verification-centric practices while building the long-term infrastructure to scale human oversight alongside agentic power, organizations can expand the verifiable share of deployment (), shrink the Measurability Gap (), and convert cheap execution into trusted outcomes rather than systemic risk.
Glossary
- AGI: Artificial General Intelligence; a level of AI with broadly human-like competence across tasks. "As this synthetic intelligence comes online, the semantic debate over whether it constitutes ``Artificial General Intelligence'' (AGI) is rapidly becoming a distraction."
- Agentic economy: An economic regime where autonomous agents act with broad agency rather than narrow instructions. "in an agentic economyâwhere autonomous agents () operate with broad agency rather than narrow instructionâthe binding constraint on growth is no longer the scarcity of intelligence, but the scarcity of trust."
- Alignment maintenance frontier: The boundary beyond which system alignment cannot be sustained given fixed oversight resources. "We define a new alignment maintenance frontier: for any fixed oversight allocation (), alignment is only sustained below the frontier; above it, alignment decays unless institutions systematically step up effective steering capacity through human augmentation and observability."
- Augmented Economy: A proposed outcome where scaled verification enables safe, unbounded discovery and execution. "By scaling verification alongside agentic power, the very forces that threaten systemic collapse become the catalyst for unbounded discovery, experimentation, and execution---powering an ``Augmented Economy''."
- Base-alignment: Foundational alignment of model objectives and behaviors to human intent and safety norms. "Graceful Degradation: Investing in base-alignment and robustness so that when oversight inevitably falters within the Measurability Gap (), systems revert to safe baseline policies rather than optimizing aggressively in unverifiable regimes."
- Campbell's Law: The principle that metrics used for decision-making become targets and get corrupted. "This echoes Campbell's Law \citep{Campbell1979}: ``the more any quantitative social indicator is used for social decision-making, the more subject it will be to corruption pressures.''"
- Codifier's Curse: The dynamic where experts codify their tacit knowledge into training data that ultimately automates their roles. "From within, the Codifier's Curse hollows out existing expertise, as senior professionals rationally mine their own tacit knowledge to create the proprietary ground truth () that trains their replacements."
- Cost to Automate (c_A): The cost of automating tasks via compute and accumulated knowledge. "We model the transition toward AGI as the collision of two racing cost curves: an exponentially decaying Cost to Automate (), driven by compute and accumulated knowledge, and a biologically bottlenecked Cost to Verify (), bounded by human time and embodied experience."
- Cost to Verify (c_H): The human time and effort required to validate AI outputs. "The first widely adopted systems clustered around domains where humans can verify outputs in secondsâchat, images, short bursts of codeâbecause the marginal cost to verify () was negligible relative to the value created."
- Cryptographic provenance: Cryptographic methods to prove authenticity and origin of data or actions. "as measurable execution commoditizes toward the marginal cost of compute, rents migrate to what remains scarce---verification-grade ground truth, cryptographic provenance, and liability underwriting (the ability to insure outcomes rather than merely generate them)."
- Distributional shift: A change between training and deployment data distributions that can degrade performance. "\citet{Ovadia2019} show that neural networks are overconfident under distributional shift."
- Drift pressure: The tendency of autonomous systems to diverge from intended behavior as oversight weakens. "As widens, drift pressure inevitably rises."
- Hidden technical debt: Implicit, accumulating maintenance burdens in ML systems that cause fragility. "\citet{Sculley2015} identify hidden technical debt in ML systems: this paper's ``Trojan Horse'' externality () is the macroeconomic aggregation of this technical debt."
- Hollow Economy: A regime with explosive nominal output but declining real utility and human agency. "Left unmanaged, these forces exert a gravitational pull toward a ``Hollow Economy'' characterized by explosive nominal output but decaying human agency."
- Human-in-the-loop: A design pattern where humans oversee AI processes; here, argued to be unstable at scale. "Critically, the current, comfortable ``human-in-the-loop'' equilibrium is dynamically unstable."
- Iceberg Index: A measure of hidden AI-exposed skill overlap beyond observed adoption. "\citet{Chopra2025} reinforce this with the ``Iceberg Index,'' showing that the hidden footprint of AI-driven skills overlap reaches 11.7\% of U.S. wage value (about a fivefold multiple of the 2.2\% linked to skills with observed AI adoption), implying far broader latent exposure than current job-loss headlines reveal."
- Jagged technological frontier: The uneven profile of AI capabilities across tasks, causing unpredictable failures. "This variance forms the microfoundation of what \citet{DellAcqua2023} vividly term the ``jagged technological frontier.''"
- Knightian uncertainty: Uncertainty that is not quantifiable with probabilities. "We retained a monopoly on the ``unknown unknowns''âthe domains of Knightian uncertainty where humans step off the map, relying on embodied experience and hard-won intuition."
- Large World Models: Models that represent physics, causality, and counterfactuals to generalize to novel environments. "culminating in Large World Models capable of representing physics, causality, and counterfactualsâthey threaten to shatter this final constraint."
- Liability underwriting: Absorbing financial responsibility for AI-driven outcomes by insuring or warranting them. "rents migrate to what remains scarce---verification-grade ground truth, cryptographic provenance, and liability underwriting (the ability to insure outcomes rather than merely generate them)."
- Liability-as-a-Service: A business model offering outcome insurance and risk absorption for autonomous systems. "Consequently, firms will be valued primarily on their capacity to absorb tail risk through Liability-as-a-Service."
- Measurability-Biased Technical Change: Technological progress that favors tasks reducible to metrics over tacit tasks. "We formalize a shift from standard skill-biased to Measurability-Biased Technical Change."
- Measurability Gap: The widening gap between what agents can execute and what humans can verify. "This structural asymmetry widens a Measurability Gap () between what agents can execute and what humans can afford to verify, and determines the verifiable share of deployment () that separates truly productive agentic output from merely plausible output."
- Missing Junior Loop: The collapse of apprenticeship pathways that erodes future expert verifiers. "It is eroded from below as apprenticeship pathways collapse (the Missing Junior Loop), shrinking the future stock of human expertise () precisely when oversight becomes most valuable."
- Model collapse: Performance degradation from recursive training on synthetic data. "\citet{Shumailov2024} demonstrate model collapse, where recursive training on synthetic data degrades the distribution."
- Observability: Tooling that makes agent behavior legible and auditable to reduce verification latency. "Observability: Deploying tools that compress high-dimensional agent behavior into signals experts can reliably process, lowering effective feedback latency and expanding the verification frontier."
- Principal--agent delegation problem: The challenge of delegating decisions to agents whose incentives or information differ from principals'. "our framework departs significantly from this compute-centric paradigm by highlighting the principal--agent delegation problem inherent in autonomous systems."
- Productivity J-Curve: The pattern where benefits of new tech lag due to required complementary investments. "This distinction empirically grounds the highly influential ``Productivity J-Curve'' described by \citet{BrynjolfssonRockSyverson2021}."
- Proxy optimization: Optimizing measured proxies instead of true objectives, leading to misaligned outcomes. "This reduces drift sensitivity (), ensuring that weakened verification triggers caution rather than unchecked proxy optimization."
- Sandwich topology: Organizational flow of human intent → machine execution → human verification/underwriting. "reorganizing around a ``sandwich'' topology (human intent machine execution human verification and underwriting)."
- Skill-biased technical change: Technological change that raises demand for certain skills; used as a baseline comparison. "We formalize a shift from standard skill-biased to Measurability-Biased Technical Change."
- Software-as-Labor: Outcome-based monetization where software delivers and is paid for labor-equivalent results. "the dominant revenue model will shift from monetizing software access (Software-as-a-Service) to monetizing outcomes (``Software-as-Labor'')."
- Tail risk: Low-probability but high-impact adverse outcomes requiring special risk management. "implementing liability regimes that internalize tail risksâensuring that safe scaling is not outcompeted by reckless deployment."
- Trojan Horse externality: Hidden systemic risk introduced by unverified agent outputs that appear beneficial. "This introduces a systemic ``Trojan Horse'' externality () of misaligned, unaccountable output into production: measured activity rises, but hidden debt accumulates in the gap between visible metrics and actual human intent."
- Verification bandwidth: The limited human capacity to validate, audit, and underwrite outcomes. "It is human verification bandwidth: the scarce capacity to validate outcomes, audit behavior, and underwrite meaning and responsibility when execution is abundant."
- Verification-grade ground truth: High-quality, trusted data suitable for certifying and auditing AI systems. "investing heavily in observability, expanding verification-grade ground truth, and reorganizing around a ``sandwich'' topology (human intent machine execution human verification and underwriting)."
- Verifiable share of the economy: The portion of output that can be reliably validated and underwritten. "This structural asymmetry turns the verifiable share of the economy () into a severe bottleneck."
Collections
Sign up for free to add this paper to one or more collections.