GEMS: Agent-Native Multimodal Generation with Memory and Skills
Abstract: Recent multimodal generation models have achieved remarkable progress on general-purpose generation tasks, yet continue to struggle with complex instructions and specialized downstream tasks. Inspired by the success of advanced agent frameworks such as Claude Code, we propose \textbf{GEMS} (Agent-Native Multimodal \textbf{GE}neration with \textbf{M}emory and \textbf{S}kills), a framework that pushes beyond the inherent limitations of foundational models on both general and downstream tasks. GEMS is built upon three core components. Agent Loop introduces a structured multi-agent framework that iteratively improves generation quality through closed-loop optimization. Agent Memory provides a persistent, trajectory-level memory that hierarchically stores both factual states and compressed experiential summaries, enabling a global view of the optimization process while reducing redundancy. Agent Skill offers an extensible collection of domain-specific expertise with on-demand loading, allowing the system to effectively handle diverse downstream applications. Across five mainstream tasks and four downstream tasks, evaluated on multiple generative backends, GEMS consistently achieves significant performance gains. Most notably, it enables the lightweight 6B model Z-Image-Turbo to surpass the state-of-the-art Nano Banana 2 on GenEval2, demonstrating the effectiveness of agent harness in extending model capabilities beyond their original limits.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces GEMS, a smart “helper system” that sits on top of image-generating AI models. Its goal is to make those models follow complicated instructions better—especially when prompts have many parts (like object positions, text in the image, style, etc.) or when the task requires special skills (like neat text rendering or artistic layouts).
In short: GEMS turns a regular image model into a small team of helpful “agents” that plan, check, remember, and improve drawings step by step.
What questions were the researchers trying to answer?
The paper asks:
- How can we help image-generating AI handle complex, multi-step instructions without retraining the model?
- Can a system that plans, checks, and learns from past attempts (like a team with a shared memory) make images more accurate and high-quality?
- Can we plug in domain-specific “skills” (like how to render clean text or organize objects in space) only when needed, to do better on specialized tasks?
How does GEMS work?
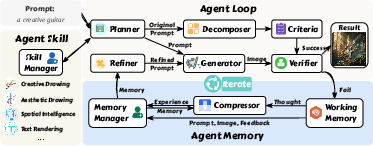
Think of GEMS as a team with a plan, a checklist, a shared diary, and a toolbox. It runs in a loop: try → check → improve → try again. It has three main parts.
1) Agent Loop: the step-by-step improvement cycle
Analogy: Like a student drafts a drawing, compares it to the instructions, fixes mistakes, and tries again.
- Planner: Reads your prompt and pulls in any useful skills. It writes a strong starting plan for the image.
- Decomposer: Breaks your prompt into a simple checklist of “must-haves” (yes/no items), like “Is there a red hat?”, “Is the cat under the table?”
- Generator: Makes the image from the current plan.
- Verifier: Checks the image against the checklist and says what’s right or wrong.
- Refiner: Uses the feedback (and the memory, see below) to improve the plan for the next try.
This loop repeats a few times and stops early if all checklist items are satisfied.
2) Agent Memory: the shared diary (with smart summaries)
Analogy: The team keeps a neat diary of what they tried—saving the important parts and summarizing long thoughts.
- It stores factual things exactly (the prompts used, the images made, and the yes/no feedback).
- It compresses long internal “thinking notes” into short “lessons learned” so the next attempt doesn’t get overwhelmed with too much text.
- This memory helps the system improve steadily instead of repeating the same mistakes.
3) Agent Skill: the on-demand toolbox
Analogy: A big toolbox where you only pull out what you need.
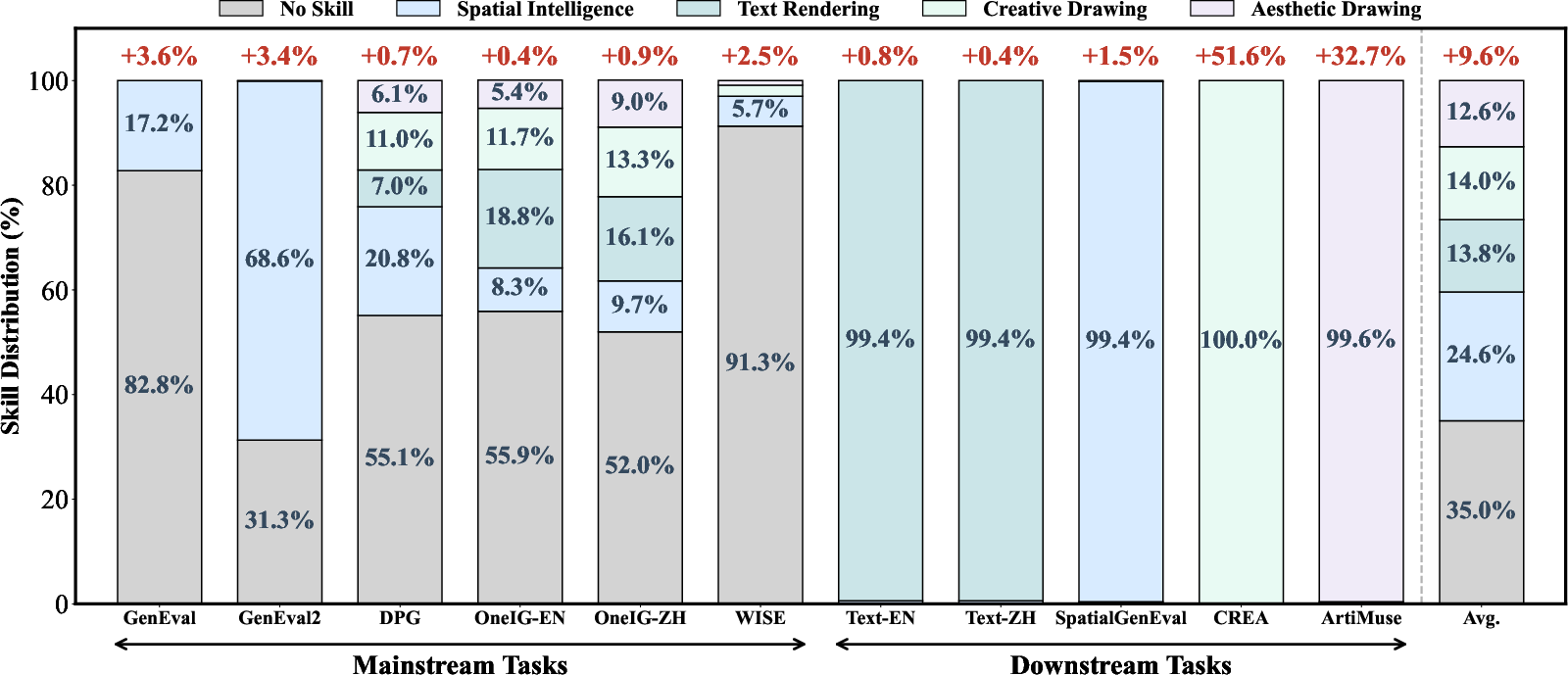
- GEMS has a library of skills for special tasks (e.g., Creative Drawing, Aesthetic Drawing, Text Rendering, Spatial Intelligence).
- It only loads the full instructions of a skill when the Planner detects the task needs it. This keeps things fast and focused.
- Skills are easy to add—just drop in a simple instruction file—and the system can start using it when relevant.
What did they find?
The researchers tested GEMS on many benchmarks that check if models follow instructions well and on specialized tasks. They used two different image models (one small and fast, one larger) to show GEMS works broadly.
Here are the key results:
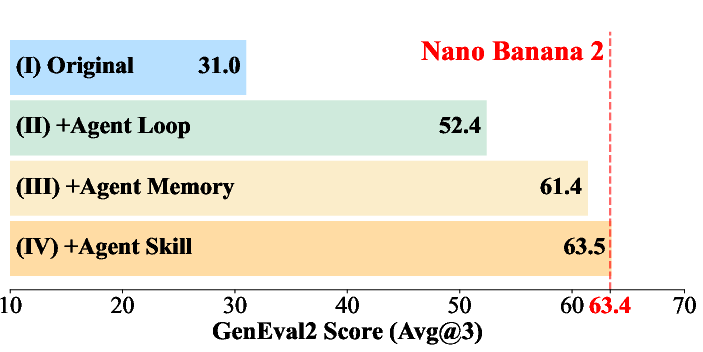
- Big overall gains without retraining the models:
- With a small, efficient model called Z-Image-Turbo (6B parameters), GEMS boosted scores by about +14 points on both mainstream and specialized tasks on average.
- With a larger open-source model (Qwen-Image-2512), GEMS also improved results a lot: about +16 points on mainstream and +8 points on specialized tasks on average.
- Beats stronger closed models on a tough benchmark:
- Using the small Z-Image-Turbo plus GEMS, the system surpassed a leading closed model (Nano Banana 2) on GenEval2, a benchmark known for tough, complex instructions.
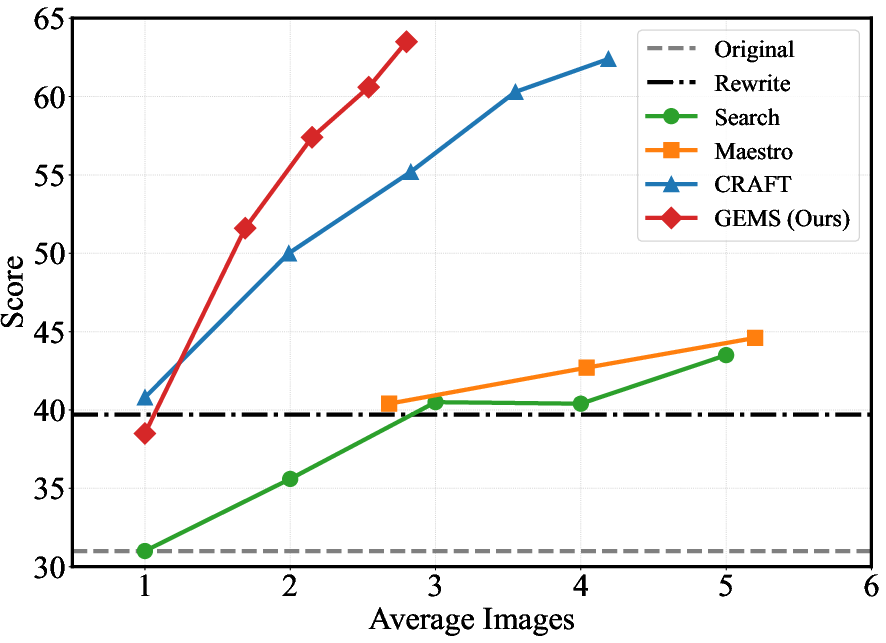
- Efficient and practical:
- GEMS often finishes in just a few tries (roughly around 3 images on average) thanks to early stopping and good planning.
- It’s not just “try randomly until it works”—the success rate increases steadily over rounds because GEMS learns from feedback and memory.
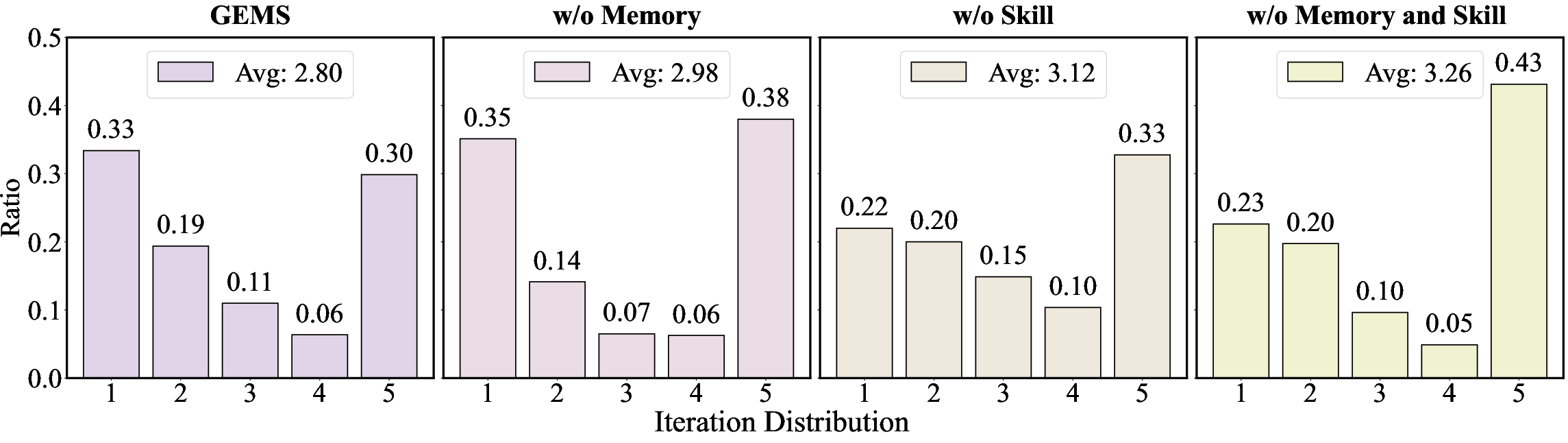
- Why the parts matter:
- The Agent Loop alone already helps by trying, checking, and refining.
- Agent Memory adds more improvement by keeping the right history: storing prompts/images/feedback and using short summaries of lessons instead of long, noisy “thinking logs.”
- Agent Skill gives extra boosts on specialized tasks like text rendering and spatial layouts, where general prompt rewriting often fails.
Why is this important?
- Works with what you already have: GEMS improves image models at “inference time” (when generating images), meaning you don’t need to retrain or rebuild the whole model.
- Handles the “long tail” of hard prompts: Complicated instructions and specialty tasks are exactly where most models struggle; GEMS helps them get those right more often.
- Scalable and flexible: New skills can be added easily, and GEMS only loads what it needs—so it’s both powerful and efficient.
- Smaller models, bigger results: With smart planning, checking, memory, and skills, even a lightweight model can beat larger, closed systems on complex tasks. That’s good for cost, speed, and accessibility.
Final takeaway
GEMS turns image generation into a guided, learn-as-you-go process. By using a loop to try and improve, a memory to remember what worked, and a toolbox of skills for special needs, it helps AI make images that better match complex instructions. This could make creative apps, design tools, and educational software smarter and more reliable—without needing bigger models or expensive retraining.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to guide concrete follow-up research.
- Verifier reliability and calibration: Quantify how well the MLLM-based Verifier’s binary judgments correlate with human evaluations across benchmarks; report false positive/negative rates, robustness to visual artifacts, and sensitivity to prompt wording.
- Decomposition quality: Evaluate the accuracy of the Decomposer’s atomic-criteria extraction (e.g., with a labeled dataset of ground-truth constraints), and analyze how decomposition errors propagate to downstream refinement.
- Graded vs. binary feedback: Investigate whether replacing/augmenting binary pass/fail with graded, weighted, or uncertainty-aware feedback improves optimization stability and final quality.
- Skill-triggering precision/recall: Measure the precision, recall, and failure modes of the skill-selection mechanism; report mis-triggering rates and their impact on outcomes.
- Multi-skill composition: Lift the “max triggered skills = 1” constraint and study strategies for composing, ordering, and conflict-resolving multiple skills within a single task.
- Skill scalability: Stress-test the on-demand skill repository with hundreds/thousands of skills to quantify retrieval latency, token overhead, and interference between similarly scoped skills.
- Skill generalization: Assess how skills authored for one dataset/domain transfer to unseen domains and tasks; include zero-shot and cross-lingual skill transfer tests.
- Skill lifecycle and governance: Specify processes for skill curation, versioning, validation, and rollback; define standards for contributor-authored SKILL.md quality and safety.
- Memory compressor design: Detail the Compressor’s algorithm/training (rules vs. learned models), compression ratio, and ablations on alternative summarization strategies (e.g., contrastive summaries, retrieval-augmented memory).
- Memory growth and pruning: Analyze memory size growth, token costs, and forgetting policies over longer horizons; compare FIFO, saliency-based, and task-aware pruning.
- Cross-task/session memory: Explore whether experiences can be shared across tasks/sessions (continual learning) without performance degradation or privacy leakage (“memory contamination”).
- Robustness of memory-derived experiences: Provide interpretability examples of experiences E_i, and test their stability across random seeds and varied prompts.
- Isolating stochastic gains vs. directed optimization: Control for multi-shot stochasticity by comparing to pure resampling baselines with identical sampling budgets to quantify the Refiner’s true contribution.
- Stopping criteria and tie-breaking: Study alternative anytime stopping rules (e.g., marginal gain thresholds, confidence estimates) and tie-breakers beyond sum of passed criteria (e.g., aesthetic/semantic preferences).
- Impact of MLLM backend choice: Replace Kimi K2.5 with open-source MLLMs of varying strengths; quantify sensitivity of GEMS performance to the Verifier/Refiner model family and scale.
- Compute and latency accounting: Report end-to-end wall-clock time, MLLM token costs, and GPU hours per task (not just images per task), including variance across benchmarks.
- Parameter sensitivity: Provide sensitivity analyses for N_max, temperature, guidance scales, and Refiner prompt templates; include robustness across seeds.
- Generator diversity: Expand beyond two backends (Z-Image-Turbo, Qwen-Image-2512) to diffusion transformers, flow models, and video generators; report consistency of gains and failure modes.
- Benchmark coverage and leakage risk: Since four skills are selected to match evaluation tasks, conduct blinded evaluations on unseen benchmarks to rule out benchmark-specific overfitting.
- Human evaluation: Complement automatic metrics with human preference studies (pairwise comparisons) on alignment, aesthetics, and text correctness; analyze disagreements with MLLM verifiers.
- Text rendering verification: Replace or augment MLLM verification with OCR-based checks and edit-distance scoring for text rendering tasks; quantify improvements over MLLM-only judging.
- Spatial reasoning verification: Evaluate specialized verifiers (e.g., object detectors, keypoint/layout analyzers) versus MLLM-only verification for SpatialGenEval; compare accuracy and cost.
- Safety and alignment: Examine how iterative refinement and skill prompts interact with safety filters; test for jailbreaks, unsafe content amplification, and propose mitigation within the agent loop.
- Cross-lingual generalization: Extend evaluations beyond English/Chinese to low-resource languages and mixed-language prompts; measure decomposition and verifier performance by language.
- Open-ended creativity: Investigate how binary criteria handle creative, non-prescriptive prompts; propose soft goals or preference models for aesthetics and style compliance.
- Failure-mode taxonomy: Provide a systematic error analysis (e.g., decomposition misses, verifier hallucinations, refiner regressions, skill misfires) with quantitative incidence rates.
- Data and code transparency: Release prompts, seeds, decomposed criteria, and verifier/refiner templates to enable exact reproducibility; specify any prompt filtering or canonicalization.
- Tool use integration: Explore invoking external tools (OCR, depth/pose estimators, CLIP-based scorers) as skills or verifiers within the loop; measure benefits vs. added complexity.
- Continual skill learning: Study automatic induction/refinement of skills from accumulated experiences E_i (e.g., converting frequent patterns into reusable micro-skills); evaluate stability.
- Theoretical framing: Develop convergence or sample-complexity analyses for agentic iterative refinement under noisy verifiers and imperfect decomposition.
- Generalization to other modalities: Test GEMS on multimodal generation beyond text-to-image (video, 3D, audio, image-to-image/editing) and report necessary adaptations to loop, memory, and skills.
- Aesthetic vs. fidelity trade-offs: Quantify how Aesthetic/Creative skills affect semantic alignment and factual correctness; propose multi-objective optimization or Pareto-front reporting.
- Adversarial robustness: Assess susceptibility to adversarial prompts/images that exploit the verifier or refiner (e.g., prompt injection in SKILL.md, visual adversarial patterns).
- Privacy implications: If memory persists across tasks/users, define privacy guarantees and mechanisms for redaction, isolation, and auditability of stored artifacts and experiences.
- Fairness and bias: Evaluate demographic, cultural, and content biases introduced or amplified by skills and the refiner; propose debiasing skills or verifier-aware constraints.
- Skill cost–benefit modeling: Provide a principled policy for when to trigger a skill (or multiple) given token/latency budgets and predicted marginal gains; learnable policies vs. heuristics.
Practical Applications
Overview
GEMS is an agent-native framework for multimodal generation that wraps existing image (and potentially other) generative models with three innovations: (1) an iterative, closed-loop multi-agent pipeline (Planner/Decomposer/Generator/Verifier/Refiner), (2) a persistent, hierarchically compressed Agent Memory that preserves factual artifacts and distilled “experiences” across iterations, and (3) an extensible Agent Skill system that loads domain-specific expertise on demand. The framework improves instruction following, spatial reasoning, and specialized tasks (e.g., text rendering, creative/aesthetic drawing) while reducing redundancy and compute via early stopping. Below are practical applications grouped by deployability horizon.
Notes on feasibility and dependencies
- GEMS is model-agnostic but depends on access to a capable image generator (e.g., Z-Image-Turbo, Qwen-Image) and an MLLM-based Verifier.
- Benefits rely on decomposition of tasks into evaluable criteria and on well-specified Skill packs for target domains.
- Iterative loops incur some compute overhead; early stopping and memory compression help but budgets matter.
- For safety- and regulation-critical domains (e.g., healthcare), expert-curated Skills and human oversight are required.
Immediate Applications
These can be deployed with existing open-source or commercial T2I models and MLLMs, using GEMS’ agent loop, memory, and skill manifest as an inference-time wrapper.
- Brand-safe marketing asset generation — Sectors: advertising, retail/e-commerce
- What: Produce campaign visuals that comply with strict brand guides (colors, typography, logo placement) and exact text content.
- How (tool/product/workflow): “Brand Skill Pack” (logo usage, color palettes, legal disclaimers) + Decomposer/Verifier defining atomic checks (e.g., Pantone match, clearance margins) + closed-loop refinement; export into DAM/CM systems.
- Assumptions/dependencies: Accurate text rendering skill; reliable OCR within Verifier; access to brand guidelines encoded as Skills; modest extra inference budget for iterations.
- Dynamic A/B testing for creatives — Sectors: growth marketing, content ops
- What: Rapidly generate and evaluate multiple variants against structured criteria (e.g., call-to-action readability, focal object prominence).
- How: Batch-run GEMS with predefined criteria and early stopping; use Agent Memory to log “experience” summaries for performance analytics; integrate with experimentation platforms.
- Assumptions/dependencies: Verifier probes align with business KPIs; enough compute for iterative trials; consent for automated content decisions.
- Catalog and listing imagery with precise constraints — Sectors: marketplaces, real estate, auto, C2C
- What: Generate clean, compliant product images (angles, background removal, text overlays for specs) with exact spatial layout.
- How: “E-commerce Product Skill” capturing angles, background rules, badge placement; Decomposer to enforce atomic layout rules; GEMS loop to refine until pass.
- Assumptions/dependencies: Spatial reasoning skill quality; high-resolution generator backends for crisp overlays; consistent OCR/visual QA.
- Poster, signage, and label design with exact text — Sectors: SMBs, events, packaging, education
- What: Create flyers, event posters, and labels requiring exact multi-lingual text placement and legibility.
- How: “Text Rendering Skill” + criteria for font size, contrast ratio, safe areas; Verifier with OCR to check correctness; export to vector or high-res raster.
- Assumptions/dependencies: Robust OCR, especially for multilingual content; generator that preserves text well; human-in-the-loop for final proofing.
- Academic and technical illustrations — Sectors: higher education, R&D, publishing
- What: Generate figures (schematics, conceptual diagrams) precisely aligned to multi-constraint prompts (labels, spatial relations, legends).
- How: “Academic Illustration Skill” for diagram conventions, axis labeling; Decomposer creates checks for text, spatial alignment; Memory stores experience for reproducibility and figure revisions.
- Assumptions/dependencies: Legal / ethical standards for synthetic figures; publisher formatting requirements encoded as skills; final human review.
- Creative ideation assistant for concept art — Sectors: media/entertainment, gaming, design studios
- What: Iteratively refine compositions, styles, and spatial arrangements guided by creative or aesthetic skills.
- How: “Creative Drawing” and “Aesthetic Drawing” Skills; GEMS loop to explore and converge; Memory experiences capturing what improved appeal.
- Assumptions/dependencies: Stylistic goals formalized into criteria; generator supports target art styles; rights management for training data and outputs.
- Layout-aware content production for infographics — Sectors: journalism, finance, consulting
- What: Generate infographics with strict placement of icons, annotations, and textual elements.
- How: “Spatial Intelligence” + “Text Rendering” Skills; criteria for spacing/alignment; Verifier loops to pass atomic layout rules; export templates into design tools.
- Assumptions/dependencies: Clear decomposition of layout constraints; vector-compatible export or post-processing pipeline.
- Cost-efficient SMB image generation — Sectors: SMEs across verticals
- What: Use smaller backends (e.g., 6B Z-Image-Turbo) wrapped with GEMS to hit performance comparable to larger closed systems on complex tasks.
- How: Deploy GEMS as a lightweight service or plugin; early stopping reduces average images per task; Skill packs for common SMB needs (menus, promo cards).
- Assumptions/dependencies: Local or cloud MLLM availability; acceptable latency with 2–5 iterations; basic DevOps capability.
- Compliance and accessibility QA for visuals — Sectors: public sector, enterprise compliance
- What: Automatically check for accessibility (contrast, font size), watermark presence, and banned content in generated images.
- How: Verifier criteria encode WCAG-like checks; Agent Loop refines until compliant; Memory stores audit trail for reviews.
- Assumptions/dependencies: Reliable visual metric estimation (contrast, size); compliance policies captured as Skills; human approval gates.
- Reproducible content pipelines with audit trails — Sectors: enterprises, procurement, legal
- What: Maintain traceable generation trajectories (prompts, images, pass/fail vectors, compressed experiences) for governance and reproducibility.
- How: Leverage Agent Memory as an immutable artifact; integrate logs with content governance and MRM tools; export “experience” summaries for reviews.
- Assumptions/dependencies: Secure storage; PII/content safety filters; policy alignment for synthetic media documentation.
Long-Term Applications
These require further research, scaling beyond images (e.g., video/3D), stronger verification, or domain certification.
- Agentic video and 3D content generation — Sectors: advertising, gaming, digital twins, AR/VR
- What: Extend GEMS’ loop/memory/skills to multi-frame video and 3D scenes with temporal/spatial consistency constraints.
- How: Video/3D generator backends; “Cinematic Skill” for shot continuity, “3D Layout Skill” for scene constraints; temporal verifiers.
- Assumptions/dependencies: Mature video/3D generators; verifiers that evaluate temporal coherence; larger compute and memory budgets.
- Verticalized skill marketplaces and auto-skill learning — Sectors: software platforms, SaaS ecosystems
- What: A marketplace of certified Skill packs (e.g., cartography, medical illustration, UI wireframing), with skills learned or updated from user trajectories.
- How: Standardized SKILL.md schemas; telemetry from Memory experiences to suggest skill updates; curation toolchains and certification workflows.
- Assumptions/dependencies: Governance for quality and IP; mechanisms to avoid leaking sensitive data; contributor ecosystem incentives.
- Regulated-domain content (healthcare, aviation, legal) — Sectors: healthcare, pharma, aerospace, legal tech
- What: Generate visuals that meet strict domain standards (e.g., anatomy diagrams, device labeling).
- How: Expert-authored Skills embedding regulatory guidelines; multi-stage verification; human approval gates with audit logs.
- Assumptions/dependencies: Regulatory compliance validation; domain-expert involvement; high-fidelity text and symbol rendering; robust safety guardrails.
- End-to-end “design copilot” integrated into creative suites — Sectors: creative software (Adobe plugins, Figma/Canva), enterprise design ops
- What: An embedded agent that plans, drafts, self-checks, refines, and documents design assets collaboratively with users.
- How: Deep integrations via APIs; shared Memory across projects for style consistency; team Skill packs for brand and accessibility.
- Assumptions/dependencies: Vendor integrations; UX for human-in-the-loop edits; content provenance standards (e.g., C2PA) support.
- Procedural content generation for interactive worlds — Sectors: gaming, simulation, robotics sim
- What: Generate assets and level layouts that satisfy complex constraints (playability, visibility, navigability).
- How: “Level Design Skill” + spatial verifiers; Memory for tracking rules that improve player experience; iterative loops to meet playtest criteria.
- Assumptions/dependencies: Domain-specific verifiers for playability; pipelines to convert images to game-ready assets; compute for batch iteration.
- Enterprise knowledge-to-visual pipelines — Sectors: BI/analytics, finance, consulting
- What: Transform structured knowledge (briefs, requirements) into accurate visuals with guaranteed constraint satisfaction and traceability.
- How: LLM-based Decomposer against specs; organization-specific Skills (brand, legal, accessibility); Memory-based governance for audits.
- Assumptions/dependencies: Reliable parsing of long, complex briefs; alignment between verifiers and business rules; secure data handling.
- Standards and policy tooling for agentic generation — Sectors: standards bodies, policymakers, public institutions
- What: Define and audit standards for agentic image generation (logs, criteria, skills), enabling transparent procurement and risk management.
- How: Exportable Memory/Verifier artifacts as compliance evidence; certification suites for Skill packs; benchmark-based acceptance tests.
- Assumptions/dependencies: Consensus on logging formats and benchmarks; privacy-aware logging; coordination with international standards.
- Cross-modal teaching assistants and curriculum tools — Sectors: education, EdTech
- What: Generate worksheets, diagrams, and step-by-step visuals aligned to curriculum constraints and accessibility needs.
- How: “Curriculum Skill” packs by grade/subject; Decomposer creates atomic learning objectives; iterative refinement to meet pedagogy and accessibility.
- Assumptions/dependencies: Curriculum licensing and educator validation; child-safe content filters; robust multilingual text rendering.
- Human preference learning from memory trajectories — Sectors: personalization, recommendation
- What: Use compressed experiences and verification outcomes to learn user-specific preferences and automatically steer future generations.
- How: Preference models trained from Memory E_i; per-user Skill tuning; policy rules for on-device vs. cloud learning.
- Assumptions/dependencies: Consent and privacy compliance; drift detection; guardrails against overfitting or bias amplification.
- Multi-agent orchestration across tools and modalities — Sectors: MLOps, creative pipelines
- What: Coordinate generators (image, vector, layout engines) and tool APIs (OCR, color checkers) in a single agentic loop with shared Memory and Skills.
- How: Toolformer-style integrations; modular Verifier chains; Memory as a shared blackboard for stateful planning.
- Assumptions/dependencies: Stable APIs and tool reliability; latency management; robust error handling and fallbacks.
By deploying GEMS as an inference-time, agentic harness around current T2I systems, organizations can immediately improve instruction adherence, spatial/layout precision, and specialized domain fidelity. Over time, expanding Skill libraries, stronger verifiers, and multi-modal backends can unlock rigorous, auditable, and domain-compliant visual generation at enterprise and societal scale.
Glossary
- Agent harness: A framework or wrapper that augments a model with agentic components to extend capabilities. "demonstrating the effectiveness of agent harness in extending model capabilities beyond their original limits."
- Agent Loop: The iterative, multi-agent process that plans, generates, verifies, and refines outputs to improve quality. "Agent Loop introduces a structured multi-agent framework that iteratively improves generation quality through closed-loop optimization."
- Agent Memory: A persistent store of past states and compressed insights that guides future iterations. "Agent Memory provides a persistent, trajectory-level memory that hierarchically stores both factual states and compressed experiential summaries"
- Agent Skill: A modular repository of domain-specific know-how that is dynamically loaded to assist tasks. "Agent Skill offers an extensible collection of domain-specific expertise with on-demand loading"
- Agentic paradigms: Design approaches that treat systems as autonomous agents with planning, memory, and skills. "In contrast, GEMS adopts advanced agentic paradigms to address these limitations."
- Agentic reasoning: Structured, agent-like reasoning used to plan, assess, and refine generation. "demonstrating that agentic reasoning and domain-specific expertise can effectively push beyond the inherent boundaries of foundational models."
- Atomic visual requirements: Minimal, binary-checkable criteria that decompose complex prompts for evaluation. "partitions the user's original prompt into a set of atomic visual requirements "
- Binary feedback vector: A vector of yes/no signals indicating which criteria are satisfied by a generated output. "It maps the visual and textual inputs to a binary feedback vector "
- Chain-of-Thought (CoT): An explicit step-by-step reasoning process used to guide generation. "introduced Chain-of-Thought (CoT) reasoning to provide more guidance for multimodal generation."
- Closed-loop optimization: An iterative process where feedback from evaluation informs the next action. "iteratively improves generation quality through closed-loop optimization"
- Compressor: A module that distills verbose reasoning into concise experiential summaries for memory. "are processed by a Compressor to distill them into concise, high-level experiences "
- Context accumulation: Naively appending all prior context in multi-turn processes, often causing redundancy. "unlike simple context accumulation~\cite{jiang2026genagent} or successive single-step updates~\cite{maestro}"
- Decomposer: The agent that splits a user prompt into atomic, testable criteria for verification. "the Decomposer partitions the user's original prompt into a set of atomic visual requirements"
- Distilled model: A compact model derived from a larger one to improve efficiency while retaining performance. "leveraging the lightweight, distilled Z-Image-Turbo"
- Downstream tasks: Specialized, application-specific tasks beyond general-purpose generation. "including five challenging mainstream benchmarks such as GenEval2 and four specialized downstream tasks spanning diverse domains."
- Early stopping mechanism: Halting an iterative process once success is detected to save computation. "Due to the early stopping mechanism, GEMS delivers superior performance while maintaining significantly lower overhead."
- Factual artifacts: Objective, compact records (e.g., prompts, images, feedback) stored verbatim in memory. "Factual artifacts with minimal token footprints, such as the prompt , the generated image , and the verification feedback , serve as reliable and objective data points"
- Foundational models: Large pretrained generative or LLMs that serve as base capabilities. "pushes beyond the inherent limitations of foundational models on both general and downstream tasks."
- Generative backends: Underlying generation models used by the agent framework to produce outputs. "Across five mainstream tasks and four downstream tasks, evaluated on multiple generative backends, GEMS consistently achieves significant performance gains."
- Generator: The component that synthesizes images from the current prompt at each iteration. "The Generator is a model-agnostic module responsible for synthesizing the visual output."
- Hierarchical compression: A memory strategy that stores compact summaries of reasoning while retaining raw facts. "we propose a Hierarchical Compression strategy to manage the historical context."
- Inference-time scaling: Methods that improve model performance by adding computation and reasoning at inference. "inference-time scaling has emerged as a promising strategy for performance enhancement."
- Iterative refinement loops: Repeated cycles of generate-evaluate-revise to progressively improve outputs. "have adopted iterative refinement loops to progressively optimize the results."
- Manifest (lightweight manifest): A minimal index of skills (names and descriptions) that is always loaded. "only the names and descriptions of skills are 'always loaded' as a lightweight manifest."
- Model-agnostic: Designed to work with different underlying models without modification. "The Generator is a model-agnostic module"
- Multimodal generation: Creating outputs (e.g., images) conditioned on multiple modalities like text and vision. "Multimodal generation has undergone transformative growth in recent years"
- Multimodal LLM (MLLM): A LLM that processes and reasons over text and images. "The Verifier , powered by a Multimodal LLM (MLLM)"
- On-demand loading: Fetching full skill instructions only when a skill is triggered to save tokens. "employing an on-demand loading and progressive exposure mechanism"
- Parallelism factor: The number of parallel generations or searches run to explore alternatives. "we specifically set the parallelism factor for Search~\cite{ma2025inference} to 5"
- Planner: The agent that selects relevant skills and crafts the initial enhanced prompt. "The Planner, denoted as , serves as the strategic entry point of the system."
- Progressive exposure mechanism: Gradually revealing detailed skill instructions only when needed. "on-demand loading and progressive exposure mechanism"
- Refiner: The agent that updates the prompt using feedback and memory to guide the next iteration. "The Refiner facilitates prompt evolution by closing the feedback loop."
- Stochasticity: Randomness in the generation process leading to variable outputs across runs. "A primary factor is the inherent stochasticity of the image generation process"
- Token efficiency: Minimizing the number of tokens used to control costs and context length. "To optimize for both information density and token efficiency, we propose a Hierarchical Compression strategy"
- Trajectory-level memory: Memory that captures the entire sequence of attempts and reflections across iterations. "provides a persistent, trajectory-level memory"
- Verifier: The agent that checks generated images against criteria and returns binary feedback. "The Verifier , powered by a Multimodal LLM (MLLM), assesses the generated image"
Collections
Sign up for free to add this paper to one or more collections.