- The paper presents a modular ensemble framework that dynamically assigns detection strategies per instance using clustering on lightweight textual features.
- Experimental results show superior macro F1-scores, achieving near-perfect detection even under adversarial conditions and varying text lengths.
- The system demonstrates robust adaptability and extensibility, paving the way for real-world deployment and future cross-lingual LLM-generated text detection research.
EnsemJudge: An Ensemble Framework for Reliable Detection of Chinese LLM-Generated Text
Introduction
EnsemJudge presents a principled ensemble-based framework for detecting text generated by LLMs in the Chinese language. The motivation originates from the growing societal risks associated with the misuse of LLM-generated content and the unique challenges presented in the Chinese linguistic context, including a scarcity of research efforts and limited benchmark resources tailored for this domain. The majority of detection methodologies have been developed and evaluated using English datasets, with their applicability to Chinese remaining largely unaddressed. Furthermore, adversarial and out-of-domain scenarios, which frequently arise in practical applications, exacerbate the limitations of existing approaches. EnsemJudge addresses these gaps via a robust and extensible architecture, incorporating both diverse detection paradigms and a dynamic, feature-driven ensemble mechanism.
Architecture and Methodology
At the core of EnsemJudge is a modular ensemble design consisting of multiple, independently implemented base detection models—encompassing rule-based, training-free, training-based, and hybrid approaches—each optimized for different subspaces of the input domain. The ensemble makes use of a clustering-based strategy assignment module, which analyzes lightweight textual features (e.g., length, perplexity) to dynamically allocate voting weights and select an appropriate subset of models for each text instance.
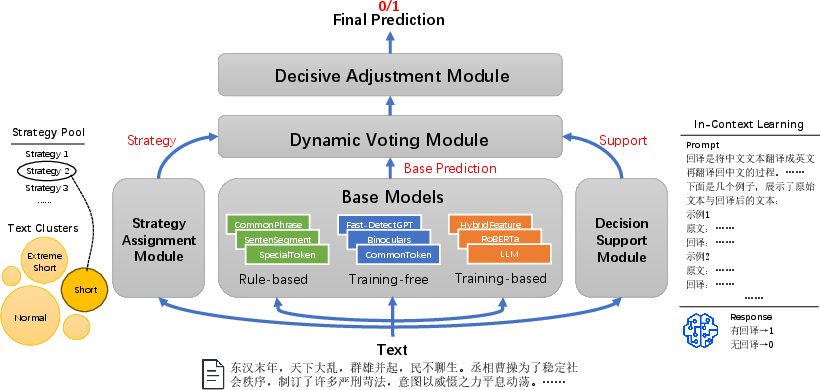
Figure 1: EnsemJudge’s system architecture, illustrating the dynamic assignment of ensemble strategies and information flow between modules.
The architecture includes:
- Base Models: Detectors from different methodological families (e.g., rule-based heuristics, zero-shot probability curvature-based models such as Fast-DetectGPT, fine-tuned LLM classifiers, and handcrafted token-based scorers).
- Strategy Assignment Module: Assigns ensemble strategy per instance by first clustering the input via feature extraction, then optimizing model subset selection and voting weights on a per-cluster basis.
- Decision Support Module: Specifically targets ambiguous cases, utilizing in-context learning (ICL) with a strong LLM to provide a secondary, context-driven decision.
- Dynamic Voting Module: Executes a weighted voting process over the selected base models, integrating optional adjustments from the decision support module.
- Decisive Adjustment Module: Applies rule-based corrections in high-certainty, pattern-matching cases (though found dispensable when upstream ensemble is robust).
The framework mathematically formalizes reliability in terms of expected macro F1 performance over adversarially perturbed text sets, guiding the design and evaluation of the ensemble to maximize worst-case robustness.
Experimental Evaluation
EnsemJudge was rigorously evaluated in the NLPCC2025 Task 1, using the DetectRL-ZH dataset with a challenging test set that was not only out-of-domain but adversarially constructed. Metrics centered on macro F1-score, with nuanced reporting across adversarial attack types—such as back-translation, text excerpting (short text attacks), mixing, paraphrasing, and lexical perturbations—and across various text-length regimes.
Key empirical findings:
- Superior aggregated performance: EnsemJudge outperformed all baseline and individual methods, achieving a macro F1 of 0.9922 on the full test set and reaching perfect classification (= 1.000 F1) on non-adversarial (“Normal”) data.
- Strong reliability under attack: Even on adversarial subsets (Mixing, Paraphrase, Perturbation), macro F1 scores exceeded 0.98, indicating that the ensemble’s diversity and dynamic voting architecture provide substantial robustness.
- Length sensitivity: All detection methods show improved accuracy as text length increases, with diminishing returns past 500 characters. Specialized detectors for extreme-short and short texts markedly increase resilience to length-based attack strategies.
- Adversarial impact differentiation: Training-free and rule-based approaches are particularly vulnerable to semantic-preserving attacks (paraphrase, mixing), with performance drops over 50% in some instances. In contrast, LLM fine-tuning approaches, notably those based on Qwen2.5, exhibit high invariance to attack, with less than 5% degradation in the most challenging settings.
- Implementation details: Even within the same methodological class, variant-specific details significantly affect outcome, emphasizing the necessity for empirical tuning and validation.
Discussion of Implications
EnsemJudge demonstrates that adaptive ensemble learning, tailored to instance-level features, is crucial for achieving robust LLM-generated text detection under real-world, adversarial conditions in non-English languages. The results decisively indicate that no single detection mechanism maintains reliability across the full spectrum of input distributions and attack surfaces. The ensemble’s dynamic integration of base models mitigates these blind spots, providing strong guarantees on aggregate system performance.
Notably, the findings also reveal that advances in pretraining (e.g., Qwen2.5’s pretraining regime) and the utilization of instruction tuning via LoRA significantly enhance generalization capacity, offering a promising direction for future architectures.
On a practical level, EnsemJudge’s extensibility and modular design make it readily adaptable for deployment in production systems requiring real-time detection and in academic settings for benchmarking new detection approaches across varying attack types and linguistic scenarios.
Theoretically, the approach underscores the necessity of adversarial and OOD evaluations for detection systems operating in high-stakes environments, and strengthens the argument for meta-learning and ensemble methodologies over specialist, single-model approaches.
Future Directions
- Transferability and Cross-lingual Adaptation: Extending the framework to multilingual detection, with emphasis on code-mixed and low-resource languages, remains a critical open area.
- Efficient, real-time deployment: Further research on efficient ensembling and model distillation may enable sub-second latency in large-scale applications.
- Adversarial Learning Integration: Joint end-to-end training of the ensemble with adversarial data augmentation may yield even stronger robustness.
- Explainability and Uncertainty Quantification: Incorporating interpretable model selection and uncertainty estimation at the ensemble level may be beneficial for forensic and regulatory use-cases.
Conclusion
EnsemJudge epitomizes a robust, extensible, and dynamically adaptive detection system for Chinese LLM-generated text, setting a new empirical benchmark by integrating diverse detection methodologies with principled, instance-adaptive ensemble strategies. The results affirm the efficacy of meta-ensemble approaches for reliable detection, even under adversarial and highly variable conditions, and establish a foundation for future work on multi-language, adversarially robust text detection systems.