- The paper presents EXP-Bench, a benchmark designed to assess AI agents in executing complete research experiments from hypothesis formulation to result analysis.
- It employs a semi-automated multi-modal extraction pipeline that curates tasks from peer-reviewed AI publications, ensuring realistic experimental challenges.
- Evaluation metrics reveal agents score below 30% on key phases, pinpointing critical bottlenecks in design, implementation, and execution.
EXP-Bench: Evaluating AI Agents on AI Research Experiments
The paper "EXP-Bench: Can AI Conduct AI Research Experiments?" (2505.24785) introduces EXP-Bench, a benchmark designed to evaluate the ability of AI agents to conduct end-to-end research experiments. EXP-Bench comprises tasks extracted from peer-reviewed AI publications, challenging agents to formulate hypotheses, design experiments, implement procedures, execute them, and analyze results. The paper highlights the limitations of current AI agents in performing complete, executable experiments, with success rates as low as 0.5%, despite achieving higher scores on individual experimental aspects. EXP-Bench serves as a tool for identifying bottlenecks and guiding future AI agents in improving their ability to automate AI research experiments.
EXP-Bench Design and Construction
EXP-Bench addresses the challenge of automating AI research by providing a structured benchmark for evaluating AI agents on end-to-end research experiments. The benchmark is built upon influential AI research papers and their associated codebases, linking high-level ideas to executable implementations. This allows for the assessment of an agent's ability to conduct established scientific procedures grounded in real-world AI experimentation.
To enable the scalable construction of high-fidelity tasks, the authors developed a semi-automated dataset curation pipeline (Figure 1). This pipeline integrates multi-modal extraction with lightweight human verification. The process begins with source selection and filtering, targeting influential papers from top-tier AI conferences (e.g., NeurIPS, ICLR) that are accompanied by publicly available code repositories. Task extraction then proceeds in two stages: (1) a multi-modal extraction phase that identifies the core elements of the research problem from papers, supplementary materials, and code; and (2) an implementation extraction phase that locates relevant code and assembles scripts to solve the specified task. Finally, all tasks are validated and finalized with execution traces checked against expected outputs.

Figure 2: EXP-Bench evaluates AI agents on research experiment tasks extracted semi-autonomously from peer-reviewed AI papers. Given a research question, a high-level method description, and starter code, agents are tasked with designing, implementing, and executing complete experiments. Performance is validated through ground-truth comparisons and implementation execution.
Dataset Composition and Task Specification
The EXP-Bench dataset comprises 461 research tasks derived from 51 papers published at NeurIPS and ICLR 2024 (Figure 3). These tasks span diverse AI subfields such as reinforcement learning, AI applications, and generative models. Each task entry includes a problem statement for the agent and a corresponding ground-truth solution derived from the original research artifacts.
The problem statement provides the agent with: (1) a research question derived from the source paper's experiments; (2) a high-level method description guiding the required experimental approach; and (3) access to the relevant code, potentially with specific components masked or requiring modification. The ground-truth experimental solution comprises: (1) an experimental design specifying key variables, constants, and procedures; (2) the necessary code modifications, assessed via a git diff against the provided repository; and (3) a final conclusion that directly answers the research question based on experimental results.
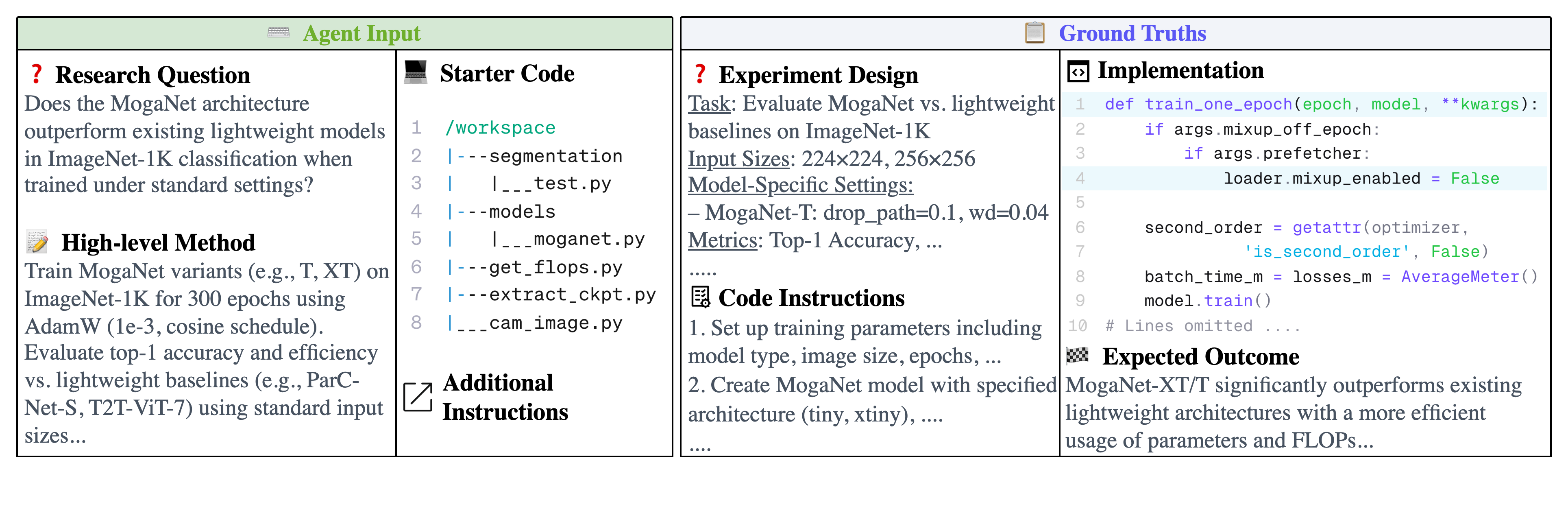
Figure 4: One AI research task example from ICLR 2024 MogaNet [li2024moganetmultiordergatedaggregation].
The multi-metric evaluation pipeline assesses agent performance across all core phases of experimentationâdesign, implementation, execution, and conclusion. Each metric captures a distinct capability, and their conjunctive use ensures that agents correctly understand and complete the experiment.
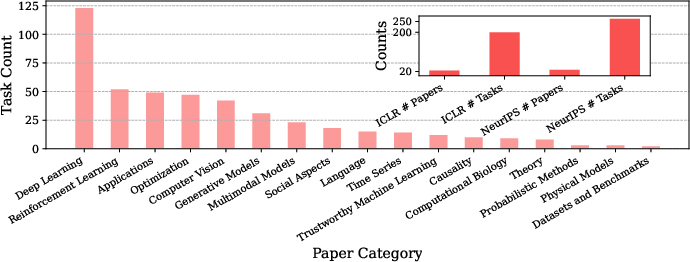
Figure 3: EXP-Bench's dataset comprises tasks from a diverse set of ML research categories.
The evaluation of AI agents on EXP-Bench involves a multi-metric assessment pipeline that evaluates agent performance across design, implementation, execution, and conclusion. The key metrics used are design correctness (D), implementation correctness (I), execution (E), and conclusion correctness (C). The initial evaluations of leading agents reveal that while they often succeed at executing routine procedures, they struggle when tasked with conducting complex experiments.
The evaluation results, shown in Table 1, demonstrate that the agents often score below 30% across all metrics. Specifically, the agents exhibit failures in: (a) conceptualizing and operationalizing sound experimental designs from high-level research questions and methods (16.1% misclassified design variables); (b) translating abstract research methodologies into complete and correct code implementations (39.7% missing essential implementation components); and (c) ensuring the robust and reproducible execution of complex experimental software stacks (29.4% environment or dependency misconfigurations or 23.8% script-level errors).
\subsection{Error Analysis and Failure Patterns}
A detailed analysis of error traces categorizes failures across four key phases of experimentation: implementation, execution, design, and conclusion. The most prevalent issues emerge during the implementation phase, with 39.71% of failures stemming from missing essential components. In the execution phase, failures are most commonly due to environment or dependency misconfigurations (29.38%). Design-related failures also occur frequently, with 16.05% involving incomplete or misclassified experimental variables. Finally, conclusion-phase errors highlight limitations in agentsâ interpretive reasoning.

Figure 5: Error Analysis and Comprehensive Explanation of the agent's failure to complete the task in Example 1.
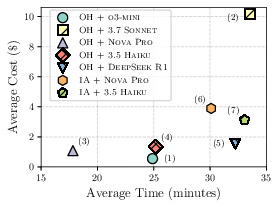
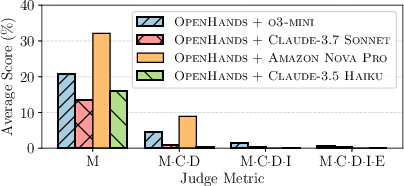
Figure 6: Costâtime trade-offs across agents.
\subsection{Implications and Future Directions}
The EXP-Bench benchmark and dataset have implications for the development of AI agents capable of automating AI research. By identifying key bottlenecks in the experimentation process, EXP-Bench helps target specific research components for improvement and advance next-generation AI agents for autonomous research. One promising direction is to apply reinforcement learning with verifiable rewards, enabling agents to autonomously navigate the research lifecycle and accelerate scientific discovery.
Conclusion
The paper introduces EXP-Bench, a benchmark for evaluating AI agents in conducting end-to-end AI research experiments. The benchmark leverages a semi-automated curation pipeline to source tasks from peer-reviewed publications and accompanying codebases. Initial evaluations reveal significant bottlenecks in conceptualizing complex experiments and ensuring robust code implementation and execution. EXP-Bench serves as a tool and dataset to guide future AI agents in automating AI research.

