TrackMAE: Video Representation Learning via Track Mask and Predict
Abstract: Masked video modeling (MVM) has emerged as a simple and scalable self-supervised pretraining paradigm, but only encodes motion information implicitly, limiting the encoding of temporal dynamics in the learned representations. As a result, such models struggle on motion-centric tasks that require fine-grained motion awareness. To address this, we propose TrackMAE, a simple masked video modeling paradigm that explicitly uses motion information as a reconstruction signal. In TrackMAE, we use an off-the-shelf point tracker to sparsely track points in the input videos, generating motion trajectories. Furthermore, we exploit the extracted trajectories to improve random tube masking with a motion-aware masking strategy. We enhance video representations learned in both pixel and feature semantic reconstruction spaces by providing a complementary supervision signal in the form of motion targets. We evaluate on six datasets across diverse downstream settings and find that TrackMAE consistently outperforms state-of-the-art video self-supervised learning baselines, learning more discriminative and generalizable representations. Code available at https://github.com/rvandeghen/TrackMAE
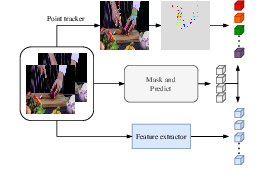

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces TrackMAE, a new way for computers to learn from videos without needing human labels. It teaches a model not only what things look like in a video, but also how they move. Think of it like training a system to both “see” and “follow” motion at the same time, so it gets better at understanding actions.
What questions were the researchers trying to answer?
- Can we make video-learning models pay more attention to movement, not just appearance?
- If we add an extra task—predicting how tiny points in the video move over time—will the model understand actions better?
- Does using motion to guide which parts of the video the model sees during training help it learn more useful skills?
How did they do it? (Explained simply)
The method builds on a popular “hide-and-seek” training game for videos:
- Masked video modeling (the hide-and-seek game):
- Imagine cutting a short video into many small blocks in space and time—like a 3D grid of tiny cubes.
- The model only gets to see a few of these cubes; most are hidden.
- Its job is to guess what’s inside the hidden cubes. This teaches it to use clues from the cubes it can see.
- In practice, a “reader” (encoder) looks at the visible cubes, and a “painter” (decoder) tries to fill in what’s missing.
What TrackMAE adds:
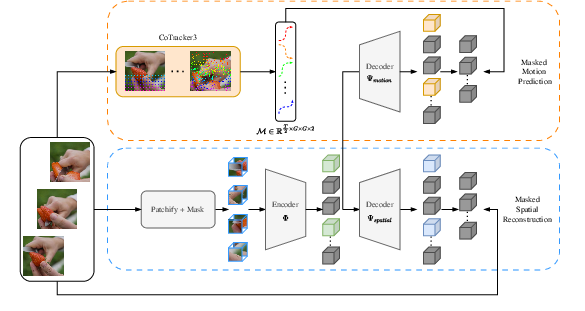
- Predicting motion paths:
- The researchers place virtual “stickers” (points) on the first video frame and use a point-tracker (CoTracker3) to follow where each sticker moves in later frames.
- These paths (called trajectories) are like drawing the route each sticker takes across the video.
- The model learns to predict these motion paths for the hidden parts, not just the missing appearance. So it learns both “what it looks like” and “how it moves.”
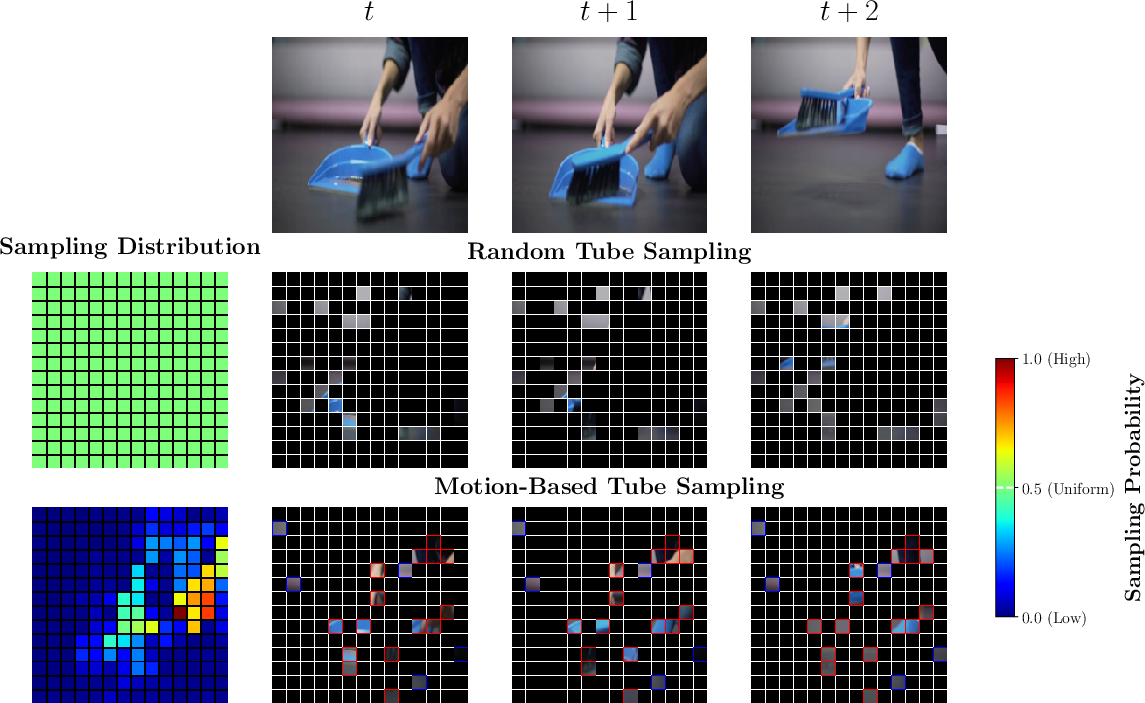
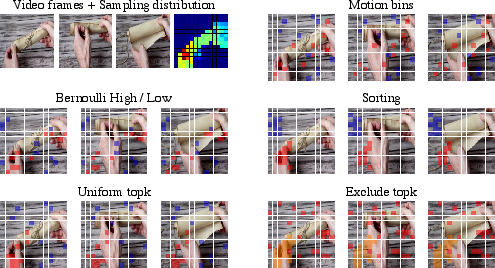
- Motion-aware masking (smarter hide-and-seek):
- Instead of hiding and showing parts at random, TrackMAE uses the motion information to choose visible pieces from both fast-moving and still areas.
- This makes sure the model doesn’t “cheat” by only relying on still backgrounds or short-term clues—it must pay attention to meaningful motion too.
- Two decoders, one shared encoder:
- One decoder learns to reconstruct how the video looks (appearance).
- Another decoder learns to reconstruct how points move (motion).
- Both tasks run together, so the model learns a richer understanding.
- Making motion targets denser without extra cost:
- Following lots of points can be slow.
- The authors track one point per patch and then “fill in” between them by smart interpolation—like connecting the dots smoothly—to simulate more detailed motion.
- This gives the model more useful motion signals without much extra computation.
- How they tested it:
- “Linear probing”: Freeze the learned model and add a simple classifier on top. This checks how good the learned features are without further training.
- “Fine-tuning”: Unfreeze and train the whole model on a specific dataset to see how well it adapts to a specific task.
What did they find, and why is it important?
Key results in simple terms:
- Better at motion-heavy tasks:
- On datasets where understanding how things move is crucial (like Something-Something V2 and FineGym), TrackMAE performs better than previous methods.
- It learns finer, more accurate motion understanding, which standard methods (focused mostly on appearance) often miss.
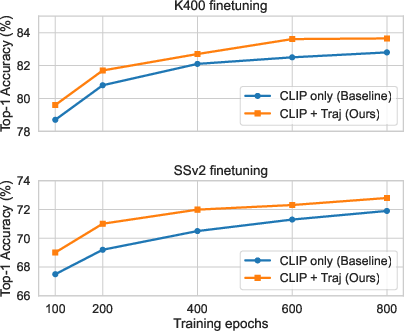
- Works with both pixels and high-level features:
- Whether the model tries to reconstruct raw pixels or higher-level features from another model (like CLIP), adding motion prediction helps.
- Combining appearance features (like CLIP) with motion targets gave the best overall results, especially for action recognition.
- Generalizes well:
- On the SEVERE benchmark (which tests how robust models are to different challenges like new domains, less data, and fine-grained differences), TrackMAE is consistently strong.
- It’s especially good when there’s not much training data, suggesting it learns more “transferable” skills.
- Practical trade-offs:
- Using a point tracker adds about 50% more training time.
- Their interpolation trick reduces the need for very dense tracking, keeping costs reasonable while improving performance.
Why this matters:
- Many real-world video tasks—sports analysis, robot perception, surveillance, and human–computer interaction—depend on understanding motion, not just recognizing objects. TrackMAE pushes video models closer to that goal.
What could this lead to?
- More reliable action understanding: Models that truly “get” movement can better recognize complex actions, subtle gestures, or tricky scenes with moving objects.
- Better performance with less data: Stronger motion-aware features help in low-data settings, making models more useful in new or specialized domains.
- A new training recipe: Treating motion as a first-class training signal—alongside appearance—could become a standard way to pretrain video models.
- Future directions: Faster trackers, smarter motion selection, or combining other motion cues could push performance further while keeping costs down.
In short, TrackMAE shows that teaching a model to both reconstruct what it sees and how it moves creates a stronger understanding of videos—especially for action-heavy tasks—than teaching it to look only at appearance.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and open questions left unresolved by the paper, focusing on what is missing, uncertain, or unexplored:
- Dependence on external trackers: The method relies on off‑the‑shelf point trackers (e.g., CoTracker3) for supervision, but does not systematically evaluate sensitivity to tracker choice, calibration, or failure modes across domains (e.g., egocentric, driving, sports, low‑light, or heavy motion blur).
- Track confidence and occlusion handling: The trajectory loss uniformly penalizes all points with an L2 error; there is no use of tracker‑provided confidence/visibility signals or occlusion masks to weight or filter supervision, nor a mechanism to drop unreliable segments.
- Camera motion and global movement: The motion targets use raw displacement magnitudes without compensating camera/ego motion; how performance changes with strong global motion (where most patches appear “high‑motion”) is not analyzed, and no camera motion estimation or stabilization is incorporated.
- Temporal anchoring to the first frame: All displacements are defined relative to the first frame; the effects of long clips, tracker drift, re‑appearance, or points entering later are not studied, nor are alternative targets (e.g., per‑step incremental displacements) evaluated.
- Limited temporal sampling: Motion is computed on every other frame to match tubelets with t=2; the impact on learning under different tubelet lengths, variable frame rates, or high‑frequency motions is not examined.
- Simple L2 motion loss: Only an L2 regression loss on 2D displacements is used; robust alternatives (Huber, angular/magnitude‑separated losses), temporal smoothness/acceleration penalties, or cycle‑consistency constraints are not explored.
- Sparse‑to‑dense upsampling assumptions: Motion densification uses spatial interpolation that assumes piecewise‑smooth motion; its failure near motion boundaries, thin structures, or multi‑motion patches is not probed, and edge‑aware or segmentation‑guided upsampling is not attempted.
- Single‑point per patch supervision: Even with upsampling, the supervision originates from one tracked point per 16×16 patch; scenes with multiple motions per patch (parallax, articulated parts) remain under‑supervised, and alternatives (multi‑point seeding or boundary‑aware targets) are not evaluated.
- Motion‑aware masking design: Masking uses two bins (high/low motion) and the average displacement magnitude; directionality, temporal variation (e.g., acceleration), and tracker uncertainty are ignored, and more expressive or adaptive sampling strategies are not studied.
- Masking ratio interactions: The interaction between motion‑aware masking and different global masking ratios (beyond the default high ratio) is not systematically analyzed, especially under extremely sparse visibility where motion cues may be scarce.
- Dynamic loss balancing: The weight λ between spatial and motion losses is tuned manually and dataset/target‑dependent (e.g., 1.0 for pixels, 0.25 for CLIP); there is no investigation of adaptive weighting schedules or uncertainty‑based balancing.
- Integration with higher‑level motion signals: The paper does not examine combining point‑track supervision with other motion cues (e.g., optical flow, motion segmentation, ego‑motion) to handle complementary failure modes.
- End‑to‑end training with trackers: The tracker is treated as a fixed black box; end‑to‑end or alternating training that co‑adapts the encoder and tracker (or uses differentiable tracking proxies) is not explored.
- Compute and energy cost: Pretraining time increases by ~50%, yet the paper does not quantify memory/compute breakdowns, scalability with larger backbones/datasets, or practical strategies for budgeted training (e.g., curriculum on grid density, lightweight trackers, or track caching).
- Domain and task breadth: Pretraining is primarily on Kinetics‑400 (and K700 for one experiment); transfer to diverse domains (e.g., egocentric EPIC‑KITCHENS/Ego4D, autonomous driving, surveillance, medical) and long‑form or variable‑FPS videos is not evaluated.
- Beyond action recognition: The method is not tested on motion‑centric dense tasks (e.g., optical flow estimation, correspondence, tracking, video segmentation) where explicit motion supervision might yield clearer gains.
- Zero‑shot and retrieval evaluation: Although CLIP features are used, the paper does not report zero‑shot video classification, text‑to‑video retrieval, or video‑language alignment to assess semantic transfer benefits of combining CLIP+motion.
- Robustness stress tests: Only mild synthetic noise is added to trajectories; more realistic stressors (heavy occlusions, jitters, tracking dropouts, motion blur, compression artifacts) and their impact on learning are not systematically benchmarked.
- Handling static or near‑static videos: There is no analysis of performance and compute waste on videos with little or no motion, nor adaptive strategies to down‑weight the motion branch when motion is negligible.
- Trajectory sparsity schedule: The effect of varying the tracker grid density over training (e.g., coarse‑to‑fine curriculum) is unexplored beyond a static upsampling factor, as is the trade‑off between grid density and masking policy.
- Interaction with tubeletization: The approach assumes a fixed tubelet size (e.g., 2×16×16) aligned with track sampling; sensitivity to different tubelet sizes, temporal spans, or non‑aligned tokenizations is not reported.
- Motion target reference frames: The choice of absolute‑from‑first‑frame displacements vs. relative inter‑frame displacements (or hybrid schemes) is not compared, especially for longer clips where drift and occlusion may dominate.
- Failure analysis of performance gaps: On some task‑shift settings (e.g., Charades), TrackMAE remains on par or slightly worse than alternatives; the paper does not analyze which motion patterns or label structures limit gains and how to remedy them.
- Uncertainty‑aware masking and losses: There is no mechanism to incorporate per‑track uncertainties into both the masking distribution and the regression loss, which could reduce the impact of tracker errors.
- Fairness and bias in motion supervision: The dataset‑ and domain‑specific biases of the tracker (e.g., bias toward textured regions, failures on low‑texture or dark scenes) and their downstream effects on learned representations are not examined.
Practical Applications
Practical Applications of TrackMAE
TrackMAE introduces a self-supervised video pretraining approach that explicitly predicts motion trajectories and uses motion-aware masking, yielding stronger temporal representations and generalization. Below are actionable applications that stem directly from its methods and findings.
Immediate Applications
- Motion-aware video embeddings for action retrieval and indexing (Software/Media)
- Build a “motion-aware embedding” API or plugin for video CMS/search that enables retrieval by actions (e.g., “open drawer,” “flip book”) rather than appearance alone.
- Why TrackMAE: Explicit motion supervision (trajectory prediction) improves fine-grained temporal sensitivity and SEVERE robustness, enhancing action-centric retrieval quality.
- Tools/workflow: Pretrain with TrackMAE (pixel or CLIP targets + motion), export encoder as a frozen feature extractor, index clip embeddings in a vector DB.
- Assumptions/dependencies: Access to unlabeled in-domain video for pretraining; compute overhead (~+50% pretraining time); reliance on a point tracker (e.g., CoTracker3) during pretraining only.
- Low-shot video classification for constrained data settings (Software/EdTech/Healthcare)
- Deploy TrackMAE-pretrained backbones to train linear heads with very few labels for tasks like exercise detection, skill categorization, or classroom activity recognition.
- Why TrackMAE: Demonstrated gains in sample efficiency and generalization (SEVERE benchmark, 1K-sample settings).
- Tools/workflow: Freeze encoder, train linear/LoRA heads; optionally use CLIP+motion for stronger semantic transfer.
- Assumptions/dependencies: Domain similarity between pretraining and downstream data; small fine-tuning budget available.
- Sports analytics and coaching (Sports/EdTech)
- Enhance repetition counting, fine-grained action segmentation, and movement quality feedback (e.g., gymnastics, weightlifting).
- Why TrackMAE: Outperforms baselines on motion-centric benchmarks (e.g., FineGym) and task generalization (e.g., repetition counting).
- Tools/workflow: Use pretrained features for clip-level classification and temporal segmentation; integrate with simple pose/tracking modules if needed.
- Assumptions/dependencies: Camera vantage points with clear motion; compliance with athlete data privacy.
- Industrial and retail activity monitoring (Manufacturing/Retail/Security)
- Detect and classify subtle activity patterns for process compliance, workstation anomalies, or shopper interactions.
- Why TrackMAE: Better fine-grained motion encoding and robustness under distribution shifts improve anomaly/activity detection.
- Tools/workflow: Unsupervised/supervised anomaly detection using TrackMAE embeddings; deploy inference on edge/NVRs with frozen backbones.
- Assumptions/dependencies: Domain-specific pretraining improves results; ensure video privacy and on-prem processing where required.
- Surveillance and safety analytics (Public safety/Construction)
- Improve detection of unusual or hazardous actions (e.g., unsafe ladder use, restricted-area intrusions) with fewer labels.
- Why TrackMAE: Motion-aware features reduce reliance on appearance cues that often fail under viewpoint or lighting changes.
- Tools/workflow: Train lightweight classifiers on top of TrackMAE embeddings; integrate with alerting systems.
- Assumptions/dependencies: Legal constraints on video use; class imbalance and rare-event modeling still required.
- Rehabilitation and home fitness assistance (Healthcare/Consumer)
- Power apps that count repetitions, recognize exercise phases, and flag form deviations using minimal labeled data.
- Why TrackMAE: Strong motion representations transfer well to repetition counting and fine-grained temporal tasks.
- Tools/workflow: Fine-tune on exercise clips; deploy on-device or via edge servers; optionally combine with pose estimation for interpretability.
- Assumptions/dependencies: Controlled capture conditions improve performance; medical validation needed before clinical use.
- Robotics perception backbone (Robotics)
- Use TrackMAE as a drop-in backbone for visual modules in manipulation, navigation, or teleoperation that benefit from temporal consistency.
- Why TrackMAE: Encodes temporal dynamics explicitly; complements existing robot pipelines without runtime tracking overhead.
- Tools/workflow: Freeze or fine-tune encoder for downstream perception (e.g., action recognition, affordance detection).
- Assumptions/dependencies: Alignment between robot camera distributions and pretraining video; integration with ROS stacks.
- Developer tooling for self-supervised pretraining (Academia/ML Platforms)
- Integrate “motion-aware masking” and “trajectory upsampling” into existing MVM pipelines to improve performance without large tracker costs.
- Why TrackMAE: Shows a simple recipe that leverages tracker outputs for both supervision and masking; upsampling reduces compute overhead.
- Tools/workflow: Add a trajectory decoder head and masking strategy to VideoMAE-like codebases (PyTorch), adopt λ and masking ratios as reported (e.g., 50% high/low motion split).
- Assumptions/dependencies: Availability of a point tracker (CoTracker3 or alternatives); GPU budget for pretraining.
- Domain-robust embeddings for multi-label video tagging (Media/Enterprise knowledge bases)
- Improve multi-label tagging of complex activities in long videos (e.g., Charades-like tasks) using motion-sensitive features.
- Why TrackMAE: Demonstrated stronger task-shift generalization in SEVERE; motion+feature targets yield robust representations across objectives.
- Tools/workflow: Train multi-label heads on top of frozen or lightly fine-tuned encoders; batch-process archives.
- Assumptions/dependencies: Dataset curation and class taxonomy mapping; ensure scalable embedding pipelines.
- Ethical/operational policy improvements for video ML (Policy/Compliance)
- Reduce dependence on large labeled datasets by adopting self-supervised pretraining on in-house data, limiting data sharing and labeling contracts.
- Why TrackMAE: SSL paradigm needs no labels and transfers well, lowering external data exposure.
- Tools/workflow: Establish internal pretraining workflows; energy reporting to track ~50% pretraining overhead; privacy-by-design storage.
- Assumptions/dependencies: Internal data governance; environmental impact assessments for compute use.
Long-Term Applications
- Generalist motion-centric foundation models (Software/AI Platforms)
- Build multimodal video-language-action models where TrackMAE-style motion signals complement semantic targets for richer temporal reasoning.
- Rationale: Trajectory prediction is complementary to high-level features (e.g., CLIP) and scales to large backbones (ViT-L).
- Dependencies: Large-scale, diverse video corpora; compute scaling; stable tracker outputs or learned “tracking-free” surrogates.
- Skill assessment and auto-annotation tools (EdTech/Sports/Workforce training)
- Automatic segmentation of skill primitives and labeling of action phases in long videos to reduce manual labeling costs.
- Rationale: Fine-grained motion sensitivity can detect phase boundaries and action primitives; improves human-in-the-loop annotation.
- Dependencies: Robust segmentation pipelines; active learning/QA workflows; task-specific quality standards.
- Safer human-robot collaboration (Robotics/Manufacturing)
- Enable robots to anticipate human micro-actions and adjust behavior (e.g., handovers, tool exchange) with minimal labeled data.
- Rationale: Explicit temporal encoding helps anticipate near-term motion; improves responsiveness and safety.
- Dependencies: Real-time constraints (need distilled/quantized models); further research on uncertainty estimation and latency.
- Transport and smart-city analytics (Mobility/Public sector)
- Analyze crowd flows, pedestrian actions, and near-miss patterns for urban safety planning and infrastructure design.
- Rationale: Motion-aware embeddings improve detection of subtle interactions and domain shifts typical in outdoor scenes.
- Dependencies: Privacy-preserving pipelines; governance for public video use; adaptation to weather/lighting variability.
- Predictive maintenance via operator behavior analytics (Energy/Manufacturing)
- Correlate operator actions with machinery states to identify precursors to faults or unsafe procedures.
- Rationale: Fine-grained action understanding can reveal anomalous routines not captured by sensors alone.
- Dependencies: Synchronization with telemetry; long-horizon temporal modeling; facility consent and data governance.
- Clinical movement assessment and tele-rehab (Healthcare)
- Quantify movement quality (e.g., tremor severity, gait irregularities) beyond simple counting, and track progress over time.
- Rationale: Motion-centric representations can capture subtle kinematic patterns; promising for neurology/orthopedics.
- Dependencies: Rigorous clinical validation; bias and fairness evaluation; integration with secure medical data systems.
- AR/VR interaction and embodied interfaces (XR/Consumer)
- More reliable gesture/action recognition for immersive interfaces, especially under occlusions or lighting changes.
- Rationale: TrackMAE’s temporal awareness and domain robustness benefit challenging XR capture conditions.
- Dependencies: On-device acceleration and model distillation; latency budgets; user privacy.
- Automated compliance monitoring (Finance/Regulated industries)
- Detect policy-relevant behaviors (e.g., restricted device usage, unauthorized access patterns) from internal CCTV feeds with minimal labels.
- Rationale: Domain-robust motion features reduce manual rule engineering; SSL minimizes sensitive labeling workflows.
- Dependencies: Strict privacy/compliance controls; robust false-positive management; clear governance for automated actions.
- Replacement of explicit optical flow in legacy stacks (Software/Video analytics)
- Use TrackMAE embeddings instead of separate flow estimators for tasks that historically relied on optical flow.
- Rationale: Motion-augmented features may reduce complexity by embedding motion cues directly into the backbone.
- Dependencies: Careful benchmarking per task (e.g., tracking/segmentation); potential retraining of downstream components.
- Energy-aware SSL strategies and standards (Policy/ML Ops)
- Develop best practices to balance improved performance with increased pretraining cost (e.g., using trajectory upsampling, mixed precision, curriculum masking).
- Rationale: Paper reports ~50% extra pretraining time; upsampling trick reduces tracking cost without sacrificing accuracy.
- Dependencies: Organizational buy-in for energy reporting; investment in efficient hardware and scheduling.
Notes on feasibility and adoption
- Pretraining-time only tracker: Point tracking is needed only during pretraining; inference-time costs are unaffected.
- Compute considerations: Expect ~50% extra pretraining time; trajectory upsampling and moderate grid sizes mitigate the cost.
- Data availability: Benefits are maximized when pretraining data distribution resembles deployment environments.
- Tracker quality: Noisy tracks can degrade targets; the paper reports modest robustness (≈–0.5% with noise) and compatibility with alternative trackers.
- Legal/ethical constraints: Ensure privacy-preserving collection and processing of unlabeled video; set up governance for SSL pipelines.
Glossary
- Action granularity: The level of fine-grained detail required to distinguish between closely related actions. Example: "four aspects of generalization: domain shift, sample efficiency, action granularity, and task shift."
- Bernoulli distribution: A probability distribution over binary outcomes, here used to randomly mask tokens. Example: "A high-ratio masking (typically 90\%) is applied at the token level following a Bernoulli distribution."
- CLIP: A vision-LLM used to provide semantic feature targets for reconstruction. Example: "We use a CLIP ViT-B model to extract feature reconstruction targets."
- CoTracker3: An off-the-shelf point tracking model used to extract motion trajectories. Example: "In particular, we use CoTracker3~\citep{Karaev2025CoTracker3}, a robust and high-quality point tracker, to extract motion trajectories."
- Cross-domain transfer: Transferring a pretrained model to a different target dataset/domain. Example: "cross-domain transfer (pretraining on K400 and finetuning on SSv2)."
- Cycle consistency: A training signal ensuring that tracking forward and backward returns to the original point. Example: "learn features by tracking backward and then forward in time (cycle consistency), enabling self-supervised correspondence."
- DINO: A self-supervised vision representation model used as a feature-space target. Example: "what to learn by replacing pixels with feature-space targets (\eg, HOG, DINO, CLIP)"
- Domain shift: A change in data distribution between training and evaluation settings. Example: "four aspects of generalization: domain shift, sample efficiency, action granularity, and task shift."
- Downstream settings: Evaluation tasks used to assess transfer of pretrained representations. Example: "We evaluate on six datasets across diverse downstream settings"
- Feature-space targets: Supervisory signals defined in a semantic feature space instead of pixel space. Example: "what to learn by replacing pixels with feature-space targets (\eg, HOG, DINO, CLIP)"
- Foreground motion: Motion associated with salient moving objects rather than background. Example: "Real-world videos also exhibit strong temporal redundancy and sparse foreground motion"
- Full finetuning: End-to-end training of a pretrained backbone on a target task. Example: "In contrast to linear probing, which freezes the encoder, full finetuning enables the model to refine its temporal and semantic understanding based on the target task distribution."
- HOG (Histogram of Oriented Gradients): A hand-crafted feature descriptor capturing gradient orientation patterns. Example: "MaskFeat~\citep{Wei2022Masked} aims to reconstruct HOG features"
- In-domain transfer: Finetuning on the same dataset used for pretraining. Example: "in-domain transfer (pretraining and finetuning on the same dataset \ie, K400)"
- L2 loss: Mean squared error loss used for reconstruction. Example: "with the following L2 loss"
- Linear probing: Evaluating representation quality by training a linear classifier on frozen features. Example: "we conduct linear probing experiments across four standard action recognition benchmarks."
- MAE (Masked Autoencoder): A masked modeling framework reconstructing missing inputs from visible parts. Example: "Masked video modeling, \eg VideoMAE~\citep{Tong2022VideoMAE}, is an extension of standard image masked modeling MAE~\citep{He2022Masked}."
- Mask-and-predict: A pretraining paradigm that masks parts of the input and trains a model to predict them. Example: "in a mask-and-predict fashion."
- Masked video modeling (MVM): Self-supervised pretraining on videos by masking spatiotemporal patches and reconstructing them. Example: "Masked video modeling (MVM) has emerged as a simple and scalable self-supervised pretraining paradigm"
- Motion-aware masking: A masking strategy biased by estimated motion to select visible tokens. Example: "motion-aware masking that equally samples visible tokens from high- and low-motion regions."
- Motion vectors: Compressed-domain estimates of movement used for motion-guided masking/targets. Example: "leverages the motion information contained in motion vectors of the raw videos"
- Multi-label classification: Predicting multiple labels per video instance. Example: "and multi-label classification on Charades"
- Occlusion: When objects are temporarily hidden from view, complicating correspondence. Example: "temporal coherence under occlusion and viewpoint change"
- Optimal-transport clustering: A clustering method based on optimal transport used to group trajectories. Example: "first clusters long-range tracked trajectories via optimal-transport clustering and then propagates the cluster assignments along tracks"
- Optical flow: Pixel-wise motion estimation between frames. Example: "improving the masking based on motion information extracted from an optical flow instead."
- Patchified: The process of splitting frames into non-overlapping patches/tubelets. Example: "a video clip is first patchified and masked."
- Point tracker: An algorithm that follows the positions of points across frames. Example: "we use an off-the-shelf point tracker to sparsely track points in the input videos"
- Positional embedding: Encodings added to tokens to preserve spatiotemporal order. Example: "and a fixed positional embedding is added to preserve spatial and temporal order."
- Pretext objectives: Self-supervised tasks used to learn useful representations without labels. Example: "replacing manual labels with pretext objectives that exploit the structure of the raw data."
- Random tube masking: Uniformly random masking of spatiotemporal tubelets during pretraining. Example: "pixel reconstruction with random tube masking, which tends to emphasize low-level appearance statistics"
- Sample efficiency: Performance in low-data regimes. Example: "four aspects of generalization: domain shift, sample efficiency, action granularity, and task shift."
- SEVERE (generalization benchmark): A benchmark to evaluate robustness across diverse factors. Example: "Comparison on SEVERE generalization benchmark~\citep{Thoker2022HowSevere.}"
- Self-supervised learning (SSL): Learning representations from data without manual labels. Example: "Self-supervised learning (SSL) has become the default pretraining recipe"
- Spatiotemporal tokens: Discrete units representing patches across space and time. Example: "a high fraction (often 80â95\%) of spatiotemporal tokens is hidden"
- Spatial interpolation: Estimating values at intermediate locations from nearby samples. Example: "we can spatially interpolate extracted sparse motion tokens to simulate denser trajectories per patch."
- Temporal correspondence: The mapping of entities across time to maintain identity. Example: "We suggest that temporal correspondence should be a first-hand signal during pretraining"
- Temporal redundancy: Repetition or similarity across adjacent frames that reduces new information. Example: "Real-world videos also exhibit strong temporal redundancy and sparse foreground motion"
- Trajectory decoder: A network module that predicts point-track displacements from encoded features. Example: "\methodname adds two components to masked video modeling: (i) a lightweight trajectory decoder that predicts point-track displacements"
- Tube masking: Masking strategy at the level of spatiotemporal tubes (tubelets). Example: "The vanilla tube masking used in VideoMAE does not assume any information of motion"
- Tubelets: Local spatiotemporal video volumes used as tokens. Example: "videos are decomposed into tubelets (\eg, )"
- Upsampling: Increasing spatial resolution of targets or features, often via interpolation. Example: "we introduce a simple yet effective upsampling trick."
- ViT (Vision Transformer): A transformer architecture applied to visual tokens. Example: "The visible tokens are fed to a ViT encoder ."
- Weighted sum loss: Combining multiple loss terms using scalar weights. Example: "The final objective is a weighted sum of the two objectives"
Collections
Sign up for free to add this paper to one or more collections.