daVinci-LLM:Towards the Science of Pretraining
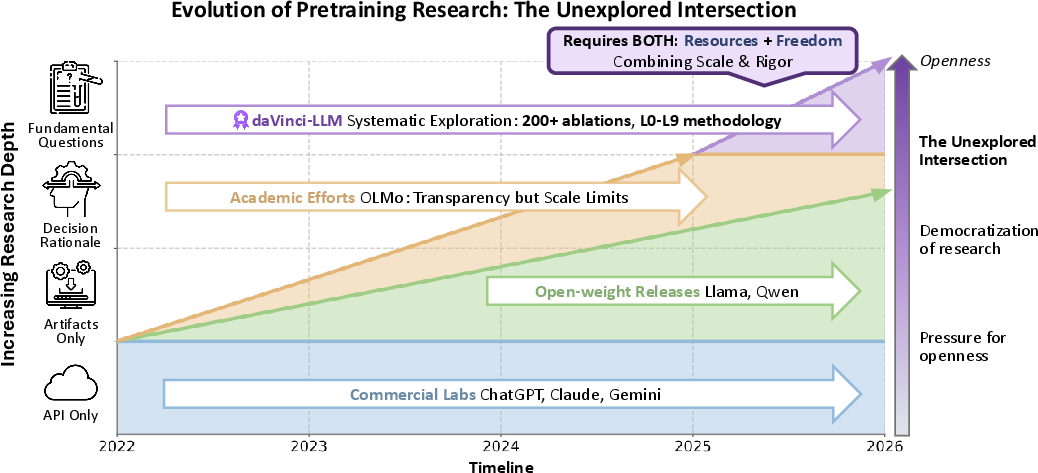
Abstract: The foundational pretraining phase determines a model's capability ceiling, as post-training struggles to overcome capability foundations established during pretraining, yet it remains critically under-explored. This stems from a structural paradox: organizations with computational resources operate under commercial pressures that inhibit transparent disclosure, while academic institutions possess research freedom but lack pretraining-scale computational resources. daVinci-LLM occupies this unexplored intersection, combining industrial-scale resources with full research freedom to advance the science of pretraining. We adopt a fully-open paradigm that treats openness as scientific methodology, releasing complete data processing pipelines, full training processes, and systematic exploration results. Recognizing that the field lacks systematic methodology for data processing, we employ the Data Darwinism framework, a principled L0-L9 taxonomy from filtering to synthesis. We train a 3B-parameter model from random initialization across 8T tokens using a two-stage adaptive curriculum that progressively shifts from foundational capabilities to reasoning-intensive enhancement. Through 200+ controlled ablations, we establish that: processing depth systematically enhances capabilities, establishing it as a critical dimension alongside volume scaling; different domains exhibit distinct saturation dynamics, necessitating adaptive strategies from proportion adjustments to format shifts; compositional balance enables targeted intensification while preventing performance collapse; how evaluation protocol choices shape our understanding of pretraining progress. By releasing the complete exploration process, we enable the community to build upon our findings and systematic methodologies to form accumulative scientific knowledge in pretraining.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about how to best “pretrain” a LLM — the early phase where the model learns most of what it will ever know. The authors argue that pretraining sets the model’s ceiling: later fine-tuning can polish skills, but it can’t fully make up for a weak foundation. They build a fully open project called daVinci-LLM to study, in a scientific and transparent way, how data and training choices during pretraining affect what a model can do.
What questions did the paper ask?
To make the study easy to reuse and trust, the authors turn their design choices into simple research questions, such as:
- How much does better data cleaning and preparation help, beyond just adding more data?
- When should we change the mix of training data (like general web text vs. math vs. code vs. Q&A) as training goes on?
- How can we add more of one skill (like reasoning) without breaking others (like general knowledge)?
- How should we test models so we get a fair picture of real progress during pretraining?
How did they do it?
Think of training an LLM like teaching a student:
- “Parameters” (3 billion of them here) are like the knobs inside the brain the teacher can tune.
- “Tokens” (8 trillion of them here) are like bite-sized pieces of text the student reads.
- A “curriculum” means starting with broad basics and then moving to harder, more focused tasks.
- An “ablation” is like changing one thing at a time in a lesson plan to see what truly helps.
Here’s their setup in everyday terms:
- Model and training plan:
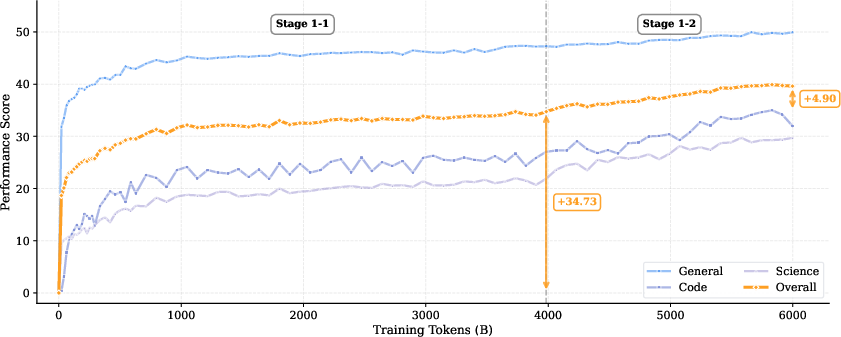
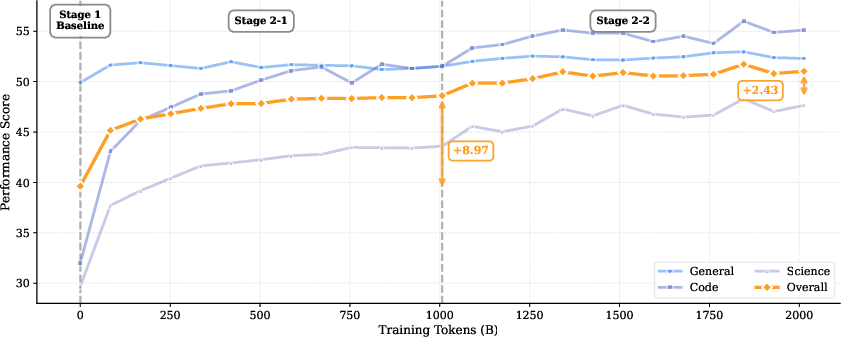
- They trained a 3-billion-parameter model from scratch on 8 trillion tokens of text.
- Stage 1 (the first 6T tokens): lots of broad, general reading to build a strong foundation.
- Stage 2 (the last 2T tokens): more “reasoning-heavy” practice — especially question–answer data, math/science, and code — to sharpen thinking skills.
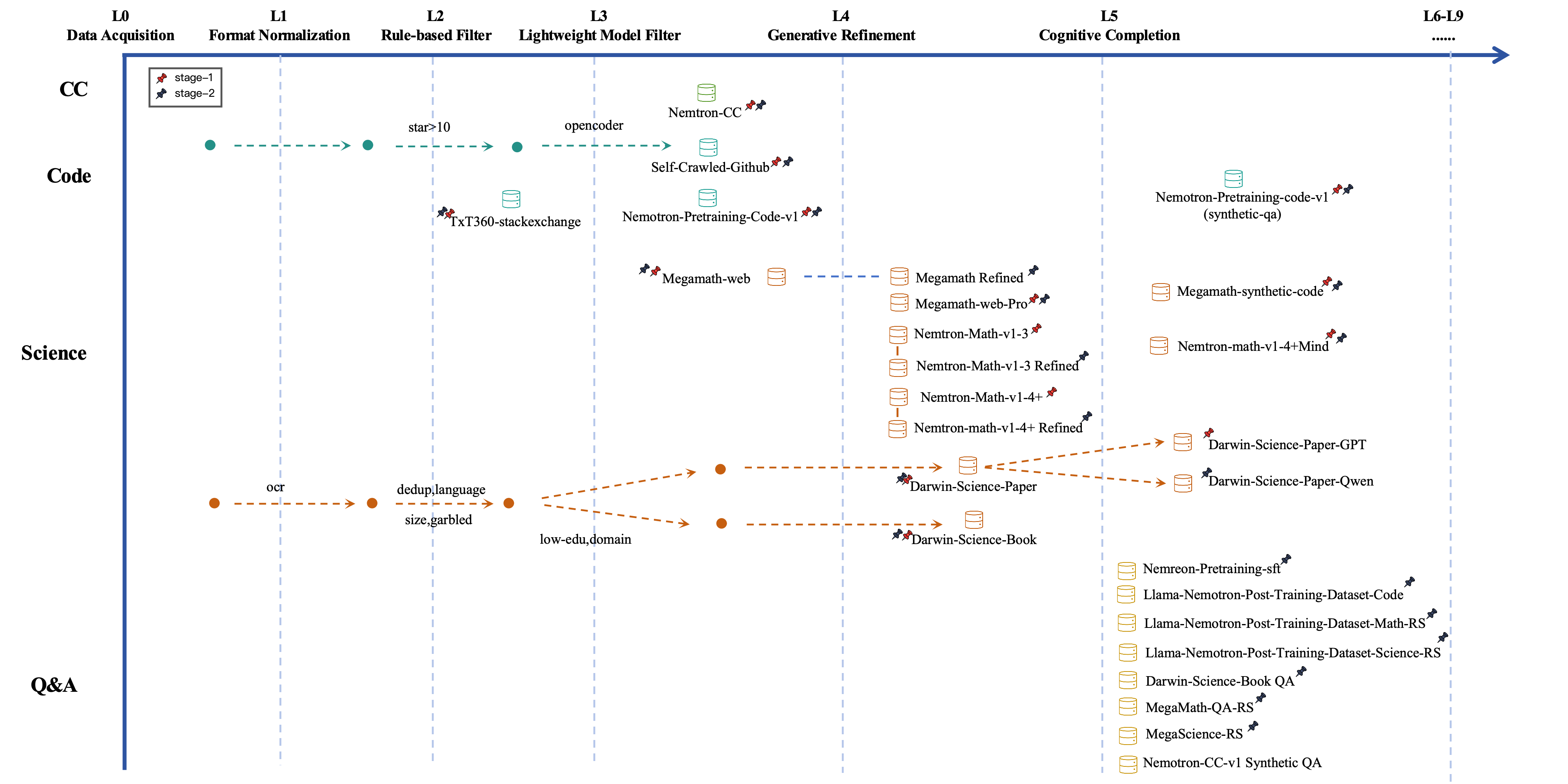
- Data strategy with “Data Darwinism”:
- They use a simple idea: data quality has levels, from raw, messy text to carefully cleaned, clarified, and even newly created practice material.
- You can imagine it like working on your notes:
- Start by collecting notes (L0–L1).
- Remove junk and duplicates (L2–L3).
- Clean and fix formatting while keeping the original meaning (L4).
- Add missing steps and explanations so it’s easier to learn (L5).
- At the highest levels, create new examples, tools, or even simulated worlds to practice in (L6–L9).
- They label every dataset with its “level” so you know how much it was improved.
- Data sources:
- General web text (big and diverse).
- Code (from real projects and also synthetic examples).
- Science and math (papers, books, and math-focused collections).
- Q&A data (short questions and answers in general, math, science, and coding).
- They gradually change how much of each type they use as training moves from basics to reasoning.
- Systematic testing (200+ ablations):
- They run hundreds of controlled experiments where they change one variable at a time (like data level, mix, or schedule) to see what actually matters.
- Radical openness:
- They release the processed datasets, the full data pipeline (how they cleaned and built the data), training code, logs, intermediate checkpoints, and both successful and failed experiments. This lets others reproduce and extend their work.
What did they find, and why is it important?
Here are the main takeaways in plain language:
- Deeper data processing makes models better, not just more data. Cleaning, refining, and adding missing steps to texts (like showing the reasoning in math) systematically improves learning. This means “quality depth” is a key dimension — as important as sheer data size.
- Different subjects need different strategies over time. For example, with some topics, adding more of the same data stops helping after a point (this is called “saturation”). When that happens, you should shift tactics: adjust the proportions, change formats (like turning a dense paper into a clear Q&A), or increase reasoning-focused content.
- Balance matters. If you push too hard on one skill (say, code) without balance, other skills (like general knowledge) can drop. A well-balanced mix can boost a target skill while keeping the rest stable.
- How you evaluate changes what you think is happening. The way you test models can make progress look bigger or smaller. Careful, consistent evaluation is essential to truly measure pretraining gains.
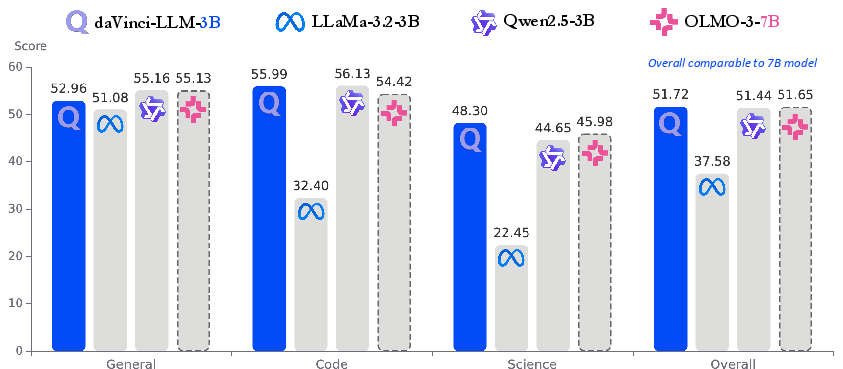
- Competitive performance with openness. Their 3B model performs well across general, reasoning, and coding skills, reaching an overall score similar to a well-known larger open model (OLMo-3-7B), which is impressive for its size and training strategy.
These findings matter because they turn pretraining from guesswork into a more scientific process. Instead of just “train longer on more data,” they show how to train smarter.
What could this change?
- Better foundations for AI: If pretraining sets the ceiling, then improving data quality and training strategy can raise that ceiling, leading to stronger models before fine-tuning even starts.
- Shared, reusable playbook: By releasing everything (data, code, checkpoints, logs, and even failed attempts), other researchers can build on this work — saving time, avoiding past mistakes, and making real scientific progress together.
- Fairer and faster innovation: Big companies often keep pretraining details secret. This project shows it’s possible to use large-scale resources and still be fully open, helping the whole community move forward.
- Smarter, more efficient training: Knowing when to switch data types, how deep to process data, and how to avoid saturating on one domain can save money and compute, while improving results.
In short, the paper treats openness as a scientific method and shows that the “how” of pretraining — especially data quality depth and adaptive curricula — can be as powerful as raw size. This helps everyone learn how to build stronger, fairer, and more transparent AI models.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored, framed to guide follow-up research.
- External validity beyond a 3B model: Do the reported findings on processing depth, mixture design, and curriculum hold at larger scales (7B–70B+) and across different architectures (decoder-only variants, Mixture-of-Experts)?
- Compute-optimality and scaling laws: How do processing depth, data volume, and parameter count jointly trade off? Can a formal “processing-depth scaling law” quantify marginal gains per level (L0–L5) and predict optimal data/compute allocations?
- Causal impact of each Darwin level: What are the isolated effects (accuracy, sample efficiency, generalization) of L3 vs L4 vs L5 on specific domains (web, code, math, science) when controlled for token budget and teacher model?
- Fidelity auditing for L4 refinement: How often do L4 operations inadvertently alter meaning or inject errors? Develop automatic+human protocols (e.g., semantic equivalence tests, source-aligned factual checks) and report error rates.
- Correctness and bias auditing for L5 cognitive completion: What is the rate and nature of teacher-injected errors, biases, or style artifacts? Establish detection and correction pipelines (cross-teacher agreement, fact-checkers, expert audits).
- Ordering of operations: What is the optimal sequence (e.g., L3→L4 vs L4→L3) per domain and data quality regime? Provide empirical guidelines and stopping criteria for iterative multi-level passes.
- Benchmark decontamination at corpus level: Given heavy use of MMLU-style and other synthetic QA, what is the residual contamination risk across standard benchmarks (MMLU, GSM8K, MATH, HumanEval, MBPP)? Release comprehensive contamination audits for the full merged corpus.
- Near-duplicate proliferation from refinement: When both original and refined versions of the same document are retained, what is the impact on overfitting, evaluation leakage, and calibration? Quantify and propose dedup strategies post-refinement.
- License compliance for self-crawled code: Beyond a 10-star threshold, what is the exact licensing filter and its trade-offs (coverage vs legality)? Provide systematic license audits and downstream reproducibility implications.
- PII and safety filtering: What procedures remove PII, toxic or unsafe content in web/code/QA data? Evaluate remaining safety risk and its effect on downstream alignment.
- Monolingual bias: The pipeline largely focuses on English. How does the methodology extend to multilingual pretraining, cross-lingual transfer, and interference across languages?
- Long-context pretraining: What is the context length used and how does long-context training (and long-document curriculum) interact with processing depth and downstream retrieval/long-horizon reasoning?
- Beyond next-token prediction: What is the benefit of integrating auxiliary objectives (execution feedback for code, retrieval-augmented pretraining, contrastive tasks) relative to deeper L4/L5 processing?
- Synthetic-heavy QA mixture risks: Does heavy L5 QA (SFT-like) in pretraining induce instruction-style overfitting or reduce adaptability as a base model? Map the generalization frontier to free-form, non-instruction tasks.
- Catastrophic forgetting across stages: How much forgetting occurs when shifting toward QA-heavy Stage 2? What mixture/scheduling mitigations (replay, elastic weights, mixture regularization) are most effective?
- Adaptive mixture optimization: Replace hand-tuned schedules with online bandit/gradient-based reweighting driven by domain-specific learning curves and “saturation” signals. How much additional efficiency can be unlocked?
- Tokenization for math/code/LaTeX: What are the effects of tokenizer design on math and code performance given LaTeX normalization and multi-language code? Provide ablations and tokenizer design recommendations.
- Sensitivity to teacher choice in L4/L5: How robust are outcomes to substituting different teacher LLMs (GPT-OSS vs Qwen3 variants)? Quantify variance and define teacher-agnostic prompts/checks.
- Cost, efficiency, and carbon footprint: Report compute budget, energy use, and tokens/GPU-hour efficiency. What are practical recipes for low-resource labs to approximate gains from L4/L5?
- Interplay with downstream alignment: How does embedding SFT-like QA during pretraining influence subsequent RLHF/DPO/Constitutional AI? Identify helpful vs harmful pretraining distributions for alignment success.
- Evaluation breadth and protocol standardization: Extend beyond standard academic benchmarks to tool-use, grounded QA, retrieval-augmented tasks, and long-horizon planning; standardize base-model evaluation protocols (decoding settings, CoT vs no-CoT, seed variance) to reduce measurement noise.
- Temporal coverage and staleness: What is the model’s robustness to time-sensitive knowledge gaps? Design pretraining refresh strategies and “recency curricula.”
- Code domain coverage and validity: Expand language/ ecosystem coverage, strengthen execution-based verification (unit tests, coverage), and quantify contamination from community Q&A sources (e.g., Stack Exchange).
- Quantifying ROI of “processing depth”: Establish cost-benefit curves (compute/inference cost of L4/L5 vs downstream gains) to guide when deeper processing beats simply scaling raw tokens.
- Realization of L6–L9 synthesis: L6–L9 are proposed but not realized. What concrete designs, legality considerations, verification harnesses, and evaluation metrics would make contextual/world synthesis reliably useful for pretraining?
- Fairness and representational harms: Audit demographic/cultural biases introduced by data sources and teacher models; test bias mitigation efficacy at pretraining (vs post-training) time.
- Data poisoning and supply-chain security: Assess poisoning risks from public code/web sources and propose robust filtering/detection; report observed poisoning patterns (if any).
- Reproducibility of L4/L5 at scale: Even with released outputs, can labs reproduce outcomes when rerunning transformations with different teachers or prompts? Provide reproducibility stress tests and variance estimates.
- Curriculum switch criteria: What principled signals (loss plateaus, per-domain slopes, competence thresholds) should trigger transitions between stages and mixture pivots?
- Quantitative mixture design rules: Move from narrative rationale to explicit formulas/algorithms for proportion updates (e.g., targeting stable performance on “core” suites while intensifying underperforming domains).
- Interaction with optimization and context hyperparameters: Does processing depth demand different learning rates, sequence lengths, or batch sizes? Provide coupled hyperparameter guidelines.
- Dialogue vs monologue formatting effects: MIND-style dialogues may alter style and calibration. Quantify impacts on base-model perplexity, instruction-following emergence, and chattyness bias.
- Learnability metrics validation: The paper references “educational value” and “learnability” proxies. Validate these metrics against downstream performance and human judgments; refine them for cross-domain comparability.
Practical Applications
Overview
The paper introduces a fully open, end-to-end pretraining program for a 3B-parameter LLM trained on 8T tokens, together with all data pipelines, processed datasets, ablations, checkpoints, and logs. Its core innovations are:
- A principled “Data Darwinism” framework (L0–L9) to characterize and deepen data processing from filtering to generative refinement and cognitive completion.
- A two-stage adaptive curriculum (foundation → reasoning-intensive) and compositional mixture design to boost targeted capabilities without degrading general skills.
- 200+ controlled ablations demonstrating that processing depth, domain-specific saturation dynamics, and mixture balance are decisive levers in pretraining.
- Full transparency enabling reproducibility and scientific accumulation.
Below are practical, real-world applications derived from these findings, grouped by deployment horizon.
Immediate Applications
These can be deployed now with available tools (the released daVinci-LLM 3B model, datasets, checkpoints, logs, and curation code), plus mainstream compute.
- Data Darwinism-based enterprise data curation (Software; Industry knowledge management; Healthcare, Finance, Legal)
- What: Use L2–L5 operations (e.g., rule/model filtering, L4 generative refinement, L5 cognitive completion) on internal corpora (manuals, SOPs, reports, repositories) to raise signal-to-noise and learnability before pretraining or continued pretraining.
- Tools/workflows: The released curation toolkit, prompts, and pipelines; integrate with enterprise ETL/ELT and document stores.
- Assumptions/dependencies: Access to permissively licensed foundation models for L4/L5 transformation (or API budget); data governance and PII scrubbing for regulated domains.
- Adaptive curriculum for domain-targeted continual pretraining (Software; Finance; Healthcare; Manufacturing)
- What: Apply the two-stage curriculum (broad web/general → reasoning-intensive QA/code/science) to efficiently lift domain reasoning while preserving generality.
- Tools/workflows: Curriculum scheduler that reallocates token budgets across stages and sources; checkpoint-based training with compositional mixtures.
- Assumptions/dependencies: Sufficient compute for continued pretraining on a 3B-class model; domain QA/code/science pools curated under Data Darwinism.
- Mixture design and “compositional balance” to avoid capability collapse (Software; Industry R&D)
- What: Use the paper’s finding that targeted intensification plus balanced background data prevents regressions when specializing.
- Tools/workflows: “Mixture tuner” that tracks per-domain metrics and adjusts sampling ratios; use released eval suite to monitor regressions.
- Assumptions/dependencies: Reliable domain competence metrics and contamination-controlled evals; data loaders supporting dynamic mixtures.
- Pretraining auditability and provenance dashboards (Policy; Regulated industry)
- What: Leverage released logs, checkpoints, and data specs as a template for transparent model provenance during procurement, certification, or internal governance.
- Tools/workflows: “Pretraining factsheet” generator that links data sources, Darwin levels, mixture histories, and checkpoints; integrates with MLOps.
- Assumptions/dependencies: Organizational policy to require/accept disclosures; secure storage for logs and data lineage; license clarity for included datasets.
- Robust base-model evaluation protocols (Academia; Industry model selection; Policy)
- What: Adopt contamination-aware, base-model-focused evaluation and reporting practices to correctly measure pretraining progress.
- Tools/workflows: Use or adapt the released evaluation suite; implement decontamination and stratified test slices by domain/format.
- Assumptions/dependencies: Availability of clean benchmarks; adoption by internal governance or academic venues.
- Code intelligence uplift via mixed real + synthetic code (Software/DevTools)
- What: Combine L3–L5 code sources (e.g., filtered GitHub, AST-verified synthetic QA/code) to improve code completion, explanation, and repo Q&A.
- Tools/workflows: Fine-tune or continue pretraining daVinci-LLM-3B on enterprise code + L5 QA; integrate with IDEs or code search.
- Assumptions/dependencies: License compliance for code corpora; high-precision filtering and deduplication to avoid contamination and bloat.
- Science/math tutoring content and assistants (Education; Daily life)
- What: Deploy content refined via L4/L5 (reasoning reconstruction, terminology explication, pedagogical bridging) to build step-wise tutors and study aids.
- Tools/workflows: A tutoring stack that uses L5-transformed science/math texts + QA pools; configurable reasoning verbosity (short CoT).
- Assumptions/dependencies: Quality assurance for factuality; age-appropriate alignment; compute for on-device or server inference.
- Lightweight local assistants and private search (Daily life; SMBs)
- What: Use the open 3B model for offline note summarization, knowledge lookup on private documents, and basic coding help.
- Tools/workflows: RAG over private corpora curated with L2–L4 cleaning; CPU/GPU-optimized inference runtimes; prompt templates from the toolkit.
- Assumptions/dependencies: Hardware constraints for 3B inference; privacy-compliant local indexing.
- Reproducible pretraining research and teaching labs (Academia)
- What: Course modules and research projects on data processing depth, mixture design, and curriculum effects using released checkpoints and logs.
- Tools/workflows: Lab assignments that re-run ablations; student-built data pipelines that move sources up the Darwin ladder.
- Assumptions/dependencies: Modest cluster access; dataset hosting allowances.
- Token-allocation “saturation” analysis for budget planning (Industry R&D)
- What: Measure diminishing returns by domain/format to reallocate tokens where gains remain steep, reducing cost.
- Tools/workflows: Training dashboards charting per-domain gains vs. tokens; auto-rebalancing data samplers.
- Assumptions/dependencies: Reliable per-domain metrics; disciplined experiment tracking.
Long-Term Applications
These require further research, scale-up, standardization, or regulatory pathways before broad deployment.
- Higher-order synthesis for training (L6–L9) (Robotics; Software verification; Simulation platforms)
- What: Progress from contextual completion to executable environment synthesis (L7), multi-agent ecosystems (L8), and world-level simulation (L9) to generate rich, verifiable training signals.
- Tools/products: “Environment-as-data” generators for code execution, robotics task planners, or simulation-based QA; emergent multi-agent training labs.
- Assumptions/dependencies: Mature sandboxing, simulators, and safety guards; substantial compute and evaluation frameworks for realism and transfer.
- Regulatory-grade transparency standards (Policy; Healthcare; Finance; Critical infrastructure)
- What: Codify disclosure norms (data compositions, mixture histories, logs, checkpoints, negative results) for procurement, audits, and incident forensics.
- Tools/products: Standardized model “provenance labels” and audits; third-party certification bodies using daVinci-style artifacts as baselines.
- Assumptions/dependencies: Consensus across regulators and industry; secure sharing protocols for sensitive logs and datasets.
- Automated “Darwinism Orchestrator” for data quality over volume (Software; Energy/Green AI)
- What: Systems that automatically escalate processing depth (L2→L5) and selectively reprocess sources to maximize capability per token and reduce training energy.
- Tools/products: Cost-aware orchestrators that choose which sources to refine, how, and when based on learning curves.
- Assumptions/dependencies: Accurate gain predictors; affordable access to strong L4/L5 models or in-house equivalents.
- Domain-specialized, high-safety reasoning models (Healthcare; Finance; Law)
- What: Use deeply refined scientific/technical corpora with compositional balance and rigorous evaluation to build assistants suited for regulated decisions.
- Tools/products: Clinical- or regulatory-grade assistants with traceable provenance and per-domain saturation controls.
- Assumptions/dependencies: Clinical trials/validation, post-training alignment, privacy-preserving pipelines, and liability frameworks.
- Cross-lingual cognitive completion and open textbooks (Education; Global development)
- What: Scale L4/L5 pipelines to multilingual corpora to produce accessible textbooks/lectures with explicit reasoning across languages.
- Tools/products: Open, leveled curricula generated from technical documents; teacher dashboards to adjust reasoning depth.
- Assumptions/dependencies: High-quality OCR/LLMs for target languages; cultural/educational standards alignment.
- Standardized, contamination-resilient base-model benchmarks (Academia; Industry; Policy)
- What: Community-driven suites and practices to evaluate pretraining progress independent of post-training.
- Tools/products: Shared contamination registries; stratified testsets by domain/format; leaderboard governance.
- Assumptions/dependencies: Long-term curation funding; community adoption.
- Compute- and carbon-efficient pretraining via depth-first strategies (Energy/Green AI; Industry R&D)
- What: Replace brute-force token scaling with deeper data processing and adaptive curricula to cut emissions per capability point.
- Tools/products: Emissions dashboards linked to mixture and depth choices; optimization solvers for “capability-per-joule.”
- Assumptions/dependencies: Emission accounting standards; integration with schedulers and cloud carbon APIs.
- IDE-native formal reasoning and verification (Software)
- What: Combine refined code/math corpora with environment synthesis to produce assistants capable of proving properties or running checks during development.
- Tools/products: “Proof-while-you-code” plugins; automated unit/invariant generation; semantic diff reasoning.
- Assumptions/dependencies: Verified datasets, language/toolchain coverage, and high-precision evals.
- National open pretraining infrastructures (Public sector; Research ecosystems)
- What: Publicly funded pipelines that mirror daVinci’s openness to bootstrap local innovation and sovereign capabilities.
- Tools/products: Shared data lakes with Darwin-level annotations; reproducible training programs and compute access.
- Assumptions/dependencies: Sustained funding, data governance, and talent pipelines.
- Privacy-first pipelines with fine-grained Darwin levels (Healthcare; Legal; HR)
- What: Integrate de-identification, access control, and risk scoring at each processing stage to move sensitive corpora up the quality ladder safely.
- Tools/products: “Privacy-aware refinement” services with auditable transformations and reversible redactions.
- Assumptions/dependencies: High-recall PII detection, legal guidance, and secure enclaves.
Notes on Dependencies and Assumptions (cross-cutting)
- Compute and budget: Immediate uses can rely on the 3B model and moderate GPUs; long-term synthesis (L7–L9) and large-scale refinement require substantial compute and/or API budgets.
- Licensing and provenance: Adoption depends on clear licenses for included datasets (e.g., Nemotron-derived sets) and enterprise data rights.
- Safety and compliance: Regulated sectors require domain validation, alignment, and monitoring beyond base pretraining improvements.
- Access to strong L4/L5 engines: Many quality gains rely on large LLMs for generative refinement and cognitive completion; open or affordable alternatives are an enabler.
- Evaluation integrity: Benefits depend on contamination-aware, domain-sensitive evaluation; mismeasurement can misallocate training tokens.
Glossary
- Ablations: Controlled experiments that remove or vary components to assess their causal impact on performance. "Through 200+ controlled ablations, we establish that: processing depth systematically enhances capabilities"
- API-only access: Access to a model solely via an application programming interface without visibility into training artifacts or weights. "surface-level artifacts (API-only access)"
- AST parsing: Analyzing code by constructing and checking its Abstract Syntax Tree to verify syntactic correctness and structure. "language-specific heuristics such as Python AST parsing"
- Benchmark decontamination: Removing test or benchmark examples from training data to prevent data leakage and inflated evaluation. "followed by fuzzy deduplication and benchmark decontamination"
- Capability ceiling: The upper bound on a model’s achievable capability largely determined during pretraining. "capability ceiling, as post-training struggles to overcome capability foundations established during pretraining"
- Chain-of-thought: Step-by-step reasoning traces embedded in training examples to elicit reasoning behavior. "retain only the short chain-of-thought portion of the data"
- Checkpoints: Saved snapshots of a model’s parameters during training for analysis, resumption, or release. "We release all intermediate checkpoints at 5k-step intervals"
- Cognitive Completion: LLM-driven enrichment that makes implicit reasoning explicit to improve learnability while preserving content fidelity. "we apply L5 Cognitive Completion using GPT-OSS-120B"
- Compositional balance: Designing data or training mixtures to intensify targeted skills without degrading overall performance. "compositional balance enables targeted intensification while preventing performance collapse"
- Contextual Completion: Adding external references and background knowledge so documents become self-contained learning artifacts. "Contextual Completion (L6) expands documents by integrating external references and background knowledge to create self-contained artifacts."
- Curriculum: A staged progression of training data and tasks that adapts focus and difficulty over time. "using a two-stage adaptive curriculum that progressively shifts from foundational capabilities to reasoning-intensive enhancement."
- Data Darwinism: A ten-level framework (L0–L9) that categorizes data processing depth from raw acquisition to advanced synthesis. "we adopt the Data Darwinism framework—a principled L0-L9 taxonomy organizing operations from basic filtering to content transformation to knowledge synthesis."
- Data mixture design: The strategy of selecting and proportioning data domains to balance capability gains and preservation. "Data Mixture Design: How to balance targeted enhancement with general capability preservation?"
- Deduplication: Removing duplicate or near-duplicate documents to reduce redundancy and overfitting. "global deduplication"
- Ecosystem Synthesis: Constructing multi-agent systems that interact to generate emergent, higher-order training data. "Ecosystem Synthesis (L8) builds dynamic multi-agent systems where diverse intelligent entities interact and generate emergent data through sustained collaboration."
- Environment Synthesis: Creating executable settings that enable validation of data through actual program or process execution. "Environment Synthesis (L7) constructs executable environments in which data objects can be validated through actual execution."
- Evaluation protocol: The specific setup, metrics, and procedures used to assess model performance. "how evaluation protocol choices shape our understanding of pretraining progress."
- Generative Refinement: Model-driven transformation that cleans and restructures text while preserving its original meaning. "L4: Generative Refinement. This stage marks a qualitative shift from selection to active, model-driven transformation."
- Genetic-Instruct: An evolutionary algorithm-based framework for synthesizing diverse instruction–solution pairs. "This subset is synthesized using the Genetic-Instruct framework"
- L0–L9 taxonomy: The hierarchical levels in Data Darwinism that define increasing processing sophistication from acquisition to synthesis. "a principled L0-L9 taxonomy"
- MinHash LSH: A probabilistic technique using locality-sensitive hashing to detect near-duplicate texts efficiently. "near-duplicates detected via MinHash LSH"
- Open-weight models: Released models whose parameter weights are publicly available for inspection and reuse. "The intermediate tier comprises open-weight models"
- Optical Character Recognition (OCR): Converting scanned or image-based documents into machine-readable text. "OCR processing of scanned PDFs"
- Pedagogical Bridging: Adding concrete explanations or analogies to make abstract concepts more accessible. "and grounding abstract concepts in concrete analogies and established knowledge (Pedagogical Bridging)."
- Reasoning Reconstruction: Expanding compressed expert logic into explicit step-by-step derivations for clarity. "step-by-step derivations (Reasoning Reconstruction)"
- Rejection sampling: Generating multiple candidates and filtering out those that fail quality criteria to retain high-quality data. "rejection-sampled open-source post-training datasets by Qwen3-32B in non-thinking mode"
- Terminological Explication: Explicitly defining and contextualizing domain-specific terms within the text. "domain-specific terminology within the narrative flow rather than assuming prior mastery (Terminological Explication)"
- Training dynamics: The temporal behavior and effects of data, optimization, and scheduling choices during training. "training dynamics remain largely undisclosed."
- World Synthesis: Building comprehensive simulated worlds to produce effectively unlimited synthetic training data. "World Synthesis (L9) represents the theoretical apex of the framework"
Collections
Sign up for free to add this paper to one or more collections.