Data Darwinism Part I: Unlocking the Value of Scientific Data for Pre-training
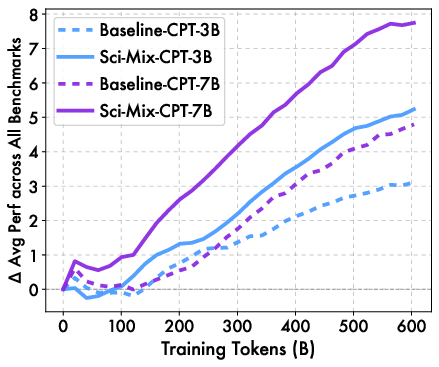
Abstract: Data quality determines foundation model performance, yet systematic processing frameworks are lacking. We introduce Data Darwinism, a ten-level taxonomy (L0-L9) that conceptualizes data-model co-evolution: advanced models produce superior data for next-generation systems. We validate this on scientific literature by constructing Darwin-Science, a 900B-token corpus (L0-L5). We identify a learnability gap in raw scientific text, which we bridge via L4 (Generative Refinement) and L5 (Cognitive Completion) using frontier LLMs to explicate reasoning and terminology. To ensure rigorous attribution, we pre-trained daVinci-origin-3B/7B models from scratch, excluding scientific content to create contamination-free baselines. After 600B tokens of continued pre-training, Darwin-Science outperforms baselines by +2.12 (3B) and +2.95 (7B) points across 20+ benchmarks, rising to +5.60 and +8.40 points on domain-aligned tasks. Systematic progression to L5 yields a +1.36 total gain, confirming that higher-level processing unlocks latent data value. We release the Darwin-Science corpus and daVinci-origin models to enable principled, co-evolutionary development.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language summary of “Data Darwinism — Part I: Unlocking the Value of Scientific Data for Pre-training”
What is this paper about?
This paper is about how to turn messy, real-world text (especially scientific books and research papers) into the best possible training material for AI LLMs. The authors introduce a step-by-step “evolution” system called Data Darwinism that explains how data should be collected, cleaned, improved, and sometimes even expanded so that AI can learn from it more effectively.
They also build a massive science dataset (called Darwin-Science), create tough science quizzes to test models, and show that carefully improved scientific text can seriously boost a model’s abilities.
What questions are the authors trying to answer?
- How do we organize all the different ways of processing data so it helps AI learn better?
- Does adding raw (unprocessed) scientific text help train AI models?
- If not, what kinds of improvements to the text actually make a difference?
- How much better can models get when trained on “smarter” versions of the same scientific content?
How did they study this? (Methods in simple terms)
Think of building an AI as teaching a student from a giant library:
- At first, you just grab a lot of books (data collection).
- Then you clean them up: remove duplicates, fix broken pages, correct scanning mistakes (data cleaning).
- Next, you make the books easier to learn from: fix messy formatting, explain the tricky parts, and add step-by-step reasoning (data enrichment).
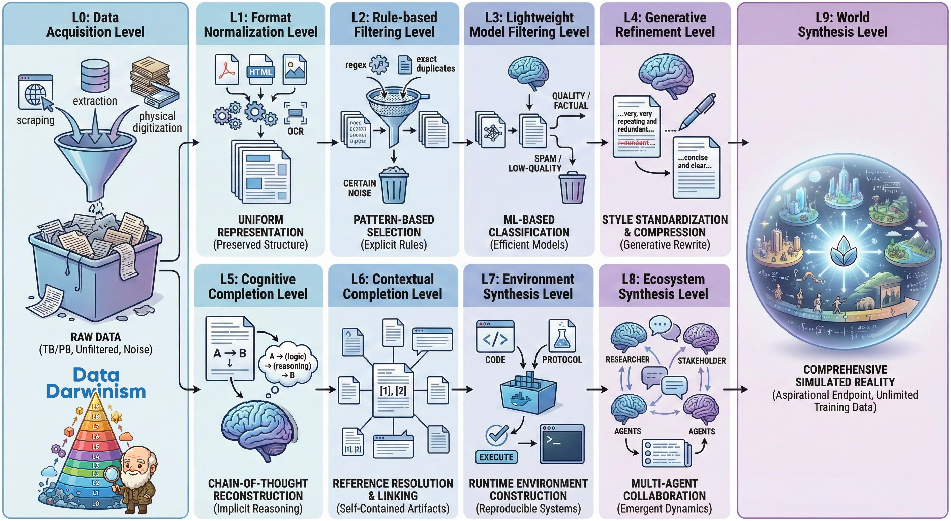
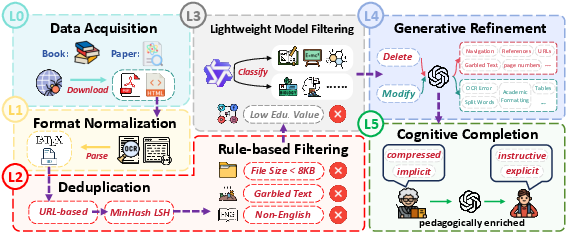
The authors created a “10-level ladder” for data processing, from basic collecting (L0) all the way to advanced synthetic worlds (L9). In this paper, they used levels L0–L5:
- L0–L3: Collect, standardize formats, and filter out bad/irrelevant content.
- L4 (Generative Refinement): Like repairing a damaged textbook—remove distracting junk (headers, footers, broken formulas) and fix structure without changing the meaning.
- L5 (Cognitive Completion): Like a great teacher’s edition—fill in missing steps, explain jargon, and add helpful examples or analogies so the logic is clear.
To test their ideas fairly, they:
- Trained two “clean-room” base models (3B and 7B parameters) from scratch on 5.37 trillion tokens that deliberately did not include any science. This avoids “spoilers” and makes it clear when gains come from scientific data.
- Built Darwin-Science, a 900-billion-token science corpus processed up to L5.
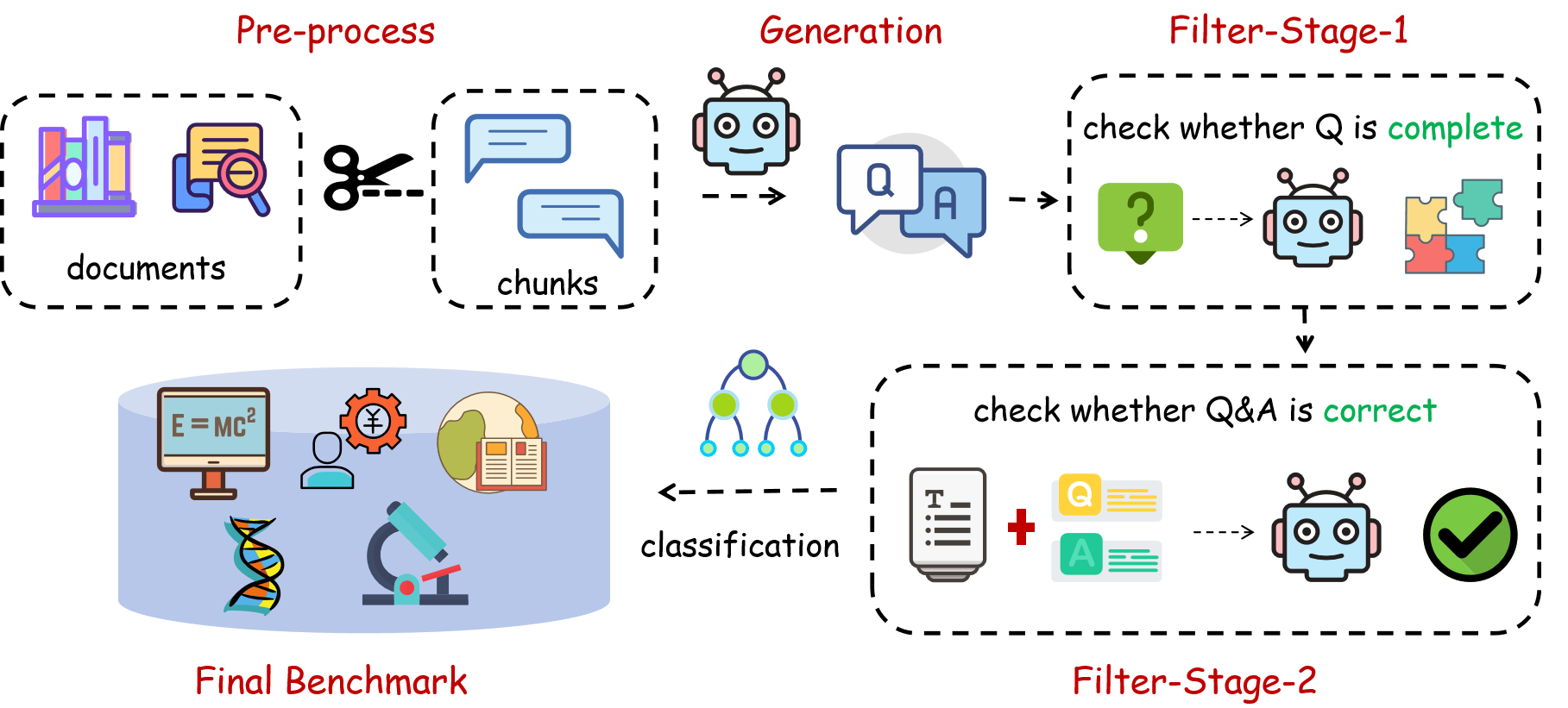
- Created Darwin-Science-Eval, a set of 150,000 expert-level multiple-choice questions made from held-out science texts to test deep understanding.
- Continued training their base models on 600B tokens and compared different data versions (raw vs. refined vs. cognitively completed) across 20+ benchmarks.
What did they find, and why does it matter?
- Raw scientific text doesn’t help much. Even though science papers are information-dense, the AI struggled to learn from them as-is. The writing assumes lots of background knowledge and skips steps—this creates a “learnability gap.”
- Cleaning and explaining makes a big difference.
- L4 (repairing structure and removing noise) helps.
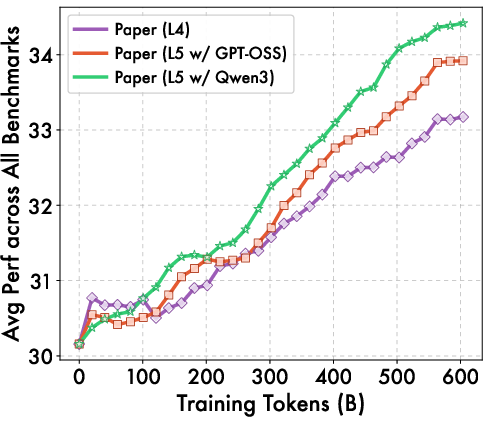
- L5 (adding missing reasoning, defining terms, and teaching-like bridges) helps even more.
- Clear, steady improvements:
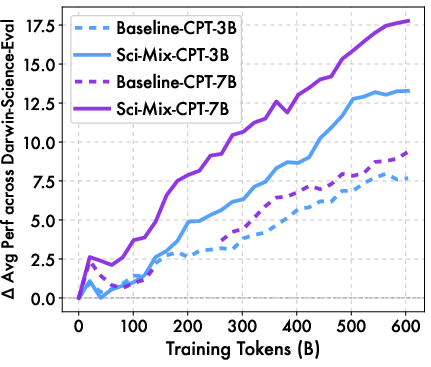
- Across 20+ benchmarks, models trained with Darwin-Science beat strong baselines by about 2–3 points (more for the larger model).
- On science-focused tests, gains were bigger: roughly +6 to +8 points, showing the improvements really mattered for the target domain.
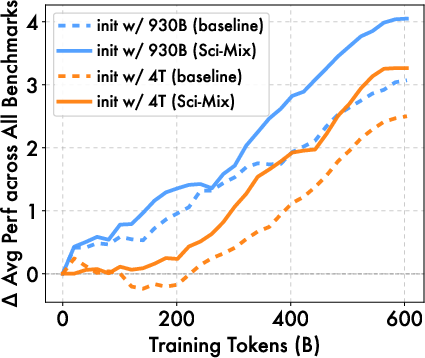
- As training continued, the gains didn’t fade—they kept growing, which suggests the improved data stays valuable at scale.
- Larger models benefit more, meaning the better the “student,” the more they can use the improved “textbooks.”
- Practical tips they discovered:
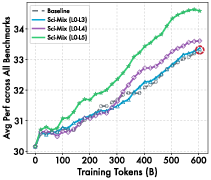
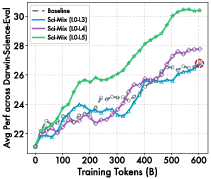
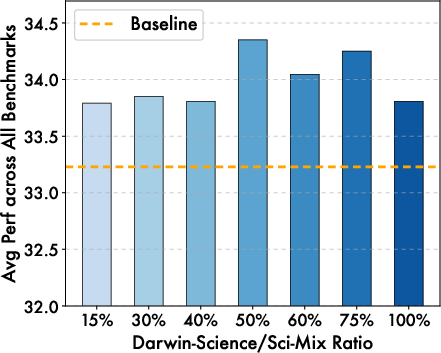
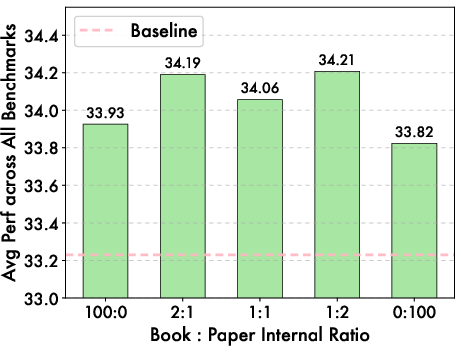
- Mixing about 50% science with other data balances depth and general skills.
- Better “teacher” models used for L5 rewriting produce better training data.
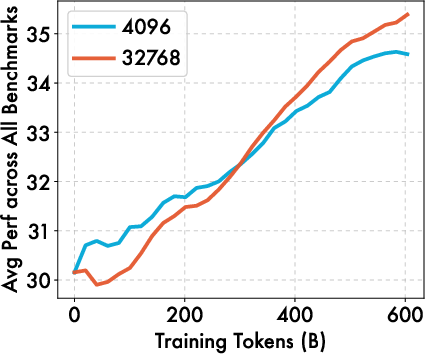
- Longer context windows (like 32K tokens) help once the model adapts.
- Domain-matched tests (science tests for science training) reveal much bigger gains than generic tests.
Why is this important? (Implications and impact)
This work gives AI builders a roadmap for turning raw information into truly useful training material. The main idea is that data quality isn’t just about collecting more—it’s about evolving the data to be teachable. As AI models get smarter, they can help produce better versions of the data (like adding reasoning steps), which then trains even better models. That’s the “Data Darwinism” feedback loop.
What this could lead to:
- Better scientific reasoning in AI, useful for research, engineering, and medicine.
- More reliable and transparent training practices (since the datasets and models are released).
- Future levels (L6–L9) that add context, runnable environments, multi-agent ecosystems, and even full simulated worlds for training—pushing beyond static text into interactive learning.
In short, the paper shows that making science texts clearer and more structured for AI—much like a teacher would for students—unlocks a lot of hidden value. It’s not just what data you have, but how you evolve it.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues, open questions, and limitations that future work could address:
- Framework coverage: Only L0–L5 are implemented. Concrete methodologies, feasibility, and evaluation criteria for L6–L9 (contextual completion, environment/ecosystem/world synthesis) remain unspecified and unevaluated.
- Faithfulness guarantees: L4/L5 rely on large generative teachers but provide no quantitative measures of semantic preservation, hallucination rates, or factual drift introduced by refinement and cognitive completion.
- Verification protocols: No systematic, model-independent audits (e.g., human expert review, alignment-based entailment checks) are reported to validate that L5 “reasoning reconstruction” and “pedagogical bridging” remain faithful to source texts.
- Chunking artifacts: L4 processes 1,024-character chunks and L5 uses 1,024-token windows; the impact of boundary effects on global coherence, cross-chunk consistency (definitions, symbols), and citation integrity is not analyzed.
- Scope of L5: Cognitive completion is applied only to papers (not books) due to cost; the utility, cost-benefit, and potential risks of applying L5 to books are unexplored.
- Teacher dependence: The effectiveness of L5 depends on teacher quality (e.g., Qwen3-235B vs. GPT-OSS-120B), but the minimal teacher capability threshold, robustness across teacher families, and sensitivity to prompting are not characterized.
- Automated evaluation bias: Darwin-Science-Eval questions are generated and filtered by LLMs (Qwen3-32B). Risks of circularity, stylistic overfitting, and model-family bias are not mitigated by independent human verification or cross-family audits.
- Benchmark scope: The evaluation is limited to multiple-choice questions; it does not test open-ended scientific writing, derivation, proof, or code/experiment reproduction, limiting claims about deeper scientific competence.
- Psychometrics and difficulty calibration: No item-response analysis, reliability measures, or difficulty stratification are provided for Darwin-Science-Eval to ensure stable, discriminative assessment.
- Baseline clarity: The “competitive baseline mixture” used for continued pre-training is not fully specified (composition, domain mix, pre-processing), complicating attribution of gains and reproducibility.
- Learnability gap quantification: The paper asserts raw scientific data yields “negligible” gains post L0–L3 but lacks a formal definition or metric for “learnability” and does not present per-discipline or per-operation ablations quantifying where the gap arises.
- Decontamination rigor: Only exact 20-gram matching is used against selected public benchmarks; near-duplicate and semantic-decontamination methods are not applied, and there is no analogous decontamination analysis for the new in-domain benchmarks beyond corpus holdout.
- OCR and formula fidelity: The pipeline depends on a single OCR system (olmOCR-7B) for scanned PDFs; there is no quantitative evaluation of OCR accuracy (especially for equations, tables), error propagation, or comparison with specialized math/LaTeX OCR tools.
- Structural content handling: L4 removes elements such as references and some structural metadata; the downstream impact of removing references (useful for L6-style linking) and the treatment of tables/figures are not evaluated.
- Tokenization suitability: The Qwen tokenizer is used without examining its suitability for scientific notation/LaTeX; potential benefits of math-aware or domain-adaptive tokenization are untested.
- Long-context training: Although 32K context reportedly helps after “sufficient adaptation,” base pre-training uses 4K context. The effect of training with long context from the start on scientific learnability is untested.
- Curriculum and scheduling: The ordering and mixing of L4 vs. L5 data during continued pre-training, curriculum strategies across levels, and sensitivity to science ratio beyond the single reported optimum (50%) remain unexplored.
- Subdomain heterogeneity: Gains are aggregated; per-discipline analyses (e.g., physics vs. medicine vs. CS) are not reported, leaving unclear which fields benefit most and where L4/L5 may harm or help.
- Generalization trade-offs: While average gains are reported, potential regressions on specific general-domain tasks are not analyzed, leaving the specialization–generalization trade-off underexplored.
- Multilingual coverage: The dataset is restricted to English; extending Data Darwinism to multilingual scientific corpora, and assessing cross-lingual transfer or inequities, is left open.
- Safety and ethics: The pipeline does not address biosecurity-sensitive content, misuse risk, or researcher-safety filters for scientific protocols; governance for higher-level synthesis (L7–L9) is not discussed.
- Legal and licensing: The use of “publicly accessible” scanned PDFs lacks a detailed rights audit; reproducibility and redistribution constraints (only a subset released) may limit community validation.
- Duplicate control: Deduplication is at the document level via MinHash; passage-level and cross-source near-duplicate control (including paraphrases) is not analyzed, risking overrepresentation of repeated content.
- Cost-effectiveness: L4/L5 are resource-intensive. There is no detailed compute/cost accounting, ROI analysis (performance per dollar/token), or guidance for resource-constrained settings.
- Model scaling: Only 3B and 7B base models are tested. Whether L4/L5 benefits scale monotonically to larger models (e.g., 13B, 70B) or saturate is unknown.
- Interactions with math/code pre-training: The base models include substantial math/code data; ablations isolating the incremental effect of scientific text vs. math/code overlap are missing.
- Temporal validity: No timestamping or retraction filtering is described; mechanisms to prevent training on outdated or retracted scientific claims are absent.
- Consistency checks: There is no mechanism to detect contradictions introduced by L5 across a document or corpus (e.g., inconsistent variable definitions, differing interpretations across chunks).
- Evaluation robustness: Reliance on perplexity-based multiple-choice evaluation can be brittle; cross-metric robustness (e.g., calibrated decoding, logit pairing) and human-graded tasks are not reported.
- Path to L6: Contextual completion (L6) is defined but not implemented; open questions include retrieval scope control, noise management, and evaluation of “self-containment” without overload.
- Higher-level synthesis evaluation: For L7–L9, there are no proposed correctness, reproducibility, or safety metrics to assess the quality and utility of synthesized environments, ecosystems, or worlds.
Practical Applications
Practical Applications of the paper’s findings, methods, and innovations
Below are targeted, real-world applications derived from Data Darwinism’s hierarchy (L0–L9), the Darwin-Science corpus, Cognitive Completion (L5), Generative Refinement (L4), the Darwin-Science-Eval benchmark, and the contamination-free daVinci-origin base models. Each item notes sectors and potential tools/products/workflows, along with assumptions or dependencies that affect feasibility.
Immediate Applications
- Enterprise data cleaning and preparation with L4 Generative Refinement
- Sectors: software, manufacturing, energy, healthcare, finance, publishing
- What: Deploy L4 to remove noise (headers/footers, OCR artifacts, tables of contents, references), repair equations/tables, and merge fragmented text in SOPs, manuals, policy documents, research archives, and scanned PDFs.
- Tools/workflows: olmOCR-7B for OCR, datatrove MinHash/LSH for deduplication, fast-langdetect, EAI-Distill-0.5B for lightweight classification, GPT-OSS-120B/Qwen-based refinement prompts, chunking at 1,024 characters.
- Dependencies/assumptions: Access to teacher LLMs, document rights/licensing, OCR quality, standardized chunking and prompts, CPU/GPU budget.
- Cognitive Completion (L5) to make expert content teachable and actionable
- Sectors: education, healthcare, engineering, safety/compliance training, software documentation
- What: Rewrite technical or clinical content to add step-by-step derivations, define terminology inline, and add pedagogical bridges/analogies for onboarding, training, and knowledge sharing.
- Tools/workflows: Qwen3-235B (or similar) for L5 rewriting, LLM-as-judge verification, larger 1,024-token windows, domain-specific QA checks.
- Dependencies/assumptions: High-quality teacher LLMs; rigorous verification to avoid hallucinations; domain expert review for sensitive fields (e.g., medicine).
- Domain-specific continued pretraining to build scientific copilots
- Sectors: biotech/pharma R&D, materials science, engineering design, academic research
- What: Use Darwin-Science (open subset) with daVinci-origin-3B/7B to continue pretrain domain models and create “scientific copilots” that better understand research literature.
- Tools/workflows: NeMo for training, clean-room baselines (daVinci-origin), Darwin-Science-Eval for aligned evaluation, recommended data mix (e.g., ~50% scientific content ratio), extended context adaptation (32K).
- Dependencies/assumptions: Compute budget, data licensing, careful contamination checks, model capacity (larger models benefit more).
- Evidence-aligned benchmarking and QA generation
- Sectors: AI product evaluation, academia, standards bodies
- What: Adopt Darwin-Science-Eval methodology to generate distribution-aligned, text-grounded MCQs for internal model assessment in specialized domains.
- Tools/workflows: Three-stage pipeline (knowledge-point detection, completeness, correctness), Qwen3-32B for controlled generation and verification, perplexity-based scoring plus few-shot evaluation.
- Dependencies/assumptions: Robust prompts, reproducible pipelines, held-out sources, rigorous independence/correctness filters.
- Standardized DataOps/MLOps pipeline using the L0–L5 taxonomy
- Sectors: MLOps, data engineering, cloud/AI platforms
- What: Turn the hierarchy into operational checklists and governance artifacts: acquisition, normalization, rule-based filtering, lightweight model filtering, generative refinement, cognitive completion.
- Tools/workflows: Datatrove MinHash/LSH, language detection, discipline classification with EAI-Distill, contamination dechecks, progressive batch scheduling and early-stage evaluation proxies.
- Dependencies/assumptions: Organizational buy-in, clear data provenance, metrics for quality gates, policy/compliance acceptance.
- Pedagogical editions of textbooks and manuals
- Sectors: publishing, ed-tech, daily-life learners
- What: Convert scanned textbooks to clean digital copies (L1/L4) and produce “pedagogical editions” with explicit reasoning and definitions (L5) for self-study and classroom use.
- Tools/workflows: OCR + L4 pipeline + L5 rewriting, editorial verification, integration with learning platforms.
- Dependencies/assumptions: IP/licensing, educator review, bias and accuracy checks.
- Scientific literature search and explainers
- Sectors: academia, knowledge management, software
- What: Generate domain-grounded summaries and explainers from refined papers to accelerate literature reviews and cross-disciplinary understanding.
- Tools/workflows: L4/L5 on abstracts and key sections, retrieval integration for topical clustering, dashboards with domain-aligned evaluation.
- Dependencies/assumptions: High-quality source coverage, careful grounding to the text, scalable chunking and caching.
- Code documentation enhancement
- Sectors: software engineering, developer education
- What: Apply L4 to clean READMEs and comments; use L5 to generate step-by-step tutorials, rationale, and API usage explanations.
- Tools/workflows: Dedup + classification + L4/L5 rewriting, synthetic NL-code pairs integration, language-aware prompts.
- Dependencies/assumptions: Repo licensing, correctness verification, privacy for private repos.
- Clinical guideline augmentation for training and compliance
- Sectors: healthcare
- What: Use L5 to clarify clinical protocols with explicit steps, define terms, highlight contraindications and rationale to improve training and compliance materials.
- Tools/workflows: L5 rewriting with medical QA constraints, human-in-the-loop review, evidence-grounded question generation for MedQA/MedMCQA-like internal exams.
- Dependencies/assumptions: Regulatory constraints, medical validation, patient privacy.
- Safety-critical maintenance manuals with explicit reasoning
- Sectors: energy, aviation, industrial manufacturing
- What: Produce L5-enhanced manuals that articulate causal chains, hazard explanations, and step-by-step procedures for field technicians.
- Tools/workflows: L4 cleaning + L5 cognitive completion + domain QA checks; distribute via ruggedized devices.
- Dependencies/assumptions: Safety verification, updated change control, liability considerations.
- Policy and procurement checklists for data quality and evaluation alignment
- Sectors: public sector, regulators, standards bodies
- What: Require reporting against the Data Darwinism levels, contamination checks, and domain-aligned evaluation in AI procurement and grants.
- Tools/workflows: Taxonomy-based audits, benchmark alignment mandates, documentation templates.
- Dependencies/assumptions: Institutional capacity, adoption by oversight entities, shared definitions of “quality.”
Long-Term Applications
- L6 Contextual Completion: Self-contained research capsules
- Sectors: academia, ed-tech, enterprise knowledge management
- What: Link cited definitions, prior work, and prerequisites into unified artifacts that remove implicit dependencies, enabling standalone comprehension and training.
- Tools/products: “Research capsule” builders integrating semantic search and knowledge graphs.
- Dependencies/assumptions: Reliable retrieval, scalable entity linking, scope control to avoid overload.
- L7 Environment Synthesis: Reproducible, executable science
- Sectors: data science, software engineering, robotics
- What: Auto-synthesize Docker/VM notebooks and runtime configs from papers/tutorials to reproduce experiments and code.
- Tools/products: “Repro Lab Builder” that infers dependencies and creates verified execution environments.
- Dependencies/assumptions: Dependency inference accuracy, sandboxing and security, legal rights to run code.
- L8 Ecosystem Synthesis: Multi-agent research studios
- Sectors: R&D, biotech/materials discovery, strategy/operations
- What: Create agent ecosystems that read literature, debate, design experiments, and generate new hypotheses with continuous logs for training.
- Tools/products: “AI Research Studio” platforms combining LLMs with simulation and workflow orchestration.
- Dependencies/assumptions: High compute for sustained inference, robust coordination/safety, reproducibility pipelines.
- L9 World Synthesis: Long-horizon scientific simulation worlds
- Sectors: foundational AI, simulation-based training
- What: Build physically/socially coherent worlds parameterized by scientific texts to generate effectively unlimited, high-signal training data.
- Tools/products: Large-scale simulation engines integrated with LLM cognition.
- Dependencies/assumptions: Massive compute, theory of consistency and evaluation, ethical safeguards.
- Sector-specific frontier scientific models
- Sectors: drug discovery, clinical decision support, materials/energy design
- What: Train domain LLMs on L5+L6-processed corpora to reason over complex mechanistic causality and protocols; integrate with lab automation and control systems.
- Tools/products: “Scientific copilot” suites, protocol planners, lab notebook assistants.
- Dependencies/assumptions: Integration with instruments, regulatory validation, robust error bounds.
- Formal data-quality standards based on the hierarchy
- Sectors: standards bodies, policy, enterprise governance
- What: Encode L0–L9 into ISO-like norms for dataset documentation, audits, and certification (e.g., “L5-compliant scientific data”).
- Tools/products: Certification bodies, audit toolkits.
- Dependencies/assumptions: Cross-stakeholder consensus, versioning and governance, enforcement.
- Next-generation education platforms
- Sectors: ed-tech, K–12 and higher education
- What: “Living textbooks” with cognitive and contextual completions, dynamic question banks, and personalized tutors grounded in processed content.
- Tools/products: Adaptive curricula, teacher dashboards, aligned assessment generators.
- Dependencies/assumptions: Licensing, pedagogy validation, equity/access, content moderation.
- Clinical decision support with evidence-grounded reasoning chains
- Sectors: healthcare
- What: Combine L5/L6-processed clinical evidence with bedside explanation and protocol planning; create audit trails of reasoning for safety.
- Tools/products: Evidence-grounded CDS modules, regulatory-ready logs.
- Dependencies/assumptions: Prospective trials, explainability standards, HIPAA/GDPR compliance.
- Regulatory and professional exam generation
- Sectors: policy, professional licensing boards
- What: Use controlled, text-grounded QA pipelines to generate fair, representative, verifiable questions from current literature and standards.
- Tools/products: Exam assembly systems with independence/correctness filters.
- Dependencies/assumptions: Governance and fairness audits, periodic refresh, stakeholder review.
- Robotics and control: Simulation data generation via L7/L8
- Sectors: robotics, industrial automation
- What: Convert technical standards and task instructions into executable simulation tasks to train planning/control policies.
- Tools/products: Task synthesis engines, sim-to-real transfer pipelines.
- Dependencies/assumptions: Physics fidelity, domain randomization, safety validation.
- Data marketplaces and “Cognitive Completion as a Service”
- Sectors: data economy, AI tooling
- What: Offer processed scientific datasets (L4/L5/L6) and on-demand cognitive completion pipelines for proprietary corpora.
- Tools/products: Managed services, API-based refinement/completion, usage analytics.
- Dependencies/assumptions: IP rights, licensing frameworks, privacy/security guarantees.
Glossary
- AdamW optimizer: A variant of Adam that decouples weight decay from gradient-based updates to improve generalization. "We train all models using the AdamW optimizer~\citep{loshchilov2019decoupled}"
- Chain-of-Thought prompting: A prompting strategy that elicits step-by-step reasoning traces from models to improve problem solving. "Technical implementation leverages Chain-of-Thought prompting and process supervision."
- Cognitive Completion: L5 in the hierarchy; generative enrichment that makes implicit reasoning explicit and adds pedagogical context. "L5 (Cognitive Completion): We leverage frontier LLMs to transform expert-level writing into pedagogically enriched content."
- Co-evolutionary feedback loop: A cyclical process where stronger models enable better data processing, producing superior data that further improves models. "Central to this framework is a co-evolutionary feedback loop"
- Contamination-free baselines: Baseline models trained with deliberate exclusion of target-domain content to avoid data leakage and enable clean attribution. "a substantial undertaking enabling contamination-free baselines"
- Continued pre-training (CPT): Additional large-scale pre-training starting from existing checkpoints on new data mixtures. "Starting from these base models, we conduct 600B tokens of continued pre-training (CPT)"
- Context length: The maximum number of tokens a model can process in a single sequence. "a context length of 4,096 tokens"
- Contextual Completion: L6 in the hierarchy; augmentation that integrates external references and background knowledge to make documents self-contained. "Contextual Completion (L6) expands data by integrating external references and background knowledge to resolve implicit dependencies."
- Data Darwinism: A ten-level hierarchical framework organizing data processing from selection to synthesis and human-centric to machine-driven operations. "We introduce Data Darwinism, a ten-level hierarchical taxonomy (L0--L9) organizing data transformations from selection to generation, preservation to transformation, and human-centric to machine-driven processing."
- Data provenance: The traceable record of data origins and transformations ensuring integrity and accountability. "The primary technical challenges center on achieving broad coverage, maintaining data provenance, and managing large-scale storage infrastructure."
- Decontamination: Removal of benchmark or evaluation content from training data to prevent test leakage. "we conducted a decontamination process to mitigate benchmark leakage."
- Distribution-aligned assessment: Evaluation designed to match the data distribution of the target domain for more meaningful measurement. "Domain-matched benchmarks reveal 3 larger gains than standard evaluations, emphasizing the necessity of distribution-aligned assessment."
- Ecosystem Synthesis: L8 in the hierarchy; construction of multi-agent systems that generate emergent interactions and data. "Ecosystem Synthesis (L8) constructs dynamic multi-agent systems where diverse intelligent entities interact and evolve."
- Environment Synthesis: L7 in the hierarchy; building executable environments and runtime conditions for reproducible operation of data artifacts. "Environment Synthesis (L7) transcends content enrichment to construct executable, interactive environments where data objects function."
- Few-shot prompting: Providing a small number of examples in the prompt to steer model behavior without full fine-tuning. "we adopted both few-shot prompting and perplexity-based evaluation strategies"
- Frontier LLMs: The most capable, cutting-edge LLMs used to perform advanced data transformations. "We leverage frontier LLMs to transform expert-level writing into pedagogically enriched content."
- Generative Refinement: L4 in the hierarchy; model-driven cleaning and repair that preserves original semantics without adding external knowledge. "Generative Refinement (L4) marks a shift from selection to active, model-driven refinement using medium-to-large generative models."
- Global batch size (GBS): The total effective batch size across all devices/workers used during distributed training. "We employ a progressive global batch size (GBS) scaling strategy:"
- Greedy decoding: Inference that selects the highest-probability token at each step without search, for consistent evaluation. "with inference conducted under greedy decoding settings for consistency across experiments."
- I/O-bound: Workloads limited by input/output throughput (network or storage) rather than compute resources like GPUs. "Computation at this level is predominantly I/O-bound, constrained by network bandwidth and storage capacity rather than GPU resources."
- Knowledge graph technologies: Structured representations and tools for linking and querying entities and relations to support retrieval. "using semantic search and knowledge graph technologies."
- Learnability gap: A mismatch where dense, expert-oriented data yields little model improvement without processing. "raw scientific data suffers a severe learnability gap"
- Lightweight Model Filtering: L3 in the hierarchy; using small models to perform semantic-level filtering and classification. "Lightweight Model Filtering (L3) introduces machine learning-based classification capabilities using pre-trained lightweight models"
- Locality-Sensitive Hashing (LSH): A hashing technique that groups similar documents to enable efficient near-duplicate detection. "with LSH from datatrove~\citep{penedo2024datatrove}"
- Micro-batch size: The per-device batch size used with gradient accumulation to form a larger effective batch. "All models use a micro-batch size of 4."
- MinHash: A probabilistic hashing method for estimating Jaccard similarity, commonly used for deduplication. "deduplication algorithms like MinHash"
- NeMo framework: NVIDIA’s toolkit for training and evaluating LLMs at scale. "All experiments are conducted using the NVIDIA NeMo framework~\citep{nemo2024}."
- OCR (Optical Character Recognition): Converting scanned PDFs or images into machine-readable text. "performing OCR on PDFs and images"
- Perplexity-based evaluation: A scoring method that uses LLM likelihoods to assess multiple-choice answers without generation. "we adopted both few-shot prompting and perplexity-based evaluation strategies"
- Process supervision: Verifying or training on intermediate reasoning steps instead of only final outputs. "Technical implementation leverages Chain-of-Thought prompting and process supervision."
- Reference resolution: Linking citations or references to their sources to create self-contained context. "Key operations include reference resolution and cross-referencing using semantic search and knowledge graph technologies."
- Rotary Position Embeddings (RoPE): A positional encoding method for Transformers that enables better extrapolation of sequence positions. "Rotary Position Embeddings (RoPE,~\citealt{su2021roformer})"
- Semantic fidelity: Preserving the meaning of content while changing format or expression. "while maintaining semantic fidelity."
- Semantic search: Retrieving information based on semantic similarity rather than exact keyword matching. "using semantic search and knowledge graph technologies."
- Structural fragmentation: Broken or malformed structural elements in text (e.g., split equations, damaged tables) that hinder learning. "repairing structural fragmentation (split equations, malformed tables)."
- Token windows: Fixed-length segments of tokens used to chunk documents for scalable processing. "1,024 token windows"
- World Synthesis: L9 in the hierarchy; generating fully coherent simulated worlds with consistent physics and social dynamics. "World Synthesis (L9) represents the theoretical apex of data processing: constructing comprehensive, physically and socially coherent simulated worlds."
Collections
Sign up for free to add this paper to one or more collections.