- The paper leverages the MDL principle to reframe supervised learning as a two-part compression problem, quantifying the trade-off between model complexity and predictive power.
- The paper empirically validates the theory using a modified Colored MNIST benchmark, demonstrating phase transitions in feature reliance as dataset size increases.
- The paper discusses practical implications for neural network robustness, highlighting how training data volume influences the shift from spurious shortcuts to robust, predictive features.
Compression Theory of Simplicity Bias in Neural Networks
The paper "A Compression Perspective on Simplicity Bias" (2603.25839) systematically investigates the notion of simplicity bias in deep neural networks by leveraging the Minimum Description Length (MDL) principle as a rigorous information-theoretic lens. Simplicity bias, the tendency of learning algorithms such as SGD to converge to models representing simple functions, is mapped to the MDL objective: optimal learning minimizes the total description length required for encoding both the model and the data. Specifically, supervised learning is reframed as a two-part compression problem, where the total code-length is the sum of the bits required to describe a hypothesis and the bits required to encode data given that hypothesis.
A key theoretical insight is that neural network training implicitly negotiates the trade-off between model complexity and predictive power. The compression-theoretic framework predicts phase transitions in feature selection as a function of dataset size: with limited data, learners favor simple features and shortcuts, while larger datasets incentivize more complex, predictive features when the reduction in data encoding cost justifies increased complexity. This progression is visualized in the compression envelopes, wherein the MDL-optimal learner transitions between qualitatively distinct solutions as data accumulates.
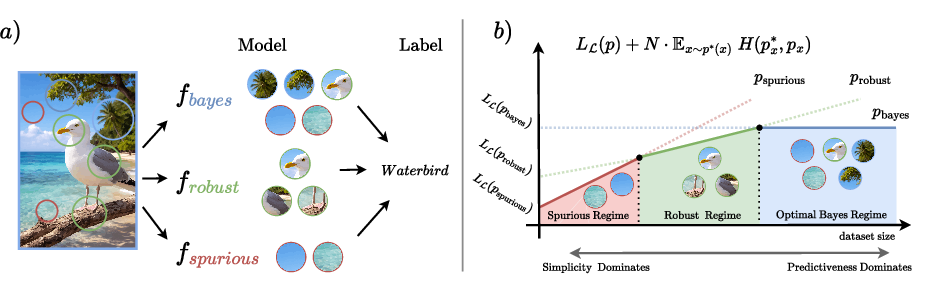
Figure 1: (a) Distinction between causal and spurious features in supervised learning, and (b) the dynamic of transitions between different model types as dataset size increases.
Analysis Across Data Regimes
The total description length for a candidate model decomposes to a fixed model complexity and a variable data encoding cost that grows linearly with training set size. In low-data regimes, the fixed complexity dominates, biasing the learner towards simple, low-cost solutions, which may include spurious environmental correlations or outright memorization. As data volume increases, the linear data encoding term becomes dominant; this compels the learner to prioritize minimizing KL divergence with the true conditional distribution, thus selecting more sophisticated and predictive models superseding simplicity.
This dynamic directly explains why models may overfit and exploit spurious correlations in data-scarce settings, but ultimately transition to robust feature exploitation as sufficient data accrues. Notably, the theory predicts both lower and upper bounds on the dataset size for robust generalization, as well as scenarios where limiting data acts as a form of complexity-based regularization by preventing learning of unreliable environmental cues.
Empirical Validation and Feature Selection Dynamics
To empirically validate the compression theory, the authors introduce a semi-synthetic benchmark derived from Colored MNIST, engineered to control feature complexity and environment-specific signals. Each input contains (i) causal digit shape, (ii) spurious color correlated with environment, and (iii) complex watermark as an environmental cue. By manipulating the predictiveness and complexity of these features, two principal scenarios are investigated: (A) spurious vs. robust solution, where simplicity favors unreliable spurious signals with low complexity; (B) robust vs. Bayes-optimal, where complex environmental cues are highly predictive but expensive to encode.
Empirical training and analysis of neural networks across dataset size regimes demonstrate exact alignment with MDL-theoretic predictions: the phase transitions in feature reliance (as evaluated via accuracy and permutation importance metrics) precisely coincide with those predicted by compression envelopes.
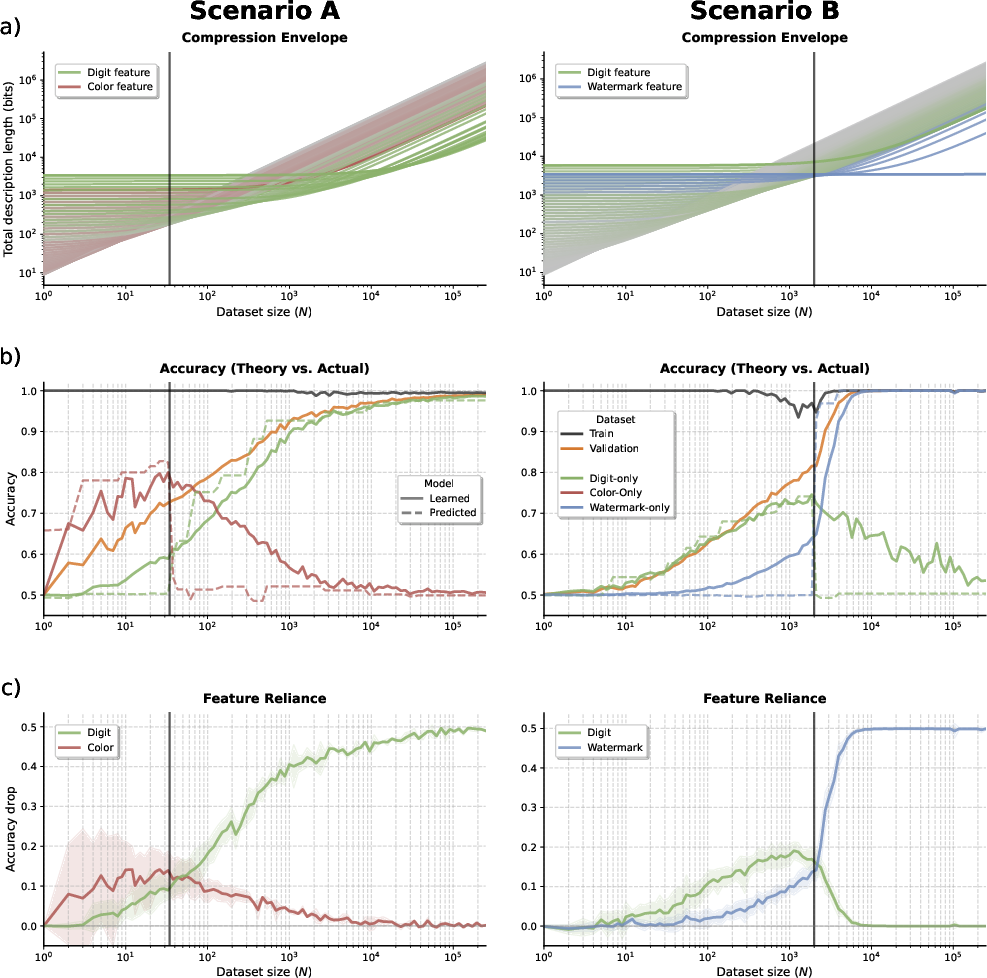
Figure 2: Comparison of compression envelopes and empirical learning behavior across training sizes, with corresponding phase transitions and feature importance visualization.
Data-driven experiments further explore how varying feature complexity and correlation strength affect the empirically observed and theoretically predicted transition points. For example, increasing watermark complexity delays the switch to environment-dependent solutions, affirming that model complexity constrains the learner until the information gain from feature predictiveness offsets the overhead.
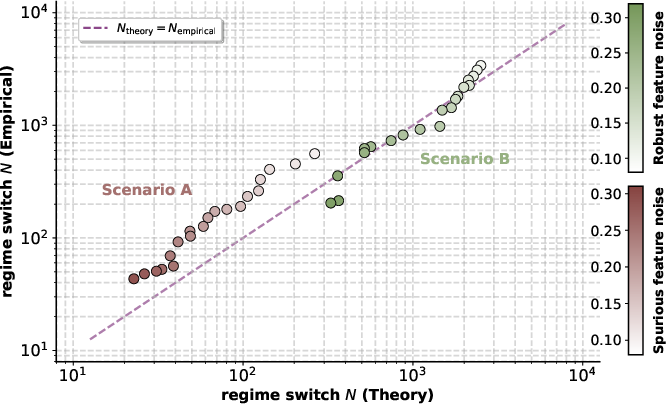
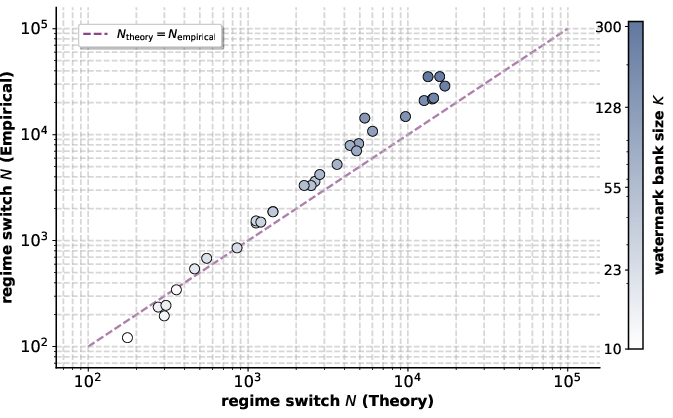
Figure 3: Impact of feature predictiveness on phase transition—lower correlation enables earlier reliance on robust features.
Practical and Theoretical Implications
This compression-centric perspective reveals nuanced implications for model selection and OOD robustness. Rather than being universally beneficial, simplicity bias can promote or impede generalization, contingent on feature composition and data availability. In low-data regimes, simplicity bias encourages shortcut learning and overfitting; in high-data regimes, it incentivizes exploitative but potentially brittle environment-dependent cues. Practically, complexity-based regularization emerges from these dynamics: constraining training data can maintain the learner in a robust regime by rendering complex, noncausal solutions prohibitively expensive.
A significant theoretical corollary is the compression-theoretic justification for strategies such as pretraining: exposure to diverse environments amortizes the description cost of robust features prior to supervised learning, thereby facilitating earlier transitions to robust solutions in downstream tasks.

Figure 4: Curated benchmark samples exhibiting the distinction and interplay of digit, color, and watermark features.
Limitations and Prospective Directions
The present framework idealizes candidate models as exploiting strictly disjoint feature subsets. However, real-world problems exhibit overlapping, partially predictive features and complex interactions. Extension to blend multiple features and model their combined contribution to compression cost would allow the theory to predict gradual transitions and more realistic failure modes. Further, computational scalability remains a challenge in evaluating MDL and prequential code-lengths for large-scale architectures.
Conclusion
The paper establishes a precise theoretical and empirical framework linking simplicity bias in deep learning to the MDL principle, predicting feature transitions as a function of data-regime and feature properties. It demonstrates that both robust and spurious solutions are rational outcomes under the compression trade-off, determined by data availability and feature complexity. This information-theoretic perspective offers actionable insight for designing models and curricula for robust generalization, and motivates future research in extending MDL-based theories to multimodal and high-dimensional settings.