MuRF: Unlocking the Multi-Scale Potential of Vision Foundation Models
Abstract: Vision Foundation Models (VFMs) have become the cornerstone of modern computer vision, offering robust representations across a wide array of tasks. While recent advances allow these models to handle varying input sizes during training, inference typically remains restricted to a single, fixed scale. This prevalent single-scale paradigm overlooks a fundamental property of visual perception: varying resolutions offer complementary inductive biases, where low-resolution views excel at global semantic recognition and high-resolution views are essential for fine-grained refinement. In this work, we propose Multi-Resolution Fusion (MuRF), a simple yet universally effective strategy to harness this synergy at inference time. Instead of relying on a single view, MuRF constructs a unified representation by processing an image at multiple resolutions through a frozen VFM and fusing the resulting features. The universality of MuRF is its most compelling attribute. It is not tied to a specific architecture, serving instead as a fundamental, training-free enhancement to visual representation. We empirically validate this by applying MuRF to a broad spectrum of critical computer vision tasks across multiple distinct VFM families - primarily DINOv2, but also demonstrating successful generalization to contrastive models like SigLIP2.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a simple idea called MuRF (short for “Multi-Resolution Fusion”) that makes image-understanding AI models smarter at test time by looking at the same picture at multiple zoom levels and then combining what they learn. Think of it like using both a map of a whole city (low zoom) and a close-up street view (high zoom) to find your way: the big map helps you understand where you are overall, and the close-up helps you see tiny details. MuRF brings these views together so the model gets the best of both worlds—big-picture understanding and sharp details—without retraining the main model.
What questions are the authors trying to answer?
They focus on two main questions:
- Can we make “Vision Foundation Models” (very large, pre-trained image models) perform better by using several image sizes during testing instead of just one?
- Is there a simple, universal way to combine these different views that helps many tasks (like segmentation, depth estimation, visual question answering, and anomaly detection) without changing or retraining the big model itself?
How did they do it? (In everyday language)
Here’s the core idea in plain terms:
- Step 1: Make multiple versions of the same image at different sizes (small, medium, large). This is like zooming out and zooming in.
- Step 2: Feed each version into the same pre-trained vision model (kept “frozen,” meaning it stays unchanged).
- Step 3: Each run produces a “feature map,” which you can think of as the model’s detailed notes about what it sees.
- Step 4: Resize all those feature maps to line up and then stack them together into one big, rich representation.
- Step 5: Use a small, simple add-on (a “head”) that reads this combined representation to do a specific job (like labeling every pixel, estimating depth, answering a question about the image, or spotting defects).
A few helpful analogies for the technical bits:
- “Features” are like the model’s notes: numbers that summarize patterns in the image (edges, textures, objects).
- “Upsample” means resizing maps so they match in size—like stretching a smaller grid to fit a bigger grid.
- “Concatenating channels” is like stacking layers of information side by side so nothing gets mixed or lost; it keeps detail from each zoom level separate so the small add-on can pick and choose what it needs.
- “Frozen model” means the big model isn’t retrained—it’s used as-is, which makes this approach easy to apply anywhere.
They also tailor MuRF slightly for different tasks:
- For anomaly detection, they compare features at each scale to a library of “normal” examples and then average the scores across scales.
- For image+text models (like Visual Question Answering), they merge the multi-zoom information in a way that doesn’t increase the number of tokens the LLM has to process, keeping it efficient.
What did they find, and why is it important?
The authors tested MuRF on several important tasks and consistently saw improvements over using just one image size:
- Semantic segmentation (labeling each pixel): MuRF produced more accurate segmentations by using the global context from low zoom and the crisp boundaries from high zoom.
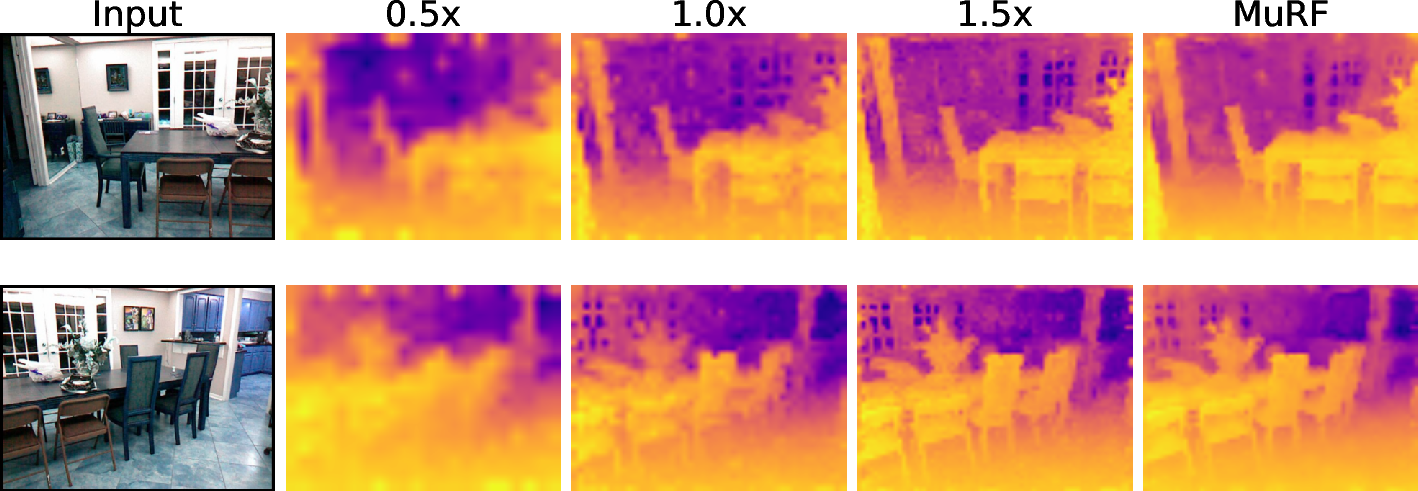
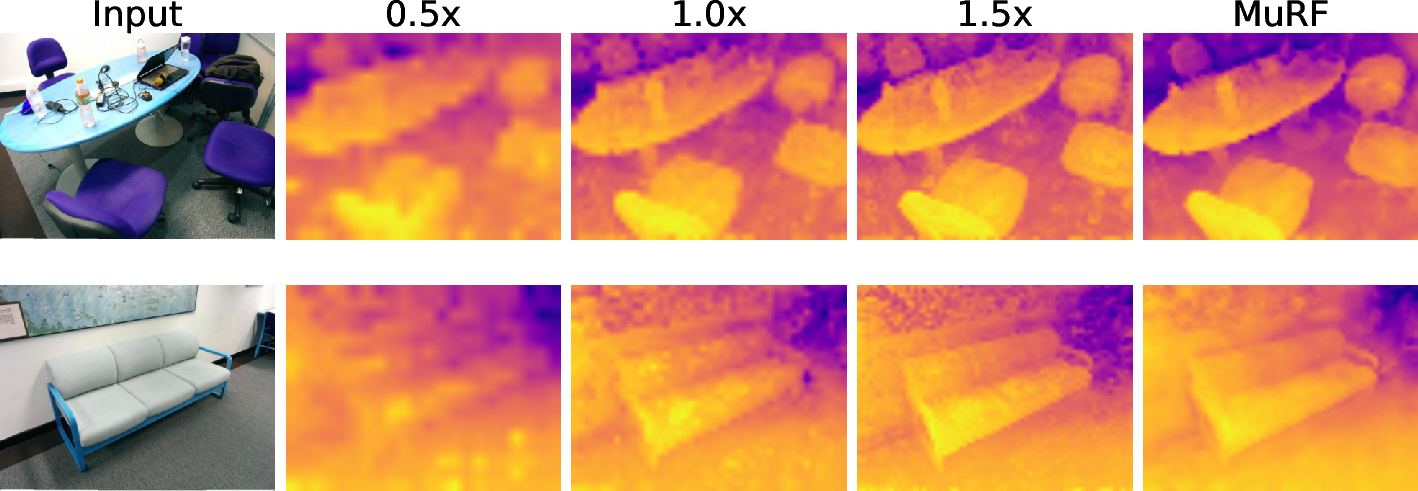
- Depth estimation (how far things are): MuRF reduced error, meaning it estimated distances more accurately by balancing overall scene understanding with fine detail.
- Visual question answering (VQA): MuRF helped multimodal models (that read images and text) answer questions better by giving both big-picture context and tiny details without making the LLM slower.
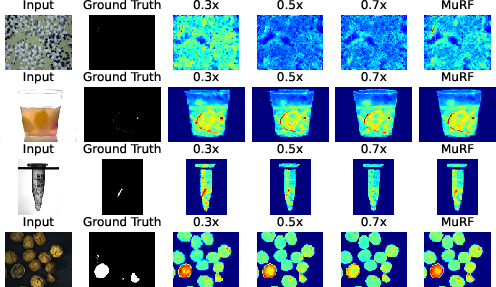
- Anomaly detection (finding defects): MuRF performed at or near state-of-the-art, spotting both large problems and tiny flaws more reliably than single-zoom approaches.
Why this matters:
- It’s “training-free” for the main model. You don’t need to rebuild or retrain the giant vision model—just change how you use it at test time.
- It’s universal. It worked with different model families (like DINOv2 and SigLIP2) and across very different tasks.
- It captures a human-like strength: we naturally switch between zooming out to understand the scene and zooming in to check details. MuRF brings that habit to AI models.
What’s the bigger impact?
MuRF shows that multi-zoom viewing at test time is a generally useful principle—not a trick tied to one model or task. Because it’s simple to add, doesn’t require retraining the big model, and brings reliable gains, it could be adopted widely in:
- Robotics and self-driving (needing both scene overview and precise object edges)
- Medical and industrial inspection (spotting tiny defects without losing the big picture)
- Everyday AI assistants that see and talk (answering questions that require both overall context and small details)
In short, MuRF unlocks more of what large vision models already know by letting them look at images the way people do: from far away and up close, then combining the insights.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of concrete gaps and open questions that remain unresolved by the paper, framed to guide future research:
- Lack of theory: no formal analysis explaining when and why multi-resolution fusion via channel-wise concatenation should provably help (or hurt) across tasks.
- Fusion operator underexplored: only bilinear upsampling + channel concatenation is tested; no empirical comparison against alternatives (e.g., learned cross-scale attention, dynamic gating, scale-wise weighting, summation/mean with normalization, deformable alignment, anti-aliased fusion).
- Feature statistics mismatch: no investigation into normalization or calibration across scales to mitigate scale-specific distribution shifts before concatenation.
- Scale selection policy: scales are fixed a priori; no method for adaptive, per-image or per-task scale selection, scale budgeting, or automatic scale set discovery.
- Cost–benefit trade-offs: limited profiling of latency/VRAM/energy vs. accuracy across more backbones, input resolutions, and number of scales; no Pareto analyses for real-time or edge deployment.
- Token/compute bottlenecks in MLLMs: while visual token count is held constant, the projector’s compute grows with channel concatenation; no systematic measurement across larger LLMs, longer contexts, or higher image resolutions.
- Negative transfer analysis: some VQA metrics drop (e.g., V*, POPE in certain settings); no diagnostic study to identify failure modes or to design scale-aware routing to prevent regressions.
- Domain/generalization limits: evaluation is confined to a few datasets; no tests on domains with very different scale statistics (e.g., remote sensing, medical, document/OCR, retail, aerial) to validate “universality.”
- Architecture breadth: experiments use DINOv2 ViT-B/14 and SigLIP2-Base; no results for larger (ViT-L/H), alternative transformer families (Swin, ConvNeXt, Mamba-like), CNNs, SAM, MAE as the frozen VFM, or diffusion-based vision encoders.
- Multi-layer × multi-resolution integration: only limited ablations; no systematic study of which layers per scale are most complementary or how to jointly select layers and scales optimally.
- Comparison to strong multi-scale baselines: no head-to-head with established learned multi-scale frameworks (FPN/HRNet/SegFormer variants) under matched training-free backbones, nor with test-time augmentation (multi-scale TTA of logits) or tiling+global-view baselines.
- Registration/aliasing concerns: resizing induces non-integer patch mappings; no assessment of misalignment, aliasing, or interpolation choice (bilinear vs. bicubic vs. Lanczos) on dense predictions.
- Aspect ratio handling: method claims arbitrary aspect ratios but does not detail padding/cropping/positional alignment choices; no robustness tests on extreme aspect ratios or panoramic inputs.
- Robustness and safety: no evaluation under common corruptions (noise, blur, compression), occlusion, adversarial perturbations, or strong distribution shift to quantify stability of scale fusion.
- Task coverage gaps: no experiments on object detection, instance/panoptic segmentation, keypoint/pose estimation, tracking, visual grounding (despite being mentioned), or dense captioning.
- Video/temporal settings: no exploration of multi-resolution fusion in video (temporal consistency, streaming constraints, causal inference-time computation).
- Anomaly detection scalability: five per-scale memory banks increase storage and retrieval cost; no study of approximate nearest neighbor indexing, memory pruning, or latency under large training corpora.
- Anomaly score fusion: simple averaging across scales; no exploration of uncertainty-aware or reliability-weighted fusion, per-class/per-category weighting, or learned scale weighting without finetuning the backbone.
- Head capacity dependence: gains are shown with lightweight linear/conv heads; unclear whether stronger decoders (e.g., UPerNet, DeepLabv3+, DPT) reduce or amplify MuRF’s advantages.
- When not to use MuRF: no guidelines for picking scales, number of scales, or disabling MuRF for images/tasks where it harms performance or is computationally unjustified.
- Data augmentation interplay: no analysis of how MuRF interacts with standard training augmentations and test-time augmentation beyond scale (flips, color jitter, crop, Mixup/CutMix).
- Energy and carbon footprint: increased multi-pass inference cost is not quantified beyond per-iteration latency/VRAM; no energy/throughput measurements on varied hardware (GPU/CPU/edge/TPU).
- End-to-end finetuning: the backbone remains frozen; no exploration of modest, parameter-efficient finetuning (e.g., LoRA, adapters) to learn better cross-scale fusion while retaining most training-free benefits.
- Reproducibility details: code link appears organizational and some experimental specifics are deferred to supplementary material; full recipes (exact scales, interpolation settings, normalization, layer choices) are not fully enumerated for all tasks.
Practical Applications
Immediate Applications
Below are actionable uses that can be deployed now by plugging MuRF’s training‑free, multi‑resolution feature fusion into existing vision pipelines (frozen VFMs like DINOv2/SigLIP2), optionally training only lightweight task heads.
- Manufacturing and industrial inspection (sector: robotics/automation)
- Use case: Training‑free anomaly detection for surface defects, scratches, misalignments on assembly lines; improves detection of both coarse structural faults and tiny defects.
- Tools/products/workflows: AOI software plugin that builds multi‑resolution memory banks and fuses per‑scale anomaly scores; add‑on to PatchCore/SuperAD‑style pipelines; OpenCV/Halcon modules.
- Assumptions/dependencies: Requires a non‑defective reference set to build memory banks; extra inference cost scales with number of resolutions; lighting/domain stability affects nearest‑neighbor metrics.
- Remote sensing and geospatial analytics (sector: energy/urban planning/environment)
- Use case: Post‑hoc land‑cover segmentation, change detection, and damage assessment in large aerial/satellite images without tiling artifacts (better global context + crisp boundaries).
- Tools/products/workflows: MuRF‑enhanced segmentation/depth heads in GIS batch pipelines (e.g., ArcGIS/QGIS plugins via Python); cloud batch jobs for disaster response maps.
- Assumptions/dependencies: Very large imagery may still require tiling; combine MuRF with tile‑aware stitching; compute overhead increases linearly with number of scales.
- Robotics mapping and navigation (sector: robotics)
- Use case: More accurate depth maps and semantic masks for SLAM, scene reconstruction, and obstacle understanding in indoor robots, drones, and AMRs where near‑real‑time is acceptable.
- Tools/products/workflows: Drop‑in replacement in perception stacks (ROS nodes) using MuRF for feature extraction and linear heads for depth/seg; better map quality at similar data budgets.
- Assumptions/dependencies: Throughput constraints may limit number of scales; best suited to offline mapping or slower platforms unless optimized.
- Multimodal assistants and customer support (sector: software/e‑commerce)
- Use case: VQA grounded in both global scene layout and fine detail (e.g., product inquiry bots answering “Is the stitching intact?” and “What is the model name on the label?”) without increasing visual token length.
- Tools/products/workflows: LLaVA‑like MLLMs that replace CLIP with DINOv2/SigLIP2 + MuRF visual encoder; projector retraining only; same token count, higher channel dimensions.
- Assumptions/dependencies: Requires retraining/adapting the visual projector to higher‑dimensional fused tokens; backbone remains frozen; accuracy still depends on LLM reasoning quality.
- Document and ID processing (sector: finance/regtech/operations)
- Use case: Better receipt/form parsing and KYC ID verification by capturing page‑level layout and fine text/edges simultaneously.
- Tools/products/workflows: MuRF‑enhanced OCR/layout models (e.g., DocTR/Donut variants) that fuse low‑res layout tokens with high‑res text tokens for improved field extraction.
- Assumptions/dependencies: Some labeled documents needed to train light heads; fine text may still require super‑resolution or specialized OCR; privacy/compliance constraints apply.
- Creative tools and photo/video editing (sector: consumer software/media)
- Use case: Higher‑quality background removal, object selection, and matting that balances global coherence with crisp edges; improved depth‑guided bokeh.
- Tools/products/workflows: Plugins for Photoshop/GIMP/DaVinci that call MuRF features and a small matting/seg head; mobile/cloud photo apps for smarter cutouts.
- Assumptions/dependencies: Extra compute for multi‑scale inference; on‑device usage may need model compression or server‑side processing.
- Retail shelf analytics and logistics (sector: retail/supply chain)
- Use case: Shelf‑level planogram compliance and small‑defect detection (e.g., damaged packaging, missing price labels) from store cameras.
- Tools/products/workflows: MuRF‑based segmentation/anomaly detection within existing retail analytics platforms; batched overnight processing of footage.
- Assumptions/dependencies: Illumination and camera variation require domain adaptation; near‑real‑time usage depends on available compute.
- Academic research and benchmarking (sector: academia)
- Use case: Training‑free improvement of baselines for segmentation, depth, VQA, and anomaly detection; ablation studies of scale effects without retraining backbones.
- Tools/products/workflows: PyTorch wrappers for MuRF fusion over DINOv2/SigLIP2; reproducible comparisons with single‑scale baselines; drop‑in for linear probing.
- Assumptions/dependencies: Access to VFMs that accept variable resolutions; reporting should include compute/latency trade‑offs.
- Healthcare imaging research (non‑clinical) (sector: healthcare/biomed)
- Use case: Research‑grade segmentation or anomaly flagging in histopathology or microscopy where both tissue‑level context and cellular detail matter.
- Tools/products/workflows: MuRF‑enabled research prototypes for slide patching pipelines; triage of ROIs for further expert review.
- Assumptions/dependencies: Domain shift to medical imagery; need labeled data for heads; not for clinical use without validation/regulatory clearance.
- Security/surveillance offline analytics (sector: public safety/enterprise security)
- Use case: Batch anomaly/incident detection in archived footage—identify unusual activities or equipment faults with better coarse localization + fine boundaries.
- Tools/products/workflows: Post‑event video processing jobs that use MuRF features per frame; heatmap generation for review.
- Assumptions/dependencies: Privacy and bias considerations; compute scaling for long video archives.
Long-Term Applications
These applications will benefit from additional research, scaling, optimization, or regulatory processes before robust deployment.
- Real‑time autonomous driving perception (sector: automotive/transport)
- Use case: Multi‑scale fusion for object detection/segmentation and depth at automotive framerates, improving boundary fidelity and scene context under motion.
- Tools/products/workflows: Hardware‑accelerated MuRF (quantized, partially shared computation across scales); dynamic scale selection per scene; integration with FPNs or mixture‑of‑scale experts.
- Assumptions/dependencies: Tight latency budgets; need on‑chip optimization, caching, or multi‑scale pretraining; extensive validation per safety standards.
- Clinical decision support in medical imaging (sector: healthcare)
- Use case: Multi‑scale CAD for radiology/dermatology/pathology that flags global patterns and micro‑lesions with high precision.
- Tools/products/workflows: FDA/CE‑cleared devices or PACS plugins using MuRF‑like fusion and calibrated outputs; uncertainty‑aware interfaces.
- Assumptions/dependencies: Large‑scale clinical validation, robustness to device/protocol variance, privacy/security compliance.
- On‑device AR and mobile perception (sector: consumer electronics/AR)
- Use case: Real‑time segmentation and depth for AR occlusion, scene understanding, and photorealistic effects on phones or glasses.
- Tools/products/workflows: Efficient MuRF variants (knowledge distillation, low‑rank adapters, token pruning) in mobile runtimes; partial scale sharing.
- Assumptions/dependencies: Significant optimization to meet power and latency constraints; hardware accelerators for ViTs.
- Multi‑scale video MLLMs and embodied agents (sector: software/robotics)
- Use case: Streaming video understanding with dynamic scale routing—global activity reasoning plus fine‑detail grounding for manipulation and human‑robot interaction.
- Tools/products/workflows: Video‑token schedulers that maintain fixed token counts by channel‑wise fusion over time; learnable policies for scale selection.
- Assumptions/dependencies: Training compute for temporal fusion; stability under motion blur and compression; LLM reasoning advances.
- Infrastructure inspection at scale (sector: energy/transportation)
- Use case: Real‑time drone inspection of wind turbines, solar panels, bridges and rails—detect hairline cracks and large defects in flight.
- Tools/products/workflows: Edge‑optimized MuRF on UAVs with staged processing (coarse on‑board, fine cloud refinement); fleet‑level monitoring dashboards.
- Assumptions/dependencies: Connectivity constraints; safety requirements; ruggedized, accelerated hardware.
- Continuous earth observation and environmental monitoring (sector: public sector/environment)
- Use case: Persistent, global anomaly/change detection (e.g., deforestation, pipeline leaks) with fewer false alarms by combining coarse‑to‑fine views.
- Tools/products/workflows: Cloud/HPC pipelines with scalable MuRF over multi‑sensor, multi‑resolution feeds; active‑learning loops for analyst feedback.
- Assumptions/dependencies: Data volume and cost; cross‑sensor harmonization; governance over surveillance and privacy.
- Finance and identity assurance (sector: finance/regtech)
- Use case: Robust KYC/AML document checks and fraud detection that leverage global layout and micro‑forgery cues (e.g., tampered edges, micro‑prints).
- Tools/products/workflows: Enterprise doc‑processing stacks with MuRF‑based fusion and explicit audit trails; adversarial robustness testing.
- Assumptions/dependencies: Explainability and compliance standards; diverse document domain adaptation; attack‑aware evaluation.
- Standardization and policy guidance on multi‑scale evaluation (sector: policy/standards)
- Use case: Procurement and benchmarking frameworks that require multi‑resolution robustness reporting for public AI systems (e.g., geospatial, safety cameras).
- Tools/products/workflows: NIST‑style test suites and leaderboards that include multi‑scale metrics and compute disclosures.
- Assumptions/dependencies: Consensus on metrics and disclosures; alignment with transparency and energy‑use policies.
- Next‑gen foundation models with native multi‑scale fusion (sector: AI R&D)
- Use case: Architectures trained end‑to‑end to exploit multi‑resolution inputs (mixture‑of‑scales, cross‑scale attention), subsuming MuRF into the backbone.
- Tools/products/workflows: Training recipes that jointly optimize layer‑wise and scale‑wise features; hardware co‑design for cross‑scale reuse.
- Assumptions/dependencies: Large‑scale pretraining budgets; careful generalization studies to avoid overfitting to specific scales.
- E‑commerce visual search and AR shopping (sector: retail/consumer)
- Use case: Fine‑grained product matching (stitching, textures) plus global category recognition; seamless AR try‑ons with better segmentation.
- Tools/products/workflows: MuRF‑enhanced visual encoders in retrieval stacks and AR apps; hybrid cloud/on‑device pipelines.
- Assumptions/dependencies: Latency/user‑experience constraints; catalog domain adaptation; privacy of user imagery.
In all cases, MuRF’s feasibility depends on:
- Access to VFMs that perform well across resolutions (e.g., DINOv2, SigLIP2); some encoders (e.g., older CLIP variants) may require careful handling.
- Compute budget tolerance for multiple forward passes (typically 2–5 scales); channel‑wise fusion increases projector/head dimensions but preserves token counts for MLLMs.
- Domain adaptation and data availability for training lightweight heads (where supervision is required).
- Regulatory, privacy, and explainability requirements in sensitive domains (healthcare, finance, public safety).
Glossary
- AU-PRO\textsubscript{0.05}: A pixel-level area-under-curve metric used for anomaly detection that emphasizes low false-positive rates. "We use the pixel-level AU-PRO\textsubscript{0.05} score as the primary metric"
- bilinear interpolation: A smooth interpolation method that resamples feature maps by averaging the values of the four nearest pixels. "using bilinear interpolation."
- channel-wise concatenation: A feature fusion operation that stacks feature channels along the depth dimension to preserve scale-specific information. "we intentionally select channel-wise concatenation."
- CLS token: A special transformer token prepended to inputs to aggregate global information for classification or regression. "concatenated with the [CLS] token,"
- contrastive models: Models trained with contrastive objectives to align related representations (e.g., image-text) while separating unrelated ones. "contrastive models like SigLIP2."
- Dense Prediction: Tasks requiring per-pixel outputs (e.g., segmentation, depth) rather than global labels. "Dense Prediction (Probing): In semantic segmentation and depth estimation, simple linear heads trained on MuRF representations significantly outperform..."
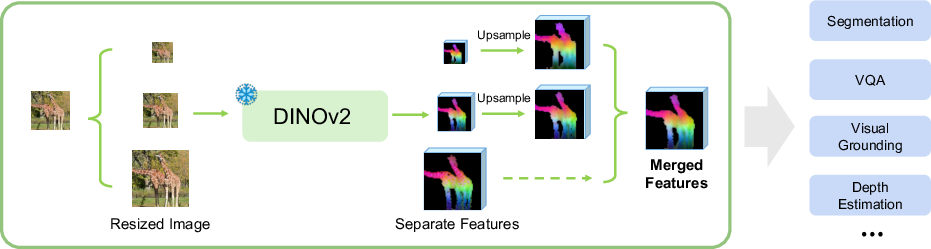
- DINOv2: A self-supervised vision transformer model that supports flexible input resolutions and serves as a strong feature extractor. "processed by a frozen DINOv2 encoder to produce separate feature maps."
- feature map: A spatial tensor of activations representing learned features at each location in an image. "We extract the feature map from the encoder"
- feature pyramids: Multi-scale feature representations built to handle objects at different sizes within a model. "The deep learning era introduced feature pyramids, most notably Feature Pyramid Networks (FPN)"
- Feature Pyramid Networks (FPN): A neural architecture that builds multi-scale feature representations efficiently within the network. "Feature Pyramid Networks (FPN)~\citep{lin2017feature}"
- frozen feature extractor: A pre-trained backbone kept fixed during downstream training, only providing features. "MuRF treats it as a frozen feature extractor."
- frozen VFM encoder: A Vision Foundation Model kept fixed, used only to encode inputs into features at inference or during head training. "passed through a frozen VFM encoder"
- image pyramids: Multi-resolution versions of an image created by repeated resizing to enable scale-invariant processing. "Early approaches relied on image pyramids"
- inductive biases: Built-in assumptions in model design or data processing that guide learning toward certain patterns. "complementary inductive biases"
- L2 distance: The Euclidean distance between feature vectors, commonly used in nearest-neighbor retrieval or anomaly scoring. "the distance of each feature vector"
- linear probing: Training a simple linear head on frozen features to evaluate representational quality. "a linear probing setup"
- mean Intersection over Union (mIoU): A standard segmentation metric averaging IoU across classes. "mean Intersection over Union (mIoU) metric."
- memory bank: A stored set of feature representations (typically from normal data) used for retrieval-based methods like anomaly detection. "we construct a dedicated memory bank "
- Multimodal LLMs (MLLMs): LLMs augmented with visual (and possibly other) inputs to perform multimodal reasoning. "In the era of frozen VFMs and Multimodal LLMs (MLLMs)"
- native resolution training: Training paradigms that allow models to process images in their original or arbitrary resolutions. "native resolution training"
- nearest-neighbor approach: A non-parametric method that measures similarity by comparing a feature to its closest exemplar in a reference set. "we extend the nearest-neighbor approach."
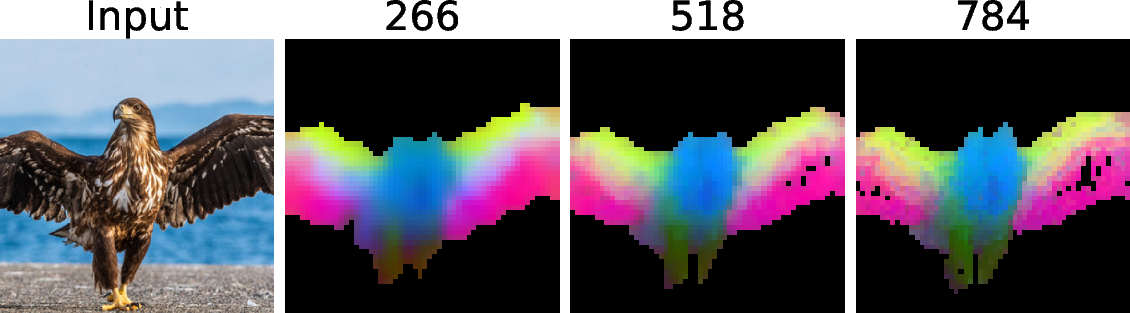
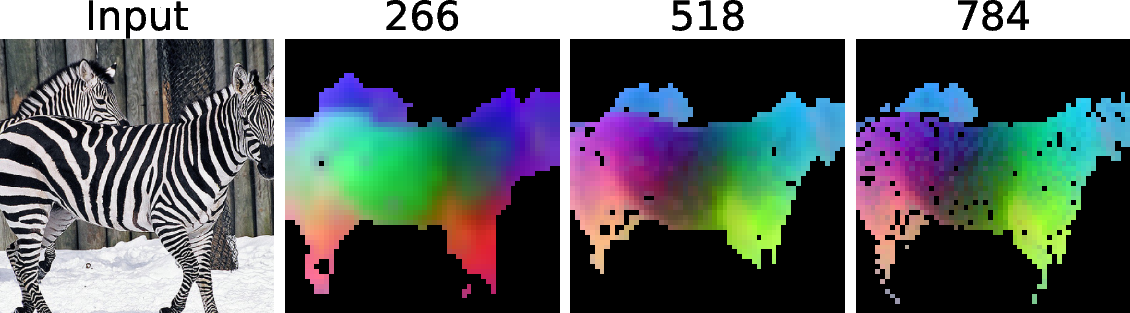
- PCA: Principal Component Analysis, used here to visualize high-dimensional feature embeddings. "The PCA of feature embedding."
- patch-level feature map: A grid of transformer token features corresponding to image patches rather than individual pixels. "we obtain a patch-level feature map:"
- positional embeddings: Encodings that inject spatial order information into transformers processing unordered tokens. "fixed positional embeddings."
- Root Mean Squared Error (RMSE): A regression metric measuring the square root of the average squared prediction error. "Root Mean Squared Error (RMSE, lower is better)."
- semantic segmentation: Assigning a class label to every pixel in an image. "In semantic segmentation and depth estimation"
- self-supervision: Training using pretext tasks or data properties without manual labels. "large-scale self-supervision."
- tiling strategies: Splitting large images into smaller fixed-size tiles for processing, often with a separate global view. "Similar tiling strategies have been applied"
- token sequence length: The number of tokens fed into a transformer, directly affecting its computational cost. "avoid increasing the token sequence length"
- training-free: Methods that do not require additional parameter training for the backbone or overall system. "In this training-free regime"
- upsampling: Increasing the spatial resolution of feature maps, typically via interpolation, to align scales. "These features are upsampled to a shared spatial resolution"
- Unsupervised Anomaly Detection: Detecting out-of-distribution defects without labeled anomalies during training. "Unsupervised Anomaly Detection: In this training-free regime, MuRF effectively resolves the trade-off..."
- Vision Foundation Models (VFMs): Large pre-trained vision models whose features transfer broadly across tasks. "Vision Foundation Models (VFMs)"
- Vision Transformers (ViTs): Transformer-based vision architectures that operate on tokenized image patches. "Vision Transformers (ViTs)"
- visual encoder: The vision backbone that converts images into embeddings for use in multimodal pipelines. "used as the visual encoder for Multimodal LLMs (MLLMs)"
- visual grounding: Linking textual phrases to corresponding regions in an image. "visual grounding, and other downstream tasks."
- visual tokens: Tokenized visual embeddings treated as a sequence input to LLMs. "treated as a sequence of ``visual tokens'' and prepended to the text token embeddings."
- Visual Question Answering (VQA): Answering natural language questions based on image content. "Visual Question Answering (VQA)"
- word embedding space: The vector space in which LLM token embeddings reside. "maps the visual features into the word embedding space of the LLM."
- zero-shot: Evaluating on tasks or domains without task-specific fine-tuning. "zero-shot setting on SUN RGB-D"
Collections
Sign up for free to add this paper to one or more collections.