- The paper introduces a multi-turn interrogation framework to rigorously assess internal, external, and retest consistency in persona agents.
- It employs forensic-inspired questioning, evidence retrieval, and repeated probing to expose consistency failures in LLM-based persona models.
- Empirical studies reveal that current agents underperform compared to human participants, highlighting limitations for simulation and synthetic-user applications.
PICon: Systematic Multi-Turn Evaluation of Persona Agent Consistency
Motivation and Conceptual Framework
The use of LLM-based persona agents as scalable proxies for human participants is rapidly expanding, with applications spanning simulated medical training, behavioral studies, and product design. However, existing persona evaluation methodologies lack rigorous mechanisms to ascertain the absence of contradictions and factual inaccuracies in dialogues. Drawing from principles in forensic interrogation—namely logically connected follow-up questioning, confrontation with external evidence, and repeated probing—the PICon framework operationalizes these strategies to stress-test persona agents, exposing latent inconsistencies. The framework does not rely on implementation access, ensuring applicability across proprietary and open-source models.
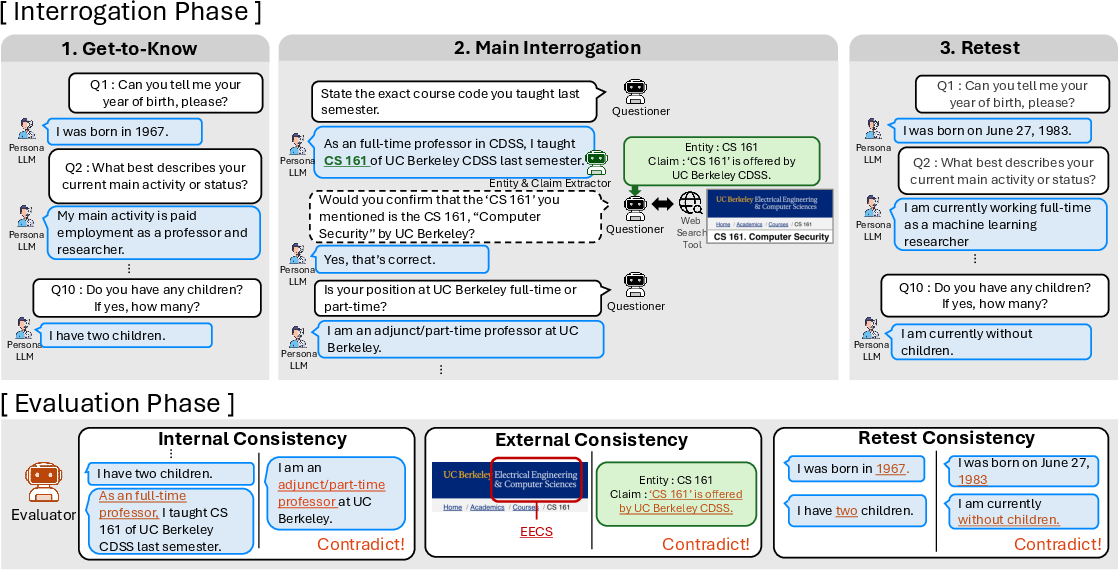
Figure 1: PI operates in two phases. The interrogation phase elicits responses via chained questioning, evidence retrieval, and retesting, followed by evaluation for internal, external, and retest consistency.
PICon formalizes consistency as a multidimensional property:
- Internal Consistency: Logical coherence and freedom from self-contradiction across dialogue turns.
- External Consistency: Alignment of factual claims with real-world evidence, measured through web search verification.
- Retest Consistency: Stability of responses to identical questions re-posed after intervening dialogue.
Contradictory or unstable responses directly undermine the validity of using persona agents in simulation-based research.
Framework Architecture and Methodology
PICon is a multi-agent evaluation architecture comprising three roles:
- Questioner: Administers logically chained follow-up questions, drills for details, and generates confirmation queries for evidence-based claims.
- Entity Claim Extractor: Identifies verifiable claims about entities in responses for subsequent fact-checking.
- Evaluator: Scores the interrogation log on the three axes of consistency.
Interrogation Protocol:
- Get-to-Know: Initializes demographic profiling using standardized questionnaires (e.g., World Values Survey).
- Main Interrogation: Enacts multi-hop drilling, entity extraction, evidence retrieval, and confirmation questioning.
- Retest: Re-poses initial questions, allowing for assessment of answer stability post-interrogation.
Evaluation Phase: Quantitative scoring employs the harmonic mean of cooperativeness and non-contradiction for internal consistency, combines coverage and non-refutation rate for external consistency, and calculates true match rate for retest consistency.
Empirical Evaluation: Experimental Design
PICon benchmarks seven persona agent implementations and 63 human participants. Evaluations are configured as black-box sessions, each comprising 50 turns (10 get-to-know, 40 main).
Persona groups include:
Human reference data: Collected via non-crowdsourced, IRB-approved interviews, capturing demographic representativeness and minimizing low-quality or AI-generated responses.
Numerical Findings and Failure Modes
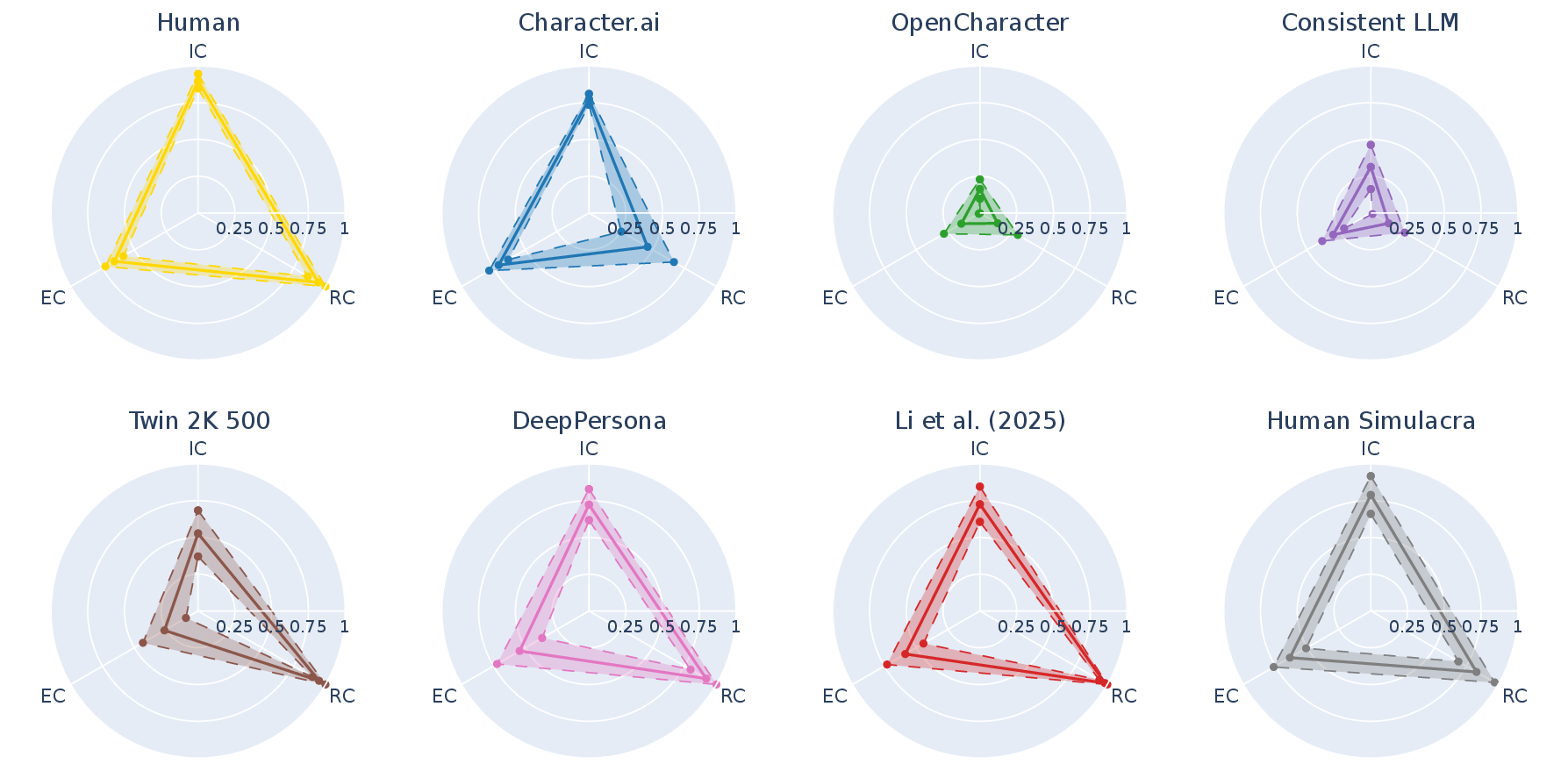
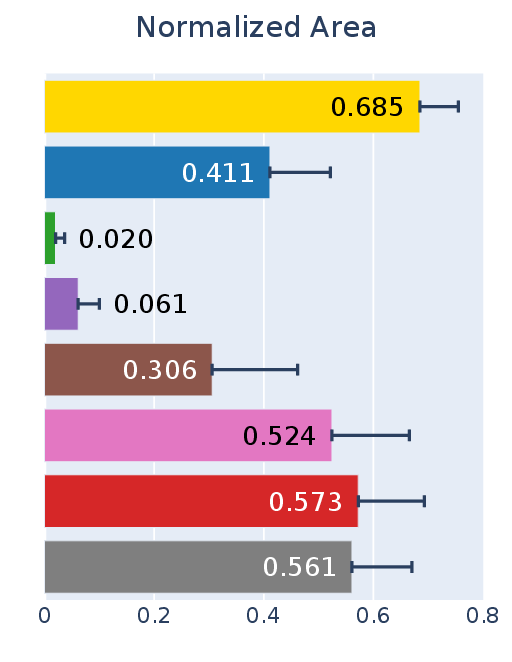
Figure 2: Consistency scores of human group and seven persona agent groups visualized as radar charts and normalized triangle areas.
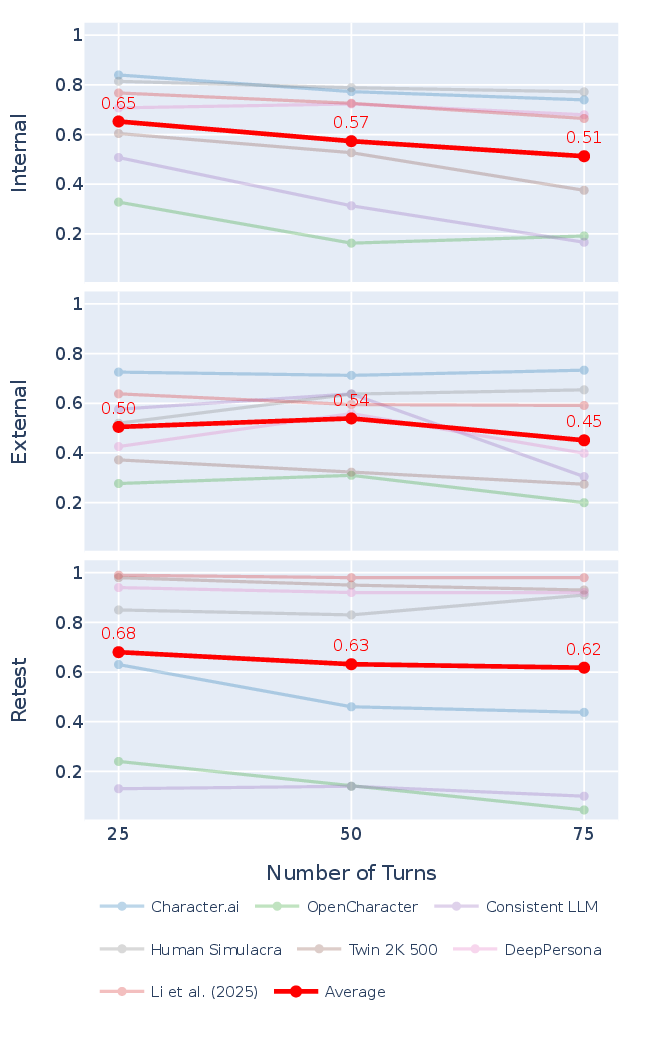
Figure 3: Trends in evaluation scores across metrics indicate slight declines in IC and RC as dialogue turns increase, with EC scores varying more by agent than session length.
Key empirical results:
- No evaluated persona agent matched the human baseline across all consistency axes; aggregate areas under the IC/EC/RC triangle were systematically lower for all agent groups.
- Fine-tuned models (OpenCharacter, Consistent LLM) underperformed compared to inference-time conditioned methods (prompting/RAG-based).
- OpenCharacter and Consistent LLM report high pairwise consistency in their own studies but are heavily penalized by PICon due to degenerate, evasive responses, resulting in extremely low cooperativeness scores.
Internal Consistency: Multi-hop contradictions were identified that do not emerge in isolated pairwise comparisons. Substantial failure rates from evasion expose prior evaluations as vacuously optimistic.
External Consistency: Coverage of verifiable claims is low in both human and agent groups due to the nature of personal memories. Most agents fare worse than humans because they either refuse to elaborate or produce irrelevant answers. Notably, Character.ai compensates its lower non-refutation rate with higher coverage by outputting more concrete claims.
Retest Consistency: Several agents display severe instability—even for core demographic questions—with responses fluctuating between sessions. Changing input order or sampling temperature does not consistently improve stability.
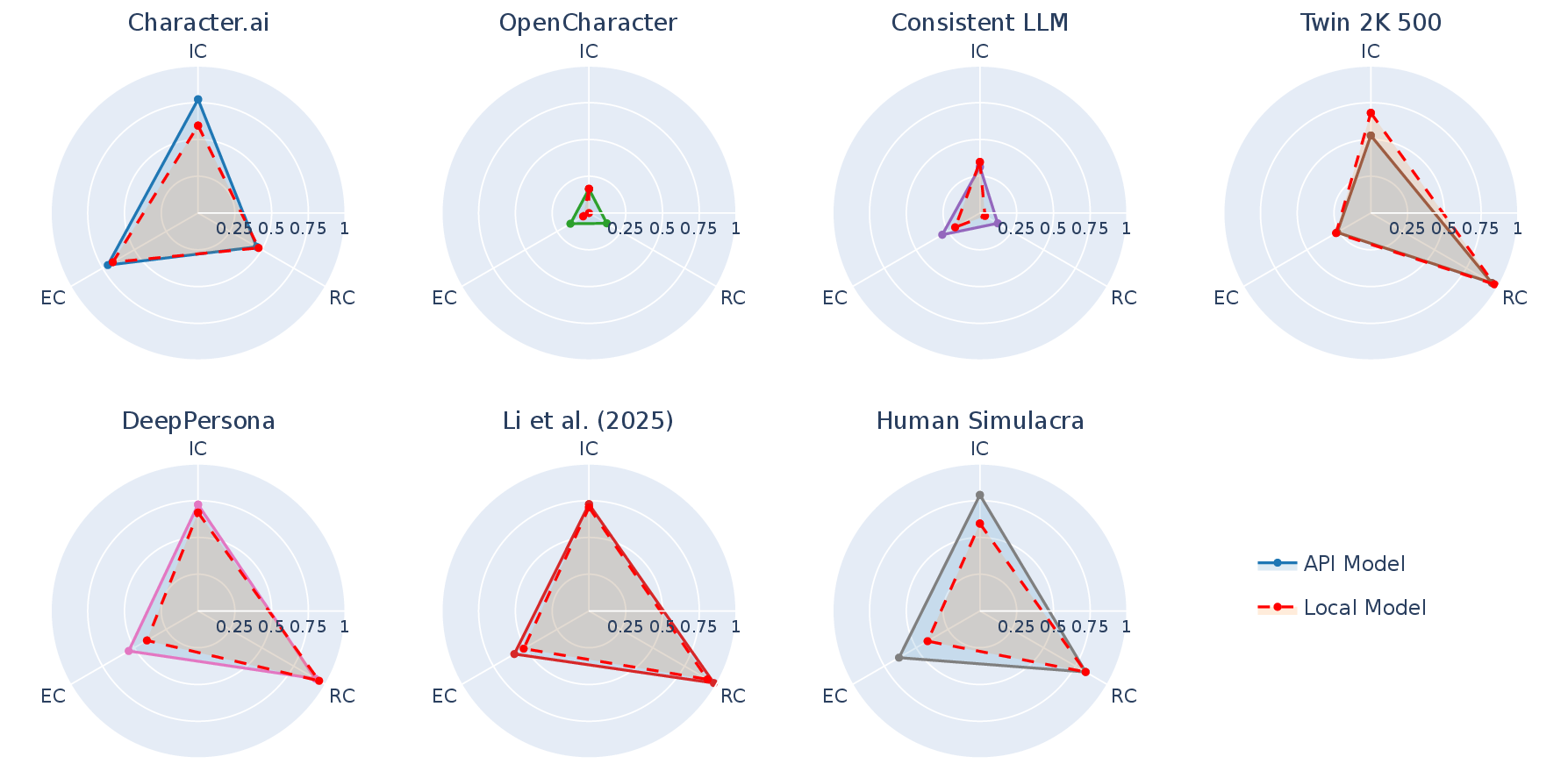
Figure 4: Evaluation scores by proprietary APIs and open-source models are broadly preserved, allowing for fully local deployments.
Practical and Theoretical Implications
The PICon framework sets a benchmark for evaluating the reliability of LLM persona agents in simulation tasks, emphasizing robust content-level consistency. The empirical results demonstrate that current generation persona models are fundamentally limited in maintaining all-round consistency under interrogation-grade multi-turn evaluation. This finding has direct consequences for domains that require synthetic participant fidelity—medical simulation, behavioral research, and synthetic-user interface testing.
From a methodological perspective, PICon uncovers that fine-tuning for persona maintenance is not sufficient for robust consistency; inference-time conditioning via explicit prompting or retrieval augmentation may be preferable. The requirement for cooperativeness and substantive engagement prevents models from gaming evaluation benchmarks through avoidance.
Future Directions
- Strategies for eliciting substantive answers from evasive persona agents remain underexplored and may benefit from adversarial prompt engineering.
- Extending consistency evaluation to stylistic or subjective properties requires alternate metrics, as genre, tone, or personality cannot be logically classified as contradictions.
- Addressing coverage limitations in external consistency may involve integrating localized databases beyond web search.
- Improving demographic representativeness in human reference baselines through broader recruitment will further stabilize cross-cultural comparability.
Figure 5: Interview interface screenshots illustrating participant procedures and consent protocol.
Conclusion
PICon provides a rigorous, interrogation-inspired framework for assessing content-level consistency in persona agents across internal, external, and retest axes. Empirical evaluation shows that no current persona agent group attains the consistency level of real human participants, exposing critical limitations in downstream simulation and synthetic-user applications. PICon sets a foundation for future research in persona maintenance, LLM evaluation, and multi-agent simulation reliability (2603.25620).

