The Rules-and-Facts Model for Simultaneous Generalization and Memorization in Neural Networks
Abstract: A key capability of modern neural networks is their capacity to simultaneously learn underlying rules and memorize specific facts or exceptions. Yet, theoretical understanding of this dual capability remains limited. We introduce the Rules-and-Facts (RAF) model, a minimal solvable setting that enables precise characterization of this phenomenon by bridging two classical lines of work in the statistical physics of learning: the teacher-student framework for generalization and Gardner-style capacity analysis for memorization. In the RAF model, a fraction $1 - \varepsilon$ of training labels is generated by a structured teacher rule, while a fraction $\varepsilon$ consists of unstructured facts with random labels. We characterize when the learner can simultaneously recover the underlying rule - allowing generalization to new data - and memorize the unstructured examples. Our results quantify how overparameterization enables the simultaneous realization of these two objectives: sufficient excess capacity supports memorization, while regularization and the choice of kernel or nonlinearity control the allocation of capacity between rule learning and memorization. The RAF model provides a theoretical foundation for understanding how modern neural networks can infer structure while storing rare or non-compressible information.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper asks a simple question with a big impact: How can one neural network both learn general rules (like grammar) and also remember specific facts (like “the capital of France is Paris”) at the same time? The authors build a clean, math-based model—called the Rules-and-Facts (RAF) model—to study when and how a learner can do both well.
The main goals and questions
The paper aims to:
- Create a simple setting where part of the training labels follow a rule and the rest are random facts that must be memorized.
- Measure two things at once: how well the model learns the rule (generalizes) and how well it recalls the random facts (memorizes).
- Understand how the size of the model, the choice of activation/kernel, and regularization affect the balance between learning rules and memorizing facts.
- Provide precise formulas that predict performance in large-scale, high-dimensional situations.
How the study works (in everyday terms)
Think of training data as a mixed bag:
- Most examples follow a hidden rule set by a “teacher.” For example, labels are determined by a simple rule based on a secret direction in space.
- A smaller fraction, controlled by a number (between 0 and 1), are pure facts: their labels are random and don’t follow any pattern. These must be memorized to be answered correctly later.
To analyze this, the authors look at three kinds of models:
- A linear model (a basic “straight-line” classifier).
- A random-features model (first map inputs through many random nonlinear knobs, then learn a linear mix of those; like adding many “lenses” before making a decision).
- A kernel method (a mathematical cousin of the random-features model that acts like the infinite-lens limit and is very powerful).
They train these models using standard losses (square loss and hinge loss, which is used in SVMs) and a regularization strength (which limits how much the model “wiggles,” keeping it from overfitting too much).
They study the “high-dimensional limit”: imagine having lots of features and examples, growing together. This lets them use tools from statistical physics to write simple equations that accurately predict performance. In plain terms, it’s like zooming out far enough that the big patterns become crisp and can be described with a few numbers.
Two performance measures are used:
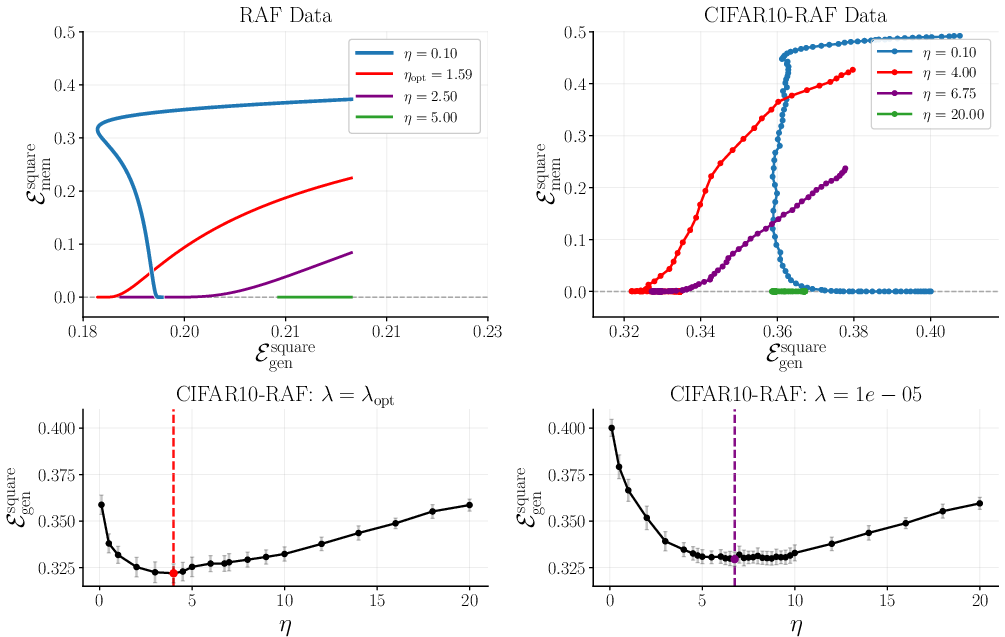
- Memorization error: among the fact examples, how often does the model fail to recall the exact label it saw during training?
- Generalization error: on new, unseen examples that follow the rule, how often is the model wrong?
What they find and why it matters
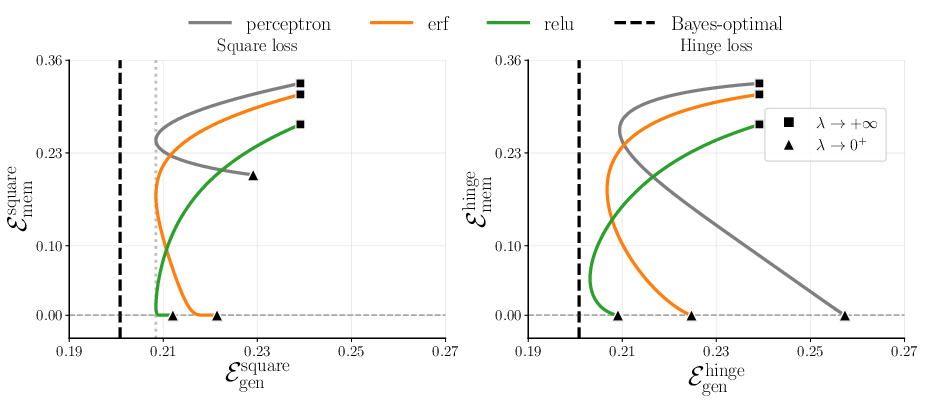
Big picture: With enough capacity (more parameters than you strictly need), a model can split its “brain space” into two parts—one part learns the rule, the other part stores the facts. This explains how modern neural networks can both generalize and memorize.
Key insights:
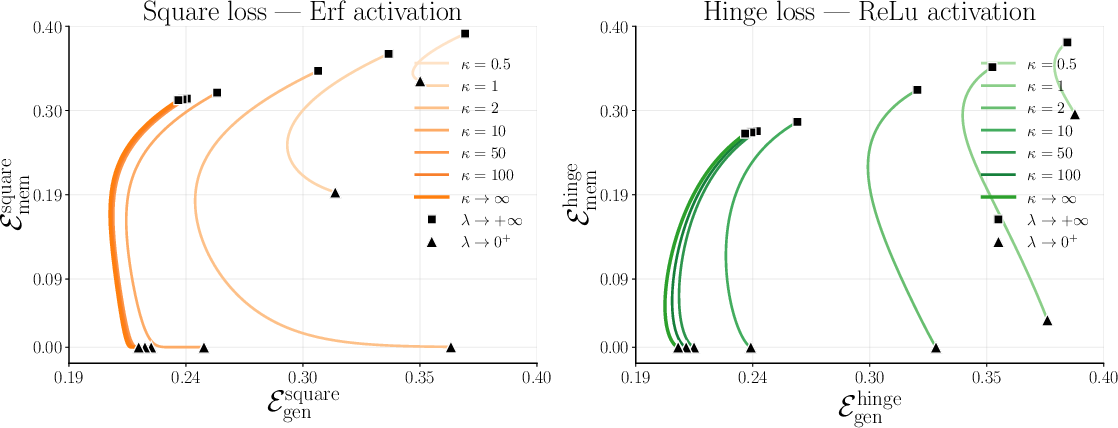
- Overparameterization helps. Having “excess capacity” gives the model room to keep the rule intact while also storing random facts.
- The kernel or activation choice matters. Two summary numbers, called and , capture how a model balances rule learning vs. fact memorization:
- reflects the part of the model aligned with the rule (the “linear” component). Bigger helps learn and apply the rule to new data.
- reflects the nonlinear parts that can absorb irregularities and exceptions. Bigger helps memorize facts.
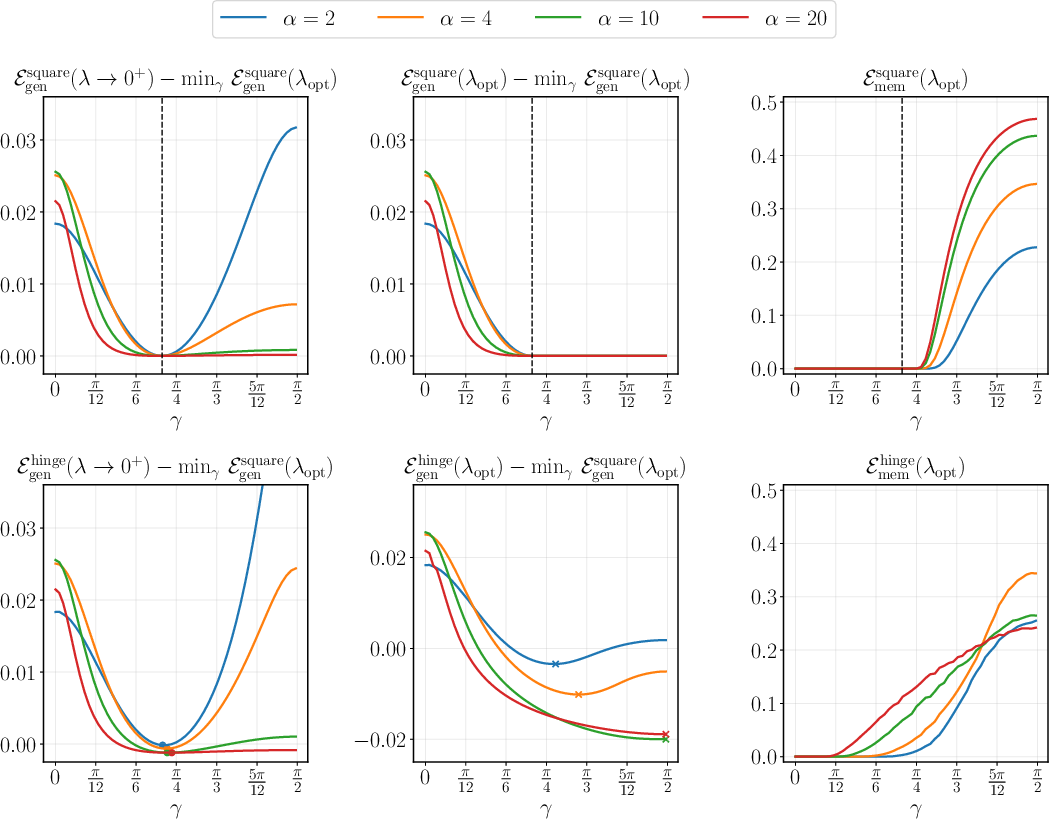
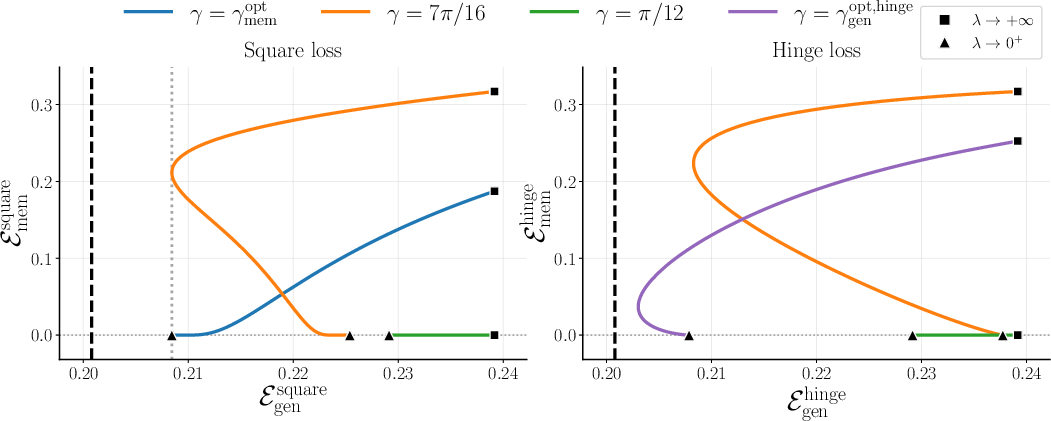
- Regularization () controls how the model allocates capacity. Stronger regularization tends to protect rule learning; weaker regularization can allow more memorization.
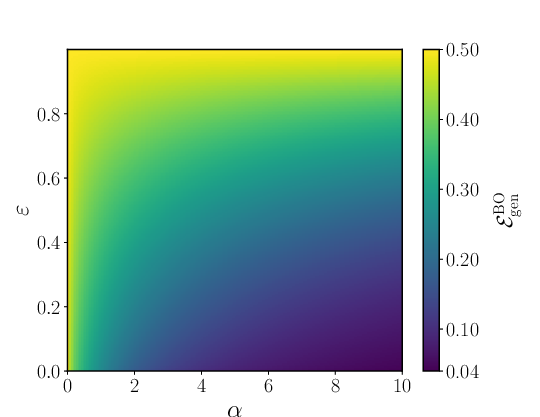
- The data mix matters. If (no facts), the problem reduces to classic rule learning. If (all facts), it reduces to pure memorization. The RAF model smoothly bridges these extremes.
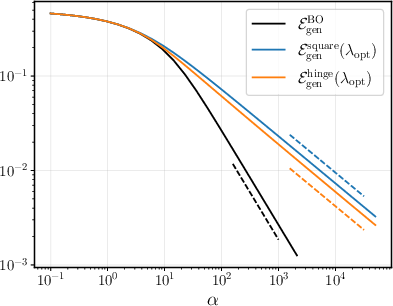
- There is a “best possible” benchmark (Bayes-optimal) for generalization. As you get more data, the ideal generalization error falls like 1/α (α is “samples per feature”), giving a clear target for how fast learning improves.
Why this is important:
- It gives a concrete, math-backed explanation for a key behavior seen in LLMs and other AI systems: they can both follow rules and recall specifics.
- It shows that memorization isn’t always a bug—it can be a necessary feature when some truths don’t follow general rules (like irregular verbs or unique facts).
- It offers guidance on how to design models and choose kernels/activations to get the balance you want.
What this research means going forward
- Theory and practice meet: This work provides a simple, solvable model that captures a real-world need—do both reasoning (generalization) and remembering (memorization).
- Design choices matter: By tuning model size, regularization, and the activation/kernel (i.e., shaping and ), practitioners can more deliberately trade off between learning rules and storing facts.
- Better understanding of “hallucinations”: Knowing how models split capacity helps explain when a model might sound convincing but get facts wrong—and how to reduce that by adjusting capacity and regularization.
- A foundation for future work: The RAF model can be extended to more complex settings, helping researchers understand and control the behavior of ever-larger neural networks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces an analytically tractable RAF model and derives high‑dimensional asymptotics for linear models, random features, and kernel methods. The following concrete gaps and open questions remain:
Modeling assumptions and scope
- Extend beyond isotropic Gaussian inputs: quantify how non-Gaussian, anisotropic, or manifold-structured inputs (e.g., clustered, heavy-tailed, covariate shift) affect the simultaneous generalization–memorization trade-off and whether the μ₁/μ⋆ decomposition still suffices.
- Move beyond a linear sign teacher: analyze nonlinear teachers, margin distributions, and misspecified rules to assess robustness of results when the rule is not linearly separable or only approximately linear.
- Generalize outputs: study multiclass classification and regression variants of RAF (e.g., real-valued facts/rules, sequence prediction), including how “facts” should be defined and evaluated in those settings.
- Relax the “isolated random facts” assumption: model exceptions with partial structure, local neighborhoods, or correlations (e.g., clusters of rare patterns) and quantify how partial compressibility alters capacity allocation.
- Incorporate noise on rule-labeled examples: distinguish memorization of true exceptions from robustness to label noise or adversarial corruptions mixed into the “rules” portion.
- Account for repeated or near-duplicate facts: assess how multiple occurrences or near-neighbors of factual examples change memorization metrics and capacity thresholds.
- Consider nonuniform or input‑dependent fact rates: let ε depend on x or vary across subpopulations and analyze implications for allocation and fairness.
Learners, training, and capacity allocation
- Go beyond random features and kernel limits to learned features: analyze deep, finite-width networks where representation learning occurs and test whether a comparable rule–fact decomposition emerges.
- Finite-width random features: provide explicit finite‑κ theory (beyond the kernel limit κ→∞), including double-descent behavior and sharp memorization thresholds as κ varies.
- Training dynamics and implicit bias: characterize gradient descent trajectories (square, logistic, hinge losses) and the role of implicit regularization in allocating capacity between rules and facts.
- Loss functions beyond square/hinge: extend to cross‑entropy/logistic losses and nonconvex surrogates; determine whether proximal-operator-based formulas and μ₁/μ⋆ sufficiency persist.
- Explicit design of kernels/activations for desired allocation: provide constructive procedures to target a specific μ₁:μ⋆ ratio and map these to practical activation choices and architectural knobs in deep nets.
- Regularization guidelines: derive explicit prescriptions for λ (and other hyperparameters) that optimize joint performance given (α, ε, μ₁, μ⋆), including phase diagrams and operating regions.
Theory and guarantees
- Rigorous justification: replace or complement replica-based results with provable high-probability bounds or asymptotically exact characterizations for RAF (e.g., via Gordon’s inequalities, convex Gaussian min–max theory).
- Sharp phase transitions: identify critical thresholds (in α, κ, λ, μ⋆, ε) for feasibility of simultaneous perfect factual recall and nontrivial generalization; characterize scaling windows and critical exponents.
- Beyond μ₁ and μ⋆: determine conditions under which higher-order kernel coefficients influence asymptotics (e.g., non-spherical inputs, different test distributions), and quantify any residual dependence.
- Finite-sample corrections: provide rates of convergence and finite‑n,d error bars; identify regimes where self-averaging breaks down or fluctuations are large.
- Robustness and adversarial aspects: analyze how exceptions that are worst-case/adversarially chosen impact the trade-off and whether regularization can mitigate vulnerability without sacrificing recall.
Evaluation and metrics
- Memorization definition: extend factual recall beyond exact input re‑presentation to near-neighbor recall, paraphrase/equivariance tests, and retrieval under small distribution shifts.
- Joint performance metrics: propose composite objectives or Pareto frontiers quantifying trade-offs between rule generalization and factual recall; identify optimal operating points.
- Test-time composition: model and evaluate scenarios where test points may also include facts (not just rule-labeled samples), including abstention options and calibrated uncertainty.
Practical relevance and empirical validation
- Empirical tests: validate the μ₁/μ⋆ predictions and capacity allocation claims on synthetic and real datasets, and in modern architectures (e.g., CNNs, transformers) to assess external validity.
- Connection to LLM behavior: instantiate RAF-inspired probes for LLMs (e.g., memorization of rare facts vs syntactic generalization) and relate observed behavior to kernel/activation proxies.
- Privacy and unlearning: quantify the cost of differential privacy or machine-unlearning constraints on factual recall vs rule generalization within the RAF framework.
Identifiability and interpretability
- Detecting facts vs rules: develop estimators or diagnostics that infer which training points are likely facts (exceptions) vs rule-consistent, and assess how such detection affects learning and capacity allocation.
- Interpretable capacity partitioning: design and test mechanisms (architectural or regularization-based) that explicitly partition capacity into “rule” and “fact” subspaces, with controllable interference.
Practical Applications
Overview
This paper introduces the Rules-and-Facts (RAF) model: a solvable statistical framework that quantifies when and how a learner can simultaneously (i) generalize an underlying rule and (ii) memorize unstructured exceptions (“facts”). It analyzes linear models, random features, and kernel regression with convex losses in the high-dimensional limit, yielding closed-form characterizations of both generalization and memorization errors. A core insight is that model capacity can be decomposed: components aligned with the rule (controlled by the kernel/activation’s linear component, parameterized by μ₁) and components that support memorization of exceptions (controlled by higher-order, nonlinear components, parameterized by μ⋆). Overparameterization and regularization (λ) govern how capacity is allocated between these two objectives.
Below are practical applications derived from these findings, organized by time horizon. Each item notes sectors, concrete tools/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
These can be piloted with current tooling (kernel methods, random features, SVM/KRR, modern deep models with regularization and width controls).
- Balanced capacity tuning for “rules vs. facts”
- Sectors: Software/ML, healthcare, finance, recommendation systems, compliance tools
- What: Use the RAF prescriptions to set regularization (λ), overparameterization (width/feature count κ), and kernel/activation choices (via μ₁ for rule learning, μ⋆ for memorization) to reach target levels of factual recall without sacrificing generalization.
- Tools/workflows:
- Hyperparameter playbooks that map desired memorization error and generalization error to (λ, κ) ranges.
- Kernel/activation catalogs annotated with (μ₁, μ⋆) (e.g., erf, sign, ReLU, quadratic kernels) to pick architectures that match task needs.
- Training dashboards that track factual-recall vs. rule-generalization metrics during model development.
- Assumptions/dependencies: RAF assumes Gaussian inputs, linear teacher rule, binary labels, and convex losses; real data violate these, so metrics should be used as guidance rather than guarantees.
- Model auditing and risk assessment for unwanted memorization
- Sectors: Policy/compliance, healthcare, finance, privacy engineering
- What: Use RAF to estimate and bound the likelihood of memorizing sensitive items as a function of overparameterization and regularization; pick settings that minimize memorization while preserving rule performance.
- Tools/workflows:
- Privacy risk scorers: “effective ε” estimators from observed behavior (how many apparent facts can be fit).
- λ-sweeps to quantify memorization sensitivity; default “safe λ” recommendations for regulated deployments.
- Assumptions/dependencies: The proxy between RAF memorization error and real-world data leakage risk is approximate; requires complementary privacy techniques (e.g., DP, audits).
- Training-time strategy for rare exceptions
- Sectors: Healthcare diagnostics (rare adverse events), code intelligence (language exceptions), education (irregular verbs), customer support (edge cases)
- What: When a task mixes rules with true exceptions, deliberately allocate some capacity to memorize rare cases while preserving rule alignment.
- Tools/workflows:
- Exception-tagged curricula or upweighted examples; capacity allocation via adapter width or feature count.
- Choice of kernels/activations with non-zero μ⋆ to ensure memorization headroom.
- Assumptions/dependencies: Requires at least approximate identification of exception-like data or acceptance that some fraction is inherently non-generalizable.
- Retrieval vs. parametric memory decisioning
- Sectors: LLM/RAG systems, enterprise search, customer support bots
- What: Use RAF to set thresholds for when to store facts in weights (parametric) versus rely on retrieval (non-parametric). High ε (many exceptions) ⇒ favor retrieval; lower ε and sufficient capacity ⇒ parametric storage viable.
- Tools/workflows:
- Routing policies: confidence or “exceptionality” signals determine retrieval calls.
- Capacity monitors that track memorization headroom to avoid overfitting facts at the cost of rules.
- Assumptions/dependencies: Requires pipelines to estimate ε-like metrics and to measure factual recall separately from rule accuracy.
- Kernel and activation selection guidelines
- Sectors: Classical ML users (SVM/KRR), embedded ML
- What: Choose kernels/activations that match the target balance; e.g., larger μ₁ for strong rule learning, non-negligible μ⋆ for memorization.
- Tools/workflows:
- Use known μ₁, μ⋆ for common kernels (erf, sign, ReLU) to select defaults.
- Quick RAF simulators to preview expected trade-offs under given α (samples per dimension), ε, and λ.
- Assumptions/dependencies: Dot-product kernels and random features at large width best match the theory; deep, nonconvex networks may deviate.
- Benchmarking and pedagogy for simultaneous generalization and memorization
- Sectors: Academia, ML education, model evaluation teams
- What: Introduce RAF-style mixed datasets to test models’ ability to do both, rather than treating memorization as mere noise.
- Tools/workflows:
- Public synthetic benchmarks with tunable ε and α.
- Teaching modules and labs demonstrating μ₁/μ⋆ capacity allocation and double-descent behavior.
- Assumptions/dependencies: Synthetic tasks; need care in translating gains to complex domains (vision, language).
- MLOps controls for capacity allocation
- Sectors: ML platforms, AIOps
- What: Operational knobs that steer capacity between rule alignment and fact storage, guided by RAF metrics.
- Tools/workflows:
- Automated λ scheduling; width (κ) gating (e.g., LoRA rank, number of experts/features).
- Dual-metric acceptance tests: must pass both “factual recall” and “rule generalization” gates before deploy.
- Assumptions/dependencies: Requires defining and maintaining two separate evaluation tracks; may increase training/validation cost.
- Product-level reliability improvements for assistants
- Sectors: Consumer AI, productivity tools
- What: Configure small fine-tunes/adapters to memorize a limited set of user-specific facts (contacts, preferences) while preserving broad generalization.
- Tools/workflows:
- On-device adapters with constrained capacity; λ tuned to avoid overfitting beyond intended facts.
- User controls to opt-in/out and purge memorized data (“machine unlearning” hooks).
- Assumptions/dependencies: Privacy consent and safe unlearning; constraints on on-device memory and compute.
Long-Term Applications
These require further research, scaling, or development (e.g., non-Gaussian data, sequence tasks, nonconvex training dynamics, multi-task settings).
- Architectures with explicit “rule” and “fact” subspaces
- Sectors: Foundation models, robotics, autonomy
- What: Design networks that structurally separate μ₁-like (rule-aligned) and μ⋆-like (memorization) components, with learned gates to allocate capacity dynamically.
- Tools/products:
- Dual-stream encoders; orthogonality-regularized subspaces; mixture-of-experts with rule/fact experts.
- Meta-learning to adapt μ₁/μ⋆ over domains and time.
- Dependencies: New training objectives to stabilize subspace separation; interpretability to validate allocation.
- Data governance and privacy policies grounded in capacity–memorization theory
- Sectors: Policy, healthcare, finance, legal tech
- What: Translate RAF insights into policies that cap memorization risk (via capacity/regularization controls) and mandate dual-metric evaluation.
- Tools/products:
- Model-card standards including “memorization capacity” disclosures and RAF-style risk scores.
- Regulatory guidance tying deployment approvals to demonstrable control of memorization vs. generalization.
- Dependencies: Validation on non-synthetic, real-world modalities; alignment with DP and audit frameworks.
- Hallucination mitigation via adaptive memory routing
- Sectors: LLMs, RAG, enterprise assistants
- What: Use RAF-inspired confidence/routing: if inputs fall outside rule-aligned subspace or capacity is saturated, defer to retrieval or trusted KBs.
- Tools/workflows:
- Subspace-projection diagnostics to detect “rule-mismatch” queries.
- Training losses that penalize misuse of the memorization subspace for generative content where retrieval is preferable.
- Dependencies: Reliable estimators of rule vs. fact load in non-linear, seq2seq models; calibration research.
- Domain-specific systems that must remember rare exceptions safely
- Sectors: Healthcare (rare diseases, contraindications), autonomous driving (edge-case hazards), cybersecurity (zero-day signatures)
- What: Build models that generalize typical patterns but deliberately memorize vetted rare exceptions with audit trails.
- Tools/products:
- Exception registries and pipelines that promote approved exceptions into parametric memory.
- Safety cases showing that rule performance is maintained (μ₁) while exception recall exceeds thresholds.
- Dependencies: High-quality exception curation; change management as exceptions evolve.
- Kernel/activation learning to target desired μ₁/μ⋆ profiles
- Sectors: AutoML, meta-learning
- What: Learn activation functions or kernels that optimize a task-specific balance of rule-generalization and exception-memorization.
- Tools/products:
- Differentiable kernel design; activation search constrained by stability and capacity allocation targets.
- Dependencies: Efficient surrogates for RAF metrics in deep, nonconvex regimes; generalization guarantees.
- Detecting and separating “facts” vs. “rules” in data
- Sectors: Data engineering, active learning
- What: Algorithms that identify likely non-generalizable examples during training and allocate capacity or retrieval accordingly.
- Tools/products:
- Outlier/atypicality detectors with RAF-inspired thresholds; active labeling workflows that verify exceptions.
- Dependencies: Robustness to spurious correlations; avoiding bias against minority but generalizable patterns.
- Scaling laws and curriculum design for mixed tasks
- Sectors: Foundation model training, education tech
- What: Use RAF-like analyses to plan data composition (ε), sample complexity (α), and curricula to achieve target joint performance.
- Tools/products:
- Planners that forecast generalization/memorization trajectories as a function of data mixture and capacity.
- Dependencies: Extending beyond binary classification and Gaussian inputs to multimodal, sequential data.
- Documentation and certification of “simultaneous competence”
- Sectors: Standards bodies, certification labs
- What: Formal test suites and certifications that a model can both generalize and memorize where necessary, with transparent trade-offs.
- Tools/products:
- RAF-derived conformance tests; badges for “balanced memorization-generalization” with quantified error bounds.
- Dependencies: Community consensus on metrics; mapping to application-specific risk thresholds.
Key Assumptions and Dependencies (Cross-Cutting)
- Data/model idealizations: Gaussian inputs, linear teacher rule, binary labels, convex losses, dot-product kernels, and high-dimensional limits (n, d, p → ∞ with α, κ fixed). Real-world tasks (text, images, multi-class/seq2seq) violate these.
- Architecture gap: Results are exact for kernel/random-features limits; deep, nonconvex networks may only qualitatively follow RAF behavior.
- Label mixture: RAF treats “facts” as unstructured, random labels. In practice, exceptions may have weak structure; identification may need domain input.
- Self-averaging: Predictions rely on concentration in high dimensions; small-data regimes may deviate.
- Safety/privacy: Reducing memorization via capacity/regularization should be combined with DP, auditing, and unlearning for sensitive data.
By treating memorization as a first-class objective alongside generalization, the RAF model provides deployable guidance for capacity tuning, evaluation, and governance today, and a roadmap for architectures and policies that explicitly control how models learn rules while storing necessary exceptions.
Glossary
- Bayes-optimal classifier: The classifier that achieves the lowest possible error given the data-generating assumptions and prior. "The Bayes-optimal classifier, which minimizes the error defined in Eq.~\eqref{eq: generalization error}, predicts the label that maximizes the posterior predictive probability, namely"
- Bayes-optimal generalization error: The expected misclassification rate of the Bayes-optimal classifier on new data. "The Bayes-optimal generalization error is then"
- Bayes-optimal overlap: A scalar measuring alignment between the learned weights and the ground-truth teacher weights in the Bayes-optimal setting. "The order parameter is referred to as the Bayes-optimal overlap with the ground truth weights"
- Denoising function (output channel): A loss-dependent function derived from the proximal operator that characterizes effective denoising under the output channel. "The function is commonly referred to as the output channel denoising function"
- Double-descent phenomenon: A behavior where test error initially increases near interpolation and then decreases again as model capacity grows. "This insight is closely linked to the now broadly studied double-descent phenomenon"
- Dot-product kernel: A kernel that depends only on the inner product between inputs. "the kernel associated with the Gaussian random features learner in Eq.~\eqref{eq:kernel-reg} is a dot-product kernel, namely"
- Empirical risk minimizer (ERM): The unique minimizer of the empirical risk (loss plus regularization) over model parameters. "admits a unique minimizer, which we refer to as the empirical risk minimizer (ERM), and denote by"
- Gardner-style capacity analysis: A statistical physics approach quantifying the ability of models (e.g., perceptrons) to memorize arbitrary labels. "Gardner-style capacity analysis for memorization"
- Gaussian prior: A prior distribution over parameters assuming they are normally distributed. "a Gaussian prior on the teacher weights"
- Heaviside step function: A unit step function that is zero for negative inputs and one for nonnegative inputs. "where is the Heaviside step function."
- Hermite expansion: Representation of functions of Gaussian variables using orthogonal Hermite polynomials; used to analyze kernels/activations. "admit an interpretation in terms of the Hermite expansion of the activation "
- Hinge loss: A convex loss used for margin-based classification that penalizes predictions inside the margin or misclassifications. "kernel classification with hinge loss is called {\bf support vector machine} (SVM)"
- Interpolation threshold: The point at which a model has enough capacity to fit the training data perfectly (interpolate). "beyond the so-called interpolation threshold"
- Kernel regression: A method that expresses the predictor as a weighted sum of kernel evaluations between inputs. "Kernel regression."
- Kernel ridge regression (KRR): Kernel regression with squared loss and L2 regularization. "kernel regression with square loss is often referred to as {\bf kernel ridge regression} (KRR)"
- Memorization error: The average fraction of randomly labeled (fact) training examples misclassified by the learned model. "The memorization error is thereafter defined as the average fraction of fact-labels in the dataset that are misclassified by"
- Order parameter: A macroscopic scalar quantity summarizing the state/performance of the learning system (e.g., overlaps). "The order parameters and admit a clear interpretation in terms of the weights $\hat{\boldsymbol{w}$ solving the ERM problem"
- Overparameterization ratio: The ratio of model width to input dimension characterizing how overparameterized the model is. " plays the role of the overparameterization ratio of the random feature architecture in Eq.~\eqref{eq:random-features}."
- Output channel: The probabilistic mechanism mapping latent variables to observed labels in the generative model. "the mixed ``rules-and-facts'' output channel"
- Posterior predictive distribution: The distribution of a new label given the new input and the observed data, integrating over the posterior. "the posterior predictive distribution of the corresponding teacher label is"
- Proximal operator: The mapping that returns the minimizer of a function plus a quadratic penalty, used in regularized optimization. "denotes the loss-dependent proximal operator:"
- Rademacher‑complexity bounds: Generalization guarantees based on the ability of a hypothesis class to fit random labels. "The classical Rademacher‑complexity bounds formalize this view"
- Random features regression: A linear model trained on nonlinearly transformed inputs via a fixed random feature map. "Random feature regression where"
- Replica method: A statistical physics technique to analyze averages in high-dimensional disordered systems, used to derive asymptotic equations. "using the replica method"
- Sample complexity: The number of samples per dimension (or in general) required to learn reliably. "The parameter is commonly referred to as the sample complexity of the problem"
- Self-averaging: The property that random quantities converge to deterministic limits in high dimension. "the quantities of interest are self-averaging in the high-dimensional limit"
- Support vector machine (SVM): A max-margin kernel-based classifier typically trained with hinge loss. "kernel classification with hinge loss is called {\bf support vector machine} (SVM)"
- Teacher–student model: A framework where data is generated by a teacher and learned by a student, used to analyze generalization. "the teacher--student model, which describes the inference of structured rules"
Collections
Sign up for free to add this paper to one or more collections.