- The paper introduces the sequence multi-index model, unifying MLPs, autoencoders, and attention mechanisms under a single framework for narrow neural networks.
- It applies statistical physics techniques, including the replica method and GAMP, to derive self-consistent equations for generalization errors and learning dynamics.
- Analytical predictions are validated through numerical experiments, revealing sharp phase transitions and practical insights into optimization and model behavior.
High-Dimensional Learning of Narrow Neural Networks: A Statistical Physics Perspective
Introduction and Motivation
The paper "High-dimensional learning of narrow neural networks" (2409.13904) provides a comprehensive review and unification of recent advances in the statistical physics analysis of neural networks with a finite (narrow) number of hidden units operating in high-dimensional regimes. The central focus is the asymptotic learning dynamics when both data dimension (d) and the number of samples (n) are large, and the network width (r) scales as r=Θd(1), i.e., remains fixed or grows slowly with d. This work consolidates previously disparate models—multi-layer perceptrons (MLPs), autoencoders (AEs), and attention mechanisms—under a single, flexible architecture called the sequence multi-index model, analyzed in the proportional scaling limit.
By leveraging statistical physics techniques, particularly the replica method and generalized approximate message passing (GAMP), the review elucidates self-consistent equations for key learning metrics (generalization error, training loss) while clarifying the connections to the algorithmic fixed points of GAMP and optimization critical points. This exposition positions the sequence multi-index model as a meta-framework subsuming a broad class of solvable high-dimensional neural learning problems.
Theoretical Model Landscape and Unified Framework
Contemporary asymptotic learning theory for neural networks distinguishes itself by the variety of high-dimensional scaling regimes, particularly in the width (r) of the network relative to the input dimension (d). The paper reviews four major asymptotic regimes—single hidden unit, finite-width, infinite-width, and extensive-width—each producing distinct phenomenology, especially regarding generalization, phase transitions, and transitions to kernel-like or linear models.
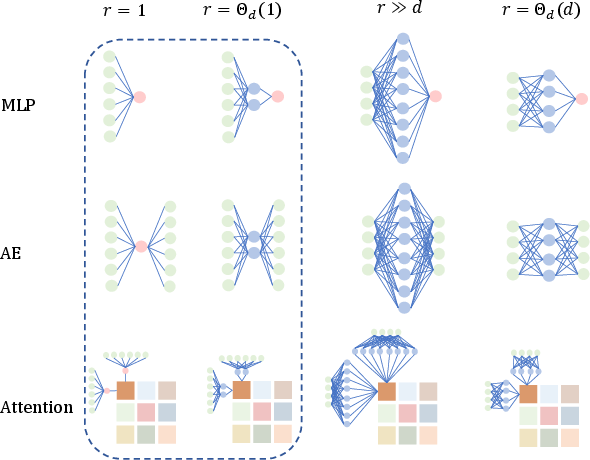
Figure 1: Visualization of network models and corresponding asymptotic regimes, highlighting the unifying focus on architectures with r=Θd(1) narrow hidden layers across MLPs, AEs, and attention mechanisms.
The principal contribution is the introduction of the sequence multi-index model, which acts as a universal generator for a broad array of neural network architectures and learning scenarios. This generic model subsumes not only MLPs, AEs, and transformer-like attention mechanisms but also kernel machines, random feature models, and even contrastive and siamese networks. It assesses learning from sequential, potentially structured data via a general empirical risk minimization (ERM) formulation.
The data generating process encompasses Gaussian mixture models with correlated cluster assignments, modeling a range of practical contexts (natural language, images, etc.) with flexibility to incorporate heavy-tail or hierarchical structure. The high-dimensional asymptotic limit is set by d,n→∞ with a fixed ratio α=n/d (sample complexity), and the analysis admits jointly diagonalizable covariance structures for analytical tractability.
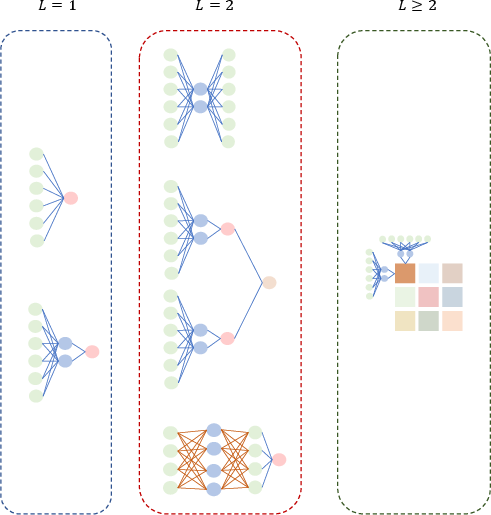
Figure 2: Graphical taxonomy of notable instantiations of the sequence multi-index model, encompassing GLMs, AEs, random features, attention, and siamese networks, unified through changes in the sequence dimension L.
Statistical Physics Methods: Replica and Approximate Message Passing
A substantial part of the work is grounded in statistical mechanics techniques, most notably the replica method, which enables characterization of the high-dimensional learning curves down to constants. The approach is typical-case and model-driven, focusing on the statistical properties of typical datasets rather than distribution-free (PAC-type) worst-case analyses, which have been shown to be qualitatively insufficient for capturing phenomena such as sharp generalization phase transitions.
For the sequence multi-index model, the analysis derives a closed set of self-consistent saddle-point (SP) equations for a low-dimensional set of order parameters: overlaps, mean projections, and cross-covariances of weights and features. These parameters succinctly encode the macroscopic learning dynamics (generalization, training error, phase transitions) across all incorporated architectures.
Importantly, the paper reveals that these SP equations are precisely the fixed points of high-dimensional GAMP message passing algorithms applied to the graphical model associated with the ERM objective.
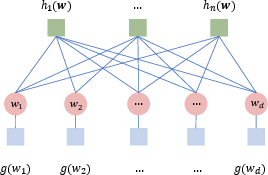
Figure 3: Graphical model representation of the probabilistic measure underlying the sequence multi-index model, facilitating the development of message-passing-based inference algorithms such as GAMP.
Moreover, the fixed points of GAMP are shown to correspond to stationary points of the empirical loss landscape; thus, the analysis not only captures optimal solutions but also provides insight into the role and prevalence of sub-optimal (local minima, saddle) solutions in high-dimensional optimization.
Phenomenological and Numerical Insights
The theoretical framework supports a broad spectrum of previously studied models and yields sharp analytic predictions confirmed by numerical optimization (e.g., stochastic gradient-based training in PyTorch). The method captures not only smooth generalization phenomena but also sharp phase transitions (e.g., abrupt transitions between learning regimes, posterior collapse phenomena in AEs and VAEs, or the emergence of semantic attention in transformer models).
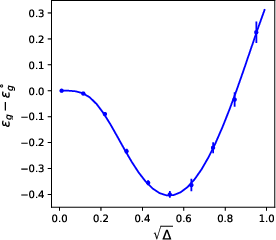
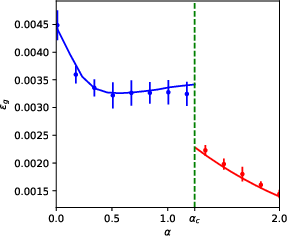
Figure 4: Examples of analytical and empirical learning curves for denoising autoencoders and single-layer attention mechanisms, revealing excellent correspondence for large d and illustrating phase-transition behaviors.
Key findings across models:
- GLMs and Regularization: For single-layer networks and properly tuned regularization (logistic, cross-entropy losses), ERM solutions attain generalization error approaching the Bayes-optimal value in balanced Gaussian mixtures. For K-class mixtures, maximal regularization (λ→∞) emerges as optimal under certain conditions.
- Autoencoders: Untangling components of DAEs reveals linear features (e.g., PCA) when isolated, but cooperative non-linear behaviors and statistically improved denoising emerge only in the joint model, reflecting a strong architectural interaction.
- Attention Mechanisms: A single-layer attention model exhibits a first-order phase transition from purely positional to semantic learning at a precise αc, accompanied by a sharp drop in test error, signaling the emergence of functionally distinct mechanisms within the same architecture.
Data Structure, Universality, and Practical Relevance
The sequence multi-index model admirably hosts a range of structured data models, from isotropic Gaussians to correlated Gaussian mixtures and even real-world data via surrogate parametrizations. The work clarifies the notion of data universality classes, particularly Gaussian universality, allowing real data learning curves to be matched by analytical predictions calibrated only on empirical covariances and means.
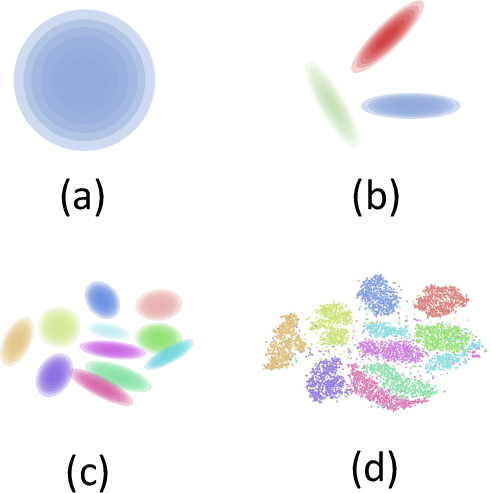
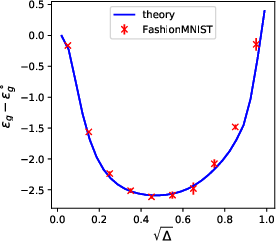
Figure 5: Comparison between stylized theoretical data models (Gaussian, mixtures) and real-world structured data (e.g., tSNE embeddings of MNIST), demonstrating that appropriately chosen surrogate statistics yield excellent agreement in learning curve predictions.
Nevertheless, the authors stress limitations: real data may possess structure beyond that captured by means and covariances, and for certain tasks or deep models, universality may break down. There remains an open challenge to enumerate principled universality criteria for arbitrary architectures/tasks and to systematically identify relevant statistics for theoretical proxy datasets.
Broader Implications and Open Directions
Theoretical
- The connection between statistical mechanics analysis (replica, cavity, message passing) and the fixed-points of modern algorithms strengthens the case for these methods as baseline tools for the typical-case theory of neural learning in high dimensions.
- The sequence multi-index framework is poised to facilitate ongoing progress in analyzing broader architectures (extensive-width, hybrid, deep, or convolutional networks) and learning algorithms (dynamics, online SGD, transfer, meta-learning).
- The identification of phase transitions and the enumeration of multiple critical points in the ERM landscape has profound implications for understanding the geometry and optimization of high-dimensional losses.
Practical
- By enabling sharp, interpretable predictions for the generalization and train/test error of practical high-dimensional networks, this line of work holds significant promise for guiding architecture/hyperparameter selection, benchmarking, and error prediction before training.
- Quantitative alignment of theoretical and empirical learning curves on real-world data implies potential for model selection and data analysis tasks (e.g., scalable estimation of data complexity and effective dimension) in applied machine learning.
Future Developments
- Extension to extensive-width (r=Θ(d)) or even deep/wide limits is an active area but presents significant technical challenges, particularly for finite-sample non-Bayesian scenarios and architectures that go beyond fully-connected models.
- Fully characterizing the universality classes for data and loss functions, especially in non-Gaussian, non-linear, or non-i.i.d scenarios, remains open.
- Systematic study of learning dynamics (as opposed to static generalization) within this framework, especially in multi-epoch or stochastic regimes, will be increasingly relevant for large-scale practical systems.
Conclusion
This work establishes the sequence multi-index model as a powerful, unifying approach for analyzing narrow neural networks in high dimensions using statistical physics. Through a mixture of rigorous asymptotic analysis, algorithmic connection via GAMP, and empirical validation, the framework provides deep insight into how architecture, data structure, and optimization interact to shape the learning curves and phase behavior of neural networks. It also highlights the open challenges in extending these methods, especially regarding richly structured data, broadening to wide/deep regimes, and understanding non-equilibrium learning dynamics. The paper serves as a definitive reference for machine learning theorists and statistical physicists engaged in high-dimensional learning theory and anticipates further interdisciplinary developments built upon this analytical foundation.

