- The paper introduces Voxtral Mini and Voxtral Small as open-weight multimodal language models that process both speech and text, achieving state-of-the-art performance in transcription, translation, and QA tasks.
- The paper employs a three-phase training approach—pretraining with audio-to-text repetition, supervised finetuning with synthetic Q&A, and direct preference optimization—to enhance speech comprehension and response quality.
- The paper integrates a Whisper-based audio encoder, MLP adapter, and transformer decoder to efficiently handle up to 40 minutes of audio within a 32K token context, enabling robust long-format conversations.
Voxtral: Multimodal Audio Chat Models
This paper introduces Voxtral Mini and Voxtral Small, two open-weight multimodal LLMs engineered to process and understand both spoken audio and textual data (2507.13264). These models achieve state-of-the-art performance across a range of audio benchmarks while maintaining robust text capabilities. With a 32K token context window, Voxtral can handle audio files up to 40 minutes in length and manage long, multi-turn conversations.
Architecture and Components
Voxtral's architecture is based on the Transformer model and comprises three primary components: an audio encoder, an adapter layer, and a language decoder. (Figure 1) illustrates the overall architecture.

Figure 1: Voxtral Architecture.
Audio Encoder
The audio encoder is based on Whisper large-v3 and converts raw audio waveforms into log-Mel spectrograms using 128 Mel-bins and a 160 hop-length. The spectrogram is processed through a convolutional stem, which downsamples the temporal resolution by a factor of two, and then fed into bidirectional self-attention layers. This process yields audio embeddings with a frame rate of 50 Hz. To handle audio sequences longer than 30 seconds, the encoder processes audio in 30-second chunks, resetting absolute positional encodings for each chunk, which is functionally equivalent to chunk-wise attention.
Adapter Layer
To reduce the computational load on the language decoder, an MLP adapter layer downsamples the audio embeddings. The paper identifies a 4x downsampling factor as the optimal trade-off between sequence length and performance, resulting in an effective frame rate of 12.5 Hz.
Language Decoder
The language decoder comes in two variants: Mini and Small. Voxtral Mini is built on top of Ministral 3B, while Voxtral Small utilizes the Mistral Small 3.1 24B backbone. The parameter counts for each component are detailed in Table 1 of the paper.
Training Methodology
The training process involves three phases: pretraining, supervised finetuning, and preference alignment.
Pretraining
The pretraining phase introduces speech to the language decoder, complementing the existing text modality. Audio data with text transcriptions is segmented into short audio-text pairs: (A1,T1),(A2,T2),…,(AN,TN). Two patterns are used: audio-to-text repetition and cross-modal continuation, as shown in (Figure 2).
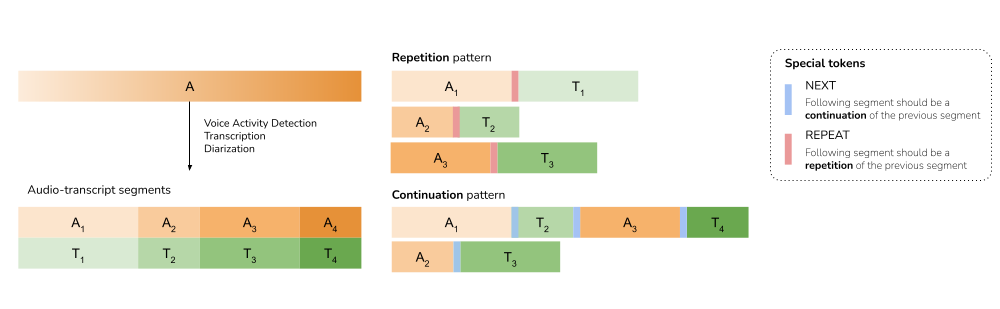
Figure 2: Pretraining patterns for Voxtral.
The audio-to-text repetition pattern aligns audio segments An with corresponding transcriptions Tn, mimicking speech recognition. The cross-modal continuation pattern aligns each audio segment An with the subsequent text segment Tn+1, resembling QA or conversation tasks. Special tokens <repeat> and <next> indicate the expected output pattern. During pretraining, these patterns are balanced evenly, with text pretraining data included to preserve text capabilities.
Supervised Finetuning
The supervised finetuning phase enhances transcription capabilities and extends the model’s proficiency in speech understanding tasks. The data includes tasks with audio context and text queries, as well as tasks where the model responds directly to audio inputs. Synthetic data is generated using long-form audio data and LLMs (Mistral Large) to create question-answer pairs. Text user messages are converted into synthetic audio using a TTS model. A dedicated "transcribe mode," signaled via a special token, is used for speech recognition tasks.
Preference Alignment
Direct Preference Optimization (DPO) and its online variant are used to improve response quality. The online variant samples two candidate responses from the current policy, and a text-based reward model ranks these responses using audio transcription to capture semantics, style, and factual coherence.
Evaluation Benchmarks
In addition to standard benchmarks, the paper introduces new test sets to evaluate long-context QA. Speech-synthesized versions of text benchmarks such as GSM8K, TriviaQA, and MMLU are created to evaluate spoken-language understanding. An internal benchmark measures the model's ability to answer questions about audios, using an LLM judge to assess helpfulness and quality.
Results and Analysis
Voxtral is evaluated on speech recognition, translation, speech understanding, speech function calling, and text benchmarks.
Speech Recognition
(Figure 3) shows macro-averaged word error rates (WER) on English Short-Form, English Long-Form, Mozilla Common Voice 15.1 (MCV), and FLEURS. Voxtral Small achieves state-of-the-art transcription results on English Short-Form and MCV, while Voxtral Mini Transcribe outperforms GPT-4o mini Transcribe and Gemini 2.5 Flash across all tasks.
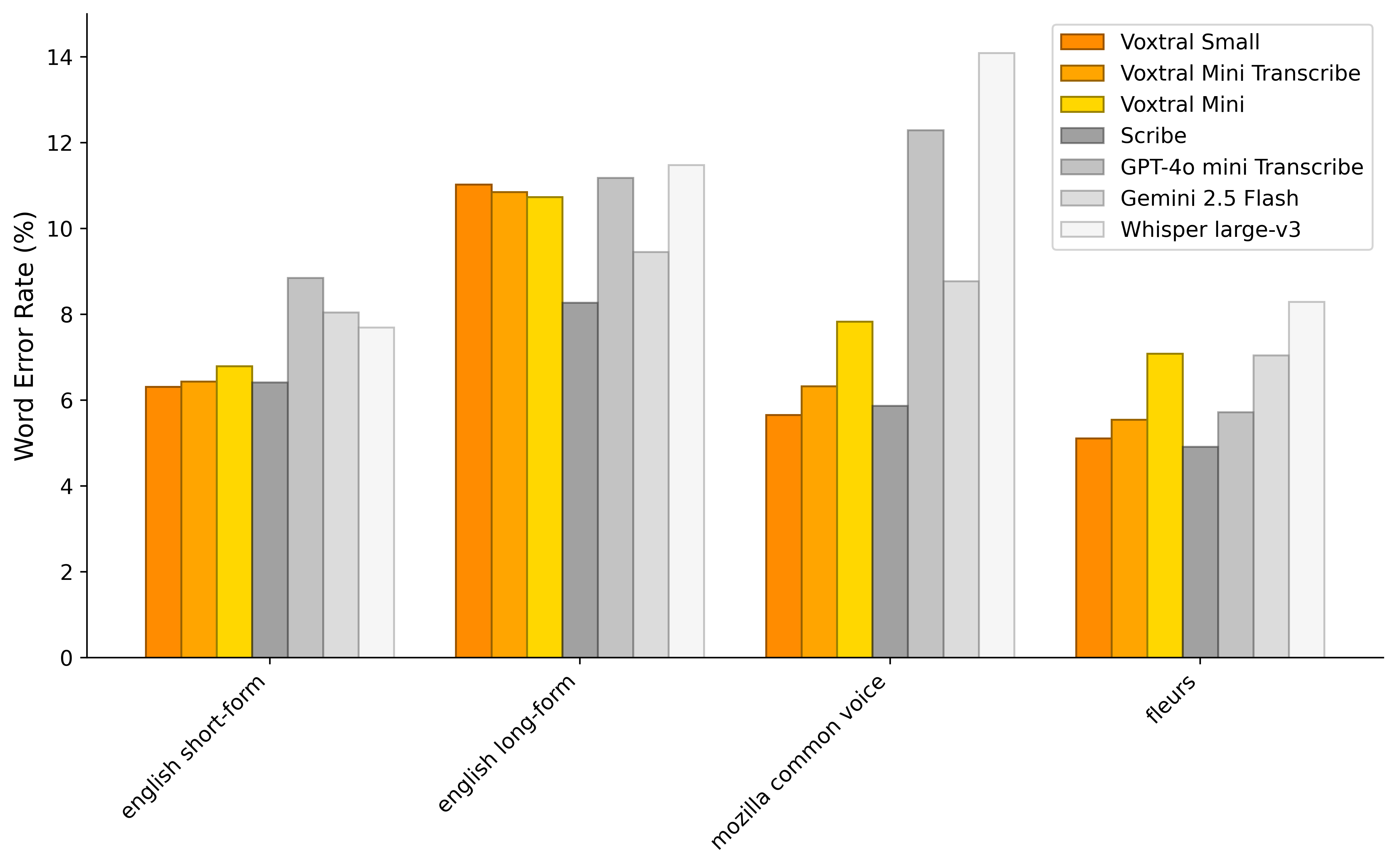
Figure 3: Speech Recognition Benchmarks.
Speech Translation
(Figure 4) presents BLEU scores for source/target pairs on the FLEURS Speech Translation benchmark, where Voxtral Small achieves state-of-the-art translation scores in every combination.
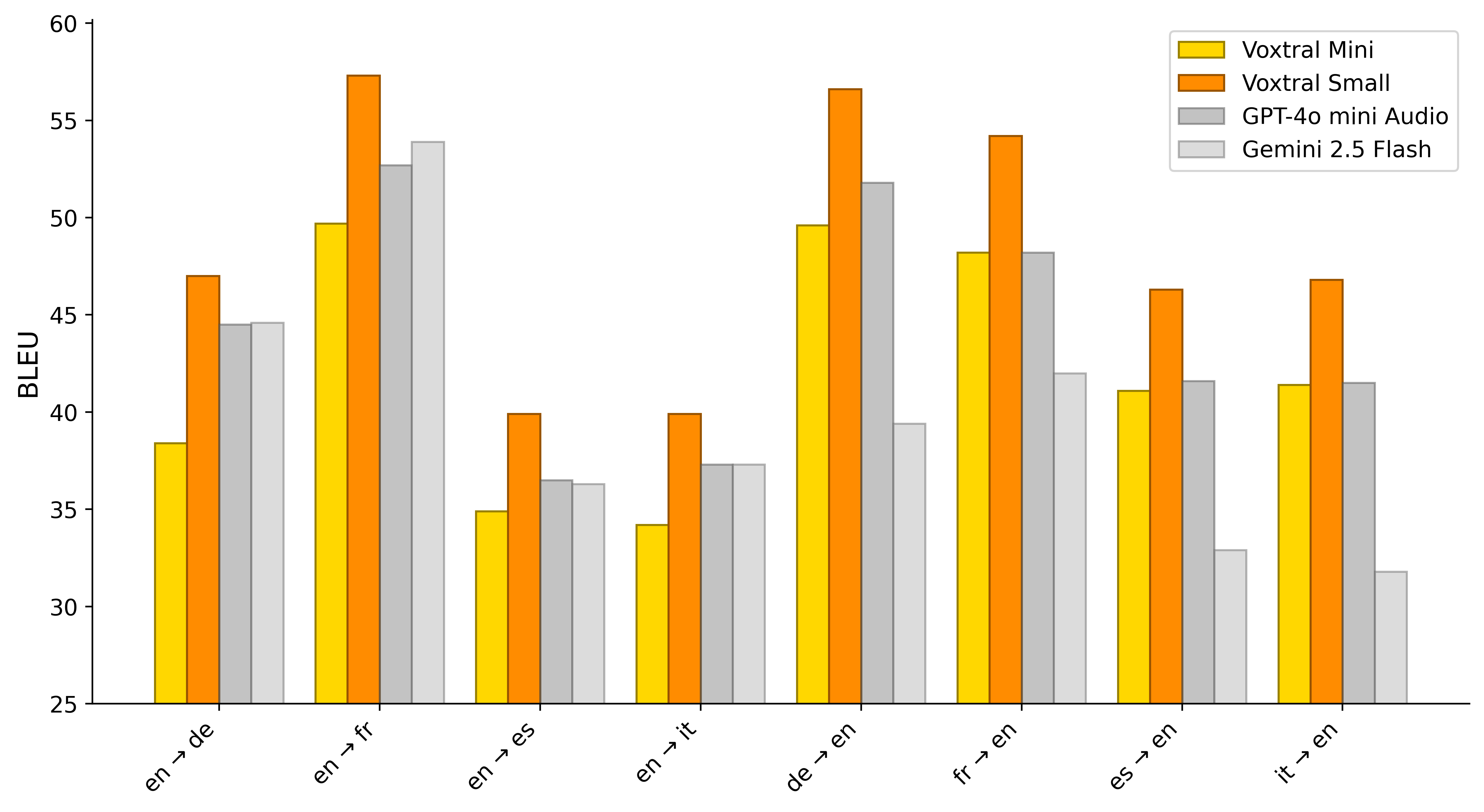
Figure 4: FLEURS Translation.
Speech Understanding
(Figure 5) highlights the performance of Voxtral Small on public Speech QA benchmarks and speech-synthesized subsets of standard Text Understanding benchmarks. Voxtral Small performs competitively with closed-source models, surpassing GPT-4o mini Audio on three of the seven tasks.
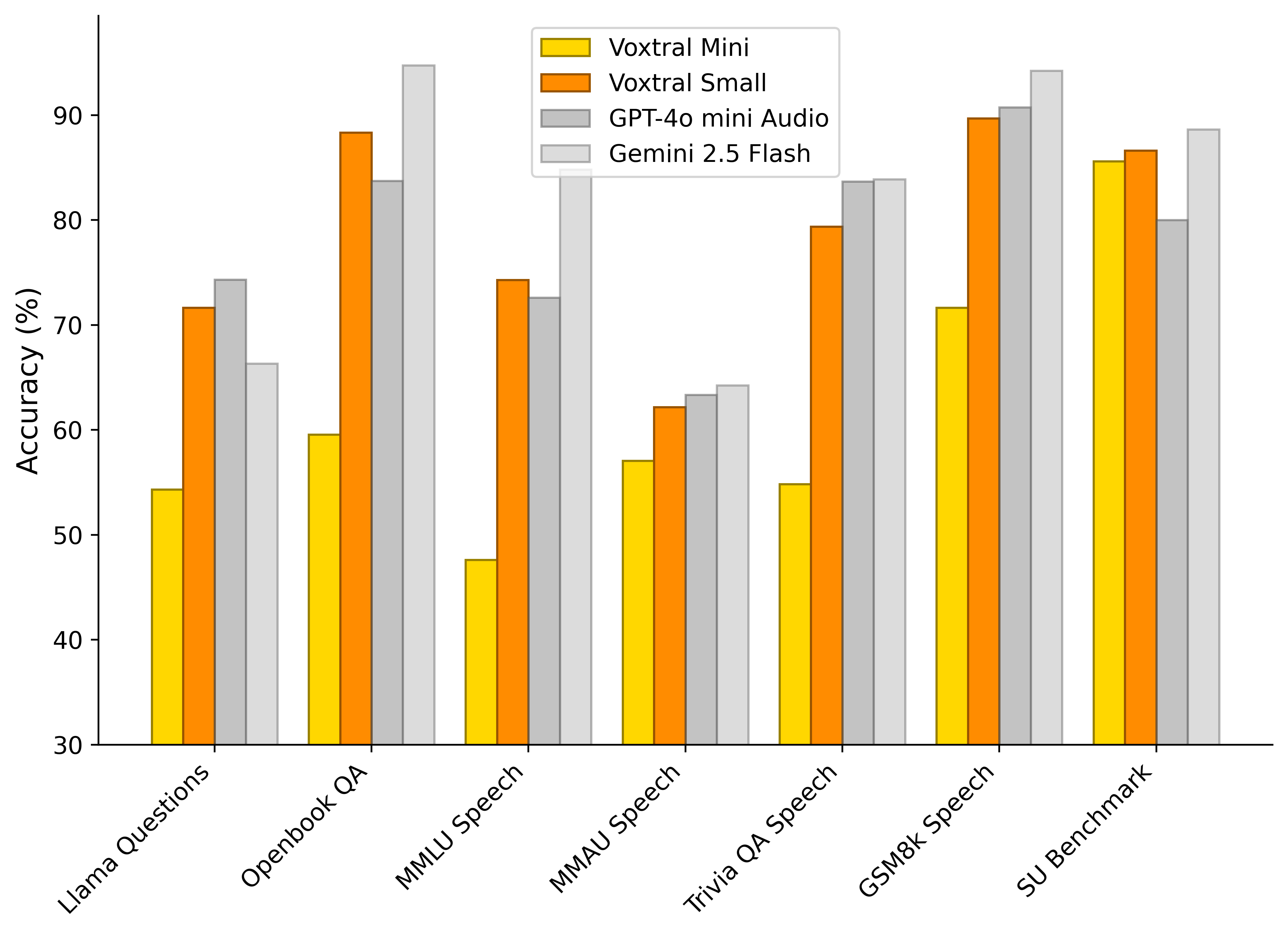
Figure 5: Speech Understanding Benchmarks.
Text Benchmarks
(Figure 6) compares the performance of Voxtral Mini and Small to the text-only Mistral Small 3.1 model, demonstrating that Voxtral Small maintains performance across text-benchmarks.
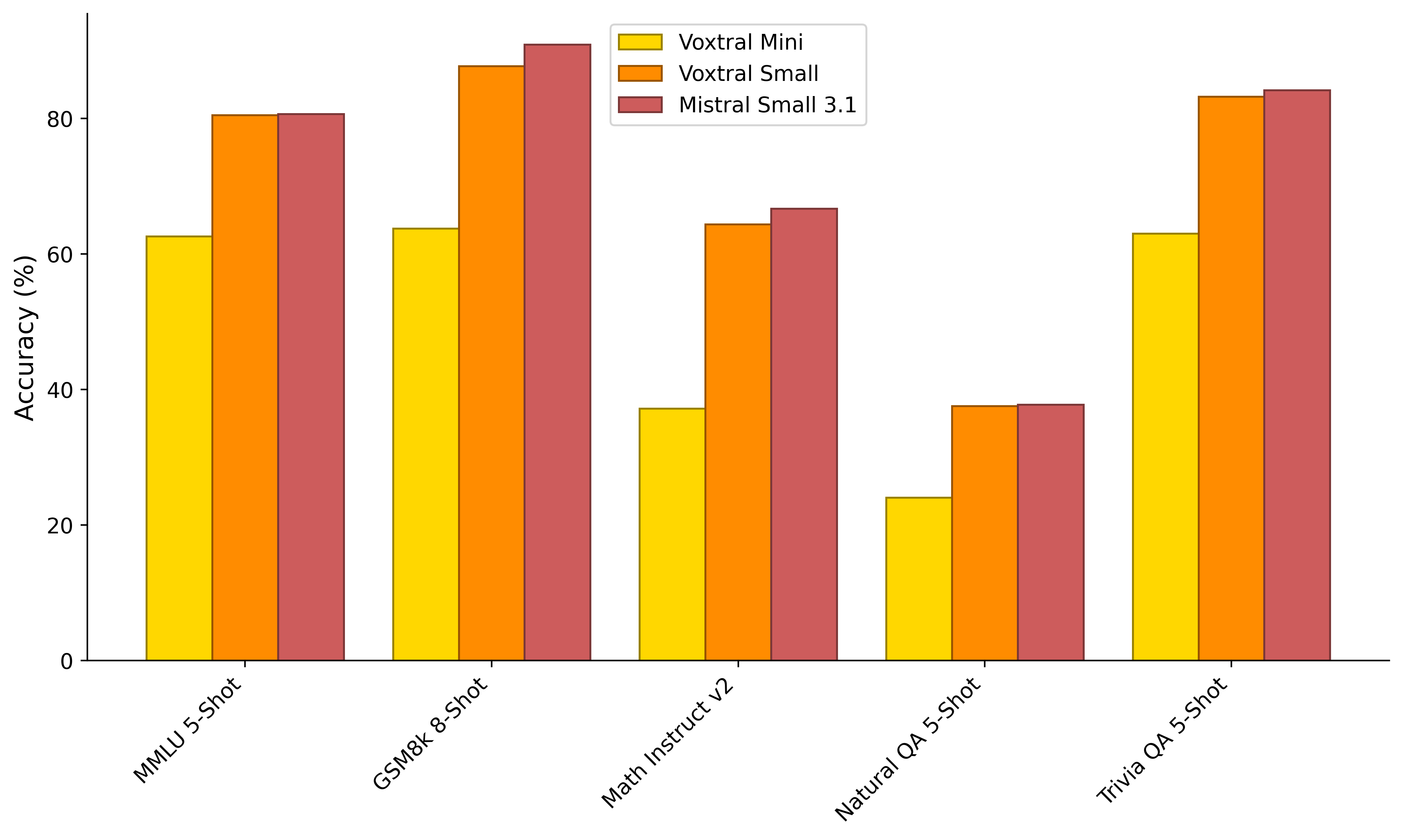
Figure 6: Text-Only Benchmarks.
Ablation Studies
The paper includes ablation studies on architectural choices, pretrain pattern formats, and the impact of Online DPO. (Figure 7) examines the effect of padding, (Figure 8) analyzes adapter downsampling, and (Figure 9) explores pre-training patterns.
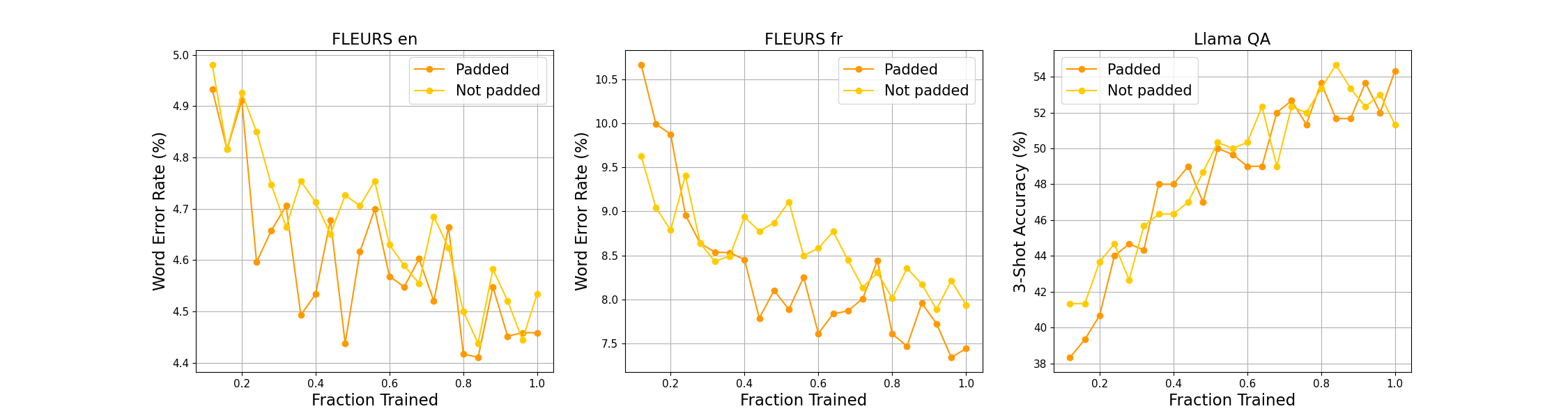
Figure 7: Effect of Padding.
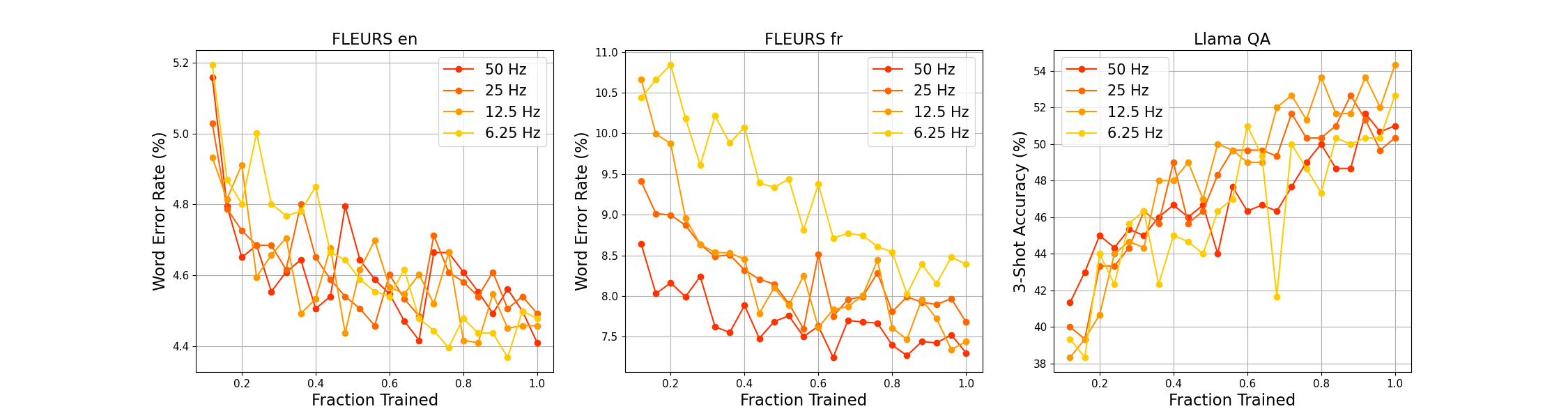
Figure 8: Effect of Downsampling.
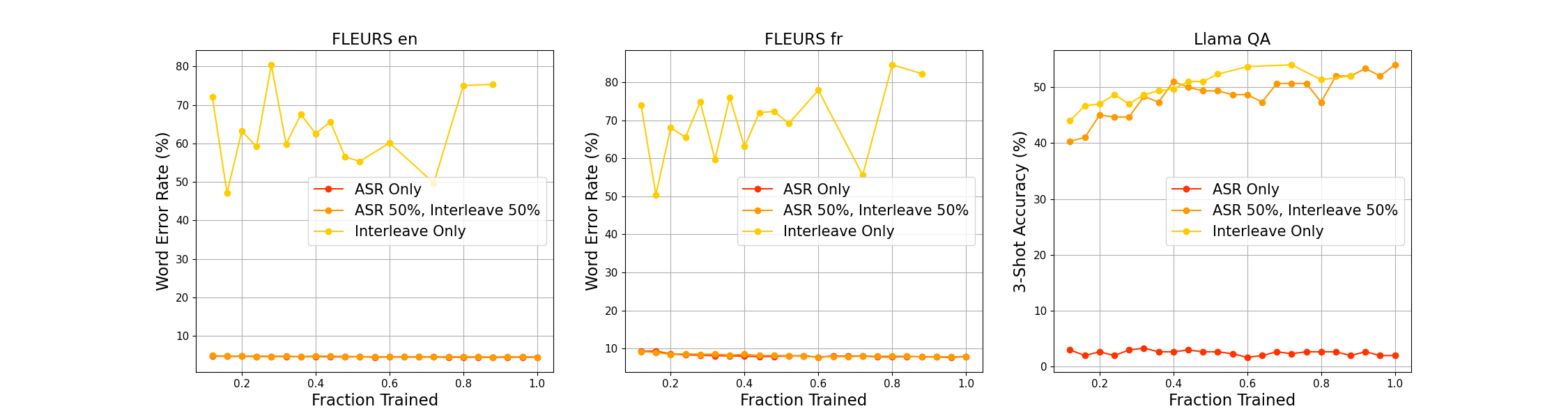
Figure 9: Pattern Proportions.
Conclusion
This paper introduces Voxtral Mini and Voxtral Small, a pair of open-weights audio chat models that demonstrate strong capabilities in understanding spoken audio and text. Their strengths across a wide array of speech tasks, instruction following, and multilingual prowess make them highly versatile for complex multimodal tasks. Both models are released under the Apache 2.0 license.