- The paper introduces a multi-reward DPO method that optimizes text alignment, audio quality, and rhythmic consistency in text-to-music generation.
- It fine-tunes flow-matching models using paired training data and reward prompting, achieving significant improvements over state-of-the-art baselines.
- Empirical results show notable gains in aesthetic scores, content enjoyment, and rhythmic stability, validated through human preference evaluations.
Multi-Reward Direct Preference Optimization for Flow-Matching Text-to-Music Generation
Introduction
MR-FlowDPO proposes a preference alignment framework for text-to-music flow matching generative models by introducing a multi-reward Direct Preference Optimization (DPO) paradigm. Rather than relying solely on single-criterion rewards or expensive human preference annotation, MR-FlowDPO utilizes a combination of automatic, scalable model-based rewards—text alignment, audio production quality, and semantic consistency—to generate preference data and guide reward prompting. This approach produces robust improvements in perceptual metrics and human preference evaluations over state-of-the-art (SOTA) baselines.
(Figure 1)
Figure 1: An overview of the MR-FlowDPO system—reward evaluation on multiple axes is used to select preference pairs for DPO fine-tuning.
Methodology
Flow-Matching Generative Modeling and Preference Optimization
The framework fine-tunes pretrained flow-matching text-to-music models using a direct preference optimization loss adapted to the flow-matching ODE paradigm. Preference pairs are characterized as positive/negative samples based on strong domination across reward axes, producing robust multi-objective optimization. The DPO loss formulation explicitly optimizes for reward difference between positive and negative samples, regularized by reference model predictions.
Multi-Reward Construction
Three reward axes are defined:
- Text Alignment: Cosine similarity between text and audio embeddings computed by a CLAP model, optimized for capturing textual-conditional alignment in musical elements.
- Audio Production Quality: Scalar regression scores from an Aesthetics predictor trained to assess audio fidelity, clarity, and technical proficiency.
- Semantic Consistency: A novel scoring mechanism using a HuBERT model retrained on large-scale music data, estimating the temporal/log-likelihood coherence over semantic audio tokens, targeting structural and rhythmic stability in the audio domain.
Paired training data is constructed using a Multi Reward Strong Domination (MRSD) scheme: for every prompt, sampled outputs are ranked on each axis, with positive/negative samples selected such that the positive strongly dominates in at least one reward, but is not worse in any other.
Reward Prompting
Inference is augmented with explicit reward prompting by prepending generated textual queries with the reward values that are being targeted, further steering samples toward desired axes of quality.
Experimental Results
Benchmarks and Objective Improvements
Evaluations are conducted using large-scale text-conditioned datasets, including MusicCaps and proprietary in-domain sets.
- Audio Quality: Aesthetics scores for MR-FlowDPO-1B reach 8.26 vs. 7.13 (MelodyFlow-1B) and 7.17 (MusicGen).
- Content Enjoyment: 7.72 for MR-FlowDPO-1B vs. 6.69/6.72 for baselines.
- Rhythmic Stability: BPM standard deviation is reduced from over 8.01 (MelodyFlow) to 6.11, indicating major improvements in rhythmic coherence.
Results indicate the multi-reward DPO alignment provides significant improvements in fidelity and musical coherence without sacrificing text adherence.
Human Preference
Subjective evaluations include overall preference, quality, text alignment, and musicality, with MR-FlowDPO-1B receiving clear preference over MelodyFlow-1B in all categories:
(Figure 2)
Figure 2: Human study results—MR-FlowDPO outperforms the reference across all evaluation axes.
Net win rates are consistently positive against all strong baselines, with the largest advantage in musicality and production quality.
Ablation and Analysis
Reward Axes Contribution
- Optimizing solely for text alignment increases text-audio congruence but degrades rhythmic stability, confirming the need for multi-reward supervision.
- Introducing production quality and semantic consistency raises both aesthetic and musicality metrics while reducing BPM variance.
MRSD and Prompting Impact
- MRSD pairing accelerates convergence and balances reward trade-offs, yielding superior audio quality and rhythmic stability.
- Reward prompting is found to further enhance all objective metrics. Using continuous (rather than categorical) reward representations in prompts is more effective.
Substituting Human Annotation
Model-based MRSD preference pairs are at least as effective as human-annotated pairs, supporting the scalability and viability of the automatic reward-based approach.
Per-Genre Effect
Analysis indicates MR-FlowDPO's human preference gains generalize across a wide range of genres, including funk, lo-fi, electronic, and industrial.
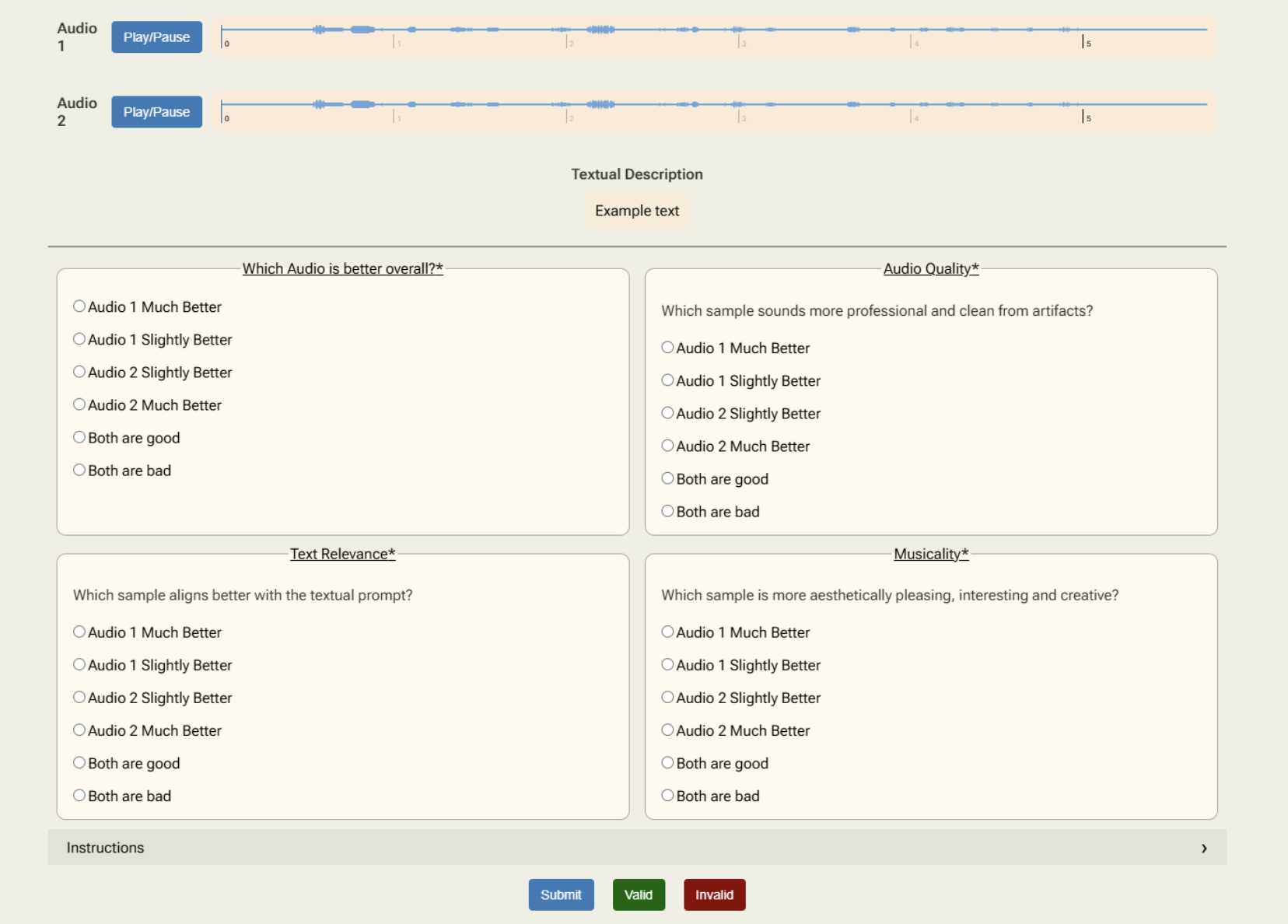
Figure 3: Human annotation interface used to collect detailed multi-aspect comparative judgments for generated music pairs.
Implications and Future Directions
MR-FlowDPO demonstrates that scalable, multi-reward model-based preference optimization can yield substantial gains across multiple perceptual axes in text-conditional music generation. The integration of semantic consistency rewards derived from self-supervised representation learning addresses a key limitation in prior flow-matching approaches—rhythmic instability and musical incoherence.
The methodology is extensible: additional reward dimensions (e.g., style, dynamics, genre specificity) and alternate alignment strategies (e.g., distributionally robust pairing, user-personalized reward models) could enhance flexibility and robustness. Practically, the framework supports generation pipelines for high-fidelity, user-aligned music creation in creative industries, adaptable sound design, and human-AI cooperative composition systems.
Conclusion
MR-FlowDPO establishes a new paradigm for aligning flow-based text-to-music generative models with human preference by incorporating multi-axis reward optimization and scalable reward prompting. Empirical evidence demonstrates robust gains over SOTA methods in both human and automatic measures of quality, coherence, and alignment. The approach supports scalable, nuanced alignment in subjective generative domains and is a strong foundation for further research in preference-driven audio generation and evaluation.

