- The paper introduces Sparton, which fuses matrix multiplication, element-wise operations, and reduction to drastically cut memory usage in Learned Sparse Retrieval.
- It achieves up to 4.8× speedup and 12× memory reduction by leveraging vendor-optimized GEMM and reordering max-reduction to minimize activation storage.
- Sparton enables processing of sequence lengths up to 8192 and larger batch sizes, unlocking scalable LSR on commodity and datacenter GPUs.
Sparton: Fast and Memory-Efficient Triton Kernel for Learned Sparse Retrieval
Motivation and Problem Context
Learned Sparse Retrieval (LSR) models have proven highly effective in producing sparse, high-dimensional representations tied to lexical vocabularies of pretrained LLMs. Architectures like Splade employ a LLM (LM) head to project hidden states into a logit matrix, which is subsequently processed through ReLU, log1p, and max-pooling operations to yield lexical salience scores. However, the LM head creates severe memory bottlenecks, particularly as vocabulary sizes in modern models (∣V∣) reach 30k–250k tokens. Materializing the full logit matrix L∈RB×S×∣V∣ in high-bandwidth memory (HBM) leads to surges in memory usage and excessive I/O operations, drastically limiting scalability in batch size, sequence length (S), and vocabulary, while throttling GPU throughput.
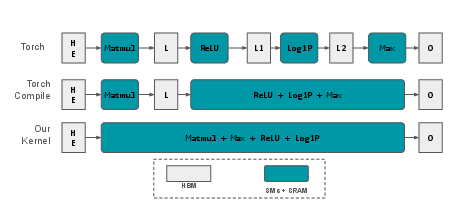
Figure 1: LM implementations in PyTorch and Sparton. Data in HBM (grey) is loaded into SRAM per block for parallel computation in Streaming Multiprocessors (green).
PyTorch's standard and compiled execution modes fail to fuse the critical matrix multiplication (matmul) with subsequent reductions, causing repeated memory transfers and hard scalability ceilings. Recent sparse retrieval approaches, including tiling the logit matrix, ameliorate forward memory consumption but leave backward memory overhead unresolved due to how PyTorch's autograd retains intermediate activations. There is thus a pressing need for a kernel that fuses matmul, element-wise operations, and reduction into an efficient, memory-minimizing pass.
Sparton Kernel Design
Sparton addresses these bottlenecks by leveraging Triton for operator fusion and early online reduction. The forward pass exploits the monotonicity of f(x)=log(1+ReLU(x)) to reorder the max reduction before nonlinearities, enabling computation of the maxima over the sequence dimension directly on raw logits. This results in only B×∣V∣ activations being written to HBM, shrinking activation storage and bandwidth requirements by a factor of S.
Algorithmically, Sparton computes tiled logits using vendor-optimized GEMM (cuBLAS/rocBLAS) over vocabulary tiles, instantly applying a fused Triton kernel for masked max-reduction and storing only max values and their argmax indices. Subsequent ReLU and log1p are localized to the reduced outputs, avoiding materialization of the full B×S×∣V∣ matrix.
The backward pass is similarly fused. Gradients are routed exclusively to the hidden states and embeddings corresponding to the stored max sequence positions. This reduces the saved forward state from O(BS∣V∣) to O(B∣V∣), radically alleviating redundant storage and minimizing I/O.
Experimental Results
Sparton was benchmarked against PyTorch (eager and compiled) and a tiled-only LM head across multiple axes: batch size, sequence length, and vocabulary size. End-to-end measurements included latency, peak memory, and retrieval effectiveness on state-of-the-art sparse encoders.
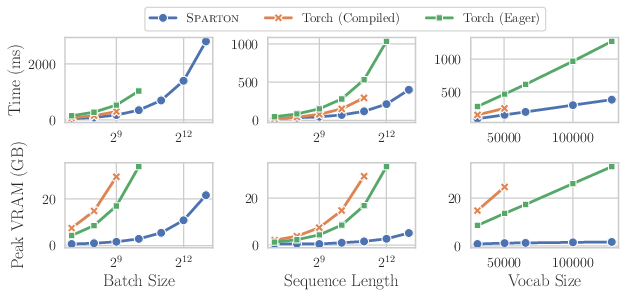
Figure 2: Scaling Sparton (without backbone) across three dimensions: Batch Size (S=512,∣V∣=30522), Sequence Length (B=128,∣V∣=30522), Vocabulary Size (B=256,S=512).
Key empirical findings:
- Speedup and Memory Reduction: Sparton delivers up to 4.8× speedup and 12× peak memory reduction versus compiled PyTorch baselines.
- Scalability: Only Sparton enables sequence lengths up to $8192$ (with B=128,∣V∣=30522), where all baselines hit out-of-memory errors. Memory requirements remain flat as batch size, sequence length, or vocab size grows, while baselines scale linearly or worse.
- Training Efficiency: When integrated into the Splade encoder, Sparton enables a 33% larger batch size and 14% faster training with no drop in retrieval effectiveness (measured via NDCG@10 on small-Beir). On multilingual backbones (∣V∣≈250k), the gains jump to a 26× larger batch size and 2.5× faster training.
Practical Implications
Sparton fundamentally removes the memory bottlenecks that have limited LSR training, unlocking the ability to process substantially larger inputs, batch sizes, sequence lengths, and vocabularies on commodity and datacenter GPUs. This enables practitioners to scale LSR models beyond the hardware limits imposed by PyTorch’s conventional implementation, facilitating rapid research iterations and deployment for retrieval scenarios requiring high throughput or multilingual coverage.
The kernel design is hardware-conscious, orchestrating block-level tiling and memory access patterns to maximize on-chip SRAM utilization and minimize HBM transfers, thus fully exploiting the arithmetic and bandwidth capabilities of modern GPUs (e.g., NVIDIA A100/H100).
Theoretical Implications and Future Directions
The operator fusion and reordering in Sparton demonstrate that activation storage for certain monotonic pipelines can be reduced by orders of magnitude. This paradigm could be extended to other model heads and architectures (beyond sparse retrieval), particularly in regimes with highly sparse regularization and sequence reductions.
Potential future developments include leveraging low-precision formats (FP8), specialized hardware features (Tensor Memory Accelerator), and exploring additional fusion opportunities across GPU primitives in Triton and vendor libraries. These optimizations would further push the envelope in LSR training speed, efficiency, and scalability.
Conclusion
Sparton presents a formalized, Triton-optimized approach for memory-efficient and accelerated LM head computation within Learned Sparse Retrieval models (2603.25011). By fusing core matrix and reduction operations, Sparton eliminates key limitations of PyTorch and enables LSR pipelines to scale seamlessly in batch, sequence, and vocabulary dimensions. Its adoption paves a practical path for scalable sparse retrieval and opens theoretical avenues for operator fusion and memory minimization in deep learning kernels.