- The paper presents Liger-Kernel, an open-source suite of Triton kernels that fuses GPU operations to significantly improve LLM training efficiency.
- It employs custom optimization techniques such as fused RMSNorm, GeGLU, and Fused Linear Cross Entropy to drastically reduce execution time and memory consumption.
- The methodology achieves practical gains, enabling larger batch processing and advanced LLM training on existing hardware without costly upgrades.
Liger Kernel: Efficient Triton Kernels for LLM Training
The growing demand for efficient training of LLMs necessitates advancements at the kernel level to enhance performance while reducing resource consumption. The paper introduces Liger-Kernel, a set of open-sourced Triton kernels optimized for LLM training that achieve significant improvements in both throughput and memory usage. The following discourse provides a comprehensive examination of the methodologies, implementations, and outcomes associated with this innovative tool.
Introduction
Liger-Kernel emerges as a solution to the challenges of scaling LLM training, particularly the inefficiencies inherent in memory management and latency-bandwidth trade-offs during tensor operations. It targets the last-mile optimization at the GPU kernel level, which is crucial for leveraging the parallelism of GPUs effectively. By integrating operation fusions within Triton kernels, Liger achieves a consistent 20% increase in training throughput and reduces GPU memory usage by 60% compared to conventional implementations.
The Liger-Kernel is designed to be modular and accessible, appealing to both novice and expert users. It integrates seamlessly with existing model compilation techniques like torch.compile, TVM, and XLA, while also supporting distributed systems such as PyTorch FSDP and DeepSpeed ZeRO, ensuring compatibility across various computational environments.
Kernels and Optimization Techniques
Operation Fusion
A central feature of the Liger-Kernel is the fusion of GPU operations to minimize overheads from separate function calls. This technique mitigates the latency between high-bandwidth memory (HBM) and shared memory (SRAM), crucial for executing deep learning models with large matrices efficiently. Techniques such as FlashAttention and its subsequent iteration, FlashAttention-2, demonstrate how fusing operations optimize attention computation in transformers, reducing memory complexity and enhancing parallelism across attention heads.
Custom Triton Kernels
The paper underscores the advantages of using Triton for developing high-performance GPU kernels without exploring low-level CUDA complexities. By using Triton, Liger-Kernel offers several optimized kernels, including:
- RMSNorm and LayerNorm: These kernels fuse normalization and scaling steps, leveraging caching mechanisms to reduce memory consumption and computation time significantly.
- GeGLU and SwiGLU: These kernels optimize specific activation functions by recomputing outputs during backpropagation, maintaining performance parity while reducing memory use.
- Fused Linear Cross Entropy (FLCE): Addresses the growing challenge of processing extensive vocabularies in LLMs by chunking logits and gradients, thereby enhancing memory efficiency and enabling larger batch sizes and sequence lengths.
- CrossEntropy Optimization: Adopts an in-place gradient computation with online softmax to improve execution speed and reduce memory usage substantially.
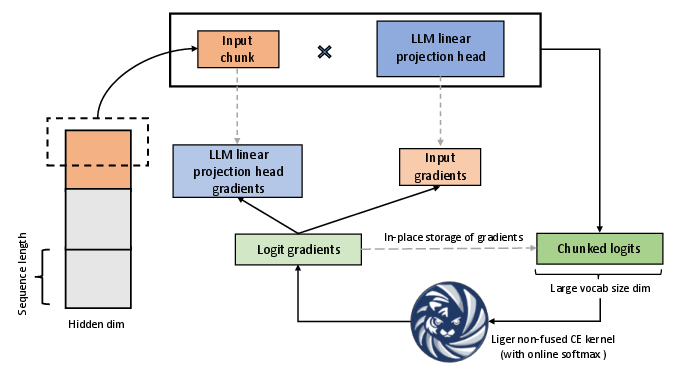
Figure 1: Fused Linear Cross Entropy in action, optimizing cross entropy loss computation by chunking logits.
Numerical Evaluation and Benchmarks
Benchmarks demonstrate substantial improvements across various kernels. For instance, the RMSNorm implementation shows a 7x reduction in execution time and a 3x reduction in memory use for larger hidden dimensions. Similarly, the CrossEntropy kernel achieves approximately 3x faster execution and 5x lower memory usage.
LLM Training Use Cases
Integration of Liger-Kernel into real-world training scenarios, such as fine-tuning LLaMA 3-8B and Qwen2 models, illustrates performance gains where throughput increases by up to 42.8% and memory usage drops by up to 56.8%. These improvements enable more efficient model training on existing hardware without the need for costly upgrades.
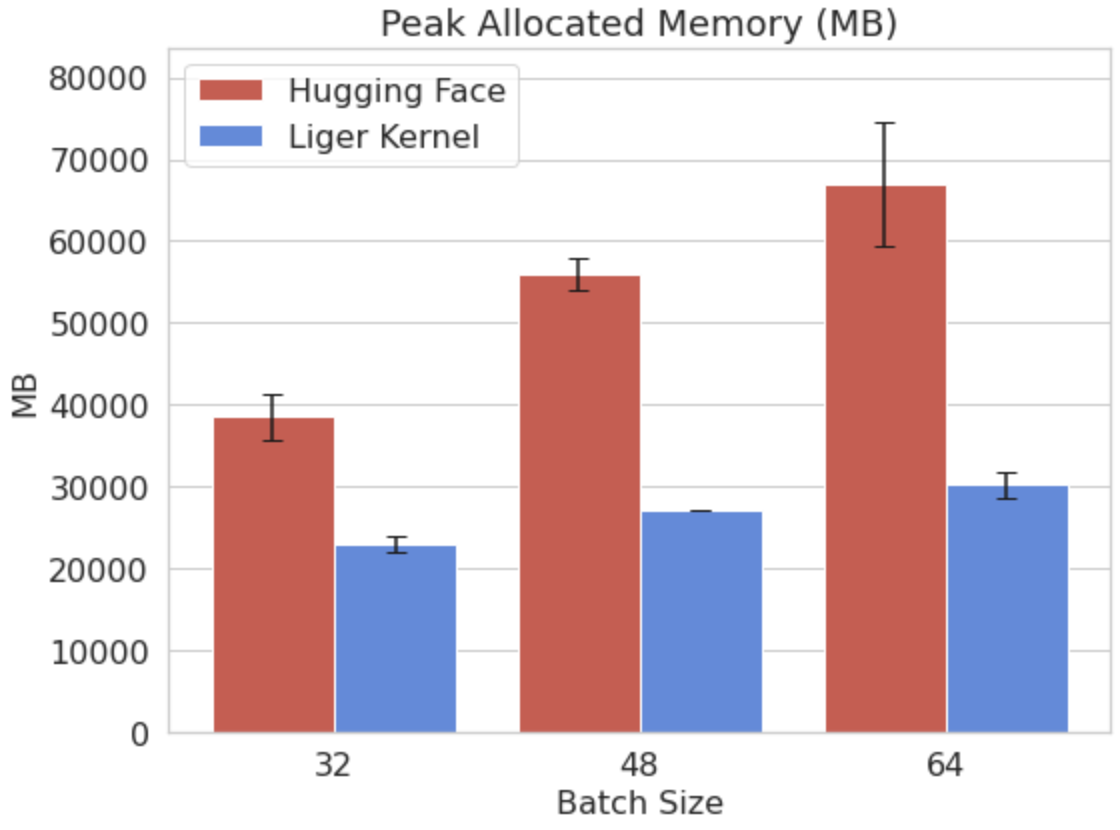
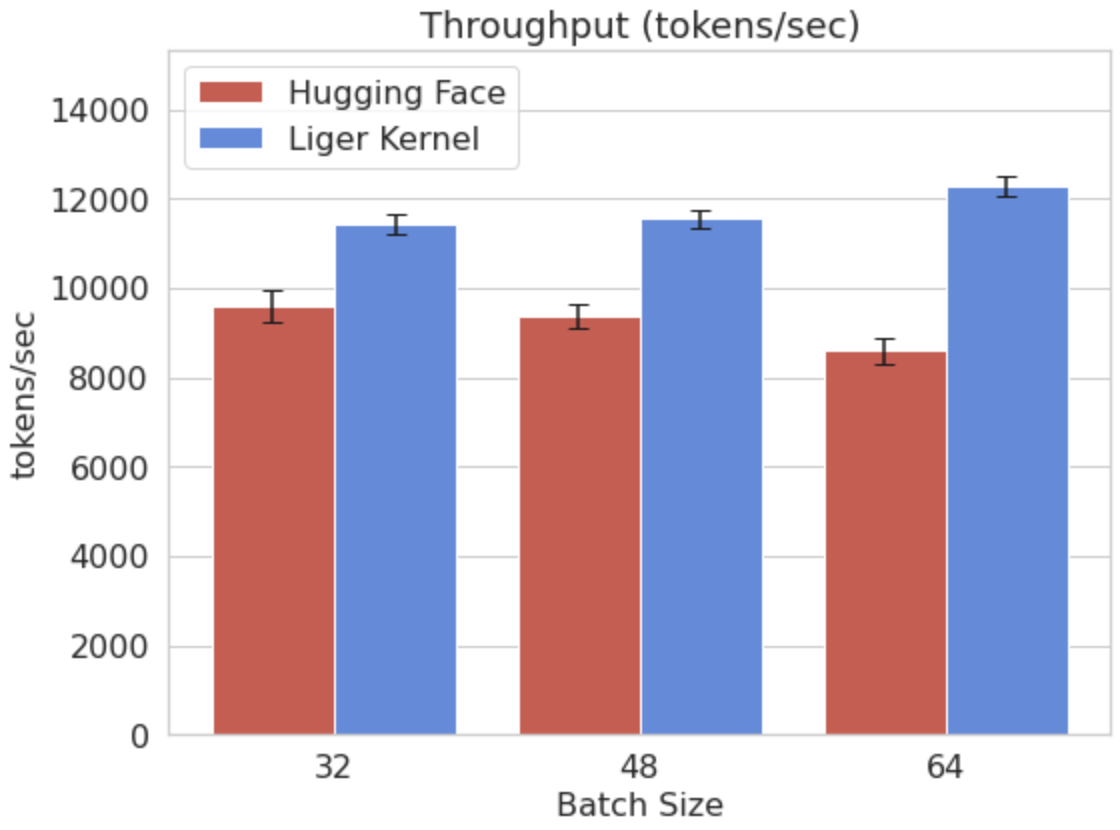
Figure 2: Comparison of peak allocated memory and throughput for LLaMA 3-8B, showcasing improvements achieved by Liger-Kernel.
Practical Implications and Future Directions
The practical implications of Liger-Kernel are profound. By enhancing efficiency and reducing resource demands, educational and research institutions with limited infrastructure can train state-of-the-art LMs more effectively. Moreover, the ability to handle larger models with low memory footprint is particularly advantageous for developing more sophisticated applications in AI and NLP domains.
Future developments may focus on expanding the kernel library, optimizing inference processes, and fostering broader community engagement to incorporate Liger-Kernel into diverse computational frameworks. The open-source nature of Liger-Kernel positions it as a pivotal tool in the drive towards more efficient and scalable AI solutions.
Conclusion
The paper presents Liger-Kernel as a substantial development in Triton kernel optimization for LLM training. By offering an accessible and high-performing kernel library, Liger-Kernel enhances the efficiency of training processes, making it a valuable asset for AI researchers and practitioners aiming to optimize training workloads without substantial hardware investment.