Composer 2 Technical Report
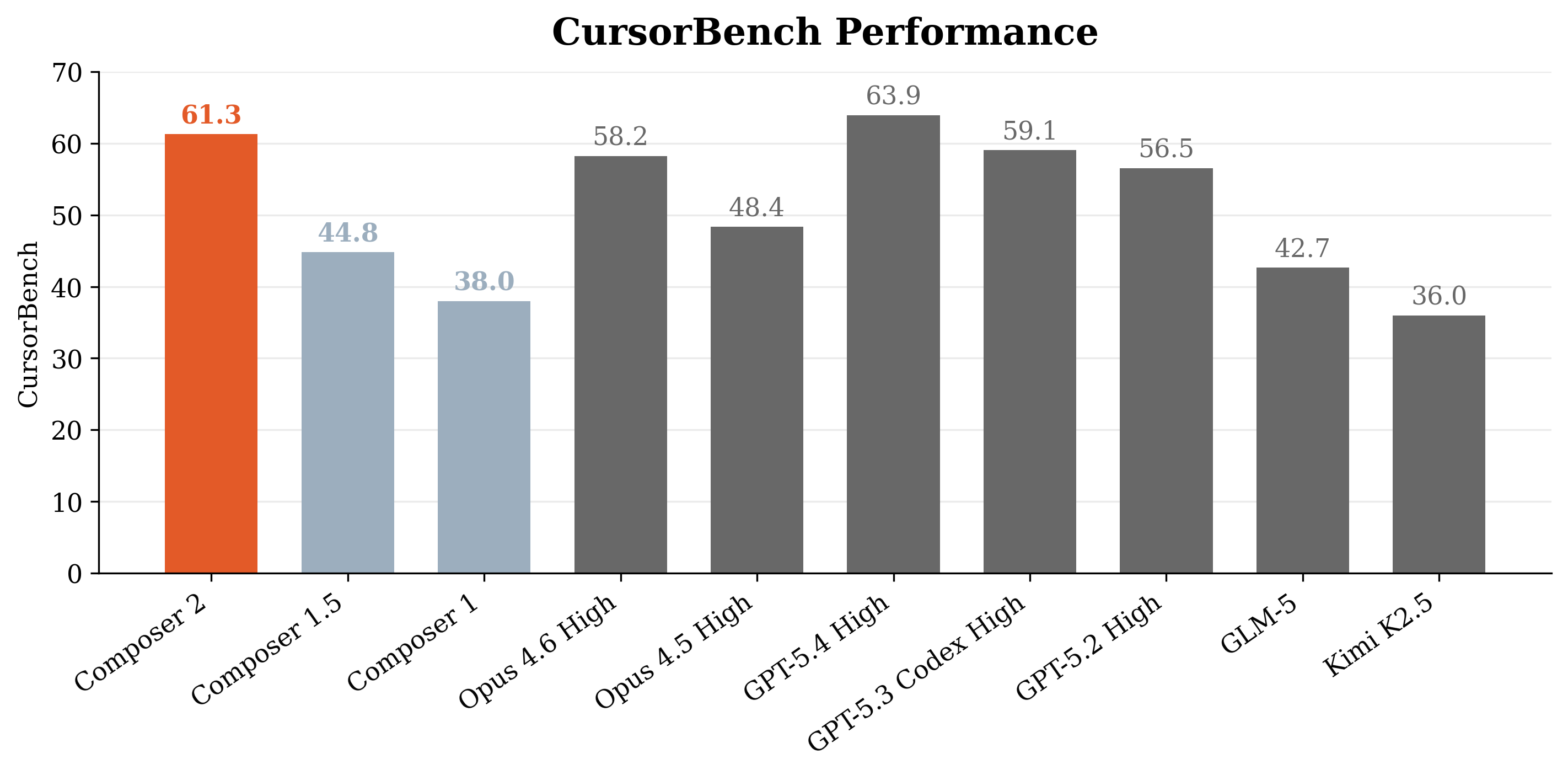
Abstract: Composer 2 is a specialized model designed for agentic software engineering. The model demonstrates strong long-term planning and coding intelligence while maintaining the ability to efficiently solve problems for interactive use. The model is trained in two phases: first, continued pretraining to improve the model's knowledge and latent coding ability, followed by large-scale reinforcement learning to improve end-to-end coding performance through stronger reasoning, accurate multi-step execution, and coherence on long-horizon realistic coding problems. We develop infrastructure to support training in the same Cursor harness that is used by the deployed model, with equivalent tools and structure, and use environments that match real problems closely. To measure the ability of the model on increasingly difficult tasks, we introduce a benchmark derived from real software engineering problems in large codebases including our own. Composer 2 is a frontier-level coding model and demonstrates a process for training strong domain-specialized models. On our CursorBench evaluations the model achieves a major improvement in accuracy compared to previous Composer models (61.3). On public benchmarks the model scores 61.7 on Terminal-Bench and 73.7 on SWE-bench Multilingual in our harness, comparable to state-of-the-art systems.
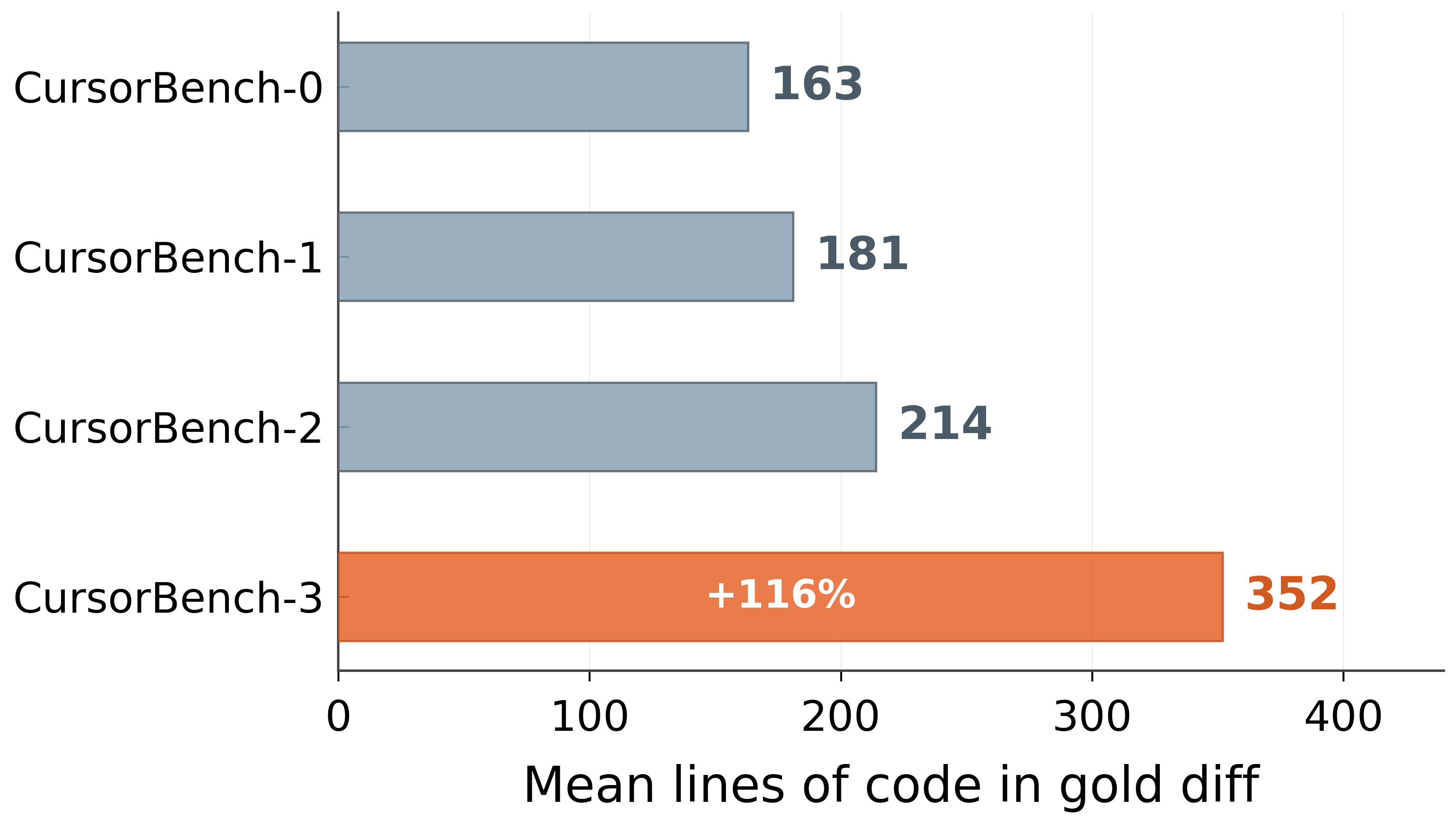
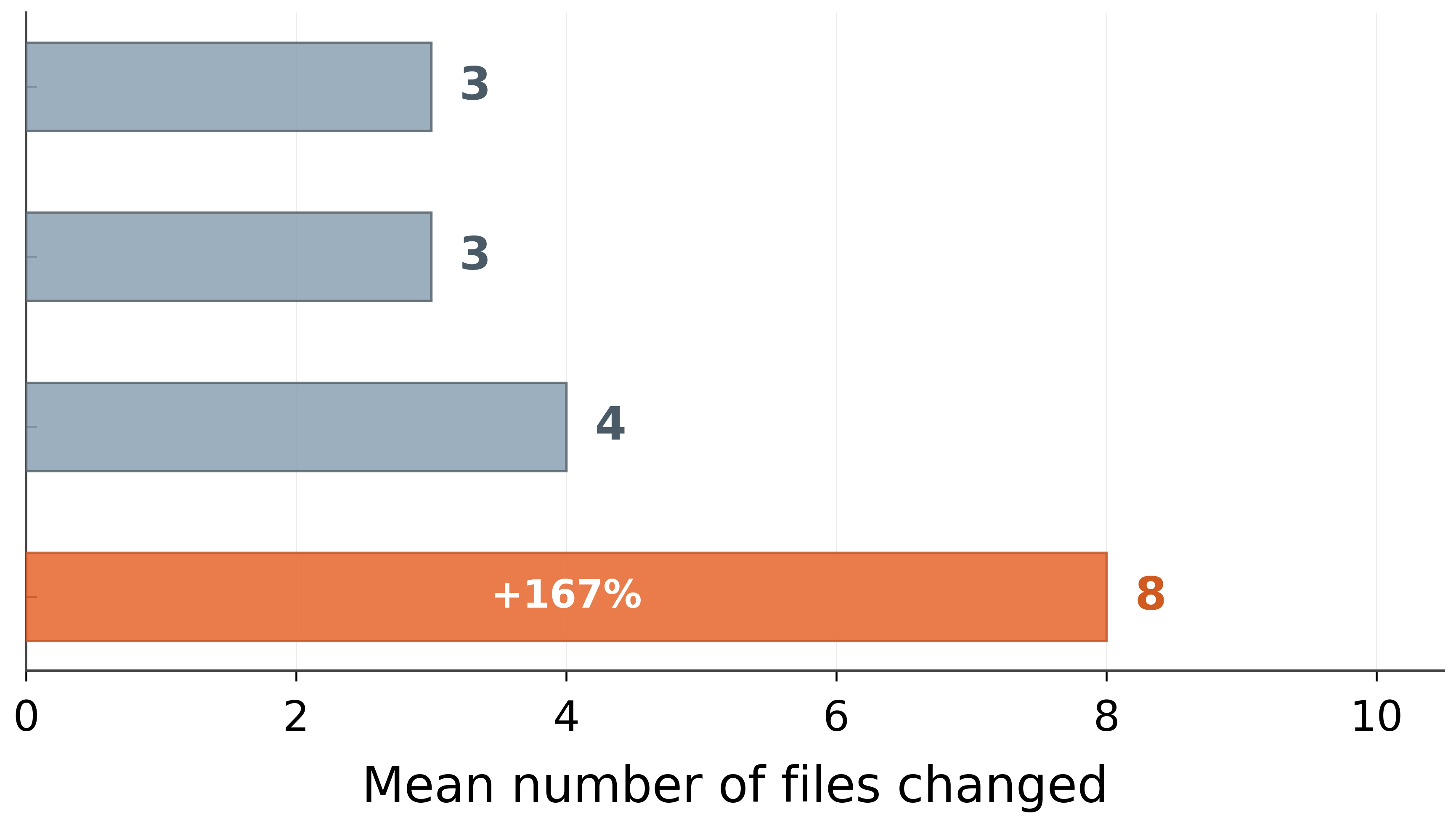
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple guide to “Composer 2 Technical Report”
What is this paper about?
This paper introduces Composer 2, an AI model built to help with real software engineering. Instead of just autocompleting code, Composer 2 acts like a careful junior developer: it reads and edits files, runs commands, searches a codebase, and plans multi-step fixes or features. The team trained it in a way that mirrors real developer work and then tested it on tough, realistic tasks. The result is a fast, strong, and cost‑effective coding assistant.
1) Big picture overview
Composer 2 is a specialized AI for coding that:
- Plans multiple steps ahead to solve tricky problems in real codebases
- Uses tools (like search, running tests, and editing files) to act like an agent
- Is trained and evaluated in a setup that matches real product use, not just lab tests
- Performs at or near the level of top models on public benchmarks while costing less to run
2) What questions were the authors trying to answer?
The team focused on a few simple questions:
- How do we train a coding model that solves real developer tasks, not just toy problems?
- Does giving the model more “coding practice” first make it better at learning from trial and error later?
- Can we use reinforcement learning (rewarding good behavior) to improve both everyday answers and the very best answers the model can produce?
- How do we measure progress using realistic tasks that look like actual work, not just tiny bug fixes?
- Can we make the model fast and affordable enough to be useful in daily development?
3) How did they train and test the model?
Think of the approach as “practice, then scrimmages,” with careful coaching.
- Continued pretraining (the “practice” phase):
- The model starts with a strong base (a “Mixture-of-Experts,” like a team of specialists).
- It gets lots of extra practice on code, including very long files (up to 256,000 tokens).
- It also learns targeted tasks to sharpen specific coding skills.
- They added Multi-Token Prediction to speed up how fast the model generates text (like learning to say several words at once, accurately).
- Reinforcement learning (the “scrimmage” phase):
- The model is dropped into realistic coding environments (the same harness used in the actual product).
- It gets a task (e.g., fix a bug, add a feature), and can:
- Read/edit files
- Run shell commands and tests
- Search the codebase (by text or meaning)
- Even search the web
- It tries different solutions. Good solutions earn rewards for correctness, clarity, style, and efficiency.
- This happens at large scale, with many “agents” trying variations in parallel, and the model updates based on how well those attempts did.
- Staying realistic:
- They trained in the same environment developers use in the Cursor product to avoid a gap between training and real-life use.
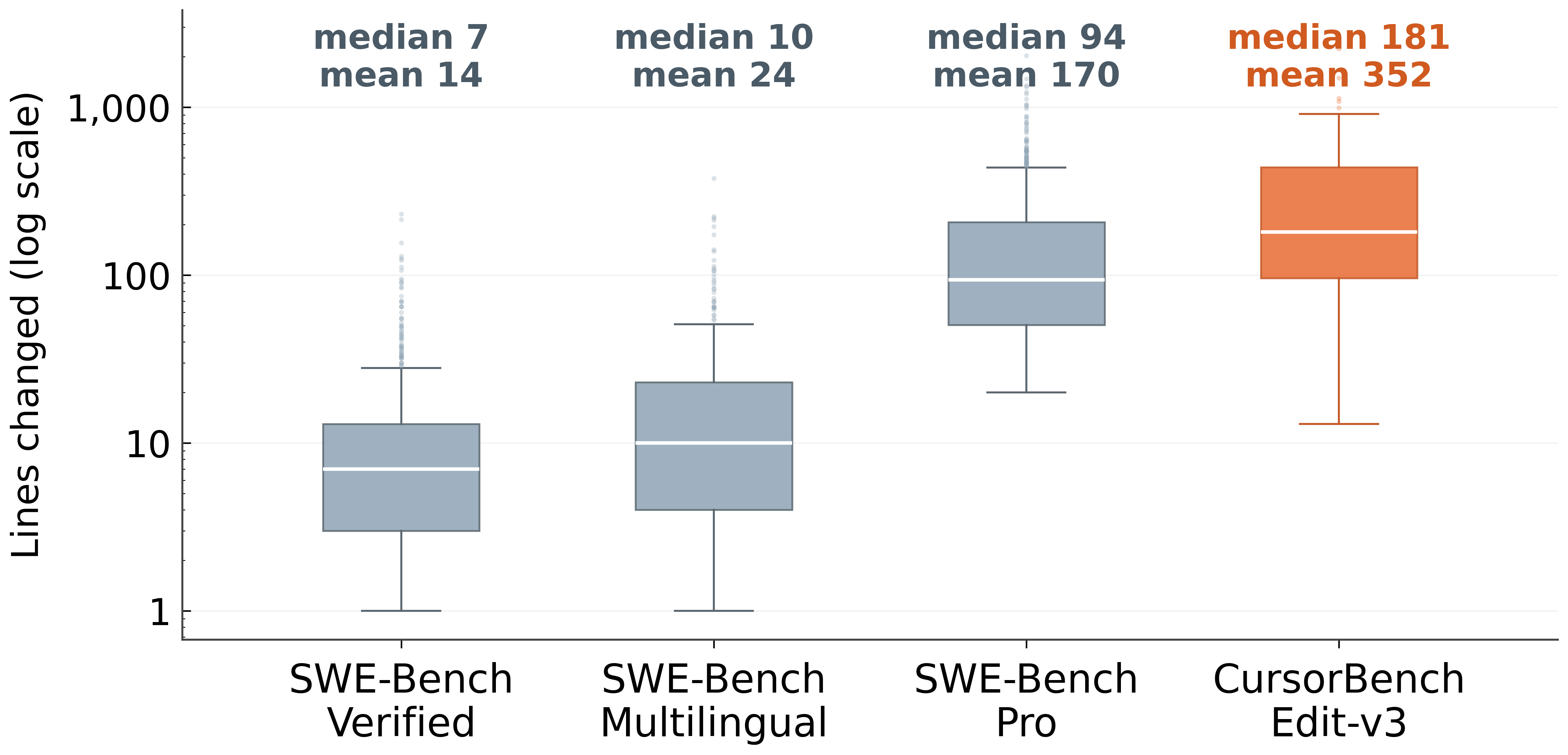
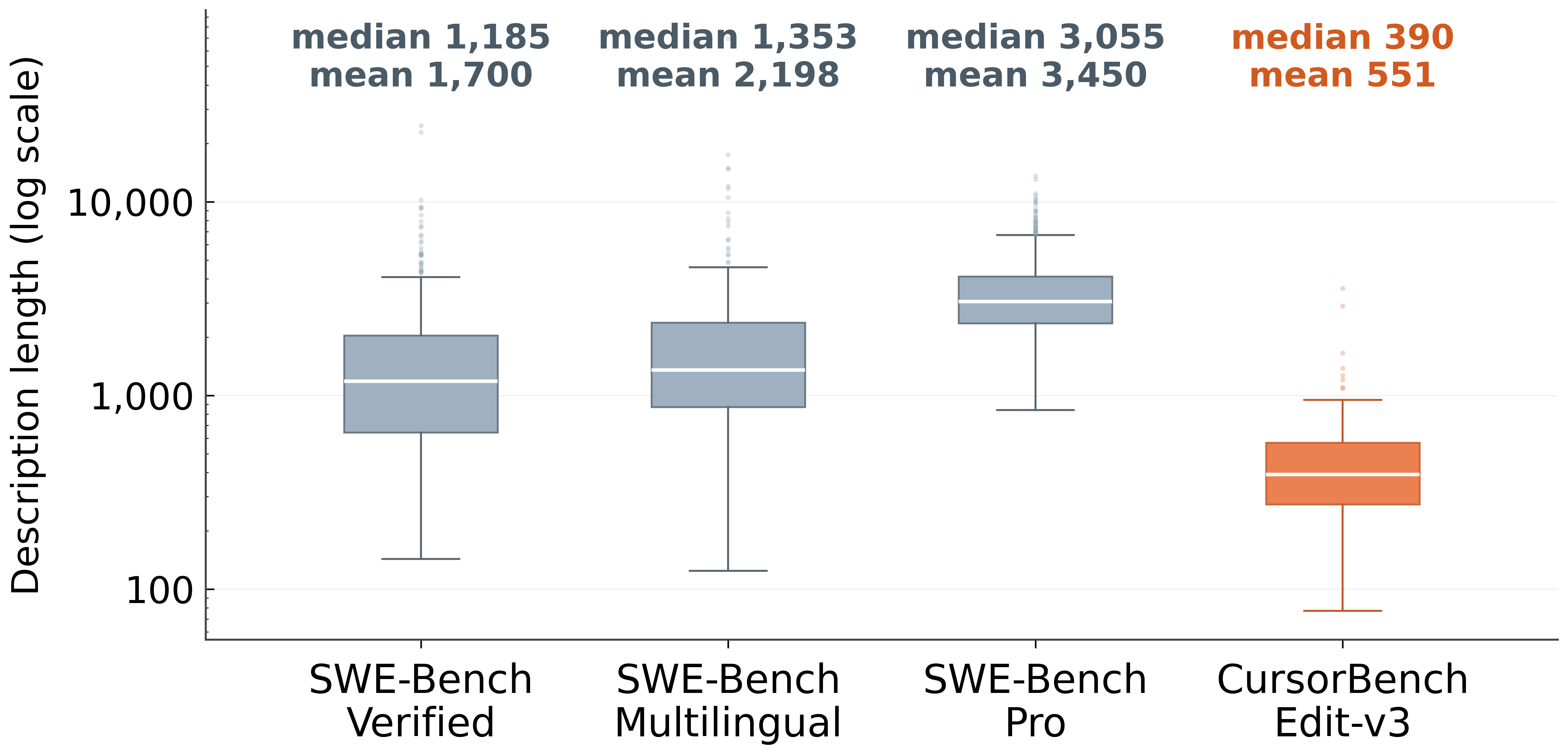
- They built CursorBench, a new evaluation made of real tasks from their engineering team—these tasks involve bigger code changes and vaguer instructions than most public tests.
- Handling long tasks:
- The model uses “self-summarization,” like taking its own notes to remember key details while working through long problems without getting lost.
- Encouraging good behavior:
- Extra rewards promote good communication, clean code, and avoiding bad habits (like leaving “TODOs” unfinished).
- A gentle “length penalty” nudges the model to be quick on easy tasks but allows more thinking time on hard tasks.
- Stability and speed:
- They used a sturdy, fast training setup that keeps the model updated across many machines without getting “off-track.”
- They used smart tricks (like replaying expert choices in the model’s “team of specialists”) so training matches the way the model behaves during inference.
4) What did they find, and why does it matter?
Here are the key results the paper reports and why they’re important:
- Strong performance on realistic tasks:
- On their internal CursorBench (built from real coding sessions), Composer 2 reached 61.3% accuracy—much higher than earlier Composer versions.
- On public benchmarks, it reaches frontier-level scores:
- Terminal-Bench: 61.7
- SWE-bench Multilingual: 73.7
- Why it matters: It’s not just good at tiny puzzles; it handles big, ambiguous tasks closer to real work.
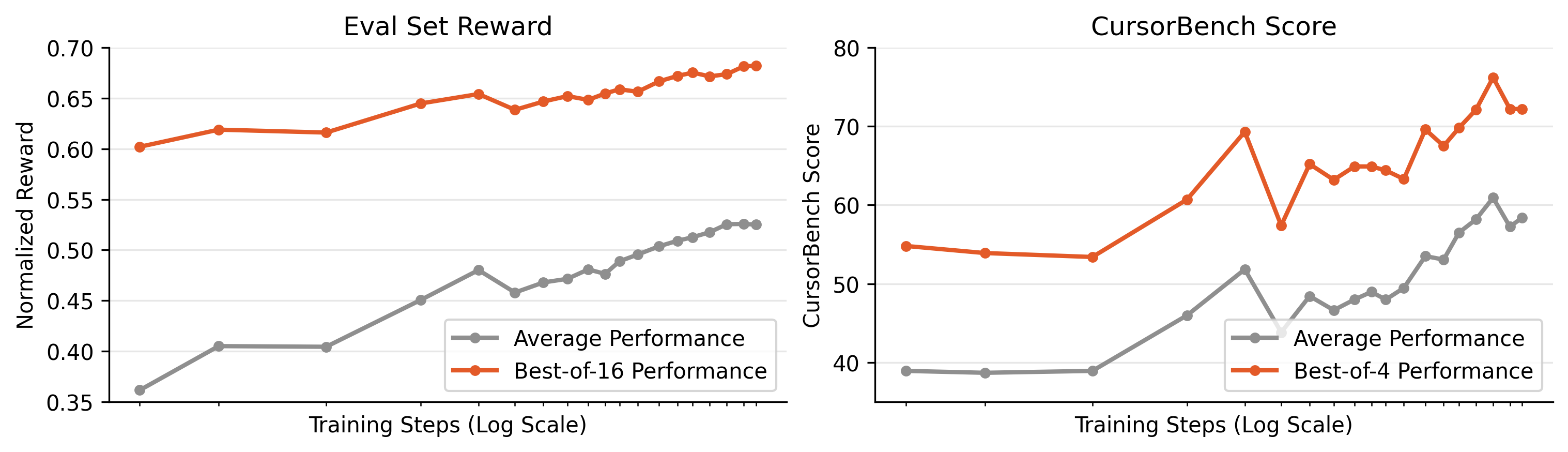
- Practice boosts learning:
- Extra coding pretraining improved how well reinforcement learning worked later.
- Why it matters: Investing in good “practice data” pays off when the model learns by trial and error.
- Better everyday answers and better best answers:
- Unlike some reports where RL makes the model safe but less diverse, Composer 2 improved both average performance and the best-of-K performance (the best answer among several tries).
- Why it matters: It suggests the model isn’t just picking one known solution more confidently—it’s expanding the number of ways it can solve problems.
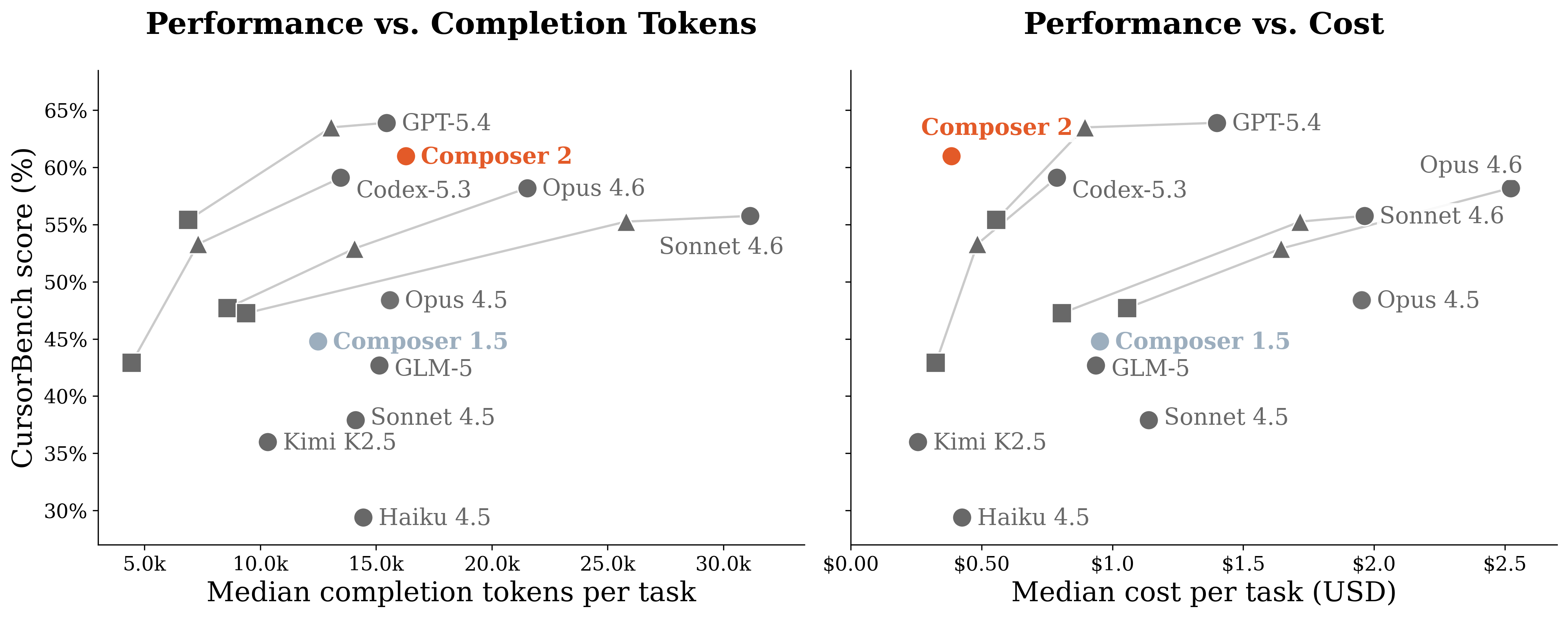
- Efficient and cost-effective:
- Composer 2 offers competitive accuracy while using fewer resources and costing less to run than many frontier models at similar quality.
- Why it matters: Developers get strong help without breaking the budget or waiting too long.
- Better evaluation for real-world coding:
- CursorBench tasks require much larger code changes and provide shorter, less-specific prompts than public benchmarks.
- Why it matters: Scores on CursorBench tell you more about how a model will perform on real jobs.
5) What does this mean for the future?
- For developers:
- Coding assistants can now plan, debug, refactor, and ship features more reliably—especially in large codebases with fuzzy requirements.
- Faster, cheaper, and more accurate tools mean better productivity and fewer roadblocks.
- For AI training:
- A clear recipe emerges: give a model extra coding practice, then train it as an agent with realistic tools and rewards.
- Self-summarization and behavior shaping (like the length penalty) help models work across long, messy tasks.
- For evaluations:
- Real-world-style benchmarks like CursorBench can push the field toward measuring what actually matters to developers: not just correctness, but code quality, communication, latency, and interactive behavior.
In short, Composer 2 shows that a carefully trained, domain‑focused model can be both powerful and practical, helping engineers solve real problems faster and more reliably.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of the main uncertainties, missing details, and open problems left unresolved by the paper.
- Reproducibility of results: CursorBench is internal and not released; no public subset, task metadata, or scoring rubrics are provided, preventing independent replication and external validation.
- External validity: Tasks are drawn from the authors’ own engineering workflows and infrastructure; the degree to which performance transfers to different organizations, stacks, and tooling ecosystems (e.g., JetBrains, VS Code without Cursor, different CI/CD) is unknown.
- Cross-language generalization: The paper does not report per-language performance or coverage; capability across diverse languages (e.g., C/C++, Rust, Go, Java, C#, CUDA, mobile, data pipelines) and mixed-language codebases is unquantified.
- Real-world developer impact: No user study or field metrics (e.g., time-to-resolution, PR acceptance rate, code review outcomes, rework frequency) are reported to substantiate claims about “developer experience.”
- Public benchmark comparability: Results are reported “in our harness” for public benchmarks; the gap and fairness relative to official evaluation harnesses, and the effect of harness-specific tools/prompts, are not quantified.
- Confidence intervals and variance: Accuracy and efficiency metrics lack confidence intervals, seed variance analyses, or per-task variability, making it difficult to assess statistical significance.
- Reward design transparency: The exact composition and weights of reward components (correctness, succinctness, coding style, communication, tool penalties) are not specified, limiting reproducibility and interpretability.
- Length penalty specification: The nonlinear length penalty formula contains a typographical error and lacks parameter values, schedule, and ablations; its sensitivity and side effects (e.g., discouraging necessary exploration) are unknown.
- Auxiliary behavior rewards: No systematic ablations isolate the effect of auxiliary behavior rewards on efficiency, quality, or unintended behaviors (reward hacking, verbosity minimization at the expense of correctness).
- Self-summarization risks: While shown to reduce tokens, there is no error analysis of information loss, hallucination, or compounding errors from inaccurate summaries over long horizons.
- Long-context efficacy: Although the context window is extended to 256k, there are no task-level measurements of how often long-context vs self-summary is used, nor the accuracy/latency trade-off at different context lengths.
- Best-of-K vs average performance: The claim that both improve lacks supporting analysis of solution diversity, entropy, and trajectory coverage; it remains unclear whether improvements stem from new reasoning paths or reweighting existing ones.
- RL algorithm choices: The paper departs from standard GRPO variants (e.g., no length standardization, no overlong masking) without head-to-head ablations at scale; the generality of these choices remains open.
- KL regularization details: The choice of the k1 estimator is motivated by variance, but KL coefficients/schedules and comparative stability metrics vs k2/k3 in real tasks are not reported.
- Off-policy drift and asynchrony: Mid-rollout weight hotloading and asynchronous sampling can increase off-policy bias; the magnitude of policy lag, its effect on gradient variance, and corrective mechanisms (beyond router replay) lack quantitative analysis.
- Router replay “plausibility threshold”: The thresholding scheme for replacing replayed experts is not specified; its failure rate, effect on gradient noise, and sensitivity to routing sparsity remain unquantified.
- Sample efficiency and scaling laws: There is no analysis of RL sample efficiency, compute budgets, or scaling laws (beyond a small Qwen study) linking continued pretraining loss to RL outcomes at Composer 2 scale.
- Continued pretraining data: The code-dominant mix, sources, licensing, and filtering strategies are not described; contamination risks for public benchmarks and compliance implications remain uncertain.
- MTP layers and speculative decoding: The latency/throughput gains and potential quality trade-offs (e.g., distributional drift if MTP is trained from a mid-run checkpoint) are not measured on agent tasks.
- Safety and reliability: There is no assessment of risky actions (e.g., destructive commands, security vulnerabilities, data exfiltration), nor of guardrail effectiveness in the presence of web search and terminal tools.
- Robustness and adversarial settings: Robustness to flaky tests, nondeterministic tools, network failures, inconsistent environments, or adversarial codebases/logs is not evaluated.
- Tooling dependence: The agent relies on a specific tool set (grep/semantic search/web/terminal) and a Cursor-local harness; how performance degrades when tools are unavailable, slow, or swapped for alternatives is unreported.
- Interruptions and human-in-the-loop: Although an interruption evaluation is mentioned, no results or methods are provided; how the model adapts to mid-trajectory feedback and course corrections needs substantiation.
- Evolving benchmark drift: CursorBench evolves over time; there is no methodology to ensure comparability across iterations or prevent overfitting to internal evaluation distributions.
- Cost and efficiency accounting: Inference “cost” is shown without FLOPs or standardized hardware assumptions; the effect of active-parameter counts, MTP, and parallel tool usage on real-world cost/latency is not rigorously quantified.
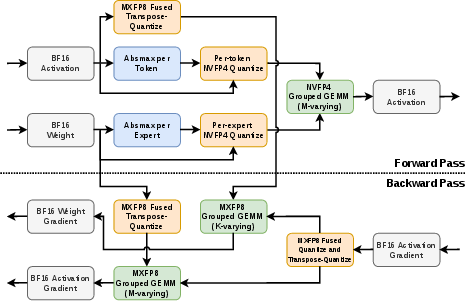
- Hardware assumptions: Training and kernels are specialized for NVIDIA Blackwell and custom low-precision formats (NVFP4/MXFP8); reproducibility on widely available hardware (A100/H100) and sensitivity to fast-math vs IEEE paths are unclear.
- Kernel-level stability: The necessity of IEEE-compliant ops for NVFP4 and tolerance to approximations for MXFP8 are noted but not generalized; limits and failure modes (e.g., divergence thresholds) are not systematically mapped.
- Data privacy and ethics: Use of production observability logs and internal codebases is discussed, but privacy protections, PII handling, and governance are not detailed.
- Generalization beyond monolithic repos: Many real projects span microservices/monorepos with heterogenous CI/CD and infra; how the agent scales across services, APIs, and deployment pipelines is not evaluated.
- Evaluation budget parity: Differences in sampling budgets, stop criteria, and tool parallelism across models in comparisons are not fully specified; fairness of cross-model comparisons remains uncertain.
- Failure mode taxonomy: The paper mentions emergent behavior (e.g., terminal-tool collapse) but does not present a systematic taxonomy of common failure modes or their frequencies post-mitigation.
- Licenses and model release: The base model (Kimi K2.5) and trained weights are not stated as being released; availability, licensing, and reproducibility for the research community are unclear.
- Open-source benchmarks: While internal metrics aim to reduce contamination, the lack of a publicly shareable benchmark that captures CursorBench’s properties limits community progress and comparability.
- Parameter and hyperparameter disclosure: Key RL hyperparameters (learning rates, KL coeffs, group size, sample counts, schedules) and SFT details are not provided, hindering reproducibility and ablation by others.
- Web search determinism: Training with web tools introduces non-deterministic content; the use of caching, snapshotting, or time-locked corpora to ensure consistent rewards is not described.
- Code quality and readability: Although rubrics exist internally, there is no public description or measurement methodology (e.g., Lint metrics, static analysis scores, human ratings) for code quality beyond correctness.
- Long-horizon credit assignment: How rewards are attributed across multi-turn trajectories and self-summary chains (beyond uniform application) is not analyzed; alternative credit assignment strategies remain unexplored.
- Security posture of environments: The paper describes Anygress/Anyrun controls but provides no empirical assessment of sandbox escapes, supply-chain risks, or side-channel attacks in training environments.
Practical Applications
Practical Applications Derived from the Composer 2 Technical Report
Below we summarize actionable, real-world applications that follow from the paper’s findings, methods, and infrastructure. We group them into what can be deployed now versus what likely requires further research, scaling, or productization.
Immediate Applications
These applications can be piloted or deployed today, assuming access to a modern LLM/agent harness with file/system tools, a secure execution environment, and standard development workflows.
- Bold, low-latency coding agent for real repositories (Software, DevTools)
- What: Use Composer 2–style agents to perform bug fixes, refactors, feature scaffolding, test generation, and repository navigation across large codebases.
- Why now: Proven long-horizon planning, self-summarization to manage huge contexts, and benchmark results competitive with frontier models at lower serving cost.
- Tools/workflows: IDE integration (Cursor-style harness), file read/edit tools, terminal, grep/semantic search, web search; parallel tool calls to speed “easy” tasks.
- Assumptions/dependencies: Access to a domain-specialized coding model and tool harness; developer review gates; repo permissions and CI hooks.
- Log-driven debugging and incident triage (Software, SRE/DevOps)
- What: Agents cross-reference terse bug reports and observability logs to locate root causes and produce minimal diffs (e.g., the esbuild transpilation bug case).
- Why now: Training distribution included real debugging tasks and sparse/ambiguous prompts; RL rewards tuned for correctness and minimal changes.
- Tools/workflows: Integration with log backends (Datadog, CloudWatch), local reproduction via terminal tool, patch proposal with tests.
- Assumptions/dependencies: Read-only access to logs or sanitized snapshots; sandboxed execution to reproduce issues.
- CI/CD assistants for failing builds and flaky tests (Software, DevOps)
- What: Automated diagnosis of failing builds and flaky tests; generation of candidate fixes and targeted tests; minimal, auditable code changes.
- Why now: RL policy handles multi-step execution and long-running tool use; rewards emphasize succinctness and engineering principles.
- Tools/workflows: CI pipeline hooks, pre-merge PR bots, test generation, best-of-K sampling with reranking.
- Assumptions/dependencies: Human-in-the-loop approval; clear revert/rollback mechanisms.
- Automated code review for quality and style (Software)
- What: Agent-enforced code quality checks, style consistency, and comment quality improvements; avoidance of “eager edits” when not appropriate.
- Why now: Auxiliary behavior rewards for communication and style; targeted “eager editing” and instruction-following evaluations.
- Tools/workflows: PR review comments, lint/format suggestions, documentation improvements, selective edit proposals.
- Assumptions/dependencies: Organizational style guides; reviewers retain final say.
- Large-scale refactoring and repository upgrades (Software, Platform)
- What: Coordinated, minimal-change refactors (API migrations, dependency upgrades), with tests authored where missing.
- Why now: CursorBench tasks require orders-of-magnitude larger diffs than public benchmarks; self-summarization improves long-horizon coherence.
- Tools/workflows: Repo-wide search and transformation, test scaffolding, staged PRs.
- Assumptions/dependencies: Adequate compute for multi-file analysis; regression test coverage; rollout plans.
- Secure agent execution at scale for untrusted code (Security, Platform)
- What: Deploy Anyrun-like isolation (Firecracker VMs) with granular egress control (Anygress) to safely run code, tests, and web calls by agents.
- Why now: The paper details this stack powering training and production (cloud agents and automations).
- Tools/workflows: Per-task VMs, snapshot/fork for mid-trajectory checkpoints and forensics, TCP-layer egress policy and CA injection.
- Assumptions/dependencies: Infrastructure engineering investment; network policy governance.
- Organization-specific, realistic evaluation suites (R&D, MLOps, Policy)
- What: Build a CursorBench-like internal benchmark drawn from real tasks to avoid contamination and over-specification, and capture multi-metric quality.
- Why now: Public benchmarks misalign in scope, contamination risk, and over-specification; CursorBench methodology addresses these gaps.
- Tools/workflows: Internal task curation, code-quality rubrics (not just correctness), cost/latency tracking, periodic refresh.
- Assumptions/dependencies: Access to representative internal tasks; processes for anonymization and safe replay.
- Token/latency-cost control via behavior shaping (Software, FinOps)
- What: Use concave nonlinear length penalties to incentivize rapid solutions on easy tasks while permitting deeper reasoning on hard ones.
- Why now: Demonstrated to learn efficient behaviors (parallel tool calls) without degrading hard-task performance.
- Tools/workflows: Reward shaping knobs tied to tokens, tool calls, turns; policy-level configuration per team/budget.
- Assumptions/dependencies: Ability to tune reward shaping or select from model variants trained under different penalties.
- Self-summarization for long-horizon tasks with limited context (Software, Data/ML)
- What: Insert self-generated summaries between steps to compress context while preserving key state and tool outputs.
- Why now: Shown to reduce error vs prompt compaction and improves throughput through KV cache reuse.
- Tools/workflows: Session memory management, summary checkpoints, replayable chains for audits.
- Assumptions/dependencies: Harness support for chaining generations and caching; acceptance of model-authored summaries.
- Efficient serving using Multi-Token Prediction (MTP) and speculative decoding (Infra, FinOps)
- What: Reduce latency and cost with MTP heads trained via self-distillation; deploy in production inference.
- Why now: MTP included and jointly trained in long-context and SFT phases.
- Tools/workflows: Speculative decoding stack, rollout of auxiliary heads, online A/Bs.
- Assumptions/dependencies: Inference engine support for speculative decoding; monitoring for rare error modes.
- MoE stability and reproducibility via router replay (R&D, Infra)
- What: Ensure training/inference expert routing consistency to stabilize policy gradients in MoE RL.
- Why now: Practical router replay with plausibility thresholds shown to reduce numerics mismatch.
- Tools/workflows: Inference engines that return per-token expert indices; trainer-side gating override.
- Assumptions/dependencies: Access/modification to inference engine internals; compatible MoE architectures.
- Low-precision, high-throughput training kernels (R&D, Hardware/Infra)
- What: Adopt MXFP8/NVFP4 kernels (with per-token scaling for NVFP4) to train and serve efficiently on NVIDIA Blackwell.
- Why now: Open-sourced kernel implementations via ThunderKittens; stability gains reported with precise math paths.
- Tools/workflows: Custom CUDA/PTX/ThunderKittens kernels; DeepEP for token dispatch; context parallelism (CP).
- Assumptions/dependencies: Availability of Blackwell GPUs; engineering expertise to integrate kernels.
- Distributed RL at scale with delta-based weight sync (R&D, Infra)
- What: World-scale asynchronous RL using S3-based delta-compressed weight sync and mid-rollout weight hotloading.
- Why now: Demonstrated training across regions with minimized staleness and bandwidth.
- Tools/workflows: Sharded uploads/downloads, fault-tolerant trainers, regional inference clusters.
- Assumptions/dependencies: Robust storage/network; orchestration and monitoring.
- Classroom and upskilling assistants for software engineering (Education)
- What: Guided, agentic tutorials where students pose open-ended tasks and the agent plans, executes, and explains edits.
- Why now: Strong instruction following, multi-step coding, and communication rewards can enhance pedagogy.
- Tools/workflows: Sandbox projects, step-by-step explanations, automated tests and rubrics.
- Assumptions/dependencies: Institution policy for AI use; oversight to prevent academic dishonesty.
- Energy/cost-efficient dev workflows (Cross-sector)
- What: Replace large general LLMs with domain-specialized coding agents for lower inference cost at similar or better quality.
- Why now: Reported Pareto efficiency on cost vs accuracy and token usage on CursorBench.
- Tools/workflows: Model routing (general vs specialized), cost dashboards, budget-aware prompting.
- Assumptions/dependencies: Task routing that recognizes coding tasks; governance over model selection.
Long-Term Applications
These opportunities likely require further research, product hardening, broader tooling adoption, or organizational change before widespread deployment.
- Semi-autonomous software pipelines (issue-to-PR-to-merge) (Software, DevOps)
- Vision: Agents take ownership of well-scoped issues, generate patches, run CI, solicit reviews, iterate on feedback, and land changes with policy gates.
- Path from paper: Long-horizon RL, self-summarization, minimal-diff behaviors, and multi-metric evaluation set the groundwork.
- Dependencies: Robust guardrails, provenance/tracing, formal verification or strong test coverage, organizational trust.
- Organization-specific agent training on private codebases (R&D, Enterprise IT)
- Vision: Continued pretraining + RL on private repos to learn domain idioms, internal APIs, and bespoke tooling.
- Path from paper: Two-stage training recipe and alignment of training with deployment harness.
- Dependencies: Data privacy, secure training environments, significant compute budgets, bespoke reward design.
- Standardized, contamination-resistant industry benchmarks (Policy, Standards, Academia)
- Vision: Sector-wide adoption of CursorBench-like design principles (real tasks, evolving suites, multi-metric scoring).
- Path from paper: Critique of public benchmarks and methodology to avoid over-specification and contamination.
- Dependencies: Community curation processes, legal/IP frameworks, reproducible harnesses.
- Agent governance for secure tool-use and egress (Policy, Security)
- Vision: Organizational policies and certifications around egress control, untrusted code execution, and agent audit trails.
- Path from paper: Anygress/Anyrun patterns and tool availability policies per environment.
- Dependencies: Regulatory guidance, vendor ecosystem support, SOC2/ISO-aligned controls for agents.
- Cross-domain agentic workflows beyond software (Data/ML, Science, Ops)
- Vision: The same long-horizon RL + self-summarization stack applied to experiment orchestration, data engineering pipelines, and analysis notebooks.
- Path from paper: Agents already run long jobs, monitor experiments, and manage multi-step tool calls.
- Dependencies: Domain-specific tools and rewards; higher stakes QA; dataset and metric design per domain.
- Numerics standards for MoE training/inference interoperability (Academia, Vendors)
- Vision: Cross-vendor agreements on router replay, gating telemetry, and precision schemes to reduce training/inference drift.
- Path from paper: Practical router replay and precision choices (k1 KL estimator, per-token NVFP4 scales).
- Dependencies: Shared APIs, open tooling, alignment among hardware/inference providers.
- Hardware-agnostic low-precision training and serving (Hardware, Cloud)
- Vision: Extend MXFP8/NVFP4-like efficiency gains to non-Blackwell hardware and multi-vendor ecosystems.
- Path from paper: Kernel innovations and quantization recipes that materially reduce cost/energy.
- Dependencies: Kernel porting, compiler/runtime support, validation at scale.
- Adaptive cost–quality contracts via learned behavior shaping (FinOps, Product)
- Vision: Policy-controlled length penalties and tool budgets that adapt to task difficulty and org budgets dynamically.
- Path from paper: Nonlinear length penalties improve efficiency without hurting hard tasks; best-of-K gains indicate broader sampling strategies.
- Dependencies: Real-time task difficulty estimation; robust feedback loops from users and CI outcomes.
- Continuous, live RL with production feedback (R&D, Product)
- Vision: Safely leverage anonymized production signals (e.g., PR approval rates, bug reopen rates) for on-policy updates.
- Path from paper: Asynchronous RL pipeline, online evaluation replicas mirroring production harness.
- Dependencies: Privacy-preserving data pipelines, careful reward design to avoid reward hacking, rollback strategies.
- Regulatory-grade auditability for agent actions (Policy, Compliance)
- Vision: End-to-end provenance of decisions, summaries, tool outputs, and diffs suitable for audits in regulated sectors (finance/healthcare).
- Path from paper: Rollout checkpointing, environment snapshotting/forking, and post-rollout state capture.
- Dependencies: Immutable logs, secure storage, integration with existing GRC tools.
- Autonomous refactoring for large monorepos with formal guarantees (Software, Research)
- Vision: Verified, semantics-preserving refactors at scale guided by agents, with proofs or certified tooling.
- Path from paper: Demonstrated capacity to modify 100s–1000s of lines with minimal diffs and test generation.
- Dependencies: Strong static analysis, formal methods integration, rich test or proof frameworks.
Notes on Assumptions and Dependencies (cross-cutting)
- Compute and hardware: Many training/inference optimizations assume access to modern GPUs (e.g., NVIDIA Blackwell), MoE-friendly inference engines, and kernel integration expertise.
- Harness fidelity: The training–deployment alignment (same toolset, execution environment) is key to observed performance; mismatches reduce transfer.
- Human oversight: Most immediate deployments should retain human-in-the-loop review gates, especially for production code changes.
- Data governance: Private codebases and logs require strict privacy and security controls for training and evaluation.
- Evaluation practices: Multi-metric evaluation (quality, latency, cost) and continual refresh (to avoid saturation/contamination) are essential for trustworthy performance claims.
Glossary
- AdamW optimizer: An optimization algorithm that decouples weight decay from the gradient update to improve generalization in deep learning. "Training was performed in MXFP8 on NVIDIA B300s using the AdamW optimizer."
- advantage: In policy gradient RL, a measure of how much better an action is compared to a baseline, used to reduce variance in gradient estimates. "minimize the bias in the gradients that can arise from transforming the underlying advantage."
- agentic software engineering: An approach where autonomous software agents perform complex engineering tasks (planning, coding, testing) with tools. "Composer 2 is a specialized model designed for agentic software engineering."
- Anygress: An internal egress-proxy service that mediates and sanitizes outbound network traffic from sandboxed environments. "Anygress, an internal service within Anyrun responsible for proxying traffic, enforcing granular request policies, and dropping sensitive headers."
- Anyrun: An internal compute platform for running untrusted code at scale in isolated, stateful development environments. "Anyrun, an internal compute platform built for running untrusted code at scale."
- BF16: A 16‑bit floating-point format (bfloat16) that preserves exponent range of FP32 with reduced mantissa for efficient training. "values are quantized from BF16 into FP4E2M1"
- best-of-K: An evaluation protocol/metric where the best result among K sampled outputs is reported, probing solution diversity and coverage. "we do not observe a tradeoff between average performance and best-of-K performance."
- block-scaled tensor-core matrix multiplications: Hardware-accelerated matrix multiplies that apply per-block scaling to quantized operands, enabling in-hardware dequantization. "We exclusively target NVIDIA Blackwell GPUs for block-scaled tensor-core matrix multiplications (i.e., in-hardware dequantization during systolic-array matrix multiplication)."
- Context Parallelism (CP): A parallelism strategy that shards the sequence/context dimension across devices to enable long-context training and inference. "Composer 2 instead uses Context Parallelism (CP) as the primary long-context scaling axis."
- cross-entropy loss: A standard predictive loss for language modeling that measures the negative log-likelihood of the correct token distribution. "demonstrating that cross-entropy loss is indeed predictive of downstream RL performance."
- delta compression: A synchronization technique that transmits only the differences between successive weight versions to reduce bandwidth. "we use delta compression: each rank caches its previous upload and transmits only the diff against the new weights."
- Dr. GRPO: A variant of GRPO (Group Relative Policy Optimization) that emphasizes de-biasing gradient estimates in group-based policy gradients. "As in Dr. GRPO~\cite{liu2025drgrpo}, we found that it is crucial to minimize the bias in the gradients that can arise from transforming the underlying advantage."
- Egress: Outbound network traffic leaving a controlled environment, typically restricted for security and reproducibility. "Egress is carefully controlled in environments to limit any external impact."
- Expert Parallelism (EP): Distributing Mixture‑of‑Experts weights/compute across devices to scale expert capacity efficiently. "Composer 2 also introduces a more flexible expert-parallel design by decoupling EP from TP."
- Firecracker VM: A lightweight virtual machine technology for secure, fast-booting microVMs suitable for multi-tenant, untrusted workloads. "Each pod is a dedicated Firecracker VM capable of running a full development environment, including a browser and GUI for computer use."
- Flash Attention 4: A highly optimized attention kernel (v4) that accelerates transformer attention, including efficient backward passes. "implement the Flash Attention 4 backward kernel"
- Fully Sharded Data Parallelism (FSDP): A data-parallel technique that shards model parameters, gradients, and optimizer states across workers to reduce memory. "Fully Sharded Data Parallelism (FSDP)"
- gating scores: The router outputs in MoE models that score experts for each token, determining expert selection and gradient flow. "The router still computes gating scores so that gradients flow through it."
- GRPO: Group Relative Policy Optimization, a policy gradient method using relative performance within groups of samples to shape updates. "we remove the length standardization term from GRPO as it introduces a length bias."
- grouped GEMM: Batch execution of multiple smaller matrix multiplies as a single grouped operation for higher GPU utilization. "a single grouped GEMM training flow"
- Kullback--Leibler divergence (KL): A measure of divergence between two probability distributions, often used as a regularizer to keep policies close to a reference. "we use a Kullback--Leibler divergence for regularization"
- KV cache: Cached key/value tensors from previous attention computations used to speed up autoregressive decoding. "reusing the KV cache."
- length penalty: A reward-shaping term that penalizes excessively long outputs to encourage concise solutions where appropriate. "we add a concave down and increasing nonlinear length penalty to the reward"
- Mixture-of-Experts (MoE): A model architecture where tokens are routed to a subset of specialized expert networks to increase capacity efficiently. "a 1.04T parameter / 32B active parameter Mixture-of-Experts model"
- Multi-Head Latent Attention (MLA): An attention architecture variant that operates via latent projections to improve efficiency in long-context settings. "in the Multi-Head Latent Attention (MLA) architecture."
- Multi-Token Prediction (MTP): Training auxiliary heads to predict multiple future tokens, enabling faster inference via speculative decoding. "train additional Multi-Token Prediction (MTP) layers"
- MXFP8: A mixed-format FP8 quantization scheme (e.g., FP8E4M3 with block scaling) used for efficient low-precision training/inference. "Training was performed in MXFP8 on NVIDIA B300s"
- NVFP4: NVIDIA’s 4-bit floating-point training/inference recipe that combines FP4 values with higher-precision scaling factors. "For the MoE forward pass, we use a novel variant of NVFP4"
- off-policy: Refers to samples generated by an older or different policy than the one being optimized, which can destabilize RL training. "it is crucial to minimize how off-policy the samples become."
- Pareto frontier: The set of solutions that optimally trade off multiple objectives (e.g., cost vs. accuracy) where no objective can be improved without worsening another. "Composer 2 achieves a superior Pareto frontier in cost"
- per-tensor scales: Quantization approach using a single scale factor for an entire tensor, reducing metadata but risking precision issues. "FP32 per-tensor scales"
- per-token scales: Quantization approach assigning a scale per token (or token block), improving numerical stability at the cost of overhead. "FP32 per-token scales."
- perplexity: The exponential of average negative log-likelihood; a standard metric of LLM uncertainty/fit. "The model undergoes a steady decrease in training perplexity."
- policy entropy: The entropy of a policy’s action distribution; higher entropy implies more exploration/diversity. "at the cost of policy entropy and output diversity"
- policy gradient algorithm: An RL method that directly estimates gradients of expected return with respect to policy parameters. "We use a policy gradient algorithm with multiple samples per prompt"
- router replay: A technique to replay and enforce MoE expert selections from inference during training to reduce policy mismatch. "we employ router replay \cite{zheng2025gspo, ma2025routerreplay}:"
- self-distillation: Training a model to match its own teacher outputs/logit distributions to stabilize and accelerate learning. "we train the MTP layers with self-distillation"
- self-summarization: An agentic technique where the model writes and consumes its own summaries to manage long-horizon context. "we use the self-summarization technique introduced in Composer 1.5"
- sequence packing: An algorithmic step that packs variable-length sequences into balanced batches to equalize compute across data-parallel ranks. "we run a global sequence packing stage"
- single-epoch regime: A training regime where each prompt/sample is seen only once, avoiding repeated exposure during RL. "We operate in the single-epoch regime"
- speculative decoding: An inference acceleration method that drafts multiple tokens ahead and verifies/corrects them with the main model. "to use with speculative decoding."
- SFT: Supervised fine-tuning on curated, labeled examples to steer model behavior prior to or alongside RL. "and finally a short SFT phase on targeted coding tasks."
- Tensor Parallelism (TP): Splitting tensor dimensions of model layers across devices to parallelize large matrix multiplications. "Tensor Parallelism (TP)~\cite{shoeybi2019megatron}"
- top-: Selecting the k highest-scoring items (e.g., experts or tokens) from a distribution. "top- selections"
- variance blow-up: A phenomenon where an estimator’s variance grows rapidly as distributions diverge, causing instability. "The estimator does not suffer from variance blow-up, but is biased."
- weight synchronization: Regularly syncing updated model weights from training to inference workers to reduce policy staleness. "fast weight synchronization"
Collections
Sign up for free to add this paper to one or more collections.