- The paper presents an actor-critic framework that leverages vision-language models to generate interactable 3D digital twins with a 75% joint prediction success rate.
- The paper details a three-stage pipeline—mesh retrieval, link placement, and joint prediction—which iteratively refines outputs via critic feedback for enhanced accuracy.
- The paper demonstrates practical applications in simulation and robotics, significantly reducing manual annotation time while enabling successful real-world robotic manipulation.
Articulate-Anything: Automatic Modeling of Articulated Objects via a Vision-Language Foundation Model
Introduction and Motivation
Articulate-Anything introduces a vision-language agentic system for automatic modeling of articulated objects from diverse input modalities, including text, images, and videos. The motivation stems from the scarcity of articulated 3D assets in open repositories, which impedes scalable simulation and robotics research. While static 3D object datasets such as Objaverse contain millions of assets, articulated datasets like PartNet-Mobility are limited to a few thousand objects due to the labor-intensive manual annotation process. Articulate-Anything addresses this bottleneck by leveraging foundation vision-LLMs (VLMs) to automate the articulation process, enabling the generation of interactable digital twins suitable for simulation, animation, and robotic manipulation.
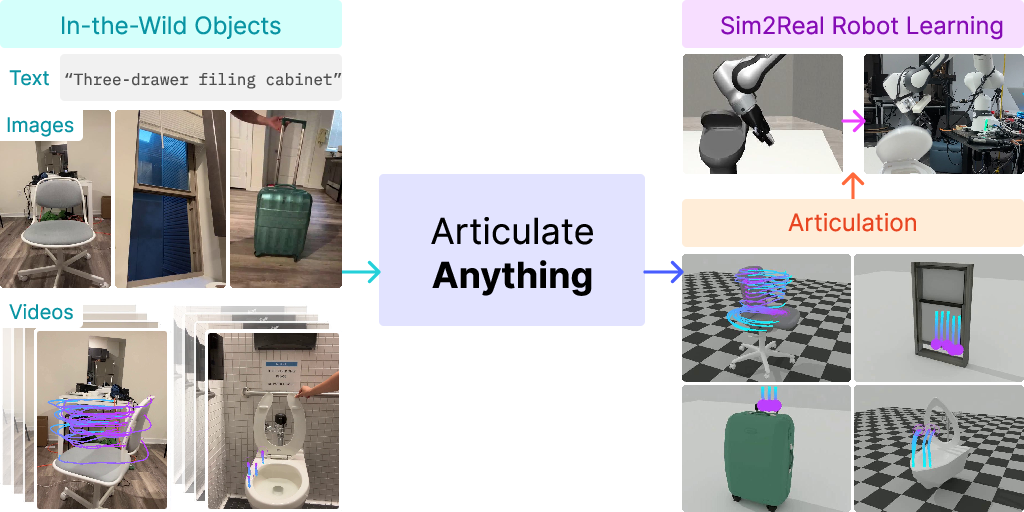
Figure 1: Articulate-Anything generates 3D interactable digital twins from text, images, or videos, supporting a wide range of objects and affordances.
System Architecture
Articulate-Anything operates in three sequential stages: mesh retrieval, link placement, and joint prediction. The system is built around an actor-critic paradigm, where both actor and critic are instantiated as VLM agents (Gemini Flash-1.5). The actor synthesizes high-level Python code, which is compiled into URDFs, while the critic evaluates the rendered predictions and provides feedback for iterative refinement.
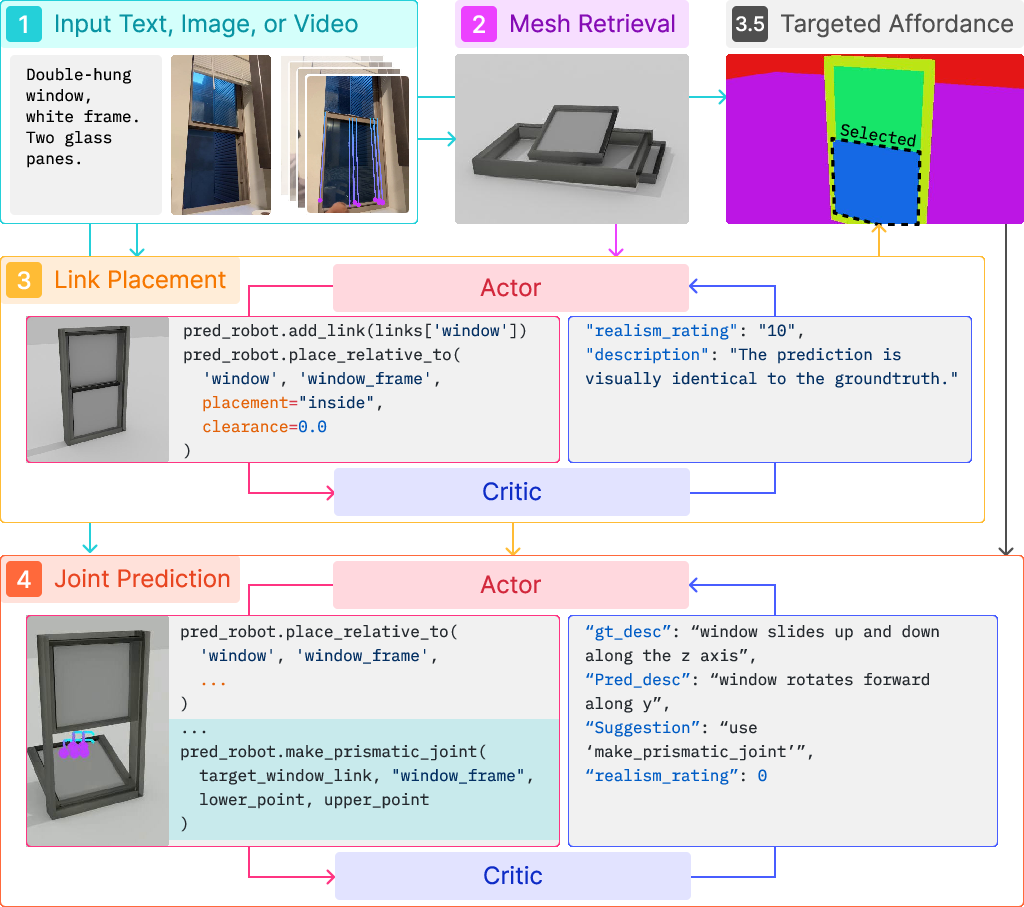
Figure 2: Overview of the three-stage pipeline: mesh retrieval, link placement, and joint prediction, with actor-critic feedback loops.
Mesh Retrieval
Mesh retrieval is modality-dependent. For visual inputs, the system matches the input object to a template in the asset library using CLIP similarity and a hierarchical divide-and-conquer selection. For text inputs, an LLM predicts object parts and dimensions, retrieves meshes via CLIP embeddings, and scales them accordingly. This approach exploits large static asset libraries while enabling semantic customization.

Figure 3: Mesh retrieval mechanisms for visual and textual inputs, leveraging CLIP similarity and LLM-based part specification.
Link Placement
The link placement module arranges object parts in 3D space. The actor aligns child and parent link centers, performing collision checks to ensure physically plausible placement. The critic compares the rendered model to the input (image or video), assigns a realism rating, and pinpoints errors in the actor's code. Iterative refinement continues until the realism rating exceeds a threshold.
Joint Prediction
Joint prediction extends the Python code to specify kinematic joints between parts. For video inputs, the critic compares the predicted joint motion to the input video, categorizes errors (joint type, axis, origin, limit), and provides feedback. The actor iteratively refines the code based on critic feedback, improving articulation accuracy.

Figure 4: Actor-critic loop for link placement and joint prediction, enabling self-correction and robust articulation.
Quantitative and Qualitative Evaluation
Articulate-Anything is evaluated on the PartNet-Mobility dataset, reconstructing masked URDFs from input modalities. Success rates are measured for link placement and joint prediction, with stringent thresholds on pose and kinematic parameters. The system is benchmarked against URDFormer and Real2Code, both limited to a handful of object categories and impoverished input modalities.
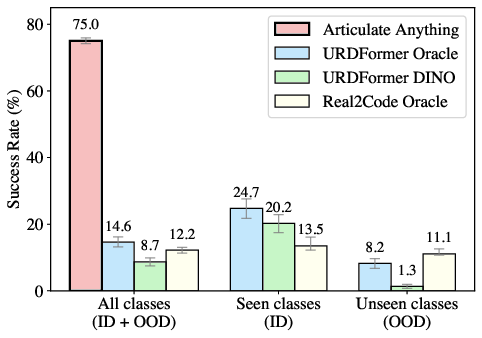
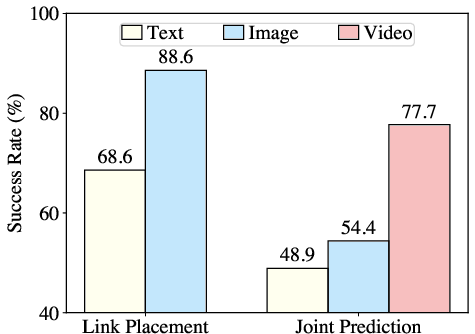
Figure 5: Articulate-Anything significantly outperforms baselines in joint prediction across all object classes.
Articulate-Anything achieves a joint prediction success rate of 75%, compared to 8.7–12.2% for prior work. The system is robust to both in-distribution and out-of-distribution object categories, and its performance improves with richer input modalities (video > image > text).

Figure 6: In-the-wild reconstruction results demonstrate superior performance and ambiguity resolution compared to baselines.
Error Analysis and Iterative Refinement
Failure analysis reveals that baseline methods suffer from invalid outputs (cyclic structures, repeated links, syntax errors) and are sensitive to segmentation inaccuracies. Articulate-Anything's actor-critic loop enables iterative self-improvement, yielding a 5.8% and 2.4% accuracy gain for link placement and joint prediction, respectively.
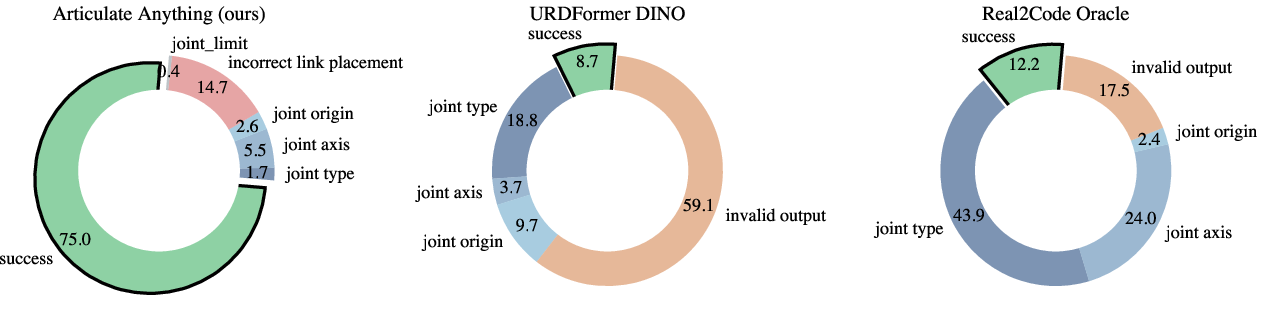
Figure 7: Breakdown of failure percentages across all classes, highlighting the robustness of Articulate-Anything.
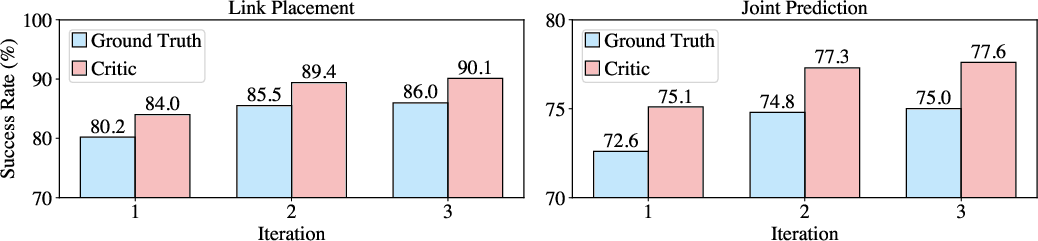
Figure 8: Iterative improvement via critic feedback, with strong correlation between critic and ground-truth evaluations.
In-Context Learning and Model Robustness
The system demonstrates in-context learning, with success rates increasing as the number of prompting examples grows. Articulate-Anything is robust to the choice of base VLM, maintaining high performance across architectures.
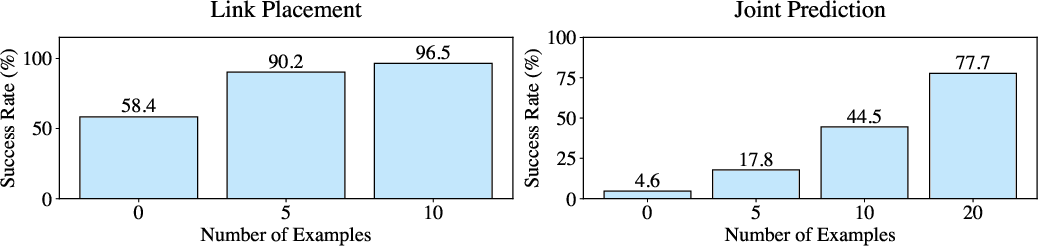
Figure 9: In-context learning: performance improves with more prompting examples.
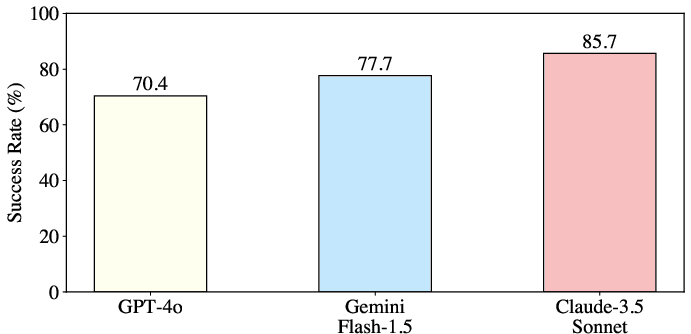
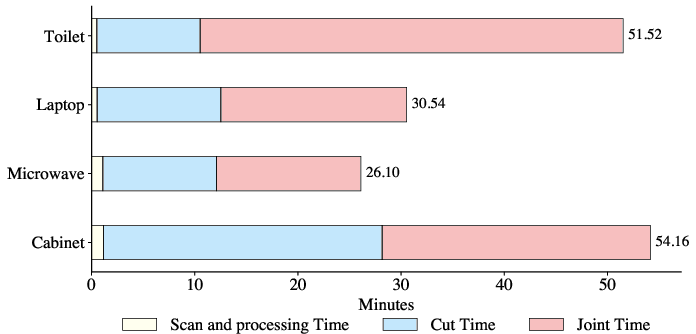
Figure 10: Robustness to different VLMs, with consistently high success rates.
Application to Robotic Manipulation
Articulate-Anything-generated assets are used to train RL policies for fine-grained manipulation tasks in simulation (Robosuite, PPO), which are then deployed on a real Franka Panda arm. Both automatically and manually annotated assets yield 100% real-world success, but Articulate-Anything reduces human annotation time by an average of 40.58 minutes per task.

Figure 11: Robotic application: policies trained on Articulate-Anything assets transfer successfully to real hardware.
Mesh Generation and Customization
While the current system relies on mesh retrieval, integration with mesh generation models (Rodin, InstantMesh, Stable-Fast-3D) enables the creation of high-quality, customized articulated objects. Grounded SAM is used for part segmentation, and projective geometry lifts 2D masks to 3D segmentation.





Figure 12: Articulate-Anything integrated with mesh generation models for high-quality articulated object synthesis.

Figure 13: Comparison of mesh generation quality across different models from a single source image.
Articulate-Anything achieves the lowest average joint type, axis, and origin errors among all evaluated methods. Chamfer distance metrics for mesh reconstruction are also superior, both in retrieval and generation settings. The system generalizes well to unseen object categories and casual, cluttered inputs.
Limitations and Future Directions
The reliance on mesh retrieval constrains asset customization. Integrating upstream mesh generation models will broaden generality and enable more diverse applications. Further optimization of segmentation and articulation for small or irregular parts is warranted. The actor-critic framework could be extended to other domains requiring program synthesis and iterative refinement.
Conclusion
Articulate-Anything presents a scalable, vision-language agentic system for automatic modeling of articulated objects from multimodal inputs. By reframing articulation as program synthesis and leveraging iterative actor-critic refinement, the system sets a new state-of-the-art in automatic articulation accuracy and generalizability. The practical implications span simulation, animation, AR/VR, and robotics, with substantial reductions in manual labor and increased accessibility for 3D content creation. Future work will focus on tighter integration with generative mesh models and further expansion of input modalities and downstream applications.

