- The paper presents MDiff4STR, a novel framework that applies mask diffusion models to elevate scene text recognition accuracy and inference speed.
- It introduces six mask corruption strategies and a token-replacement noise mechanism to mitigate the noising gap and correct overconfident errors.
- Experimental results demonstrate significant improvements in handling occluded, artistic, and multilingual text with up to 97.3% accuracy on English benchmarks.
Mask Diffusion Models for Scene Text Recognition: A Comprehensive Analysis of MDiff4STR
Introduction
Scene Text Recognition (STR) poses distinct challenges for vision-LLMs due to the presence of irregular, occluded, distorted, and artistic text within natural scenes. Traditional frameworks predominantly utilize Auto-Regressive Models (ARMs), which offer robust unidirectional linguistic modeling yet suffer from inefficient sequential decoding. Recently, Mask Diffusion Models (MDMs)—non-autoregressive architectures built on iterative masked token denoising—have shown substantial promise in vision-language tasks. The MDiff4STR framework introduces MDMs into STR for the first time, proposing technical solutions that bridge the gap in recognition accuracy while leveraging the efficiency afforded by parallel and adaptive denoising strategies.
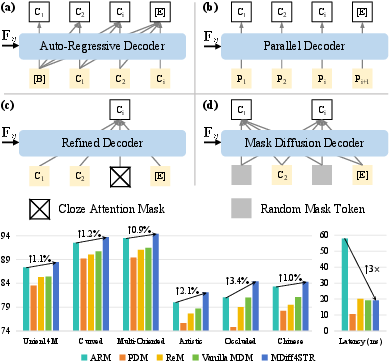
Figure 1: Architectural paradigms for STR—(a) ARMs, (b) PDMs, (c) BERT-like ReMs, (d) MDMs.
Mask Diffusion Modeling and Its Integration into STR
MDMs reconstruct target character sequences through iterative denoising from masked inputs, inherently enabling omnidirectional contextual reasoning. Unlike ARMs and BERT-like ReMs (bidirectional refiners), MDMs can capture dependencies from arbitrary positions, not restricted by sequential or left-right context.
MDiff4STR leverages the SVTRv2 visual encoder and a mask diffusion decoder. The denoising process is executed for K steps, starting from a fully masked token sequence and progressively remasking uncertain or incorrect tokens based on confidence heuristics. This architecture efficiently balances accuracy and inference speed.
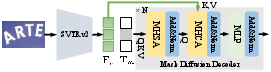
Figure 2: The MDiff4STR architecture: visual encoding and mask-based denoising pipeline.
Technical Innovations in MDiff4STR
1. Noising Gap Mitigation
A major challenge in applying MDMs to STR is the “noising gap”—the discrepancy between randomized masking in training and structured masking in inference. Standard random masking fails to simulate the inference remasking strategies, degrading generalization.
MDiff4STR introduces six specific mask corruption strategies spanning full, random, forward or backward AR-like, refinement, and confidence-guided remasking. These strategies are uniformly sampled during training, aligning training with inference behaviors and substantially improving robustness in challenging scene conditions.
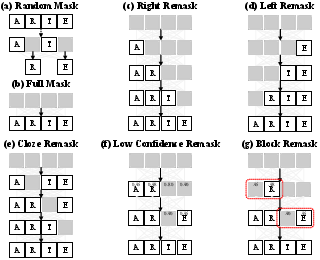
Figure 3: Masking and remasking strategies for training and inference; detailed mechanisms to eliminate the noising gap.
2. Token-Replacement Noise Mechanism
MDMs are susceptible to overconfident mispredictions—where incorrect tokens are assigned high confidence, thus escaping remasking and correction. The proposed token-replacement noise mechanism introduces random substitutions (non-[MASK] noise) during training, explicitly teaching the model corrective reasoning for erroneous high-confidence tokens. This increases the model’s ability to revise earlier predictions, enabling robust post-hoc error correction during the denoising cycle.
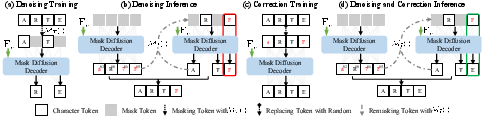
Figure 4: Comparison of vanilla denoising, inference, error-correction training (token-replacement), and augmented denoising in MDiff4STR.
The total training objective combines both denoising and correction losses: masked tokens are supervised for reconstruction, while the entire sequence receives correction supervision for randomly replaced tokens, enforcing global error correction capability.
Decoding Paradigms and Omnidirectional Contextual Reasoning
MDiff4STR supports and generalizes multiple decoding paradigms:
- Auto-Regressive Decoding (AR): Emulated via forward remasking.
- Parallel Decoding (PD): One-step denoising from fully masked input.
- BERT-like Refinement (Re): Iterative bidirectional refinement using partial masking.
- Low-Confidence Remask (LC): Iterative remasking of low-confidence tokens.
- Block Low-Confidence Remask (BLC): Remasking within fixed-size blocks, mitigating trap effects in confidence-based remasking.
LC and BLC paradigms are novel to MDM-based STR, capitalizing on omnidirectional masking capabilities for adaptive denoising and correction.
Experimental Evaluation and Numerical Results
MDiff4STR is extensively validated on diverse test suites covering regular, irregular, occluded (OST), artistic, and Chinese text scenarios. Key findings include:
Pretraining on synthetic datasets further boosts performance, with pretraining-fine-tuned models achieving 98.02% on common English benchmarks and 87.4% on OST, exceeding even models with multimodal or vision-language pretraining.
Practical and Theoretical Implications
MDiff4STR advances the STR modeling paradigm by:
- Unifying diverse decoding strategies under a single omnidirectional framework.
- Surpassing ARMs and ReMs in both accuracy and efficiency, especially in scenarios with heavy occlusion or artistic distortion.
- Enabling robust revision of overconfident errors, which traditional architectures cannot efficiently rectify.
- Demonstrating adaptability to large character sets and multilingual recognition—crucial for practical OCR deployments beyond Latin scripts.
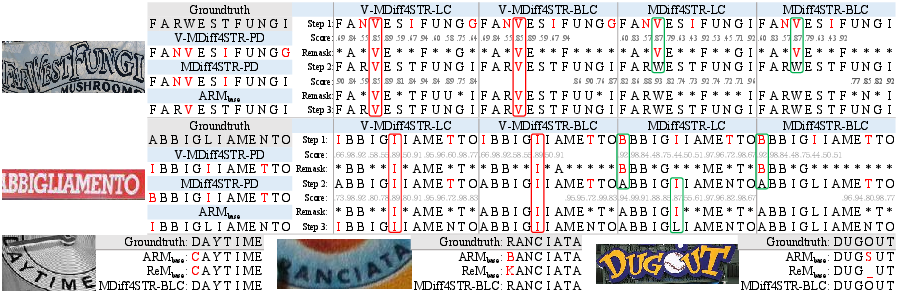
A key limitation is the current lack of explicit mechanisms for token insertion and removal, as highlighted in redundant/missing character cases (Figure 6).

Figure 6: Bad cases—MDiff4STR's inability to handle sequence insertions/deletions due to deterministic masking.
Future research directions include integrating flexible sequence-length adjustment operations into the MDM framework and extending omnidirectional reasoning for open-vocabulary and multimodal tasks.
Conclusion
MDiff4STR marks the first integration of Mask Diffusion Models into the STR domain, proposing rigorously engineered noising and correction mechanisms that bridge accuracy-efficiency trade-offs. Experimental evidence strongly supports the efficacy of omnidirectional language modeling, confidence-based adaptive decoding, and error correction for scene text recognition. The methodology sets a benchmark for further theoretical studies and practical deployments in OCR, vision-language modeling, and potentially multimodal generative systems.
(2512.01422)