- The paper presents CORGI, a novel benchmark tailored for business intelligence that evaluates LLMs on descriptive, explanatory, predictive, and recommendational queries.
- It implements a multi-agent evaluation framework with a discriminator and seven scoring agents to assess SQL query performance across multiple dimensions.
- The study reveals that current LLMs struggle with complex BI tasks, with SQL execution success rates significantly lower than those on simpler text-to-SQL benchmarks.
Agent Bain vs. Agent McKinsey: A New Text-to-SQL Benchmark for the Business Domain
Introduction and Motivation
Text-to-SQL systems, which translate natural language inputs into SQL queries, have emerged as critical tools for bridging the gap between human language and structured data access, especially in data-driven industries like business intelligence (BI). Despite the rapid advancements in LLMs, existing benchmarks predominantly focus on data retrieval capabilities, overlooking complex real-world BI scenarios that demand causal reasoning, temporal forecasting, and strategic recommendations. The CORGI benchmark addresses this gap by introducing a realistic evaluation framework for business applications, highlighting the challenges and opportunities for leveraging LLMs in these contexts.
CORGI Benchmark Design
The CORGI benchmark is a meticulously crafted evaluation framework comprising synthetic databases inspired by real-world enterprises such as Doordash, Airbnb, and Lululemon. It focuses on four key categories of business queries: descriptive, explanatory, predictive, and recommendational. Each category is designed to incrementally challenge LLM capabilities, moving from straightforward data extraction to intricate strategic planning and forecasting, thus simulating multi-step decision-making processes typical in business scenarios.
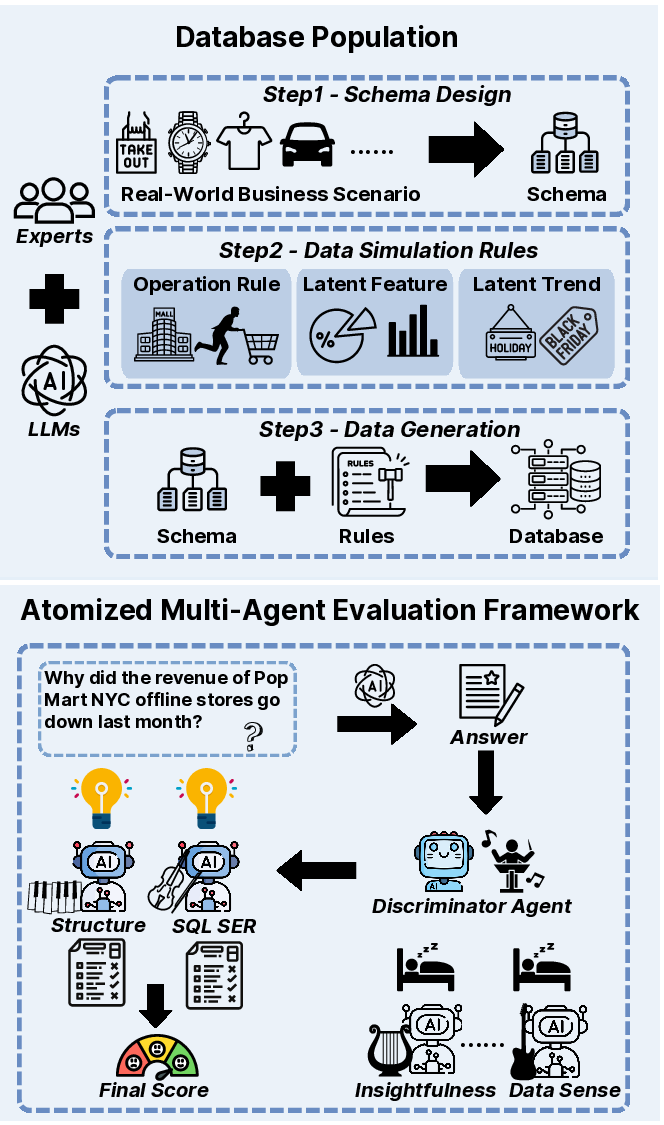
Figure 1: We incorporate business logic into our synthesized database population process, and propose a multi-agent evaluation framework consisting of a discriminator agent and seven scoring agents.
Evaluation Framework
The proposed evaluation framework utilizes a multi-agent, business literature-inspired approach. A discriminator agent first selects relevant scoring metrics, which are then processed by seven specialized scoring agents. These agents evaluate responses on dimensions such as structure, SQL execution success rate (SER), data sense, insightfulness, operational implementability, purpose alignment, and compliance, thereby ensuring a comprehensive assessment of LLM-generated outputs.
Experimental Findings
Preliminary experiments with leading LLMs reveal their struggle on complex explanatory, predictive, and recommendational tasks. The average SQL SER for high-level queries like type 2, type 3, and type 4 is reported at 67.8%, 57.4%, and 74.5%, respectively, significantly lower than simpler text-to-SQL benchmarks such as BIRD with an 88.0% success rate.
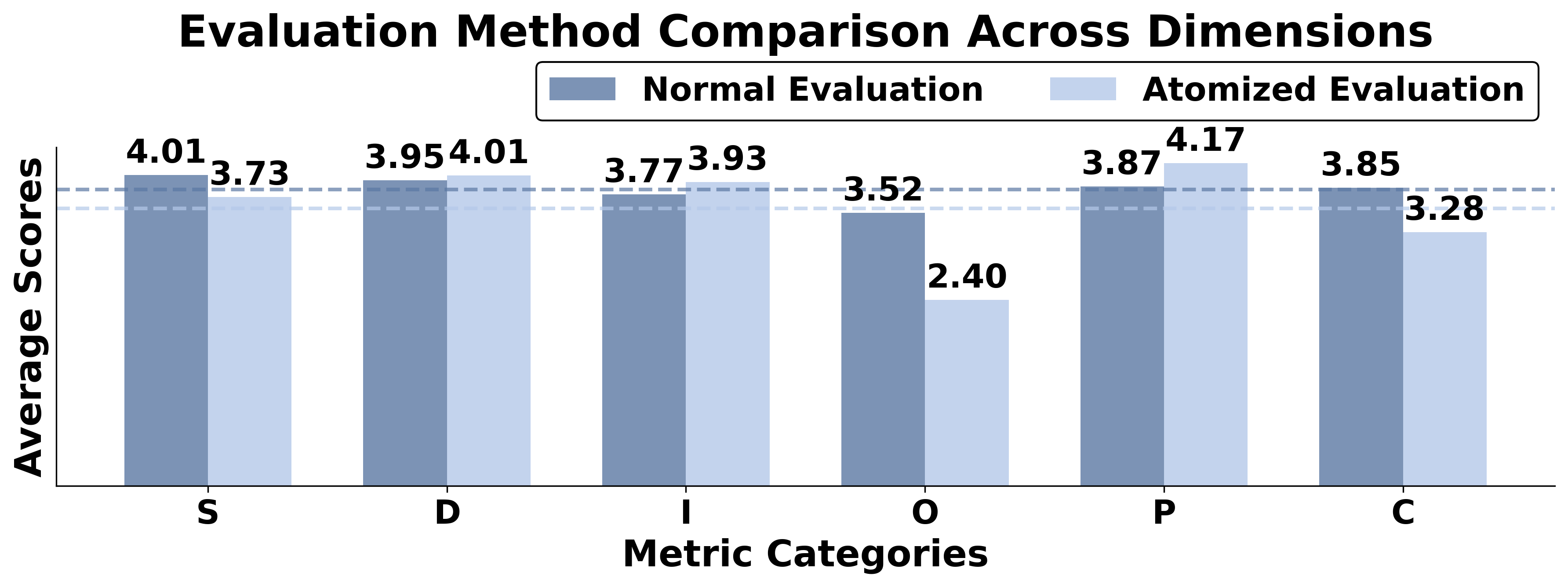
Figure 2: Comparison between our proposed atomized multi-agent evaluation mechanism and single LLM evaluation. S: Structure, D: Data Sense, I: Insightfulness, O: Operation Implementability, P: Purpose Alignment, C: Compliance. The dashed lines indicate overall average scores.
Implications and Future Directions
The CORGI benchmark underscores the gap between current LLM capabilities and the requirements of profound BI applications. LLMs exhibit substantial declines in performance when tasked with higher complexity business queries, highlighting open challenges for research into models that can incorporate strategic alignment and judgment under uncertainty.
As business applications increasingly depend on automating decision-making and strategy formulation, future research should explore extending LLM capabilities to better simulate real-world consultancy tasks. Enhancements might include developing models that integrate external knowledge bases, refine causal reasoning abilities, and apply domain-specific fine-tuning to address the nuances in complex BI scenarios.
Conclusion
The introduction of the CORGI benchmark represents a significant step towards evaluating and improving LLMs in the dynamic and demanding field of business intelligence. By aligning benchmark design with real-world business objectives and challenges, CORGI seeks to encourage advancements that will enable AI systems to deliver actionable insights, strategic recommendations, and foresight, thus bridging the gap between academic advances in text-to-SQL research and practical applications in business consulting.
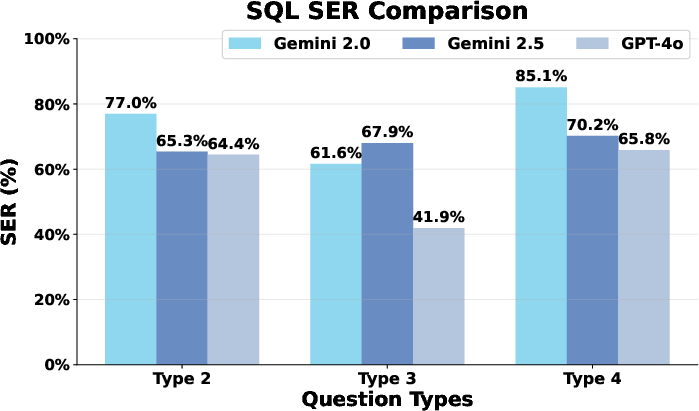
Figure 3: LLMs SQL Query Execution Performance Comparison Across Question Types.

