- The paper introduces Legi-Val as a novel framework to quantify trace legibility in AI models by focusing on efficiency and transfer utility.
- It employs metrics such as token length, redundancy, and backtracking to assess both the conciseness and the pedagogical effectiveness of reasoning traces.
- Empirical findings reveal an accuracy-legibility paradox where high-performing models often produce less teachable reasoning traces.
Measuring the Legibility of Reasoning Traces in LLMs
Introduction
The ability of LLMs to generate multi-step reasoning traces has become central to scalable oversight, auditability, and capability distillation in modern AI systems. However, metrics and protocols for quantifying the legibility of such reasoning traces, especially for weak verifiers or downstream students, remain undercharacterized. The paper "Measuring Reasoning Trace Legibility: Can Those Who Understand Teach?" (2603.20508) rigorously defines, decomposes, and benchmarks legibility in reasoning LLMs (RLMs), proposing new metrics and uncovering unexpected trade-offs between model performance and trace accessibility.
Legi-Val: A Framework for Quantitative Legibility Assessment
Legi-Val is introduced as a unified framework that operationalizes reasoning trace legibility across two axes: (1) Efficiency, capturing length, redundancy, and strategy backtracking, and (2) Transfer Utility, quantifying how well reasoning traces scaffold weaker models towards correct answers as the trace is incrementally revealed.
Legi-Val runs large-scale evaluations across 99,528 traces from 12 open RLMs over three diverse datasets (MATH, GPQA, Connections). It produces a comprehensive multi-metric ranking that exposes varying legibility profiles and provides actionable measurements for reward modeling and RL training.

Figure 1: The Legi-Val pipeline: trace elicitation, efficiency analysis (length, redundancy, backtracking), and transfer utility via rollouts to student models.
Efficiency Metrics: Concision, Redundancy, Backtracking
Efficiency-based legibility metrics are grounded in empirical findings from cognitive science. The core metrics are:
- Length: The (normalized) number of tokens/steps in a trace, with concision as the desideratum.
- Redundancy: The ratio of semantically redundant steps, computed using MiniLM embeddings with thresholded cosine similarity.
- Backtracking: The fraction of steps labeled as exploration or revision, detected using LLM judges with domain-specific rubrics.
These metrics collectively measure how far traces deviate from the minimal informative path. However, compression can be pathological—a trace "the answer is 5" is maximally concise yet useless as an explanatory artifact.
Transfer Utility: Pedagogical Fitness of Reasoning Traces
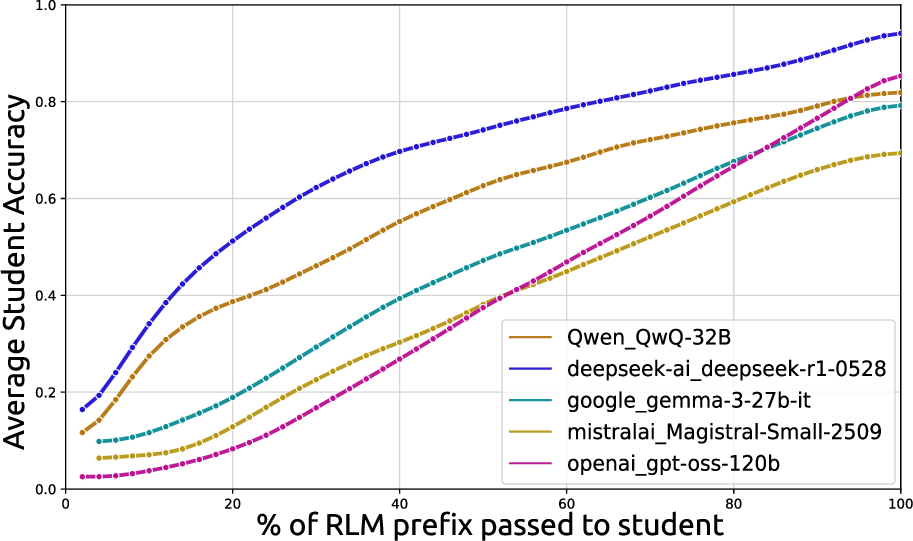
To resolve the limitations of efficiency metrics, the transfer utility (TU) suite assesses the multi-agent value of a trace: does exposing additional steps help a weaker student model converge on the correct answer? This is operationalized by prefix-rolling out traces and measuring student accuracy as a function of revealed reasoning. Legi-Val defines:
Importantly, TU metrics measure utility for both correct and “near-miss” traces, revealing whether reasoning is genuinely legible or simply outcome-optimized.
Empirical Findings: An Accuracy-Legibility Paradox and the Legibility Pareto Frontier
Analysis yields several robust and, at times, contradictory findings:
The highest-accuracy models (e.g., GPT-OSS-120B, DeepSeek-R1) consistently rank poorly on transfer-based legibility metrics, while the lowest-performing LLaMA-Nano is among the most pedagogically effective under FOTU. This exposes an accuracy-legibility paradox: current SOTA RLMs optimize for compressive, outcome-oriented reasoning, which is pedagogically opaque to weaker agents.
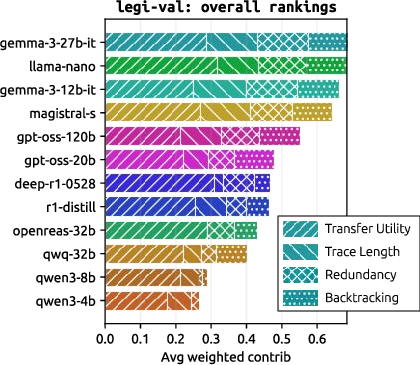
Figure 3: Model-level rankings over Legi-Val axes highlight divergent profiles: no model leads all legibility metrics; high-accuracy models often have poor transfer utility.
Distinct model “families” exhibit consistent profiles—Gemma models are highly efficient but pedagogically weak; DeepSeek and OpenReasoning models are verbose but excel in transfer and scaffolding utility.
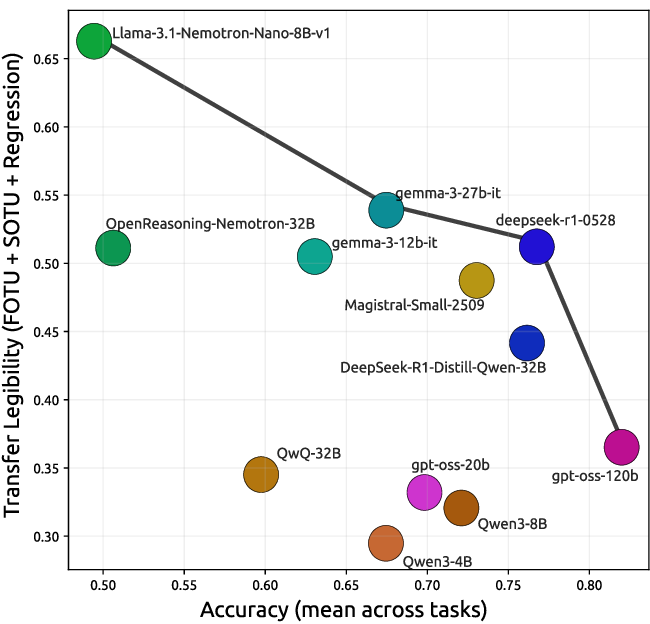
Figure 4: Trade-off between answer accuracy and transfer utility: models cluster by family, revealing a Pareto frontier between efficiency and pedagogical value.
No Universal Legible Reasoner
No single RLM dominates all legibility dimensions. Instead, models populate a Pareto frontier: improving conciseness generally reduces teachability, and vice versa. This is not merely an artifact of random post-training, but an intrinsic trade-off surfaced by Legi-Val.
Reward Models and Optimization Blind Spots
Scalar reward models used for RL-finetuning do not intrinsically optimize for legibility as measured by TU metrics. Correlations between reward scores and transfer utility vanish when controlling for correctness, indicating that legibility is not simply a by-product of standard reward-driven optimization.
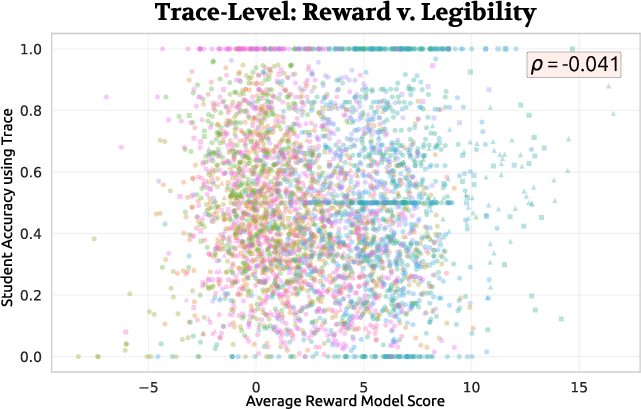
Figure 5: Trace-level scatter of reward model scores vs. first-order transfer utility—highlighting minimal direct association between reward-based optimization and pedagogical legibility.
Task and Domain Dependency
Legibility rankings are task-sensitive. Reasoning styles that scaffold student models in STEM (MATH, GPQA) do not transfer reliably to open-ended puzzles (Connections), and vice versa. SOTU (uniform information distribution) is more stable across domains than FOTU, suggesting domain-invariant characteristics in what makes a trace incrementally helpful.
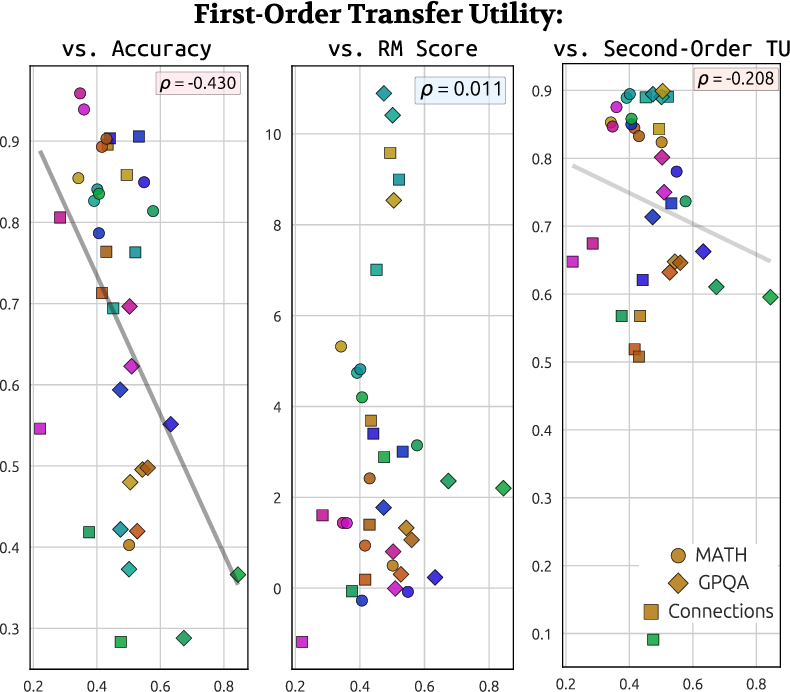
Figure 6: Joint analysis of transfer utility, reward, and accuracy across models and datasets confirms complex, multidimensional trade-offs.
Theoretical and Practical Implications
Legi-Val crystallizes two emergent realities:
- Multi-Objective RL for Reasoning: Existing RLVR procedures optimize for final answer correctness but neglect the role of reasoning traces as first-class artifacts, critical for auditability, scalable oversight, distillation, and compositional reuse. Training pipelines must introduce explicit reward signals aligned with both efficiency and transfer utility, potentially via multi-objective RL or direct inclusion of weak verifiers during rollout sampling.
- Scalable Oversight and Multi-Agent Supervision: As models approach and outperform human verifiers, legible (teachable, auditable) reasoning traces become vital for safe deployment and capability distillation. The accuracy-legibility decoupling documented here demonstrates that correctness alone is an insufficient metric for scientific/engineering progress in reasoning modeling.
- Limitations and Future Work: The framework’s current deployment is limited to in-context, inference-time rollouts (not full student distillation), employs LLM judges for some metrics, and has limited direct comparability with human cognitive load. Future extensions should address legibility as an explicit RL target, human-validated cognitive correspondence, domain-adaptive reward tuning, and transfer utility as a metric of SFT/RL student learning, not just single-shot rollout.
Conclusion
Legi-Val provides a unified, scalable methodology for decomposing and benchmarking the legibility of RLM reasoning traces. Major empirical results include a documented anti-correlation between correctness and teachability, demonstration of a multi-objective Pareto frontier, and the finding that prevailing reward models fail to incentivize legibility beyond correctness. As multi-agent and agent–human regulatory protocols are adopted, the metrics in Legi-Val are poised to inform future RL algorithms, reward modeling approaches, and scalable oversight protocols in advanced reasoning systems.
References
The essay above is based on and closely summarizes "Measuring Reasoning Trace Legibility: Can Those Who Understand Teach?" (2603.20508).