AI Agents Can Already Autonomously Perform Experimental High Energy Physics
Abstract: LLM-based AI agents are now able to autonomously execute substantial portions of a high energy physics (HEP) analysis pipeline with minimal expert-curated input. Given access to a HEP dataset, an execution framework, and a corpus of prior experimental literature, we find that Claude Code succeeds in automating all stages of a typical analysis: event selection, background estimation, uncertainty quantification, statistical inference, and paper drafting. We argue that the experimental HEP community is underestimating the current capabilities of these systems, and that most proposed agentic workflows are too narrowly scoped or scaffolded to specific analysis structures. We present a proof-of-concept framework, Just Furnish Context (JFC), that integrates autonomous analysis agents with literature-based knowledge retrieval and multi-agent review, and show that this is sufficient to plan, execute, and document a credible high energy physics analysis. We demonstrate this by conducting analyses on open data from ALEPH, DELPHI, and CMS to perform electroweak, QCD, and Higgs boson measurements. Rather than replacing physicists, these tools promise to offload the repetitive technical burden of analysis code development, freeing researchers to focus on physics insight, truly novel method development, and rigorous validation. Given these developments, we advocate for new strategies for how the community trains students, organizes analysis efforts, and allocates human expertise.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
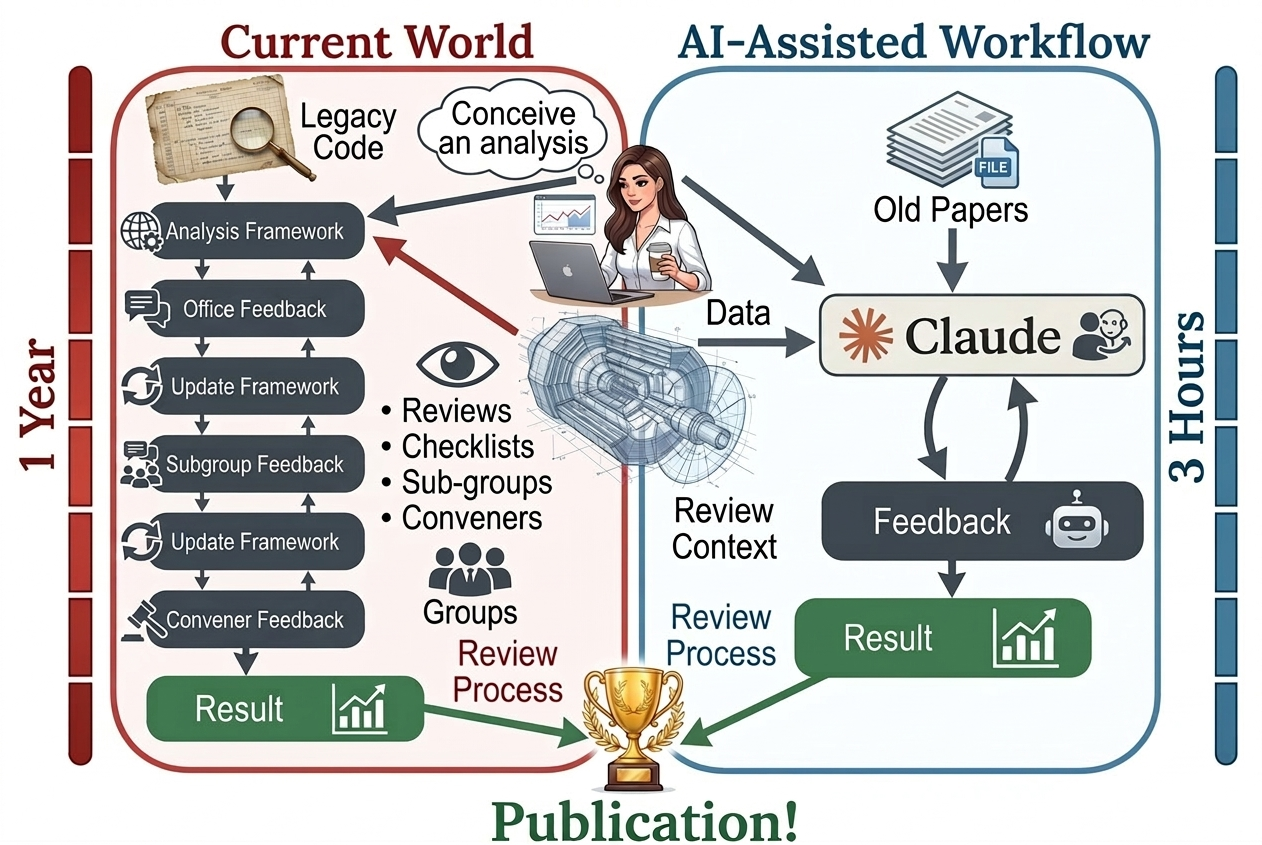
This paper shows that modern AI “code-writing” assistants can already do most parts of a real particle physics data analysis by themselves. The authors build a framework called SLOP (short for “Just Furnish Context”) that gives an AI agent access to:
- open physics data from past experiments,
- tools to run code,
- and a way to look up information from the scientific literature.
With that, the AI plans the analysis, cleans and filters the data, estimates backgrounds (things that mimic the signal), checks uncertainties, runs the statistics, and even drafts a report with publication-quality plots. The team demonstrates this on open data from three famous experiments (ALEPH, DELPHI, and CMS), covering measurements in electroweak physics, QCD, and the Higgs boson.
Objectives and Questions
The paper aims to answer a few simple but important questions:
- Can an AI agent, given data and access to past papers, carry out a full particle physics analysis on its own?
- Which typical steps in an analysis can be automated reliably today?
- Can a system of multiple “reviewer” agents catch mistakes before humans look at the final results?
- What does this mean for how physicists should organize their work and train students?
Methods and Approach
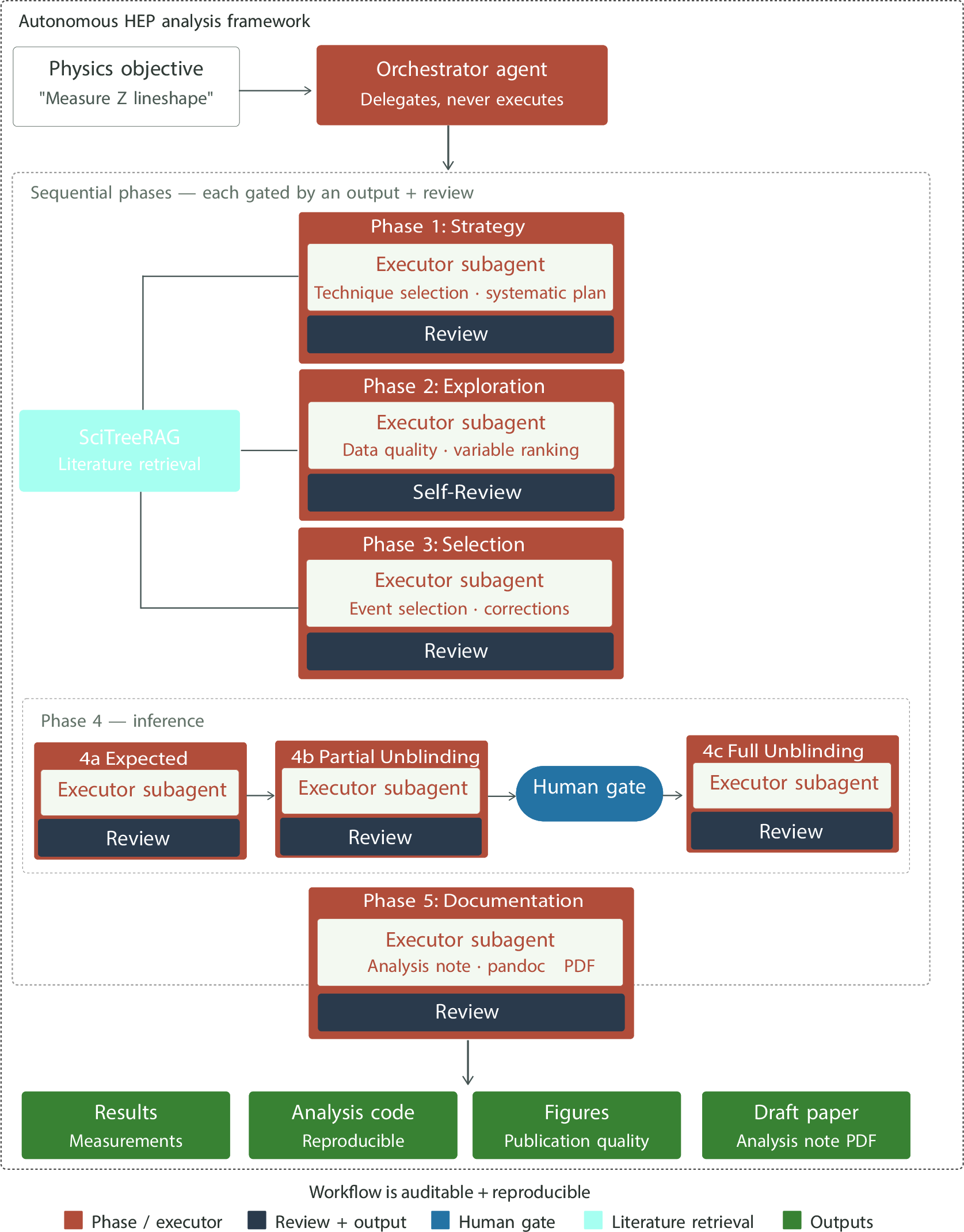
The authors set up an end-to-end analysis pipeline that an AI can navigate step by step, with checks after every stage. Here’s how it works in everyday terms:
- Planning the analysis: The AI starts with a high-level goal (for example, “measure a certain process using ALEPH data”). It looks up similar published analyses and plans how to proceed.
- Event selection: Imagine you have a huge pile of photos and you only want the ones showing a cat. Event selection is like teaching the computer to filter out the right “cat photos” (the signal) and remove the “not-a-cat photos” (the background). In physics, this means keeping the right particle collision events and discarding the rest.
- Background estimation: Some non-cat photos still look a bit like a cat (shadows, toys, etc.). The AI estimates how many of these confusing lookalike events sneak in and how to account for them.
- Uncertainty quantification: Even with a good filter, you can’t be 100% sure. Uncertainty is like saying, “We think there are 1,000 cat photos, give or take 30.” The AI calculates these “give or take” ranges and checks different sources of possible error.
- Statistical inference: This is the math that turns all the filtered data into a final answer. Think of running fair coin tests a huge number of times to decide whether a coin is actually fair—here, it’s about deciding whether a signal is really there and how strong it is.
- Blinding: To avoid bias, the AI hides the key part of the data (the “signal region”) until all the setup work is done. It then does a small “partial peek” at 10% of that hidden region to make sure nothing is obviously wrong. Only after human approval does it look at the full signal data.
- Multi-agent review: Different specialist bots check the work at every stage—one focuses on physics logic, another checks presentation, another validates plots programmatically, and an “arbiter” decides whether the analysis can move forward or must be revised.
- Literature retrieval: The AI uses a tool (SciTreeRAG) to find and read relevant parts of earlier papers. This helps it design good selections, choose which uncertainties to include, and pick sensible statistical methods based on what experts have done before.
- Documentation: Finally, the AI writes a thorough analysis note with clear figures and labels, ready for human review.
Main Findings and Why They Matter
The paper’s main results are straightforward:
- The AI agent completed all the major steps of several realistic physics analyses, from planning to report writing.
- It produced figures and explanations that look similar to what a trained graduate student might prepare.
- The multi-agent review system caught issues early and guided improvements without continuous human intervention.
- The approach worked across different types of measurements and different experiments’ data.
Why this matters:
- It shows that current AI systems can take over much of the repetitive coding and data-handling work in physics, freeing humans to focus on ideas, tricky details, and careful validation.
- It could make it much easier to revisit older datasets, check results for reproducibility, and document analysis steps thoroughly—things that are very important but traditionally take a lot of time.
- It suggests the community may be underestimating what today’s AI agents can already do.
Importantly, the authors stress that these are demonstrations, not official scientific results, and that humans must still validate and approve any final findings.
Implications and Potential Impact
If this way of working spreads, it could:
- Change how physicists train students: Less time on boilerplate coding and more time on understanding physics, designing new methods, and performing tough cross-checks.
- Speed up routine analysis tasks: Teams could test ideas faster and document them more completely.
- Improve reproducibility and reanalysis: AI can help redo old analyses or audit them systematically, which strengthens science.
- Require new review strategies: Human experts would become final gatekeepers, focusing their attention where judgment and creativity matter most.
Bottom line: AI agents won’t replace physicists, but they can be powerful helpers that handle a lot of the heavy lifting. Used responsibly—with strong review, blinding, and human approval—they can make particle physics research faster, more reliable, and more accessible.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions left unresolved by the paper that future researchers could address:
- Lack of quantitative evaluation: No systematic metrics (e.g., agreement with published yields, limits, best-fit μ, nuisance pulls, goodness-of-fit, coverage) or pass/fail rates across many runs; design and publish a benchmark suite with target metrics and success criteria.
- No human-baseline comparison: Absent head-to-head comparisons with junior/expert analysts on the same tasks (time-to-result, error rates, physics accuracy); run controlled studies to quantify productivity and quality gains/losses.
- Generalization beyond case studies: Demonstrations are limited to ALEPH, DELPHI, and one CMS open-data context; test on modern, complex LHC Run 2/3 analyses (high pileup, trigger-dependence, multi-year combinations, multichannel fits) to assess scalability and realism.
- Run-to-run reliability and stochasticity: No analysis of variability across seeds, model non-determinism, or retrials; quantify stability of selections, fits, and final results across repeated autonomous runs.
- Component ablations: Unclear contribution of each scaffold (literature retrieval, multi-agent review, phase-gating, conventions directory); perform ablation studies to measure which pieces are necessary and most impactful.
- Reviewer-agent validity: No estimates of false-negative/false-positive rates relative to human reviewers; conduct blinded audits where humans inject subtle mistakes to test reviewer detection power.
- Blinding protocol robustness: 10% partial unblinding may still leak signal information; evaluate leakage risks, define limits on repeated subsampling, and test whether agents adapt choices post-partial unblinding (p-hacking exposure).
- RAG corpus quality and coverage: Literature conversion is partial and subject to OCR/LaTeX parsing errors; quantify conversion error rates, retrieval precision/recall, and downstream impact on analysis decisions; validate citation fidelity.
- Model and vendor dependence: Framework is tied to Claude Opus; assess portability to other models (GPT, Gemini, open-weight LLMs), sensitivity to model updates, latency/rate-limit impacts, and cost-performance trade-offs.
- Cost and compute footprint: No accounting of total compute time, GPU/CPU usage, or monetary cost per analysis phase; profile and optimize resource use, including parallelization and caching strategies.
- Toolchain constraints: Prohibiting ROOT may hinder integration with collaboration workflows; compare numerical agreement, performance, and maintainability between the mandated Python stack and canonical ROOT/RooFit pipelines.
- Statistical inference rigor: Coverage properties, bias, and robustness of binned/unbinned fits (pyhf/zfit) are not validated; run toy-MC studies (Asimov vs. pseudo-data), signal injection/recovery tests, and coverage evaluations across typical likelihood complexities.
- Handling of complex likelihoods: The framework’s ability to manage shape systematics, correlated nuisances across regions, multi-bin control/validation regions, and non-Gaussian constraints remains untested on real-world models.
- Systematic uncertainty completeness: How the agent enumerates and prioritizes detector/theory systematics is not validated against collaboration standards; benchmark the completeness and correctness of systematics programs for known measurements.
- Detector- and conditions-dependent effects: No demonstration that agents can correctly account for calibrations/conditions, trigger turn-ons, run-by-run variations, or time-dependent detector states that are often proprietary.
- Data access realism: Open data may lack full calibration constants and metadata; evaluate how the framework performs with internal collaboration datasets and restricted information.
- Security and isolation: Agents execute code and parse external documents; specify sandboxing (e.g., containers, seccomp), supply-chain controls (pinned hashes, SBOMs), and defenses against malicious PDFs/LaTeX or prompt injection via documents.
- Reproducibility guarantees: No locked environment specs, container images, or artifact registries are provided; release version-pinned environments (e.g., Docker), random seeds, and immutable artifact stores to ensure bitwise reproducibility.
- Documentation and rendering limits: The rendering reviewer checks formatting, not scientific content consistency (e.g., references/plots aligning with text claims); introduce content-consistency checks (cross-refs between tables/figures and text).
- Governance and accountability: Roles for authorship, responsibility for errors, and integration with collaboration ARC processes are not defined; propose governance models and audit trails acceptable to large experiments.
- Failure-mode cataloging: No taxonomy of common agent errors (e.g., double-counting systematics, signal-region bleed, misread literature) or mitigation playbooks; build a public registry of failure cases and countermeasures.
- Benchmark tasks for community: The paper notes the lack of analysis benchmarks but does not release tasks; publish open, graded tasks spanning selection → inference → documentation with reference solutions for reproducible evaluation.
- Human-gate design: Concentrating oversight at a single unblinding gate may be insufficient; test alternative oversight placements (e.g., mandatory human reviews at phase boundaries) and quantify trade-offs in speed vs. safety.
- Conventions directory governance: A “living” conventions corpus risks drift and enshrining suboptimal practices; implement versioning, change logs, and approval workflows, and study how conventions affect agent choices over time.
- Plot validator thresholds: Heuristic cutoffs (e.g., ratio ranges, χ2 thresholds) may misclassify valid/invalid cases; calibrate thresholds on real analyses and quantify false alarm/miss rates.
- Context isolation vs. continuity: Disposable subagents may duplicate effort or lose verified context; design mechanisms for safe state handover (e.g., minimal, validated summaries or signed artifacts) without context bloat.
- ML and MVA integration: The framework mentions optional ML tools but provides no tests on MVA-heavy analyses (e.g., boosted decision trees, DNNs) or their systematics; evaluate agent competence in training, validation, and uncertainty propagation.
- Bias from literature retrieval: Agents may preferentially adopt legacy methods over better modern alternatives; study whether RAG induces methodological conservatism and devise prompts or filters to promote innovation while maintaining safety.
- Legal and licensing issues: Redistribution and transformation of publisher PDFs/LaTeX to Markdown may have licensing constraints; audit licenses and define compliant distribution policies for the converted corpus.
- Accessibility and release status: No public repository link, data artifacts, or executable examples are provided; release the framework, prompts, agents, and a minimal working example for community replication and critique.
- Epistemic uncertainty of agent choices: No quantification of uncertainty over the agent’s own decisions (e.g., ensemble of agents or prompts); explore committee-of-agents or self-consistency checks to flag fragile decisions.
- Robustness to adversarial or misleading sources: Retrieval may surface outdated or incorrect practices; evaluate resilience against conflicting literature and build mechanisms to reconcile sources or flag controversy.
- Partial-unblinding safeguards: The paper does not define limits on repeated partial unblindings or fix the random seed policy across reruns; codify strict rules to prevent information leakage across iterations.
- Training and education claims: The paper argues for changes in student training but offers no curricular blueprint or measured learning outcomes; pilot courses/labs using the framework and assess pedagogy and skill development.
Practical Applications
Immediate Applications
The following are deployable now with modest engineering effort, using the paper’s methods (autonomous multi‑phase planning, literature‑aware RAG, multi‑agent review, blinding gates, and a reproducible Python stack).
- Autonomous reanalysis of open HEP datasets for education and benchmarking
- Sectors: academia (physics departments, summer schools), education (MOOCs), software (benchmark suites)
- What it looks like: Use a slop-style orchestrator to produce end‑to‑end analyses (event selection → systematics → inference → analysis note) on CERN Open Data (ALEPH, DELPHI, CMS) with publication‑grade plots and Asimov-based expected results
- Tools/workflows: Claude Code or equivalent coding agents; SciTreeRAG for literature retrieval; pure‑Python HEP stack (uproot, awkward, hist, mplhep, pyhf/zfit); state tracking and arbiter‑gated review
- Assumptions/dependencies: Access to open datasets; GPU/CPU for code execution; one‑time setup of a domain “methodology” and “conventions” repository; model with long context and reliable tool use
- Internal scaffolding for collaboration analyses (offloading boilerplate)
- Sectors: academia (HEP collaborations), software (research engineering)
- What it looks like: Delegate code generation for selection, control/validation regions, closure tests, likelihood building, and draft note writing; auto‑apply plotting and style conventions; pass internal automated review before ARC
- Tools/workflows: Multi‑agent reviewers (physics/critical/constructive/plot‑validator/arbiter); Git + CI; SLURM scaling rules; columnar selection style
- Assumptions/dependencies: Collaboration buy‑in; permissions to use internal software/data; rulebooks formalized as “conventions” docs
- Reproducibility audits and “analysis note from code” generation
- Sectors: academia, policy (funding agencies, journals), software (reproducibility services)
- What it looks like: Rebuild figures and tables, compare against archival notes; auto‑produce ANALYSIS_NOTE.md/PDF with fully traceable provenance and failure‑to‑pass review gates logged
- Tools/workflows: Pipeline state file (STATE.md); rendering reviewer; plot validator; deterministic seeds for partial unblinding
- Assumptions/dependencies: Access to code, data, and literate configuration; acceptance of automated linting/review outputs in internal processes
- Literature‑aware method retrieval for faster ramp‑up
- Sectors: academia (new students/postdocs), education, software (RAG providers)
- What it looks like: Retrieve prior selection cuts, detector object definitions, standard systematics, and inference practices from published corpora to guide agent decisions
- Tools/workflows: SciTreeRAG (hierarchical RAG, knowledge graphs); document ETL (INSPIRE/CDS metadata, Nougat OCR, Pandoc normalization)
- Assumptions/dependencies: Adequate digitized and normalized literature; permissions for content use; retrieval quality tuned to the experiment
- Structured blinding and human‑gate workflows beyond HEP
- Sectors: healthcare (observational studies, RCTs), finance (backtesting), software (A/B testing)
- What it looks like: Adopt formal “partial unblinding → human approval → full unblinding” gates to reduce p‑hacking and leakage; automate checklists and Asimov-like expected results before reveal
- Tools/workflows: Configurable “unblinding gate” plugin for Airflow/MLflow/Databricks; standardized checklists; arbiter decisions (PASS/ITERATE/ESCALATE)
- Assumptions/dependencies: Organizational acceptance of gating; proper de‑identification and privacy controls; auditors willing to rely on agent‑produced checklists
- Multi‑agent “analysis linting” as a service
- Sectors: software (data science platforms), bioinformatics, materials, climate
- What it looks like: Run critical/constructive reviewers and programmatic plot validators on Jupyter notebooks and pipelines to catch statistical and presentation errors pre‑publication
- Tools/workflows: Reviewer profiles; figure/label/style checklists; non‑visual histogram/data sanity checks (e.g., non‑negative yields, monotonic cutflows)
- Assumptions/dependencies: Domain‑specific conventions encoded; agents allowed to execute code safely in sandboxes
- Student training assistants that mirror collaboration review culture
- Sectors: academia, education technology
- What it looks like: Course labs where agents plan and execute mini‑analyses, enforce conventions, and provide structured feedback; students focus on physics reasoning and validation
- Tools/workflows: Phase‑gated execution; reviewers producing categorized A/B/C findings; example corpora and prebuilt “conventions” packs
- Assumptions/dependencies: Faculty oversight; compute quotas; guardrails to avoid over‑reliance and ensure conceptual understanding
- Cross‑experiment open‑data synthesis and quick‑look studies
- Sectors: academia, policy (open science), media (science communication)
- What it looks like: Rapid, literature‑grounded re‑production of legacy results across ALEPH/DELPHI/CMS open data for pedagogy, outreach, or meta‑analysis sanity checks
- Tools/workflows: Shared orchestrator and review stack; per‑experiment conventions; automated figure harmonization (labels, units, luminosity stamps)
- Assumptions/dependencies: Sufficiently standardized open data schemas; robust object definitions; documented detector effects
- Automated technical report generation for R&D teams
- Sectors: industry (R&D, analytics), energy (grid analytics), telecom (network analytics)
- What it looks like: Agents turn pipelines into audit‑ready PDFs with consistent figures, citations, and cross‑references; reduce time to produce internal whitepapers
- Tools/workflows: Pandoc + xelatex rendering reviewer; style enforcement via mplhep‑like themes; citation managers
- Assumptions/dependencies: Corporate style guides encoded; data governance approvals for auto‑generated reports
- Domain corpus digitization and RAG builds
- Sectors: academia, industry (pharma, materials), policy (national libraries)
- What it looks like: Replicate the paper’s literature ETL (OCR → Markdown → hierarchical chunks) to power method‑aware assistants in new fields
- Tools/workflows: Nougat OCR; Pandoc; tree/graph RAG indexing; provenance tagging
- Assumptions/dependencies: Rights to digitize/use content; compute/GPU for OCR at scale; QA for conversion fidelity
Long‑Term Applications
These require additional research, scaling, governance, or integration with closed infrastructures and evolving norms.
- Collaboration‑integrated autonomous analyses with human gates only at unblinding
- Sectors: academia (HEP collaborations, neutrino/astrophysics)
- What it looks like: Agents plan/execute most standard measurements; humans concentrate on physics choices, detector subtleties, and final sign‑off
- Tools/workflows: Secure agent access to conditions databases, calibration constants, internal MC; deeper conventions catalog; collaboration CI/CD integration
- Assumptions/dependencies: Policy approval; robust failure modes and audit trails; verified handling of complex systematics and bespoke reconstruction
- Nearline/online experiment monitoring and anomaly triage
- Sectors: robotics (detector ops), energy (SCADA), manufacturing (QC)
- What it looks like: Plot validators and reviewers run in near‑real‑time to flag red‑flags (fit non‑convergence, abnormal pulls) and suggest mitigations before full reprocessing
- Tools/workflows: Streaming adapters; lightweight models for fast checks; escalation policies
- Assumptions/dependencies: Low‑latency data access; safety/ops controls; clear handover to human shifters
- Regulated analytics with formal blinding and automated CSRs
- Sectors: healthcare (clinical trials, RWE), finance (stress testing), public policy (impact evaluations)
- What it looks like: End‑to‑end analyses with pre‑registered plans, partial unblinding, multi‑agent review, and auto‑drafted Clinical Study Reports or regulatory filings
- Tools/workflows: Domain‑specific conventions and checklists; compliant data rooms; validation suites for agents; audit logging
- Assumptions/dependencies: Regulator acceptance of AI‑assisted pipelines; strict privacy/security; validated statistical procedures and traceability
- Cross‑domain autonomous science assistants
- Sectors: materials, chemistry, climate, genomics, astronomy
- What it looks like: Literature‑aware agents design analyses/experiments, run simulation/data pipelines, and draft papers with multi‑agent review
- Tools/workflows: Domain RAG corpora and ontologies; tool adapters (e.g., Gaussian, VASP, xarray); reviewer packs for each field
- Assumptions/dependencies: High‑quality, structured corpora; tool reliability; community standards for AI authorship and credit
- Closed‑loop experiment design ↔ analysis optimization
- Sectors: academia (detector upgrades), robotics (automated labs), industry (process optimization)
- What it looks like: Analysis agents inform design choices (e.g., detector geometry, calibration strategies) and iterate with simulators/robots (cf. GRACE‑like)
- Tools/workflows: Coupled design/analysis models; black‑box optimization loops; safety constraints and sandboxing
- Assumptions/dependencies: Fast, faithful simulators; safe robot interfaces; governance for autonomous design choices
- Reviewer‑as‑a‑Service marketplaces and standards
- Sectors: software (SaaS), publishing, academia
- What it looks like: Standardized “statistical reviewer,” “physics reviewer,” and “rendering reviewer” profiles certified by benchmarks and used by journals or collaborations
- Tools/workflows: Public benchmarks; API‑driven review results with adjudication tables; integration with submission systems
- Assumptions/dependencies: Community consensus on criteria; liability and accountability frameworks; transparency requirements
- National‑scale digitization and knowledge graphs for scientific corpora
- Sectors: policy (national research agencies), academia, industry
- What it looks like: SciTree/Graph‑RAG at national repositories enabling method discovery and meta‑analysis across decades of papers and theses
- Tools/workflows: Large‑scale OCR pipelines; bibliographic integration; cross‑document entity linking; provenance tracking
- Assumptions/dependencies: Funding and rights; sustained curation; open APIs for research use
- AgentOps control planes for HPC and data platforms
- Sectors: software (cloud/HPC), energy (grid analytics), automotive (autonomy analytics)
- What it looks like: Orchestrators that decompose tasks, spawn disposable agents with least‑privilege access, enforce gates, and track state/regressions across clusters
- Tools/workflows: SLURM/Kubernetes adapters; policy engines; secure execution sandboxes; observability dashboards
- Assumptions/dependencies: Enterprise security model; cost controls; model/tool reliability under scale
- Expanded plot/data validators for scientific and industrial QA
- Sectors: academia, manufacturing, pharma QC
- What it looks like: Domain‑specific, non‑visual validators catching physics/engineering impossibilities and style non‑compliance before release
- Tools/workflows: Validator libraries with rulesets; CI integration; deviation explainability
- Assumptions/dependencies: Rich rule catalogs; versioned standards; minimal false positives
- Educational reform and assessment frameworks
- Sectors: education, academia policy
- What it looks like: Curricula that leverage agents to automate routine coding, emphasizing physics insight, validation, and ethics; new assessment that measures judgment rather than boilerplate coding
- Tools/workflows: Agent‑supported labs; instructor dashboards showing review findings and student decisions; plagiarism/attribution policies
- Assumptions/dependencies: Institutional guidelines; faculty training; fair access to compute and models
Notes on feasibility across applications
- Reliability and oversight: The framework assumes humans retain ultimate responsibility; automated reviews mitigate but do not eliminate subtle errors.
- Data access and IP: Many high‑value settings involve closed data and sensitive IP; deployment depends on secure, auditable environments and permissions.
- Model capability drift: Performance depends on access to strong, tool‑using LLMs with large context windows; changes in model behavior require continuous validation.
- Standardization: Success hinges on encoding “methodology” and “conventions” per domain—an up‑front investment that determines agent quality and safety.
Glossary
- ALEPH: One of the four detectors at the LEP collider; here, a source of archived open high-energy physics data. "open data from ALEPH, DELPHI, and CMS"
- Analysis Review Committee (ARC): An internal panel in HEP collaborations that reviews analyses before public release. "equivalent to an Analysis Review Committee (ARC) member"
- Asimov dataset: A synthetic dataset constructed from expected values (often background-only) used to predict expected fit outcomes without statistical fluctuations. "uses exclusively Asimov datasets"
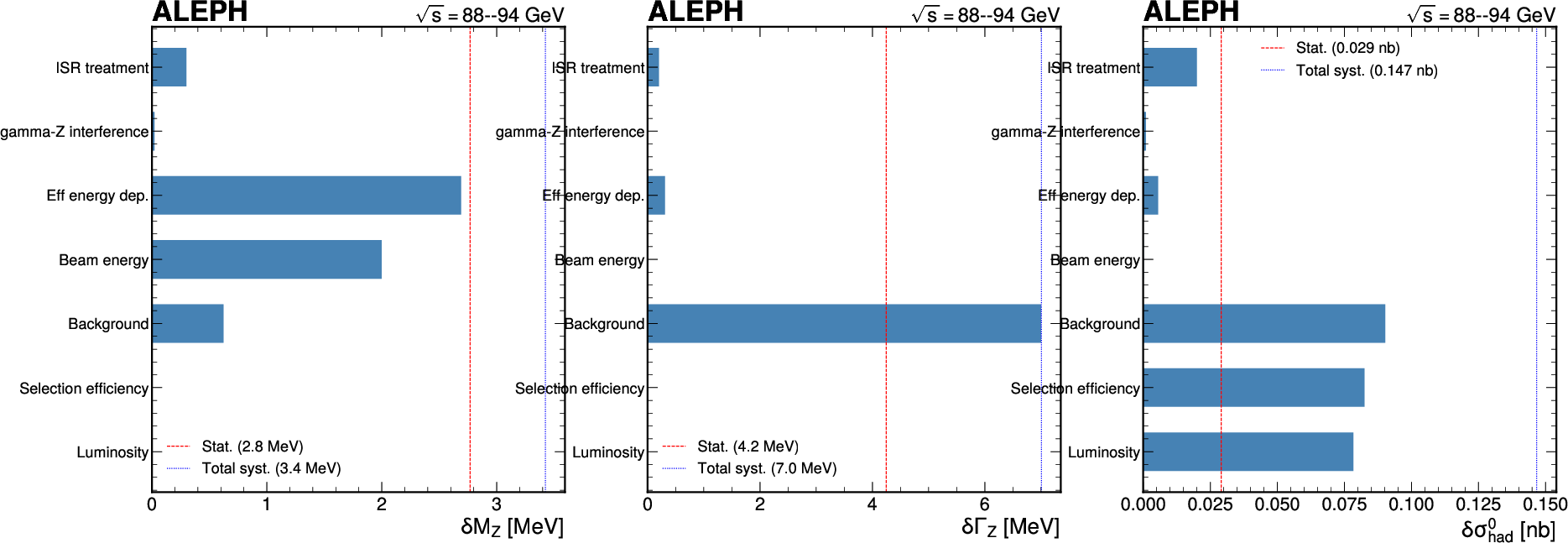
- background estimation: The process of modeling and quantifying contributions from non-signal processes in an analysis. "event selection, background estimation, uncertainty quantification, statistical inference"
- beyond the Standard Model (BSM): Theories and searches for phenomena not described by the Standard Model of particle physics. "beyond the Standard Model (BSM) physics searches"
- blinding variable: A chosen observable that defines regions (like the signal region) kept hidden from analysts until procedures are fixed to prevent bias. "defines the blinding variable"
- bump hunts: Searches for localized excesses (“bumps”) in distributions (e.g., invariant mass) that may indicate new particles or phenomena. "combining bump hunts with weakly supervised approaches like CWoLa"
- chi-squared per degree of freedom (χ2/ndf): A goodness-of-fit metric comparing data to model, normalized by degrees of freedom. ""
- CLs (CL) method: A statistical technique for setting exclusion limits that reduces sensitivity to low-probability background fluctuations. "CL exclusion procedure"
- closure tests: Validations ensuring that a background estimation method correctly reproduces known (often simulated) “truth” before applying to data. "closure tests pass in all validation regions"
- columnar analysis: A data processing paradigm operating on columns (arrays) of event variables rather than looping over events one by one. "All analysis code is written in a columnar style"
- control region: A phase-space region enriched in background and depleted in signal, used to validate or constrain background models. "define control and validation regions"
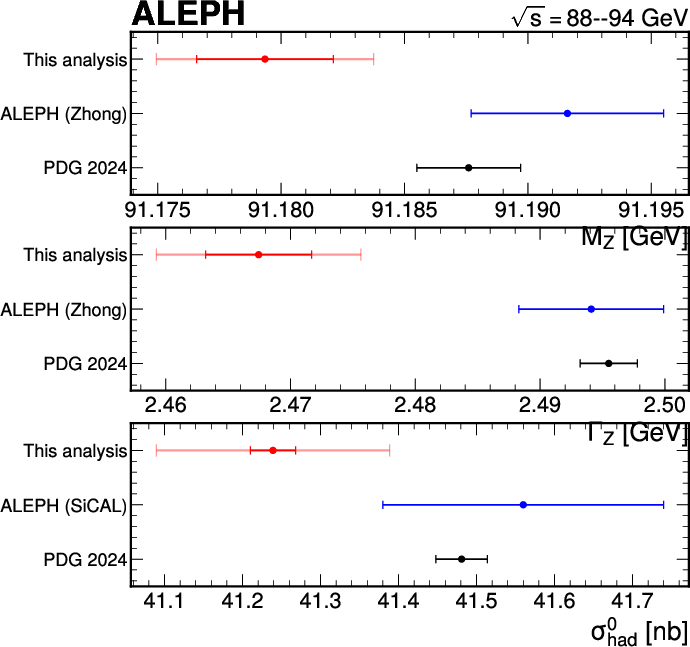
- cross-section: A measure of the probability of a given process occurring in particle collisions, with units of area. "measure the hadronic cross-section of the Z boson"
- CWoLa: “Classification Without Labels,” a weakly supervised learning approach for distinguishing signal from background using mixed samples. "CWoLa"
- data/MC ratio: The ratio of observed data yields to Monte Carlo predictions, used to check modeling accuracy. "data/MC ratios in control regions"
- DELPHI: Another LEP detector experiment providing archived open data used for retrospective analyses. "open data from ALEPH, DELPHI, and CMS"
- electroweak: The unified interaction encompassing electromagnetism and the weak nuclear force; a key sector of Standard Model measurements. "electroweak, QCD, and Higgs boson measurements"
- goodness-of-fit: A quantitative assessment of how well a model describes observed data. "goodness-of-fit"
- hadronic: Referring to processes involving hadrons (particles made of quarks, like protons and pions). "hadronic cross-section"
- Higgs boson: The scalar particle associated with electroweak symmetry breaking, discovered at the LHC in 2012. "Higgs boson measurements"
- Large Electron-Positron (LEP) collider: A former CERN collider that accelerated and collided electrons and positrons; precursor to the LHC. "Large Electron-Positron (LEP) collider"
- Large Hadron Collider (LHC): CERN’s proton–proton collider and the highest-energy particle accelerator in operation. "Large Hadron Collider (LHC)"
- likelihood: A function quantifying the probability of observed data under a model; central to statistical inference and fitting. "constructs the likelihood"
- LHC Olympics dataset: A community dataset for benchmarking anomaly detection and analysis strategies in collider physics. "using the LHC Olympics dataset"
- Monte Carlo (MC) simulation: Stochastic simulation of particle collisions and detector responses used to model expected signals and backgrounds. "using Monte Carlo (MC) simulation"
- nuisance parameter: A parameter representing systematic uncertainties that is profiled or constrained during statistical fits. "nuisance parameter pulls"
- profile likelihood: A method where nuisance parameters are profiled (optimized) to obtain likelihoods for parameters of interest. "profile likelihood fits"
- quantum chromodynamics (QCD): The quantum field theory describing the strong interaction between quarks and gluons. "electroweak, QCD, and Higgs boson measurements"
- retrieval-augmented generation (RAG): An approach where an LLM retrieves relevant documents to ground its responses in external knowledge. "Standard retrieval-augmented generation (RAG)"
- SciTreeRAG: A literature-retrieval system that exploits the hierarchical structure of scientific documents for better context. "built on SciTreeRAG"
- signal injection tests: Validations where synthetic signal is injected into data or Asimov samples to ensure the analysis can recover it. "signal injection tests"
- signal region: The phase-space region where the signal is expected to appear and which is kept blinded until analysis finalization. "signal region data"
- Snakemake: A workflow management system that orchestrates reproducible, rule-based computational pipelines. "Snakemake workflow manager"
- statistical inference: The process of drawing conclusions about model parameters or hypotheses based on data and statistical models. "statistical inference"
- systematic uncertainty: Uncertainties from imperfect knowledge of detectors, modeling, or methods, distinct from statistical fluctuations. "quantifies all relevant sources of systematic uncertainty"
- template methods: Techniques using binned distributions (“templates”) of observables to separate signal from background in fits. "template methods"
- unbinned fit: A statistical fit performed directly on event-level values rather than on binned histograms. "zfit (unbinned)"
- unblinding: The act of revealing the data in the signal region after the analysis strategy is fixed and validated. "unblinding checklist"
- validation region: A region similar to the signal region but with reduced signal, used to validate background models without biasing results. "control and validation regions"
- Z boson: The neutral electroweak gauge boson mediating the weak force; a frequent target of precision measurements. "Z boson"
- cutflow: A tabulation of event counts after each successive selection cut, used to track efficiencies and check logic. "cutflow yields are monotonically non-increasing"
Collections
Sign up for free to add this paper to one or more collections.