A Super Fast K-means for Indexing Vector Embeddings
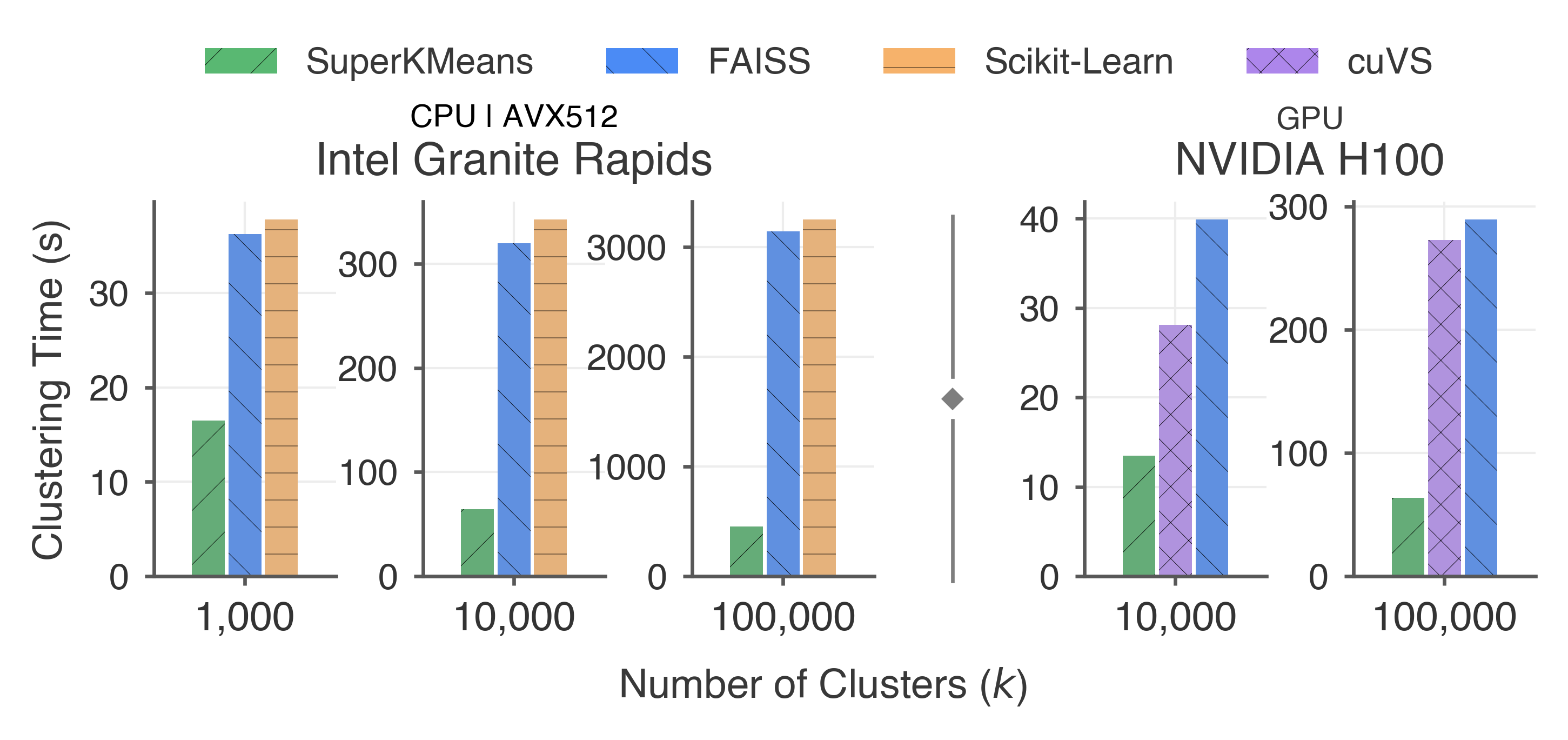
Abstract: We present SuperKMeans: a k-means variant designed for clustering collections of high-dimensional vector embeddings. SuperKMeans' clustering is up to 7x faster than FAISS and Scikit-Learn on modern CPUs and up to 4x faster than cuVS on GPUs (Figure 1), while maintaining the quality of the resulting centroids for vector similarity search tasks. SuperKMeans acceleration comes from reducing data-access and compute overhead by reliably and efficiently pruning dimensions that are not needed to assign a vector to a centroid. Furthermore, we present Early Termination by Recall, a novel mechanism that early-terminates k-means when the quality of the centroids for retrieval tasks stops improving across iterations. In practice, this further reduces runtimes without compromising retrieval quality. We open-source our implementation at https://github.com/cwida/SuperKMeans


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A super-fast way to group big vectors for search
What this paper is about
This paper introduces SuperKMeans, a faster way to run k-means clustering on very large, high‑dimensional vectors (long lists of numbers), like the ones used by AI models. The goal is to build vector search indexes more quickly without hurting search quality. Think of it as a faster “organizer” that helps search systems (like recommendation engines or AI assistants) find similar items quickly.
What questions the paper tries to answer
- Can we make k-means clustering much faster for large, high‑dimensional data used in vector search?
- Can we keep search quality (how well we find the right matches) the same while going faster?
- Can we tell when to stop k-means early, as soon as it stops helping search results?
- How many k-means iterations and how much data do we really need to get great results?
- Do fancy starting choices (like k-means++) actually help here—or hurt?
Key ideas and how the method works (in simple terms)
A quick reminder: what is k-means?
- You have lots of points (vectors). You want to group them into k groups (clusters).
- Each group has a center (called a centroid).
- You repeatedly: 1) assign each point to its closest center, 2) move centers to the middle of their assigned points, 3) repeat until things stop changing much.
This is used in vector search (like IVF indexes) to route a query to the most promising clusters first, so you don’t have to check everything.
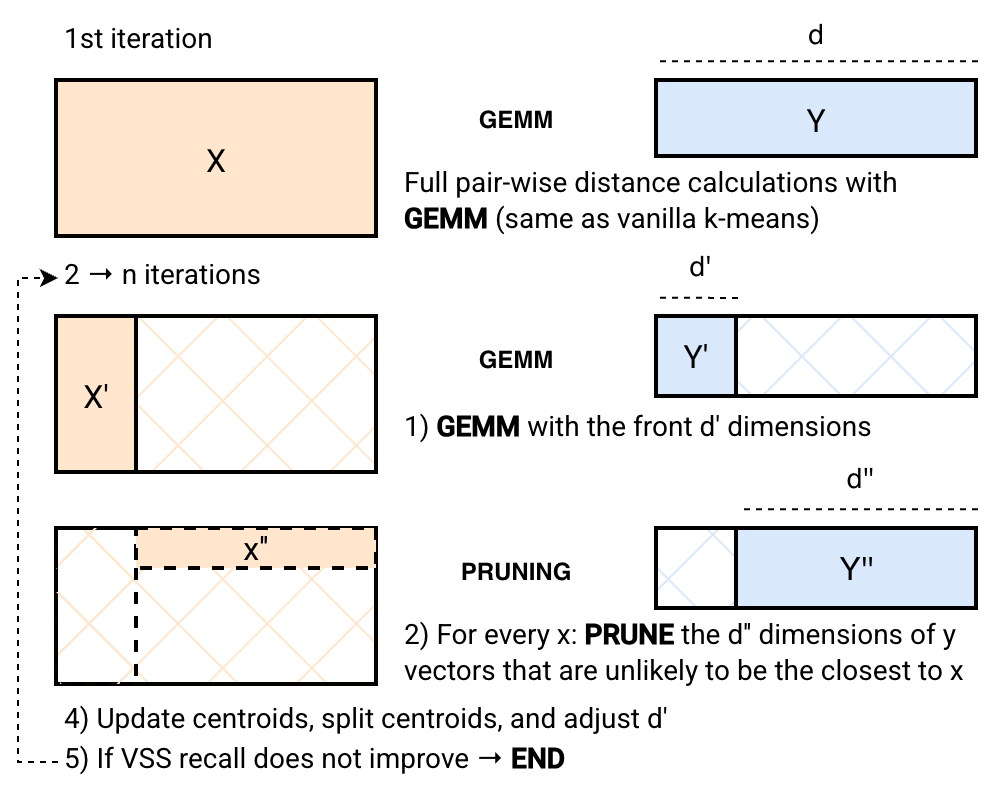
The core trick: “peek early, skip most”
SuperKMeans speeds things up by not doing full work for every comparison:
- Phase 1: Partial check (fast peek)
- It first compares only a small portion (about 12.5%) of each vector’s dimensions using super‑fast matrix math (GEMM; think “turbo calculator for big matrix multiplications”). This gives a quick, rough idea of which centers are promising.
- Phase 2: Pruning (skip the rest)
- Using that rough info, it skips fully comparing most centers that are clearly not the best match. It only finishes the check for a tiny fraction of possible centers.
- It uses a technique called Adaptive Sampling (ADSampling) to decide safely when to stop early. In practice, it skips over 97% of unnecessary checks.
To make Phase 2 fast, SuperKMeans stores centers in a memory layout (PDX) that lets the computer read the right pieces quickly. It also rotates the data once at the start (a standard trick) so useful information is spread across dimensions more evenly.
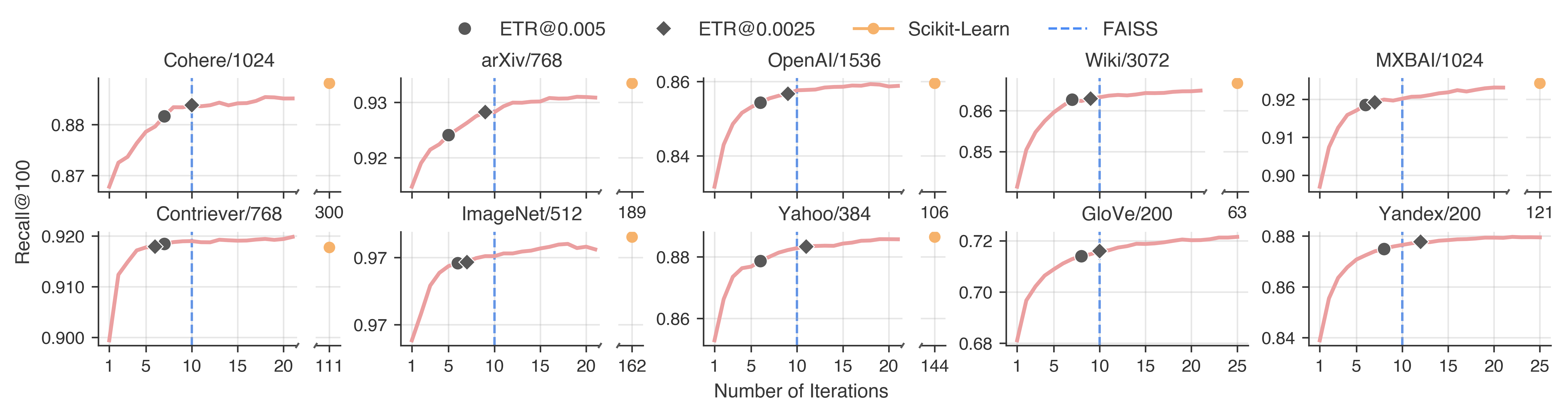
Stop early when search quality stops improving
SuperKMeans adds Early Termination by Recall (ETR):
- It watches the actual search quality (“recall”—how many of the true nearest neighbors we find) after each iteration.
- If recall stops improving beyond a tiny amount for two rounds, it stops early.
- This saves time and avoids wasting iterations that don’t help.
Small extra improvements
- It adjusts how big the “peek” is (the number of early dimensions) so that pruning stays effective (aiming to prune about 95–97% of centers).
- It supports sampling: you can cluster on only part of your data to go faster, then still get good search quality.
What did they test and how?
- They compared SuperKMeans to popular libraries: FAISS and Scikit‑Learn on CPUs, and cuVS on GPUs.
- They used many real vector datasets (text, images, word embeddings) with up to 10 million vectors and hundreds to thousands of dimensions.
- They measured:
- Speed (time to build clusters/index),
- Search quality (recall) when those clusters are used in a vector search index (IVF),
- How many vectors need to be checked during search,
- How performance scales with more clusters (larger k) and more threads/cores.
Main results and why they matter
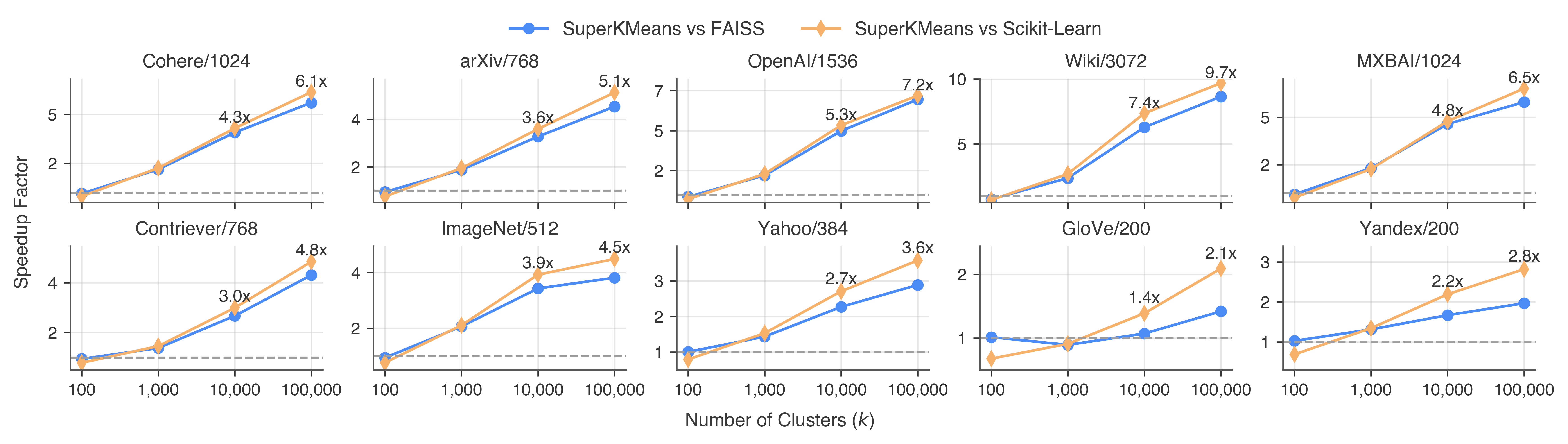
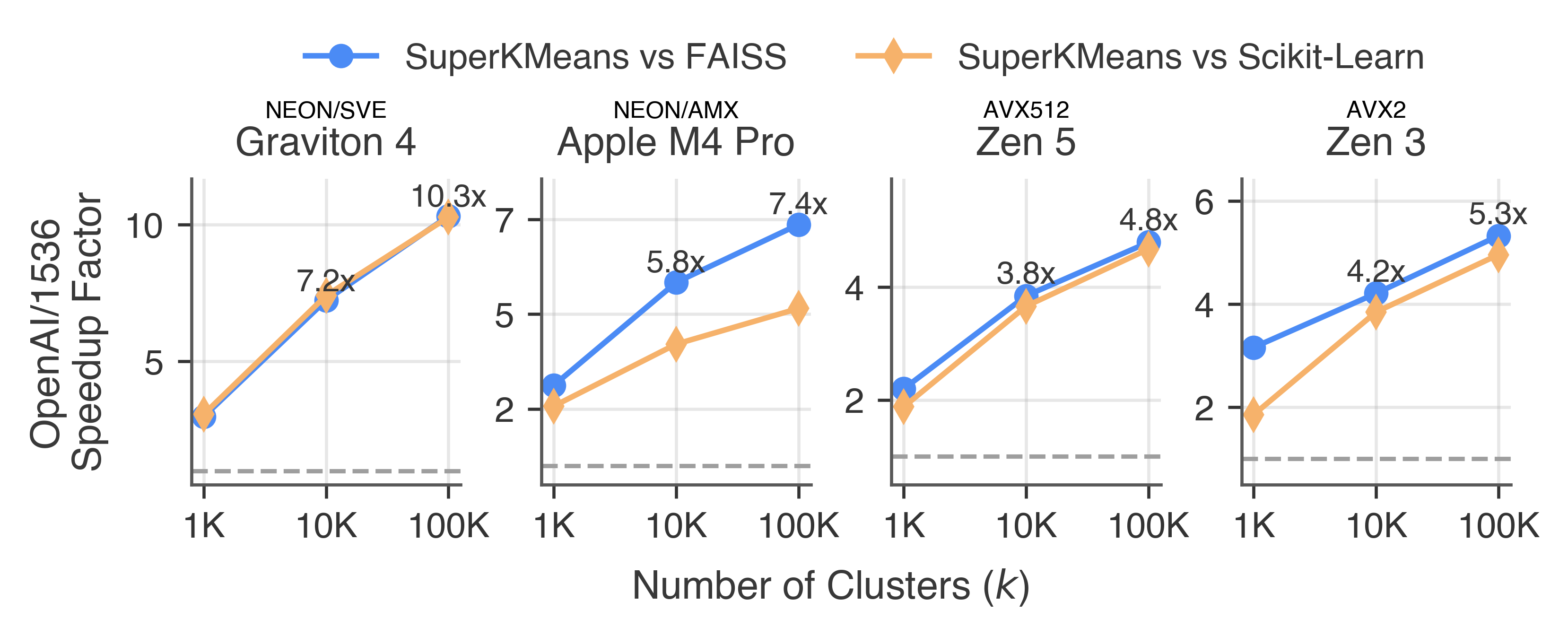
- Much faster, same quality:
- Up to about 7× faster than FAISS and Scikit‑Learn on modern CPUs.
- Up to about 4× faster than cuVS on GPUs.
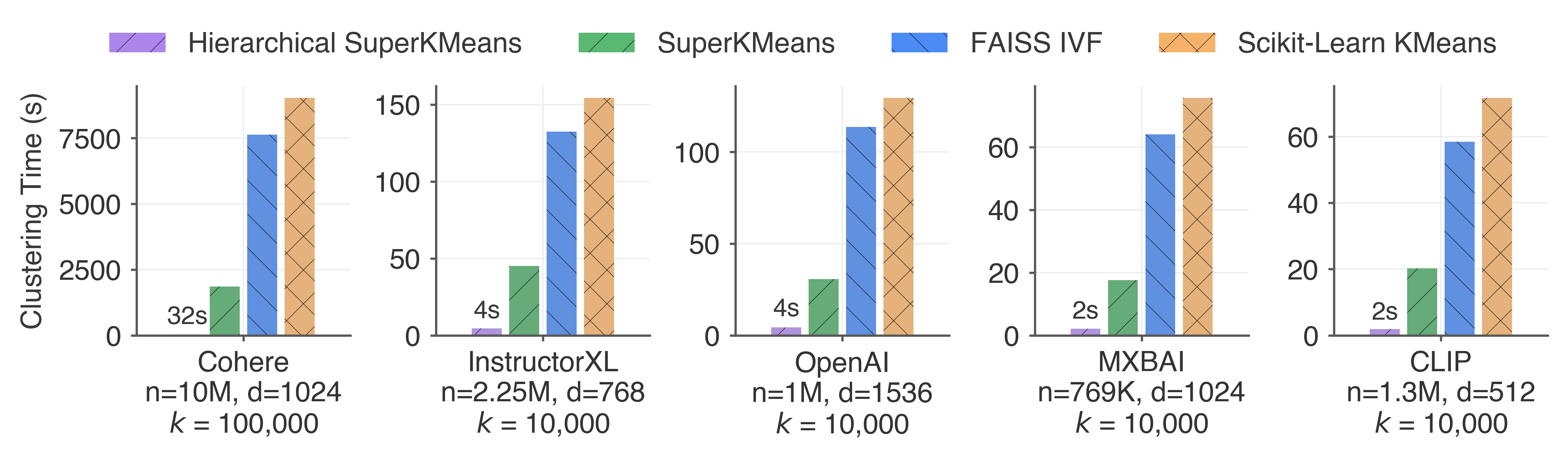
- When combined with hierarchical k‑means, they show a case that is about 250× faster than FAISS for indexing 10M vectors (1024 dimensions).
- Despite the speedups, search quality (recall) is essentially the same as competitors.
- Early stop saves time:
- ETR often stops earlier than FAISS’s default and much earlier than Scikit‑Learn’s, with almost no loss in recall.
- Big k and high dimensions are where it shines:
- The more clusters you want (big k) and the higher the dimensions, the bigger the speedup.
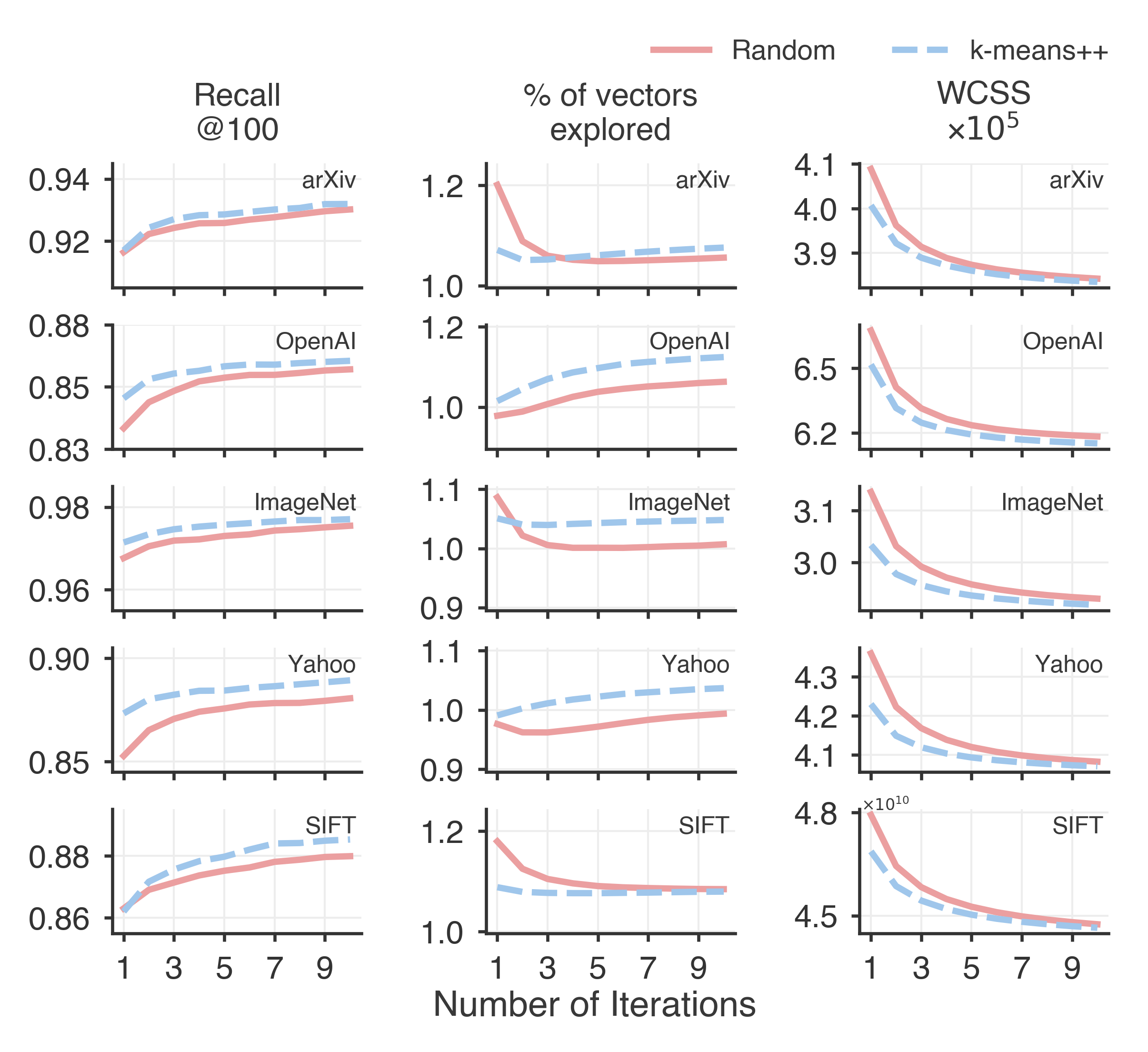
- You don’t need many iterations or all the data:
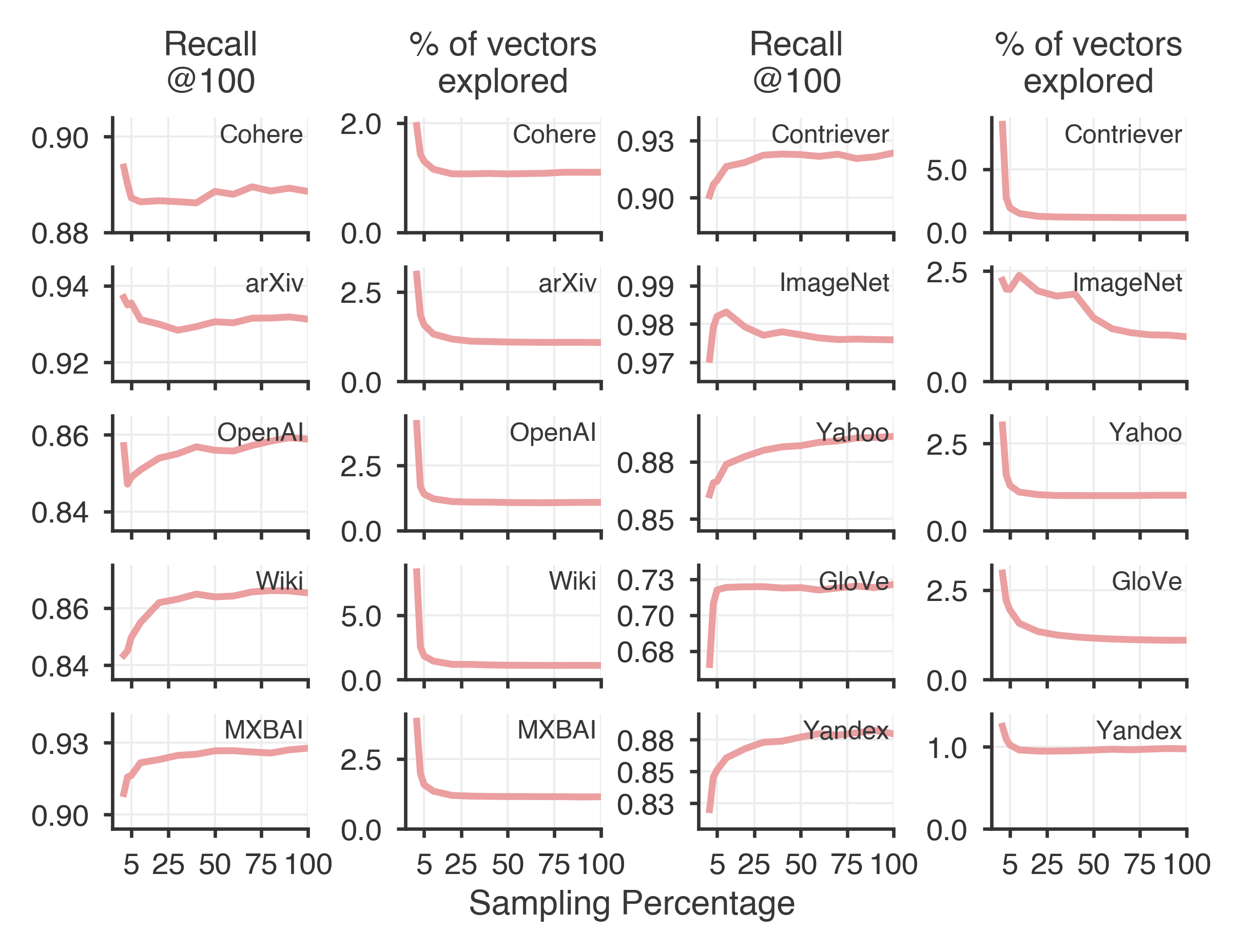
- Just 5–10 iterations are usually enough to reach top search quality.
- Using only 20–30% of your data to train the clusters often gives you near‑best results, though using more data can balance clusters better (which can reduce search work later).
- k-means++ isn’t helpful here:
- For these high‑dimensional embedding datasets, fancy initialization like k‑means++ can actually hurt final index quality. Simple random initialization works well.
Why this matters (impact)
- Faster index building:
- Systems like search engines, recommenders, and RAG applications can build or refresh their vector indexes much faster—saving time and money.
- Works across hardware:
- It runs well on many CPUs (Intel, AMD, ARM/Apple) and GPUs, making it practical in data centers or the cloud.
- Better developer experience:
- ETR removes guesswork about “how many iterations to run,” stopping automatically when improvements stop.
- Greener computing:
- Doing far less unnecessary work reduces energy use.
- Open source:
- The code is available, so others can use, test, and improve it.
In short, SuperKMeans keeps the good search results you expect, but gets there much faster by doing smart early checks, skipping most of the unnecessary work, and stopping as soon as it stops helping.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, organized by theme to guide future work.
Algorithmic guarantees and failure modes
- Lack of formal correctness/quality guarantees for ADSampling-driven pruning within Lloyd’s assignments: quantify worst-case misassignment probability, bound on k-means objective increase per iteration, and conditions under which pruning remains exact.
- No theoretical analysis of convergence under approximate assignments: does SuperKMeans converge to a stationary point of the -means objective, and how do pruning-induced errors affect convergence rate and fixed points?
- Unclear failure modes and dataset regimes where pruning becomes harmful (e.g., very high intrinsic dimensionality, nearly isotropic distributions, small , or highly imbalanced clusters). Provide diagnostic criteria to decide when to disable pruning or revert to full GEMM.
- Effect of pruning on centroid drift and bias across iterations is unquantified: does early misassignment create systematic centroid displacement that persists despite later iterations?
- Impact of empty-cluster handling (UpdateCentroidsAndSplitEmpty) on stability and balance is not detailed: compare alternative split strategies and quantify their effect on WCSS, recall, and explored vectors.
Hyperparameters and auto-tuning
- The target pruning ratio (95–97%) and initial ≈ 12.5% of are empirical; provide principled methods (e.g., online control, bandits, or Bayesian optimization) to learn and adjustment step sizes per dataset and iteration.
- Sensitivity analysis is missing for key knobs: step size (20%), PDX block size (64), chunk sizes for /, and OpenMP chunk size (8). Provide cross-architecture guidelines and automatic tuning policies.
- First-iteration policy is fixed to full GEMM; investigate whether partial GEMM + PRUNING is viable in iteration 1 (possibly with a conservative ) or if a brief warm-up on a sample can safely skip full GEMM.
Early Termination by Recall (ETR)
- ETR uses recall measured on user-supplied or data-sampled queries; risk of overfitting to non-representative queries is unaddressed. Evaluate ETR on held-out query sets or production logs to ensure generalization.
- Sensitivity of ETR to search parameters is unexplored: termination may differ across , top-, and metric; provide a robust, multi-parameter ETR or a procedure to calibrate ETR for deployment settings.
- Tolerance and patience values (e.g., 0.005, patience=2) are empirical; propose criteria or automated selection based on variance of recall estimates and desired confidence.
- For large collections (e.g., ), computing ground truth for 1000 queries may no longer be “minimal” overhead; evaluate scalable/approximate ground truth strategies and their impact on ETR decisions.
Generality across metrics and data types
- The method is primarily evaluated under /angular equivalences; generalization to inner product (MIPS), cosine without normalization, or other metrics (e.g., learned or Mahalanobis distances) is not described.
- It is unclear how ADSampling thresholds and pruning decisions adapt to different metrics; provide metric-specific derivations or calibrations.
- Sparse or mixed-modal embeddings (e.g., very high-dimensional sparse text, multi-view embeddings) are not evaluated; assess whether PDX and pruning remain effective.
GPU-specific design and limits
- GPU implementation details are sparse: kernel fusion strategy, memory access patterns, warp-level load balancing, use of cuBLASLt/CUTLASS, and interaction with TF32/FP16/BF16 precisions need explication.
- Memory footprint and tiling strategies on GPU (for large and ) are not documented; quantify peak memory, batch sizing, and the trade-off between tiling granularity and kernel-launch overhead.
- Portability across GPU architectures (NVIDIA generations, AMD/Intel GPUs) and sensitivity to math modes (TF32 vs FP32) are untested; evaluate numeric stability and performance variance.
Systems scalability and scheduling
- Thread-level load imbalance in PRUNING is acknowledged but unresolved for many-core settings (e.g., ≥64 threads): evaluate advanced scheduling (work stealing, two-dimensional partitioning over points and centroids) and NUMA-aware strategies.
- Distributed or multi-node indexing is not evaluated: explore how SuperKMeans composes with hierarchical k-means in distributed settings (data partitioning, centroid synchronization, communication costs).
- Energy efficiency and cost-performance (perf/Watt) across CPUs and GPUs are not reported; provide analyses to guide deployment choices in cloud vs on-prem environments.
Memory footprint and precision
- End-to-end memory usage (distance buffers, norms, PDX-transposed centroids) is not quantified for large and ; document peak RAM/VRAM and propose memory-saving modes (streaming, reduced precision).
- Effects of lower precision (FP16/BF16/INT8) on GEMM, PRUNING thresholds, and final recall are unexplored; characterize numeric stability and potential speedups with mixed precision.
Evaluation scope and methodology
- IVF performance was assessed at a single probe rate (1% of ); provide full –recall curves to show robustness across operating points.
- Sampling analysis focuses on recall and explored vectors but not on latency distributions during search; report p50/p95/p99 search latency impacts due to cluster imbalance from sampling.
- The claim that -means++ is detrimental to index quality is referenced but not fully substantiated across diverse datasets and ; provide broader evidence and analyze when/why -means++ harms IVF quality.
- Real-world workloads (e.g., non-stationary query distributions, multi-tenant scenarios) are not simulated; evaluate robustness when query distributions shift after indexing.
Integration with broader indexing pipelines
- Interaction with PQ/OPQ training and residual quantization is untested: does SuperKMeans preserve downstream ANN accuracy and compression efficacy compared to vanilla training?
- Incremental/online updates (insertions/deletions and periodic re-clustering) are not addressed; design and evaluate incremental SuperKMeans and ETR policies for continuously evolving collections.
- The reported “250× faster” hierarchical -means result lacks methodological details (branching factor, tree depth, sampling per level, quality trade-offs); provide a transparent evaluation and quality benchmarks.
Practical reproducibility and portability
- Results rely on highly optimized BLAS backends (IntelMKL, AOCL-BLIS, Apple AMX); report performance with vendor-neutral OpenBLAS and across compiler flags to ensure reproducibility.
- Provide a detailed description of the ADSampling threshold function and “likely()” decision rule used in implementation to enable faithful re-implementation by others.
- Document integration pathways with common vector databases (e.g., Milvus, FAISS IVF variants) and migration considerations (data layout conversions, memory planners, API compatibility).
Miscellaneous open directions
- Explore structured random rotations (e.g., SRHT/FJLT) to reduce the cost of preprocessing versus dense rotations while preserving pruning effectiveness.
- Investigate learned or data-adaptive selection (e.g., regressors on simple dataset statistics: kurtosis/skewness per dimension, intrinsic dimensionality) to predict speedups and choose strategies a priori.
- Study robustness to outliers and rare clusters, and whether additional regularization or robust -means variants (trimmed, -medoids initializations) improve IVF quality under pruning.
Practical Applications
Immediate Applications
These applications can be deployed with the paper’s open-source implementation and current ecosystems (FAISS, cuVS, Milvus, Weaviate, etc.), leveraging SuperKMeans’ two-phase GEMM+PRUNING, Adaptive Sampling, PDX-friendly layout, and Early Termination by Recall (ETR).
- Accelerated IVF index construction in vector databases
- Sectors: software (vector databases, search platforms), e-commerce, media, legal, finance, healthcare
- What: Replace vanilla k-means/coarse quantizer training with SuperKMeans to build IVF/IVF-PQ indexes 3–7x faster on CPUs and up to 4x on GPUs, with matched recall and cluster balance.
- Tools/workflows: Integrate into FAISS- or cuVS-based build pipelines; add SuperKMeans as a clusterer option in Milvus/Weaviate/Qdrant/LanceDB; provide a CLI/SDK “superkmeans index” command for ingestion nodes.
- Assumptions/dependencies: High-dimensional embeddings (typically d ≥ 384); k in the √N to 4√N range; optimized BLAS (MKL/BLIS/Accelerate/OpenBLAS compiled for the target CPU) or cuBLAS; distance metric compatible with ADSampling (L2 or cosine via normalization).
- Faster reindexing and continuous refresh for RAG and semantic search
- Sectors: software (LLM/RAG platforms), enterprise search, developer tools
- What: Cut reindexing SLAs from hours to minutes; enable frequent ingestion/retraining of embeddings without degrading recall.
- Tools/workflows: Use ETR to auto-stop when recall plateaus and sample 20–30% of data for centroid training; schedule nightly/rolling re-clusters.
- Assumptions/dependencies: Representative query set (or sampled queries) to drive ETR; ground truth estimation cost is small but nonzero (4–6% runtime in paper’s profiling).
- Cost and energy reduction for index building
- Sectors: cloud platforms, FinOps, sustainability
- What: Reduce CPU/GPU-hours and carbon footprint for large-scale indexing jobs (10M+ vectors), especially in multi-tenant/managed services.
- Tools/products: “Green indexing” preset using [email protected] and 20–30% sampling; Graviton/ARM and Apple Silicon builds validated by the paper.
- Assumptions/dependencies: Benefits largest at high d and large k; diminishing returns for very small k (e.g., k < 100).
- Default changes in production pipelines: random init, fewer iterations
- Sectors: software (IR/ML infrastructure)
- What: Switch from k-means++ to random initialization; cap iterations at 5–10 with ETR—empirically no loss in retrieval quality.
- Tools/workflows: Update default configs in FAISS-based pipelines (e.g., IVF training iters=10, init=random).
- Assumptions/dependencies: Embedding regimes with fuzzy Voronoi cells (typical for modern LLM/CLIP embeddings); monitor recall to validate.
- Aggressive yet safe sampling for faster builds
- Sectors: all using vector search at scale
- What: Train centroids with 20–30% of points while keeping recall stable; balance explored-vectors vs. build-time.
- Tools/workflows: Sampling-aware trainer that targets a fixed “vectors explored” budget; auto-tune sampling until cluster balance stabilizes.
- Assumptions/dependencies: Heavier sampling can increase explored vectors at query time if clusters become imbalanced; validate on workload.
- GPU-accelerated clusterer in existing indexing services
- Sectors: cloud AI services, MLOps platforms
- What: Use SuperKMeans GPU mode (with cuVS) for multi-million vector datasets; target 4x speedups.
- Tools/workflows: Containerized “index-builder” jobs with CUDA/cuBLAS/cuVS; auto-switch CPU/GPU by data scale and queue depth.
- Assumptions/dependencies: Sufficient GPU memory; tuned kernel launch configs; consistent normalization pipeline for cosine/L2.
- Hierarchical k-means turbo-builds for very large collections
- Sectors: e-commerce catalogs, social media, threat intel, logging/observability
- What: Combine SuperKMeans with hierarchical k-means for 10M+ embeddings (paper reports up to 250x vs FAISS in one setup).
- Tools/workflows: Multi-level coarse quantizer training; staged ingestion where upper levels are pre-trained and reused.
- Assumptions/dependencies: Engineering integration effort for multi-level training; careful memory management and batch scheduling.
- On-device/edge indexing for personal search and media
- Sectors: daily life, mobile, edge/IoT
- What: Local semantic search over notes, photos, emails, or code snippets with reduced battery/time cost; Apple M-series and ARM validated.
- Tools/products: Mobile/desktop apps that build small IVF indexes locally; “quick reindex” button using ETR and sampling.
- Assumptions/dependencies: Smaller k reduces pruning benefits; still observe wins at high-d models; need OS-optimized BLAS.
- Recommender systems: faster periodic re-clustering
- Sectors: media, retail, fintech
- What: Refresh item/user embedding clusters more frequently to capture drift without missing SLAs.
- Tools/workflows: Nightly/weekly batch jobs with ETR; evaluate recall on representative interaction queries.
- Assumptions/dependencies: Requires a query proxy (historical interactions) that is predictive of online recall.
- Academic and benchmarking uses
- Sectors: academia, education
- What: Use open-source SuperKMeans to study high-d clustering, SIMD/GEMM co-design, and recall-aware early stopping.
- Tools/workflows: Course labs on CPU vs GPU performance, ablations (PDXification, initial thresholds), dataset-wide scaling (k from 102 to 105).
- Assumptions/dependencies: Reproduction needs tuned BLAS and careful dataset normalization.
Long-Term Applications
These opportunities require additional research, engineering, or scaling beyond the paper’s current implementation.
- Streaming and incremental SuperKMeans for dynamic corpora
- Sectors: news feeds, social, security, observability
- What: Online updates to centroids with recall-aware early stopping under concept drift.
- Tools/products: Incremental clusterer with mini-batches; periodic ETR checks on rolling query windows.
- Dependencies: Algorithmic extensions for true online k-means; stability guarantees; background rebalancing for cluster skew.
- Hybrid graph–partition indexes with fast re-partitioning
- Sectors: vector DBs, large search platforms
- What: Use SuperKMeans for rapid re-partitioning that improves navigability of graph-based ANN (e.g., HNSW) or SPANN-like hybrids.
- Tools/workflows: Periodic “re-shard and rewire” jobs that minimize downtime; two-phase rollout of new centroids.
- Dependencies: Integration with graph maintenance and consistency; memory headroom for dual-index phases.
- Recall-aware, self-tuning vector DBs (closed-loop SLOs)
- Sectors: managed databases, cloud AI services
- What: Systems that auto-tune d′, sampling ratio, k, and ETR tolerance to meet latency/recall SLOs per-collection.
- Tools/products: Control-plane service with telemetry-driven tuning; per-tenant policies (latency budgets, energy caps).
- Dependencies: Real-time recall estimation (ground truth proxies); safe exploration; robust monitoring.
- Privacy-preserving and federated indexing
- Sectors: healthcare, finance, gov
- What: Leverage random rotations and pruning-friendly layouts as part of privacy-enhancing pipelines; federated centroid training across silos.
- Tools/workflows: Secure enclaves or MPC for centroid updates; share only rotated summaries.
- Dependencies: Formal privacy guarantees; provenance and auditability; acceptable utility under rotations/sampling.
- Specialized hardware co-design and kernels
- Sectors: semiconductors, cloud hardware
- What: PDX-friendly memory layouts and pruning kernels accelerated on NPUs/AMX/TPUs; ISA-level support for progressive pruning.
- Tools/products: Vendor-optimized SuperKMeans libraries; kernel fusion (GEMM + early-exit accumulation).
- Dependencies: Hardware vendor collaboration; compiler/runtime support; sustained software ecosystem adoption.
- Distributed, billion-scale hierarchical SuperKMeans
- Sectors: web-scale search, foundation model infra
- What: Multi-node hierarchical training for 100M–1B vectors with recall-aware checkpoints.
- Tools/workflows: Data-parallel coarse quantizer training; elastic, failure-tolerant index builders.
- Dependencies: Partitioning strategies for communication minimization; cross-node BLAS scheduling; fault recovery.
- Generalization of GEMM+PRUNING beyond k-means
- Sectors: ML platforms, analytics
- What: Apply Adaptive Sampling + progressive pruning to GMM/EM, k-medoids, RQ/OPQ codebook training, and other distance-heavy iterative methods.
- Tools/workflows: Shared pruning runtime with pluggable distance metrics; ablations across tasks.
- Dependencies: Theoretical guarantees per algorithm; metric-specific pruning thresholds; quality validation.
- Standardized recall-aware early stopping across ecosystems
- Sectors: open-source IR/ML tooling
- What: ETR-like APIs in FAISS/cuVS/Scikit-learn and vector DBs, with ground-truth proxies and sampling guidance.
- Tools/products: “Recall meter” modules; benchmarks that report time-to-ETR instead of fixed-iteration timing.
- Dependencies: Agreement on proxy metrics and patience thresholds; dataset-specific calibration.
- Energy-aware scheduling and policy guidance
- Sectors: cloud operations, sustainability policy
- What: Scheduling policies that route index builds to ARM/energy-efficient SKUs during off-peak; procurement guidelines favoring recall-aware early stopping.
- Tools/workflows: FinOps dashboards showing energy/time savings from SuperKMeans vs baselines; carbon reporting.
- Dependencies: Provider support for accurate energy metering; organizational policy adoption.
Notes on feasibility and transferability
- Where it works best: high-dimensional embeddings (text/image/code) with large k (√N to 4√N), typical of IVF-based systems.
- Where benefits narrow: small k (≤100) or low-dimensional datasets; pruning yields less advantage when centroids fit in L1/L2.
- Metrics and distance: L2 and cosine (via normalization) are natural fits; other metrics may require adapted pruning thresholds.
- ETR robustness: Needs a representative query set; otherwise, risk of premature stopping or overfitting to the proxy.
- Sampling: 20–30% is a strong default, but verify cluster balance and “vectors explored” on your workload.
- Engineering: Ensure BLAS is properly optimized for target CPUs; use dynamic scheduling for multi-threaded pruning; validate GPU memory limits for very large k.
Glossary
- ADSampling (Adaptive Sampling): A pruning technique that estimates distances using a small, adaptively chosen subset of dimensions to early-abort most comparisons. "Efficient pruning kernels are achieved by using Adaptive Sampling (ADSampling)~\cite{adsampling} and by keeping centroids in memory using the PDX layout~\cite{pdx}."
- AMX: Apple’s matrix-multiplication coprocessor used to accelerate linear algebra on Apple Silicon. "Apple Accelerate uses AMX, a co-processor in Apple Silicon chips specialized in matrix multiplication operations~\cite{amxpaper, corsix_amx}."
- AOCL-BLIS: AMD’s optimized implementation of the BLAS linear algebra API. "Some notable examples of BLAS implementations include IntelMKL for Intel CPUs, AOCL-BLIS for AMD CPUs, Apple Accelerate for Apple Silicon chips, and OpenBLAS, which can be compiled for various CPU microarchitectures."
- angular distance: An angle-based distance metric (often derived from cosine similarity) used for measuring similarity between vectors. "Note: Scikit-Learn is not plotted in the datasets that need an angular distance, since this is an unsupported feature."
- Apple Accelerate: Apple’s optimized math and signal-processing framework that provides BLAS and uses AMX on Apple Silicon. "Some notable examples of BLAS implementations include IntelMKL for Intel CPUs, AOCL-BLIS for AMD CPUs, Apple Accelerate for Apple Silicon chips, and OpenBLAS, which can be compiled for various CPU microarchitectures."
- BLAS: A standardized API for basic linear algebra routines (vector and matrix operations) with highly optimized implementations. "BLAS libraries are accelerators for linear algebra operations tailored for modern CPUs."
- cover trees: Hierarchical metric trees that enable nearest-neighbor search in general metric spaces. "Also, we shifted our focus away from methods that use auxiliary data structures for clustering (e.g., seeded search graphs~\cite{usearch, seededsearchgraphs}, SA-trees~\cite{satrees}, cover trees~\cite{covertrees}), as the costs associated with building these structures often exceed those of -means."
- cuVS: A GPU-accelerated library for vector search (part of NVIDIA RAPIDS). "SuperKMeans' clustering is up to 7x faster than FAISS and Scikit-Learn on modern CPUs and up to 4x faster than cuVS on GPUs (Figure 1), while maintaining the quality of the resulting centroids for vector similarity search tasks."
- DBSCAN: A density-based clustering algorithm that groups points with many close neighbors and marks outliers. "we will not cover other clustering algorithms, such as DBSCAN~\cite{dbscan} and HDBSCAN~\cite{hdbscan}, as they are not commonly used for building vector search indexes because they form clusters based on density rather than proximity to centroids."
- Early Termination by Recall (ETR): An early-stopping rule for k-means that halts when retrieval recall no longer improves. "Finally, we introduce a novel early termination mechanism named Early Termination by Recall (ETR)."
- Elkan's k-means: A k-means variant that uses triangle inequality bounds to prune distance computations. "One example is Elkan's -means variant, which achieves theoretical speedups through pruning but, in practice, is slower than a complete GEMM for distance calculations."
- FAISS: A library for efficient similarity search and clustering of dense vectors. "Despite this, the implementation of -means in modern vector systems like FAISS~\cite{faisspaper} has not evolved beyond vanilla -means (i.e., Lloyd's -means) with tuned hyperparameters."
- GEMM (General Matrix Multiplication): The core matrix-matrix multiplication kernel used to accelerate distance computations via linear algebra. "This is because Lloyd's -means can leverage highly optimized General Matrix Multiplication (GEMM) routines to accelerate the pairwise distance calculation between data points and cluster centroids---the main bottleneck of -means."
- HDBSCAN: A hierarchical extension of DBSCAN that discovers clusters of varying densities. "we will not cover other clustering algorithms, such as DBSCAN~\cite{dbscan} and HDBSCAN~\cite{hdbscan}, as they are not commonly used for building vector search indexes because they form clusters based on density rather than proximity to centroids."
- hierarchical k-means: A recursive clustering strategy that builds a tree of centroids for scalable partitioning. "Furthermore, we combine SuperKMeans' acceleration with hierarchical -means~\cite{micronn, turbopuffer, kmeanselastic, jin2026curator, spfresh}."
- intrinsic dimensionality: The effective dimensionality that governs distance behavior and concentration in data. "A higher intrinsic dimensionality also diminishes the benefits of pruning (e.g., GloVe)."
- Inverted-Files (IVF): A partition-based index where vectors are assigned to clusters (lists), searching a subset of lists at query time. "This indexing method, commonly known as Inverted-Files (IVF)~\cite{pqivf, faisspaper}, is one of the most widely used indexes in vector systems \cite{faisspaper, micronn, vectordbs, milvus, quake}."
- k-means++: A seeding strategy that initializes centroids to speed up convergence and improve quality. "and iii) that using -means++ initialization is detrimental for index quality."
- Lloyd's algorithm: The standard iterative k-means procedure of assignment and centroid update. "The vanilla version of -means is known as Lloyd's algorithm~\cite{kmeans}."
- OpenBLAS: An open-source, highly optimized BLAS implementation. "Some notable examples of BLAS implementations include IntelMKL for Intel CPUs, AOCL-BLIS for AMD CPUs, Apple Accelerate for Apple Silicon chips, and OpenBLAS, which can be compiled for various CPU microarchitectures."
- PDX layout: A block-column-major data layout for centroids that improves cache access and pruning efficiency. "Efficient pruning kernels are achieved by using Adaptive Sampling (ADSampling)~\cite{adsampling} and by keeping centroids in memory using the PDX layout~\cite{pdx}."
- PDXification: The transformation step that reorganizes centroids into the PDX layout. "\;"
- random rotation matrix: An orthogonal matrix used to rotate data so that information is more evenly spread across dimensions. ""
- recall (VSS): The fraction of true nearest neighbors retrieved by an approximate search. "The quality of these retrieved answers is typically measured using the recall metric, which quantifies the proportion of retrieved vectors that are truly the closest to the query."
- SA-trees: Spatial approximation trees used for efficient proximity search. "Also, we shifted our focus away from methods that use auxiliary data structures for clustering (e.g., seeded search graphs~\cite{usearch, seededsearchgraphs}, SA-trees~\cite{satrees}, cover trees~\cite{covertrees}), as the costs associated with building these structures often exceed those of -means."
- seeded search graphs: Graph-based structures initialized with selected seeds to support fast approximate nearest-neighbor search. "Also, we shifted our focus away from methods that use auxiliary data structures for clustering (e.g., seeded search graphs~\cite{usearch, seededsearchgraphs}, SA-trees~\cite{satrees}, cover trees~\cite{covertrees}), as the costs associated with building these structures often exceed those of -means."
- sgemm: The single-precision GEMM routine in BLAS (float32 matrix multiply). "For our purposes, we are only interested in the \codeword{sgemm} routine inside BLAS that does a \underline{s}ingle precision (\codeword{float32}) \underline{ge}neral \underline{m}atrix \underline{m}ultiply."
- SIMD: Single Instruction, Multiple Data; CPU vectorization for processing multiple data elements per instruction. "efficient vectorization (SIMD), CPU/GPU-friendly algorithms, evaluation across CPU microarchitectures, comprehensive evaluation in high-dimensional embeddings datasets () using a high number of clusters (), and comparison against SOTA systems."
- triangle inequality: A metric property leveraged to bound and prune distance computations. "ADSampling offers much higher, more effective pruning capabilities than the triangle inequality~\cite{pdx, adsampling, rabitq}."
- vector embeddings: High-dimensional numeric representations of data (e.g., text, images) produced by models. "We present SuperKMeans: a -means variant designed for clustering collections of high-dimensional vector embeddings."
- Vector similarity search (VSS): The task of finding the most similar vectors to a query under a chosen metric. "VSS consists of finding the vectors in a collection that are the most similar to a given query vector, based on a distance or similarity metric."
- Voronoi cells: Regions of space where every point is closest to the same centroid; used to conceptualize cluster boundaries. "This phenomenon leads to densely populated boundaries of the Voronoi cells."
- within-cluster sum of squares (WCSS): The sum of squared distances from points to their assigned centroids (also called inertia). "Note that both algorithms also yield a similar within-cluster sum of squares value (WCSS, also known as inertia)."
Collections
Sign up for free to add this paper to one or more collections.