- The paper presents an open framework delivering inclusive multilingual embeddings that address English-centric biases with documented data recipes and transparent training protocols.
- It employs a two-stage training pipeline with Matryoshka Representation Learning, enabling dynamic embedding dimensionality and efficient model compression across multiple scales.
- Empirical results demonstrate superior performance on 17 MTEB benchmarks across 282 natural languages, optimizing models for diverse, real-world deployment scenarios.
F2LLM-v2: Scalable, Inclusive, and Efficient Multilingual Embeddings
Motivation and Context
The F2LLM-v2 project addresses critical limitations in the current research ecosystem around multilingual text embeddings: pervasive English-centric bias in training data and benchmark coverage, and a lack of training transparency among frontier models. Existing state-of-the-art LLM-based embedding models (e.g., Gemini-Embedding, Qwen3-Embedding) center their evaluations on high-resource language tasks, and generally fail to provide full transparency in training data and protocols, impeding reproducibility and fair benchmarking. F2LLM-v2 directly confronts both issues by delivering a large family of open, multilingual embedding models—with documented data recipes, intermediate checkpoints, and source code—trained on a globally diverse corpus.
Data Curation: Coverage and Diversity
The foundation of F2LLM-v2 is a curated dataset (60M samples) encompassing 282 natural languages (ISO-639-3) and over 40 programming languages. Real-world data availability prioritization is explicit; mid- and low-resource languages such as Malay, Vietnamese, Hebrew, and Yoruba feature prominently, ensuring representational inclusivity that extends beyond the coverage of prior open datasets (e.g., KaLM-Embedding). The distribution underscores deliberate effort to rebalance linguistic representation for practical global deployment.
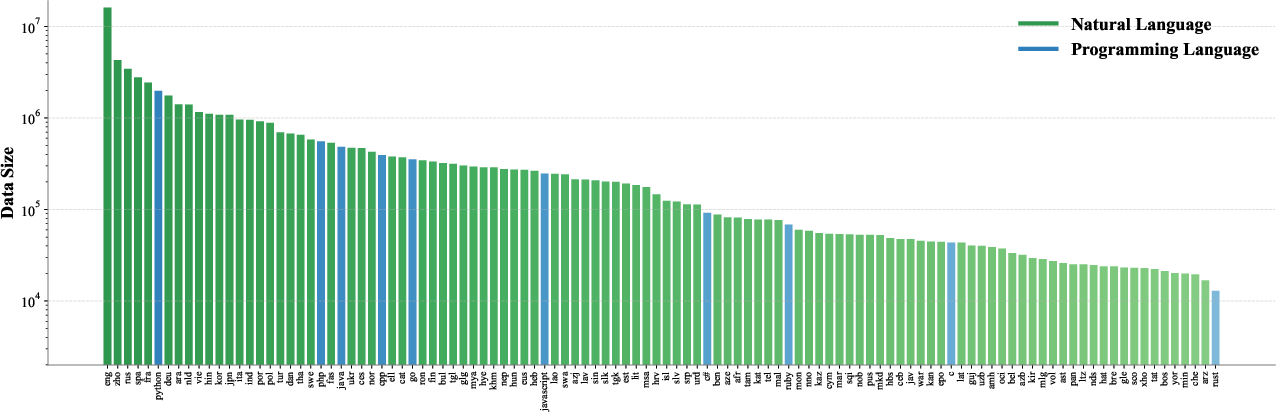
Figure 1: Distribution of the top-100 natural languages and top-10 programming languages in the F2LLM-v2 training corpus, highlighting broad linguistic and code diversity.
Functional diversity is a second axis of heterogeneity. The collection spans retrieval (QG/QA), clustering (topic, intent, scenario), classification (sentiment, NLI, paraphrase), summarization, code search, and more, sourced from 157 public datasets. All data is restructured into three supervised formats—retrieval, clustering, and two-way classification—enabling unified contrastive learning across distinct tasks.
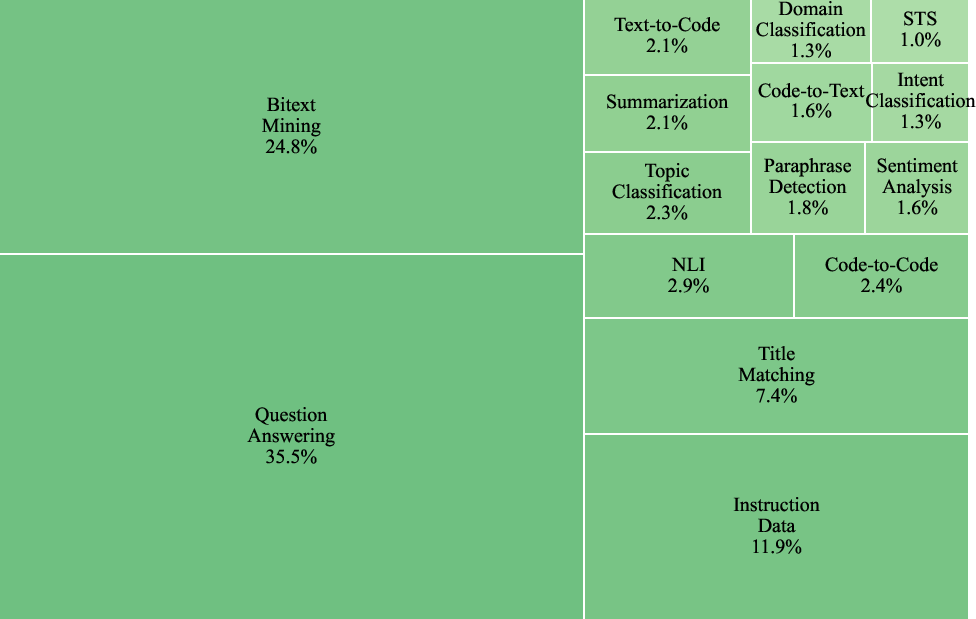
Figure 2: The task type distribution in the F2LLM-v2 training data, illustrating broad coverage across retrieval, clustering, and classification paradigms.
Model Family, Architecture, and Training Pipeline
F2LLM-v2 constitutes eight model scales (80M to 14B parameters), all adopting dense Transformer decoders based on Qwen3 architectures. Smaller models (80M–330M) are topologically pruned from the 0.6B model based on activation norm heuristics. All models extract sequence embeddings from the EOS token’s final layer.
Training unfolds in two stages:
- Semantic Foundation: Retrieval-centric data (~27M samples) is used to initialize semantic spaces, focusing on language- and domain-diverse corpus segments (e.g., CodeSearchNet, CLIRMatrix, ParaCrawl).
- Downstream Specialization: Balanced sampling across all tasks (max 80k per source) for 18M samples, injecting task instructions and randomly applying document-side instructions to further enhance generalization.
Matryoshka Representation Learning (MRL) is employed throughout, concentrating semantic information in leading dimensions of the embeddings, thus promoting flexibility for resource-constrained deployment scenarios.
Model Compression: Pruning and Distillation
The F2LLM-v2 approach to computational inclusivity leverages three forms of model compression:
- Structured pruning along hidden, intermediate, and layer dimensions, using activation-norm based criteria for all but layer selection (where the first n layers are retained).
- Knowledge distillation for the low-parameter variants, using mean squared error supervision from teacher to student on [query, positive, hard-negative] triplets.
- Empirical results confirm notable mitigation of performance degradation; distillation also provides quality enhancement at mid-scale (0.6B, 1.7B), demonstrating its utility past extreme compression regimes.
Empirical Results
Multilingual and Language-Specific Leaderboards
F2LLM-v2 models are evaluated on 17 Massive Text Embedding Benchmark (MTEB) aggregates: Multilingual, Code, Medical, and 14 language-specific leaderboards. The 14B model achieves rank-1 on 11 leaderboards and consistently outperforms previous SOTA and strong baselines in under-served languages, as visualized below.
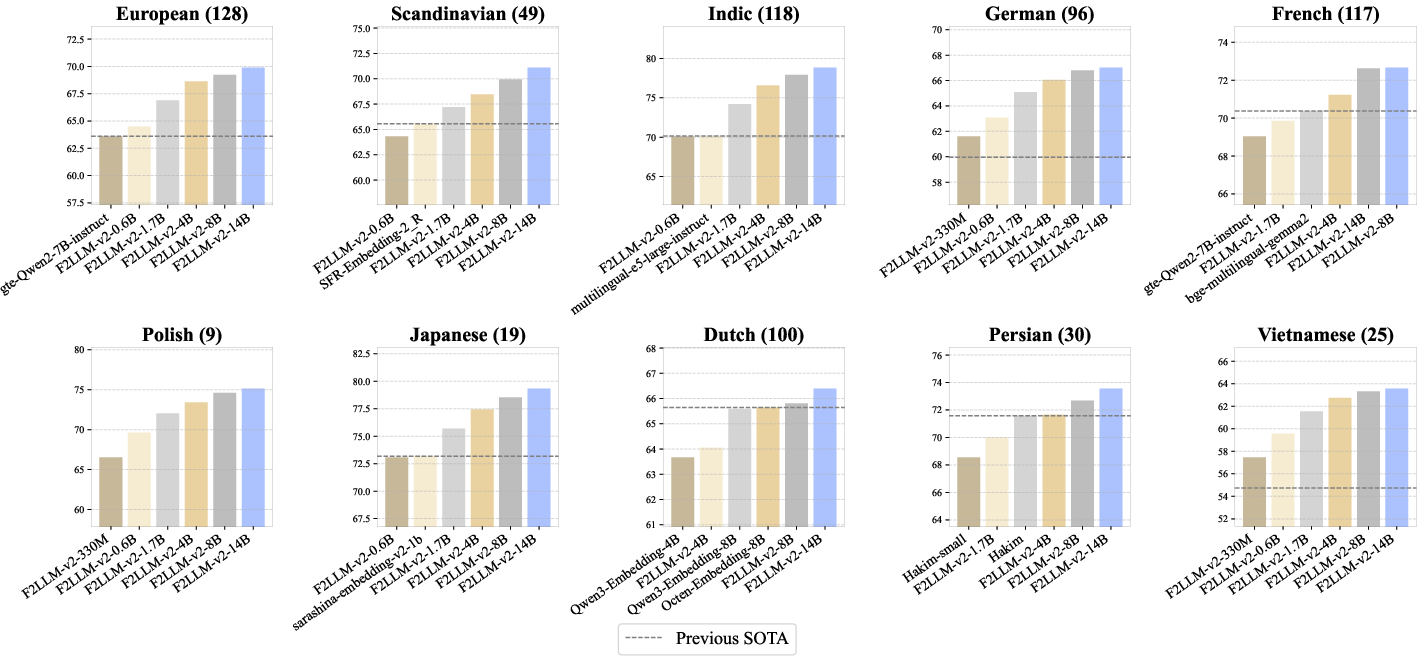
Figure 3: The top six models on ten language-specific MTEB leaderboards, with the SOTA line and counts of comprehensive submissions, demonstrating F2LLM-v2's cross-linguistic superiority.
Notably, the 330M and 0.6B models outperform Qwen3-Embedding and EmbeddingGemma at their respective parameter counts on most language- and code-centric benchmarks. The performance gap is especially visible in mid- and low-resource leaderboards (e.g., Polish, Vietnamese, Indic), where competing models historically failed to register competitive results.
Empirical Highlights:
- 14B model: Average score 71.72 across 430 tasks; top rank in Multilingual, Scandinavian, Indic, German, French, Polish, and Persian benchmarks.
- 80M and 160M models: Optimal inferences for edge deployments, maintaining competitive scores relative to larger baselines of the last generation despite radical parameter reduction.
Matryoshka Representation Learning (MRL) Impact
Ablations show that MRL empowers users to dynamically adjust embedding dimensionality without catastrophic loss. For example, the 330M model using the full 896D embedding matches the truncated (32D) performance of the 14B model.
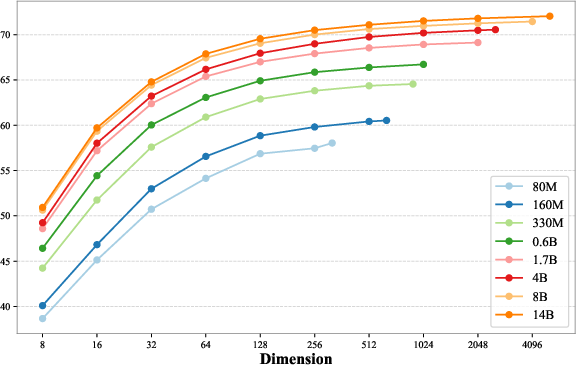
Figure 4: Model performance as a function of representation dimensionality, illustrating the efficiency of MRL in concentrating semantic information in leading dimensions.
Critically, the architecture provides robust trade-offs between memory, inference latency, and accuracy, furthering deployment realism for diverse hardware targets and on-device applications.
Implications and Future Directions
The open, end-to-end reproducibility protocol for F2LLM-v2 is a substantial response to the opacity of competitive embeddings research, stimulating transparent community benchmarking and catalyzing research in fair evaluation for global NLP. The explicit focus on computational inclusivity enables adaptive scaling for device, edge, and enterprise use-cases, advancing true democratization of multilingual NLP infrastructure.
Future research directions include dynamic resource allocation in Matryoshka adapters, further scaling of mid- and low-resource language coverage via cross-linguistic transfer, and unified embeddings leveraging parallel instruction-tuned objectives across text, code, and multimodal corpora. The open-source release of code, weights, intermediate checkpoints, and dataset recipes is strategically positioned to foster competitive, reproducible, and extensible model development in the multilingual embeddings domain.
Conclusion
F2LLM-v2 establishes a new paradigm for inclusive, transparent, and performant multilingual embedding models. The extensiveness in both model and corpus design, combined with strong leaderboard performance and pragmatic deployment features (scalable dimensions, parameter-efficient variants), redefines the practical and scientific landscape for embedding models covering the global diversity of languages (2603.19223).

