- The paper introduces a cascading annealed language learning schedule that progressively adds languages and reduces mask rates to boost low-resource language performance.
- The paper leverages a ModernBERT-inspired architecture with the Gemma 2 tokenizer and phased training, yielding superior results on benchmarks like GLUE and XTREME compared to XLM-R.
- The paper demonstrates notable efficiency enhancements using Flash Attention 2 and optimized model merging, enabling scalable processing up to 8192-token contexts.
mmBERT: A Modern Multilingual Encoder with Annealed Language Learning
Introduction
mmBERT presents a significant advance in encoder-only multilingual language modeling by introducing a suite of architectural and training innovations tailored for both high- and low-resource languages. The model is trained on 3T tokens spanning 1833 languages, leveraging a ModernBERT-inspired architecture and a Gemma 2 tokenizer. The core contributions include a cascading annealed language learning (ALL) schedule, an inverse mask ratio schedule, and a strategic introduction of low-resource languages during the decay phase. These innovations collectively yield strong empirical gains over prior multilingual encoders, notably XLM-R, and demonstrate competitive or superior performance to large-scale decoder models such as OpenAI's o3 and Google's Gemini 2.5 Pro on low-resource languages.
Model Architecture and Training Regimen
mmBERT adopts the ModernBERT architecture, with 22 layers and an intermediate dimension of 1152. The base model uses a hidden size of 768 (307M total parameters), while the small variant uses 384 (140M total parameters). The Gemma 2 tokenizer is employed for robust multilingual tokenization, though the authors note that future work should consider Gemma 3 with prefix space support for improved NER and POS tagging.
The training is divided into three phases:
- Base Pre-training: 2.3T tokens, 60 languages, 30% masking rate, standard learning rate and batch size warmup.
- Mid-Training (Context Extension): 600B tokens, 110 languages, context length extended to 8192 via RoPE, 15% masking rate, higher-quality data.
- Decay Phase: 100B tokens, 1833 languages, 5% masking rate, inverse square root learning rate decay, and three data mixtures (English-focused, 110 languages, 1833 languages).
A novel aspect is the progressive lowering of the mask rate and the staged introduction of languages, which is coupled with an annealed temperature sampling schedule to balance high-resource and low-resource language exposure.
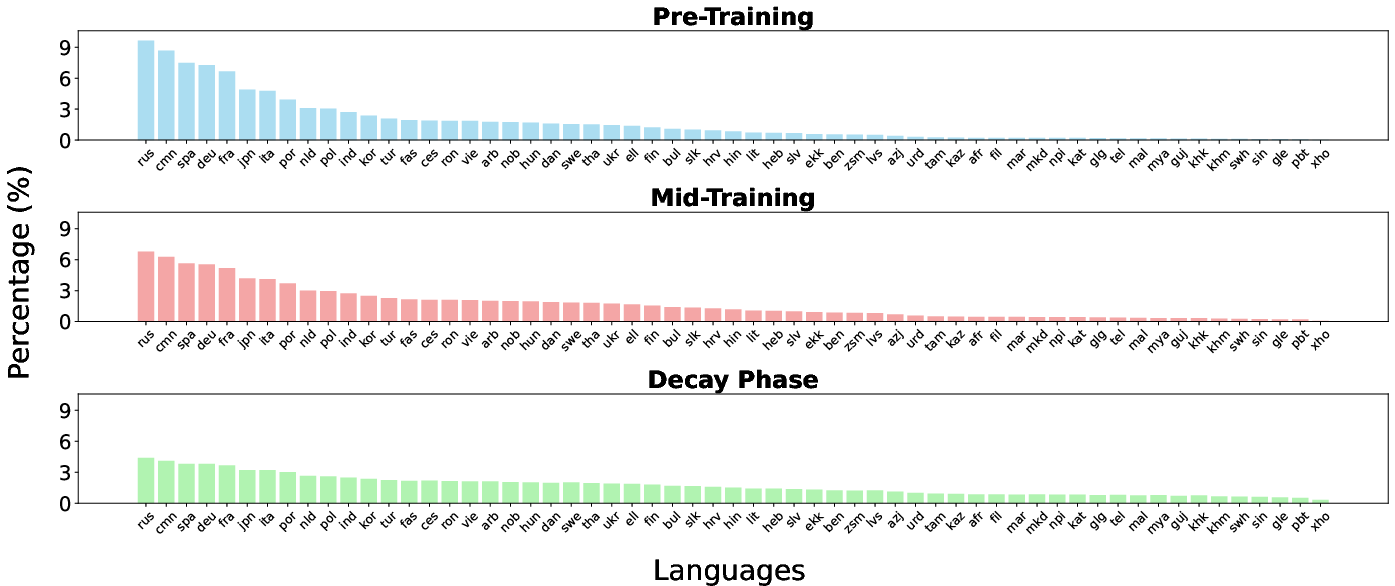
Figure 1: The inverse temperature sampling ratio for FineWeb2 data, showing the annealing from high-resource bias (τ=0.7) to more uniform sampling (τ=0.3) as training progresses.
Model merging via TIES-merging is used to combine the best checkpoints from each decay mixture, mitigating parameter interference and maximizing performance across language groups.
Cascading Annealed Language Learning
The ALL schedule is a central innovation. Unlike prior work with fixed language sets and static sampling temperatures, mmBERT incrementally adds languages and anneals the sampling temperature. This approach avoids excessive overfitting on low-resource languages and leverages transfer from high-resource languages. The staged addition is as follows:
- Stage 1: 60 languages + code, high-resource focus.
- Stage 2: 110 languages, mid-resource inclusion.
- Stage 3: 1833 languages, all available scripts and languages.
The temperature for sampling is annealed from 0.7 to 0.3, moving from a high-resource bias to a more uniform distribution.
Empirical Results
Natural Language Understanding
On GLUE, mmBERT small achieves an average of 84.7, outperforming Multilingual MiniLM (78.3) and even surpassing XLM-R base. mmBERT base achieves 86.3, approaching ModernBERT's monolingual English performance despite a multilingual focus.
On XTREME, mmBERT base outperforms all other multilingual encoders (72.8 average vs XLM-R's 70.4), with notable gains in classification (XNLI: 77.1 vs 74.6) and QA (TyDiQA: 74.5 vs 70.5). Structured prediction lags slightly, attributed to tokenizer limitations.
Retrieval and Embedding Tasks
On MTEB v2 (English), mmBERT base matches ModernBERT (53.9 vs 53.8) and outperforms all multilingual baselines. On MTEB v2 (multilingual), mmBERT base leads with 54.1, a 1.5-point gain over XLM-R.
On code retrieval (CoIR), mmBERT base achieves 42.2, outperforming all massively multilingual models except EuroBERT-210m, which benefits from proprietary data.
Low-Resource Language Learning
A key result is the rapid performance gain on languages introduced only in the decay phase. For Tigray and Faroese, mmBERT base shows a 68% and 26% increase in F1, respectively, when the language is included in the decay phase. On FoQA (Faroese), mmBERT base surpasses Gemini 2.5 Pro and o3 by 6 and 8.3 points, respectively.
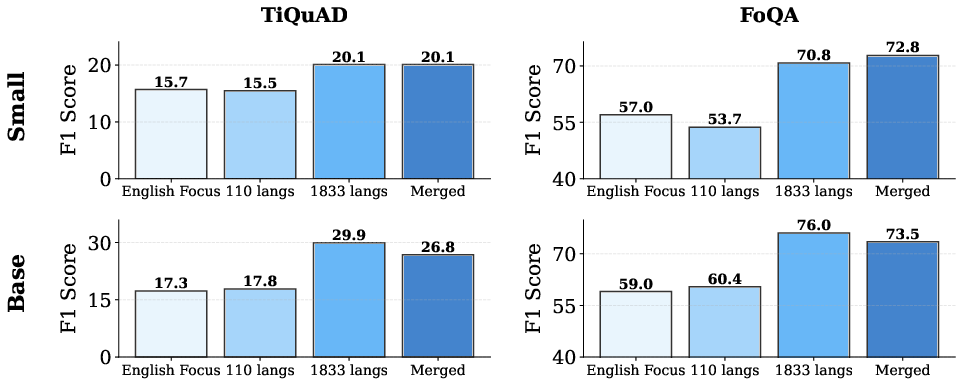
Figure 2: Performance improvements on Tigray and Faroese when languages are introduced in the decay phase, demonstrating the efficacy of the annealed language learning schedule.
Efficiency
mmBERT models are significantly more efficient than prior multilingual encoders, enabled by Flash Attention 2 and unpadding inherited from ModernBERT. mmBERT base is over 2x faster on variable sequence lengths and up to 4x faster on long contexts compared to XLM-R and MiniLM, which are limited to 512 tokens.
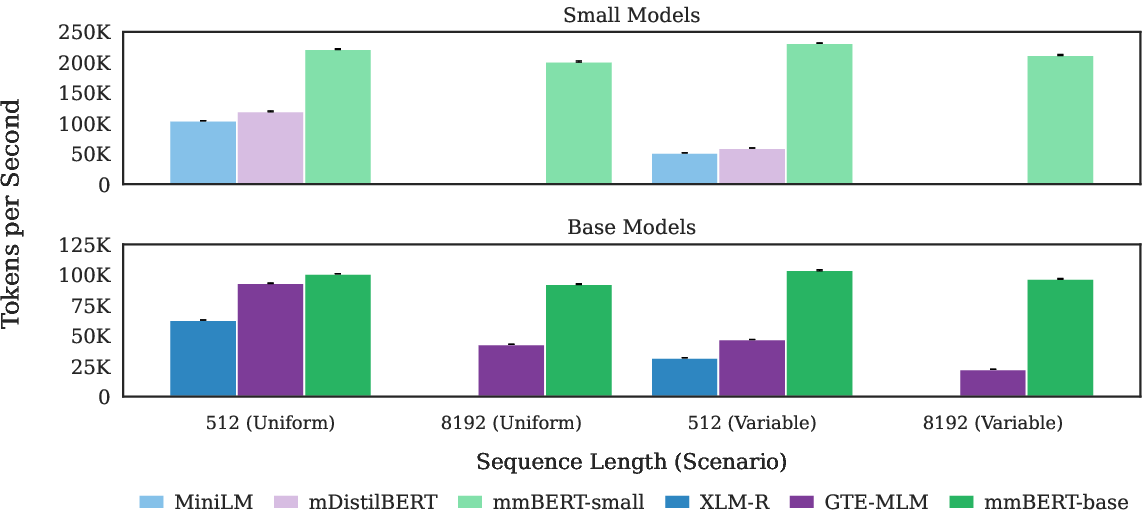
Figure 3: Throughput efficiency for various sequence lengths, with mmBERT demonstrating superior speed and scalability to 8192 tokens.
Comparative Analysis
mmBERT outperforms EuroBERT-210m on EuroBERT's in-distribution languages for both XNLI and PAWS-X. Compared to decoder models of similar size (e.g., Gemma 3 270M), mmBERT small achieves higher scores on XNLI (73.6 vs 69.0) and GLUE (84.7 vs 82.9), reinforcing the advantage of encoder-only architectures for NLU and retrieval.
Practical and Theoretical Implications
The staged, annealed approach to language inclusion and sampling provides a scalable recipe for massively multilingual pretraining, especially when high-quality data is unevenly distributed. The results suggest that late-phase introduction of low-resource languages, combined with aggressive mask rate reduction, can yield rapid and substantial gains with minimal data. The efficiency improvements make mmBERT suitable for real-world deployment in multilingual retrieval and classification pipelines, especially where inference speed and context length are critical.
Theoretically, the findings support the hypothesis that transfer from high-resource to low-resource languages is maximized when the latter are introduced after a strong multilingual base is established. The annealed temperature schedule further mitigates the risk of overfitting and catastrophic forgetting.
Future Directions
Potential avenues for further research include:
- Adopting improved tokenizers (e.g., Gemma 3 with prefix space) to address structured prediction deficits.
- Exploring more sophisticated model merging strategies for small models.
- Extending the ALL schedule to decoder-only and encoder-decoder architectures.
- Incorporating higher-quality or synthetic data for extremely low-resource languages.
- Investigating the impact of parallel data and cross-lingual transfer in the ALL framework.
Conclusion
mmBERT establishes a new standard for massively multilingual encoder-only models, combining architectural efficiency with a principled, staged training regimen. The cascading annealed language learning schedule and inverse mask rate schedule are empirically validated to yield strong gains, particularly for low-resource languages. mmBERT is positioned as a robust, open-source alternative to XLM-R and demonstrates that encoder-only models remain highly competitive for NLU and retrieval tasks across the multilingual spectrum.