DROID-SLAM in the Wild
Abstract: We present a robust, real-time RGB SLAM system that handles dynamic environments by leveraging differentiable Uncertainty-aware Bundle Adjustment. Traditional SLAM methods typically assume static scenes, leading to tracking failures in the presence of motion. Recent dynamic SLAM approaches attempt to address this challenge using predefined dynamic priors or uncertainty-aware mapping, but they remain limited when confronted with unknown dynamic objects or highly cluttered scenes where geometric mapping becomes unreliable. In contrast, our method estimates per-pixel uncertainty by exploiting multi-view visual feature inconsistency, enabling robust tracking and reconstruction even in real-world environments. The proposed system achieves state-of-the-art camera poses and scene geometry in cluttered dynamic scenarios while running in real time at around 10 FPS. Code and datasets are available at https://github.com/MoyangLi00/DROID-W.git.

















































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
DROID-SLAM in the Wild — Explained Simply
1) What is this paper about?
This paper is about teaching a computer to figure out where a camera is moving and what the surrounding 3D world looks like, using only regular video (RGB) from a single camera. This task is called SLAM: Simultaneous Localization and Mapping. The big challenge they tackle is making SLAM work well in real-world scenes full of moving things—like people, cars, pets, and trees blowing in the wind—without slowing down.
The authors build a new system called DROID-W (based on an earlier system called DROID-SLAM) that can:
- Track the camera’s path
- Reconstruct the 3D scene
- Estimate “uncertainty” (how much to trust each pixel) to ignore moving or unreliable parts of the image
And it does this in real time, about 10 frames per second.
2) What questions are they trying to answer?
In simple terms:
- How can we make SLAM work when parts of the scene are moving?
- Can we do this without relying on predefined rules like “humans move, cars move,” or needing a perfect 3D model first?
- Can we estimate, for every pixel, how trustworthy it is so we don’t get confused by moving objects?
- Can this run fast enough to be used in the real world?
3) How does their method work? (with simple analogies)
Think of a tourist walking with a camera:
- Localization: “Where am I?”
- Mapping: “What does the world around me look like?”
Real-world scenes are messy—people walk by, cars pass, leaves move. If the computer assumes everything is still, it gets confused and the map becomes wrong.
Here’s what DROID-W does:
- Uncertainty map (a per-pixel “trust score”):
- Imagine coloring pixels by how much you trust them: static background pixels get high trust, moving pixels get low trust.
- The system learns this trust by comparing how similar parts of the image look across different frames. If a patch matches well across frames, it’s probably static; if not, it might be moving or unreliable.
- Feature similarity instead of raw image error:
- The system uses strong visual features (from a model called DINOv2) that act like fingerprints for small image patches. These fingerprints are good at matching the same object even if lighting or viewpoint changes.
- If the fingerprint for a pixel in frame A doesn’t match its corresponding pixel in frame B (after accounting for camera motion), that pixel is likely dynamic and should be downweighted.
- Bundle Adjustment (BA), uncertainty-aware:
- BA is like adjusting all the camera positions and the 3D points so that everything lines up across frames.
- DROID-W makes BA “uncertainty-aware,” meaning pixels with low trust (e.g., moving people) affect the optimization less. This keeps the camera tracking stable.
- Alternating updates:
- It repeats two steps:
- 1) Refine camera path and 3D depths using the current uncertainty map.
- 2) Update the uncertainty map by looking at how consistent features are across views.
- This back-and-forth makes both the map and the uncertainty better over time.
- A little extra help: predicted depth
- The system also uses a separate depth predictor (like a smart guess of how far things are) to make BA more stable in very dynamic scenes.
In short: it’s like building a 3D map while wearing “smart glasses” that dim out the untrustworthy, moving parts, letting the system focus on the reliable background.
4) What did they find, and why does it matter?
Main results:
- More accurate camera paths and 3D reconstructions in dynamic, cluttered scenes than other top systems.
- Works in real time (~10 FPS), which is fast enough to be practical.
- Robust across many kinds of videos, including “in the wild” YouTube clips with lots of motion and visual clutter.
- The uncertainty maps it estimates are clean and meaningful, highlighting moving regions and keeping static regions stable.
Why this matters:
- Most classic SLAM assumes the world is still, which is rarely true outside controlled labs.
- Other recent methods often rely on detecting known moving objects (like “cars” and “people”). That breaks when the moving thing is unknown or weird.
- Some methods need a perfect 3D model first; if that model is bad, everything falls apart. DROID-W avoids that by computing uncertainty directly from feature consistency between frames.
They also introduce a new dataset (DROID-W) with challenging outdoor scenes and ground-truth trajectories, and show their method performs best on it.
5) What could this change in the future?
This research helps make SLAM trustworthy in everyday situations, not just neat, static rooms. That’s useful for:
- Robots and drones navigating busy streets or crowded indoor spaces
- Augmented reality (AR) apps that must place virtual objects correctly even when people and cars move around
- Autonomous systems that need stable tracking without special sensors
Big picture: DROID-W shows that giving each pixel a learned “trust score,” based on how consistent it looks across views, makes SLAM far more reliable in the real world. It’s a step toward more robust, general-purpose vision systems that can handle the messiness of life outside the lab.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper advances SLAM in dynamic, cluttered environments via uncertainty-aware bundle adjustment (BA) and feature-similarity–driven uncertainty, but it leaves several important aspects unresolved. Future work could address the following concrete gaps:
- Sensitivity to initialization and bootstrap coupling:
- Uncertainty is computed from multi-view feature similarity using correspondences derived from current pose and depth; errors early on can corrupt both correspondences and uncertainty, risking poor convergence. How robust is the interleaved optimization to bad initial poses/depths, and can more resilient initialization or multi-hypothesis strategies reduce this coupling?
- Limited capacity of the uncertainty model:
- The uncertainty predictor is a local affine mapping over DINO/FiT3D features with Softplus; this may be too weak to capture complex, context-dependent dynamics or long-range correlations. What are the trade-offs of richer models (e.g., shallow CNNs, transformers, spatial-temporal smoothing) with explicit regularization to preserve real-time performance?
- Freezing uncertainty during global BA:
- The system freezes uncertainty parameters during global BA to keep the mapping local, but global trajectory updates change correspondences. Would re-optimizing uncertainties at a coarser global scale improve overall consistency, and under what schedules is this stable and efficient?
- Occlusion handling in uncertainty optimization:
- The cosine-similarity loss does not explicitly model occlusions; static points that become occluded can be misinterpreted as dynamic. How can occlusion-aware correspondence filtering, visibility reasoning, or robust pair selection be integrated without harming speed?
- Failure in scenes dominated by motion:
- The method degrades when dynamic content occupies most of the field of view (e.g., DyCheck “haru”); downweighting dynamics leaves few static constraints. Can object-level motion modeling, scene-flow priors, or inertial constraints maintain tracking when the static background is sparse or absent?
- No reconstruction or tracking of moving objects:
- The pipeline suppresses dynamic regions rather than modeling them. How can it be extended to jointly reconstruct dynamic objects (4D) and estimate their trajectories, without sacrificing robustness or speed?
- Dependence on external monocular depth priors (Metric3D):
- Monodepth regularization improves stability but may bias optimization if the prior is inaccurate (e.g., nighttime, unusual optics). How sensitive is the system to monodepth errors and scale biases, and can self-calibration of scale or uncertainty-aware depth priors mitigate this?
- Robustness of feature-similarity–based uncertainty:
- DINO/FiT3D features are robust but not invariant to all nuisances (strong illumination change, specularities, motion blur, repetitive patterns, extreme viewpoint change). What failure modes arise, and can multi-cue consistency (e.g., optical flow, depth, photometric residuals) be fused to disambiguate dynamics from appearance changes?
- Rolling-shutter and exposure effects:
- The method assumes pinhole, global-shutter geometry; strong rolling-shutter distortions and exposure flicker can degrade correspondences and similarity. Can rolling-shutter camera models or exposure-invariant features improve performance in hand-held videos and mobile devices?
- Long-sequence scalability and memory:
- YouTube videos longer than 5 minutes must be chunked due to resource limits. What architectural or systems-level changes (feature caching/compression, out-of-core BA, hierarchical maps, keyframe culling policies) enable true streaming operation over hour-long sequences?
- Real-time performance on constrained hardware:
- The system achieves ~10 FPS on an RTX 3090, with a noted slowdown from DINO feature extraction and monodepth. How can feature extractors be made lighter (e.g., distilled DINO, quantization, pruning), and what is the achievable performance on embedded GPUs or CPUs?
- Resolution and fine-detail limitations:
- Depth and uncertainty are estimated at 1/8 resolution; fine structures and thin objects may be misweighted or lost. What are the benefits and costs of multi-resolution uncertainty and depth, or adaptive upsampling guided by edges?
- Lack of quantitative evaluation of geometry and uncertainty:
- Results focus on ATE; there is no quantitative assessment of reconstructed geometry (depth/mesh accuracy) or calibration of uncertainty (e.g., error-vs-uncertainty curves, AUROC for dynamic regions). Can standardized metrics corroborate the claimed spatial/semantic consistency of uncertainty?
- Sensitivity to intrinsics estimation:
- For YouTube content, intrinsics are estimated from a few frames using MonST3R; the impact of intrinsics errors on uncertainty, pose, and depth remains unquantified. Can online self-calibration be integrated to reduce sensitivity to imperfect intrinsics?
- Frame-graph construction and pair selection:
- Performance depends on which frame pairs are linked in the BA and uncertainty modules. How do connectivity, overlap thresholds, and temporal spacing affect robustness in dynamic scenes, and can adaptive graph policies improve stability?
- Convergence and stability of interleaved optimization:
- The paper does not analyze convergence properties or provide schedules beyond alternating steps and simple GD with weight decay. What learning rates, step counts, and alternation policies guarantee stable convergence across diverse dynamics?
- Dataset limitations and ground truth quality:
- DROID-W has only 7 sequences; two use FAST-LIVO2 as ground truth (not absolute RTK), and YouTube sequences lack ground truth. More diverse benchmarks (night, rain, low-light, high-speed) and tighter GT would enable stronger claims about generalization.
- No use of available IMU/LiDAR in method:
- Although DROID-W includes synchronized IMU and LiDAR, the proposed system is RGB-only. What gains arise from integrating inertial/point cloud priors for disambiguating dynamics and stabilizing BA when visual cues are weak?
- Handling of transient imaging artifacts:
- Strong motion blur, sensor noise, and compression artifacts (common in web videos) can corrupt features and BA residuals. Can learned deblurring or robust filtering pre-processing improve downstream uncertainty and tracking?
- Interpretability and calibration of uncertainty:
- The per-pixel uncertainty acts as a weight but is not tied to a calibrated probabilistic model of residuals. Can a Bayesian formulation or post-hoc calibration make uncertainty quantitatively meaningful for downstream decision-making?
- Hyperparameter sensitivity:
- Key choices (e.g., prior weight γ_prior, weight decay η, learning rate λ, window size, number of keyframes) are not systematically studied. Automated tuning or adaptive schedules could improve robustness across sequences and domains.
- Robustness to repetitive textures and parallax-induced similarity changes:
- Cosine similarity in high-level features may remain high for different but semantically similar regions, and parallax can change appearance across views. Can geometric consistency checks or local descriptor matching be combined to reduce false positives/negatives in dynamic detection?
- Generalization beyond standard camera models:
- The method assumes perspective cameras; fisheye/wide-angle lenses and non-standard intrinsics (common in action cams and drones) are not explored. How to adapt the pipeline to broader camera models without sacrificing performance?
Practical Applications
Below is a concise synthesis of practical, real-world applications enabled by the paper’s findings, methods, and innovations. Each item includes sector alignment, potential tools/products/workflows, and feasibility notes.
Immediate Applications
These can be deployed now with the released codebase and existing hardware (GPU-equipped PCs, embedded GPUs) and existing models (DINOv2/FiT3D, Metric3D).
- Robust monocular SLAM for mobile robots in crowded, dynamic spaces (Robotics, Industry)
- What: Real-time (≈10 FPS) RGB-only localization and mapping that downweights moving people/objects via per-pixel dynamic uncertainty, improving stability over prior SLAM in cluttered environments.
- Tools/products/workflows: ROS2 node or SLAM SDK integration for delivery robots, indoor patrol robots, service robots in malls/airports, warehouse AMRs operating near humans; plug-in replacement for brittle visual odometry.
- Assumptions/dependencies: Requires GPU-class compute for real-time throughput; known/estimated camera intrinsics; absolute scale depends on monocular depth prior (Metric3D); extreme motion blur or very low light may degrade performance.
- AR/VR on-device tracking in dynamic scenes (Software, Consumer Electronics)
- What: More stable inside-out tracking for AR overlays during concerts, museums, classrooms, or street-level use where people move through view.
- Tools/products/workflows: Integration as a tracking backend for mobile AR apps and headsets; improved camera trajectories for AR cloud anchors in crowded settings.
- Assumptions/dependencies: Mobile performance hinges on efficient deployment of DINOv2/FiT3D and Metric3D; rolling shutter and phone thermal limits may reduce frame rate.
- Video stabilization and VFX camera solve in “in-the-wild” footage (Media, Film/Games)
- What: Recover accurate camera trajectories and sparse scene structure from casual handheld video with moving distractors, improving matchmove and stabilization robustness.
- Tools/products/workflows: NLE/VFX plug-ins (e.g., After Effects, Blender) for camera solving that auto-weights dynamic regions; pipelines for sports and action footage shot in crowds.
- Assumptions/dependencies: Needs intrinsics (or pre-solve via existing tools); pro-grade accuracy may require higher resolution and careful calibration.
- Low-cost site capture and photogrammetry in active environments (Construction, AEC)
- What: Camera-only mapping in sites with ongoing activity (workers, machinery) by suppressing dynamic pixels; aids quick documentation and progress tracking.
- Tools/products/workflows: Smartphone/GoPro capture workflow + PC processing; export trajectories/point clouds for BIM alignment and site reports.
- Assumptions/dependencies: Monocular scale regularization from Metric3D may need site-specific calibration for metric fidelity; safety protocols for on-site capture apply.
- Crowd-aware navigation for service robots in hospitals and campuses (Healthcare, Education)
- What: Reliable localization in hallways, cafeterias, and lecture halls by mitigating dynamic residuals (people, carts), enabling smoother navigation and delivery.
- Tools/products/workflows: Drop-in SLAM module for hospital delivery robots; campus service bots; facility inspection trolleys.
- Assumptions/dependencies: Requires embedded GPU (e.g., Jetson class) for real-time; privacy considerations for camera-based operation in sensitive areas.
- Forensic camera path recovery from consumer videos (Public Safety, Insurance)
- What: Retrieve camera trajectories and approximate scene structure from dashcams, body cams, or bystander videos with moving agents for event analysis.
- Tools/products/workflows: Analyst workbench to import video, solve trajectories while downweighting moving people/vehicles; export to incident reconstruction tools.
- Assumptions/dependencies: Intrinsics estimation must be reliable; legal/privacy constraints on video use; lighting and motion blur can affect accuracy.
- Dynamic-uncertainty maps for motion-aware perception stacks (Software, Robotics)
- What: Use per-pixel uncertainty as a general-purpose “dynamic mask” to gate downstream modules (e.g., dense mapping, pose-graph optimization, object trackers).
- Tools/products/workflows: Middleware that feeds uncertainty maps to occupancy mapping, semantic SLAM, or 3D Gaussian/NeRF recon modules for better robustness.
- Assumptions/dependencies: Quality depends on DINOv2/FiT3D feature extraction; integration requires consistent frame timing with other sensors if fused.
- Benchmarking and research with the DROID-W dataset (Academia, R&D)
- What: A challenging outdoor dynamic dataset with ground truth to evaluate SLAM under real-world crowd and clutter.
- Tools/products/workflows: New evaluation protocols for dynamic-SLAM; training/evaluation of uncertainty-aware modules and motion segmentation.
- Assumptions/dependencies: Community adoption and consistent baselines; dataset licensing/use terms.
Long-Term Applications
These require further research, scaling, optimization, or multi-sensor integration beyond the current system’s constraints (compute, monocular depth priors, throughput).
- Embedded, power-efficient deployment on edge devices (IoT, Consumer Electronics)
- What: Port DROID-W pipeline (DINOv2/FiT3D features, Metric3D depth, BA) to mobile SoCs for AR glasses/phones and small robots.
- Tools/products/workflows: Quantized models (e.g., MobileViT/Lightweight DINO variants), hardware acceleration via NPUs/DSPs; partial offloading to edge servers.
- Assumptions/dependencies: Significant model compression and runtime engineering; maintaining robustness under aggressive optimization.
- Vision-only fallback and redundancy in automotive perception (Automotive, Safety)
- What: Provide a robust visual odometry fallback when LiDAR/GNSS is degraded (urban canyons, tunnels), taming dynamics via uncertainty.
- Tools/products/workflows: Integration into ADAS/AV stacks alongside GNSS/IMU; watchdog that switches to uncertainty-aware VO during sensor failures.
- Assumptions/dependencies: Automotive-grade reliability, stringent safety certification; higher FPS and rolling-shutter handling; night/rain robustness.
- 4D mapping with dynamic object modeling (Smart Cities, Robotics, Media)
- What: Extend uncertainty-aware SLAM to jointly segment and track moving objects (people/vehicles) and produce temporally consistent 4D maps.
- Tools/products/workflows: Coupling with object trackers or dynamic NeRF/3DGS that use uncertainty as a supervisory signal; city-scale dynamic map services.
- Assumptions/dependencies: Real-time dynamic instance modeling; memory and compute scaling; privacy-preserving pipelines for public spaces.
- Multi-camera, stereo, and multi-modal fusion (Robotics, Drones, AR)
- What: Increase robustness and accuracy by fusing stereo/IMU/LiDAR with the uncertainty-aware BA, using uncertainty to weight cross-modal residuals.
- Tools/products/workflows: Visual-inertial SLAM with dynamic weighting; drone navigation in crowds; AR headsets with depth sensors for accurate scale.
- Assumptions/dependencies: Synchronization and calibration; fusion complexity; maintaining real-time performance with added modalities.
- Real-time broadcasting overlays in crowded sports/events (Media, Live Entertainment)
- What: Stable camera pose estimation for handheld/steadicam/phone streams in dynamic stadium scenes to enable live AR graphics and analytics.
- Tools/products/workflows: Broadcast toolkits that ingest multiple feeds, solve trajectories, and render overlays in real time with crowd-robust weighting.
- Assumptions/dependencies: Low-latency constraints (<50 ms) beyond current ~10 FPS on high-end GPUs; professional calibration; multi-stream coordination.
- Safety certification frameworks for robots in public spaces (Policy, Standards)
- What: Use robust dynamic-scene benchmarks (e.g., DROID-W) and uncertainty-aware metrics to define minimum localization performance for certification.
- Tools/products/workflows: Compliance tests requiring stability under defined dynamic conditions; procurement specs for public-sector robot deployments.
- Assumptions/dependencies: Standard-setting bodies’ adoption; reproducible evaluation protocols; consideration of privacy and data retention.
- Consumer 3D capture “in crowds” for social content (Consumer Apps, Creator Tools)
- What: One-tap 3D scene capture from phones in tourist hotspots or events, with automatic suppression of passersby to maintain consistent geometry.
- Tools/products/workflows: Creator apps that produce 3D walkthroughs or meshes by combining DROID-W trajectories with downstream reconstruction methods.
- Assumptions/dependencies: Mobile-friendly models; user guidance for capturing; robust scale estimation without external calibration.
- Facility digital twins with live updates despite human activity (Enterprise IT, AEC)
- What: Continuous camera-only updates to digital twins in offices/retail/warehouses while operations continue, by ignoring dynamic agents.
- Tools/products/workflows: Pipelines that integrate with facility management systems; anomaly detection overlayed on updated maps.
- Assumptions/dependencies: Continual operation and drift control over long durations; data governance in workplaces; integration with existing twin platforms.
- Privacy-preserving vision SLAM via non-semantic uncertainty (Policy, Security)
- What: Dynamic handling without storing or transmitting identities, since uncertainty relies on feature inconsistency rather than explicit person detection.
- Tools/products/workflows: On-device processing that avoids face/body detection; legal/compliance narratives emphasizing minimal semantic inference.
- Assumptions/dependencies: Legal interpretations vary; must still address raw video capture and retention; evaluate susceptibility to re-identification through features.
Notes on feasibility across applications:
- Compute: Current real-time performance (≈10 FPS) is demonstrated on a high-end GPU (RTX 3090). Embedded/mobile deployment will require model slimming and acceleration.
- Scale/metric accuracy: Monocular scale is regularized by Metric3D; for safety-critical or metrology tasks, additional sensors (IMU, stereo, depth) or calibration may be needed.
- Intrinsics: Accurate camera intrinsics are required; when unknown, pre-solvers or factory calibration must be integrated.
- Edge cases: Sequences with minimal static background or extreme motion blur/lighting can still degrade performance; uncertainty estimates help but do not eliminate all failures.
- Licensing/data: Adoption of the DROID-W dataset and pretrained models must respect licenses; organizational policies may limit in-situ video collection.
Glossary
Below is an alphabetical list of advanced domain-specific terms from the paper, each with a brief definition and a verbatim usage example.
- 3D Gaussian Splatting (3DGS): A real-time scene representation that models a scene as a set of 3D anisotropic Gaussians for fast, photorealistic rendering and optimization. "More recently, the emergence of 3D Gaussian Splatting (3DGS)~\cite{kerbl3Dgaussians} inspired numerous SLAM approaches~\cite{keetha2024splatam, sandstrom2024splat, matsuki2024monogs, yan2024gs-slam, hu2024cg, ha2024gs-icp} that adopt Gaussian primitives."
- Absolute Trajectory Error (ATE): A metric that measures the difference between estimated and ground-truth camera trajectories, often after alignment. "We use the Absolute Trajectory Error (ATE) to evaluate camera tracking accuracy."
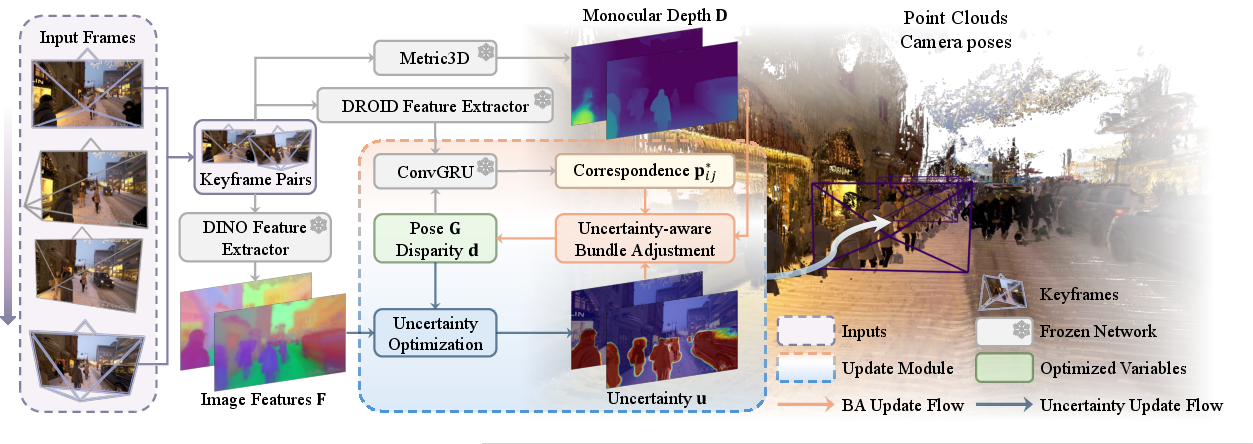
- Bundle Adjustment (BA): A nonlinear optimization that jointly refines camera poses and 3D structure by minimizing reprojection (or correspondence) residuals over multiple views. "DROID-SLAM leverages a differentiable bundle adjustment (BA) layer to update camera poses and depths in an iterative manner."
- Co-visibility (frame-graph): The graph of frames with edges indicating image pairs that observe overlapping parts of the scene, used to constrain multi-view optimization. "it constructs the frame-graph to represent co-visibility across frames, where an edge means that the images and overlap."
- Cosine similarity: A feature similarity measure based on the cosine of the angle between two vectors, used here to gauge multi-view consistency. "Multi-view consistency of the image pair is measured by cosine similarity between the DINOv2 features ."
- DINOv2: A self-supervised vision foundation model that provides robust, semantically rich image features. "They utilize a shallow MLP to estimate per-pixel motion uncertainty from DINOv2~\cite{oquab2023dinov2} features"
- FiT3D: A refined DINOv2-based model for extracting 2D visual features tailored to 3D perception tasks. "2D visual features $(\bF_i, \bF_j)$ are first extracted using FiT3D~\cite{yue2025FiT3D}, a refined DINOv2 model."
- Gauss-Newton algorithm: An iterative second-order optimization method for least-squares problems, commonly used in BA. "The pose and disparity are optimized using the Gauss-Newton algorithm as follows:"
- Gaussian primitives: The basic 3D Gaussian elements used in 3DGS-based scene representations. "More recently, the emergence of 3D Gaussian Splatting (3DGS)~\cite{kerbl3Dgaussians} inspired numerous SLAM approaches~\cite{keetha2024splatam, sandstrom2024splat, matsuki2024monogs, yan2024gs-slam, hu2024cg, ha2024gs-icp} that adopt Gaussian primitives."
- Inverse depth (disparity): A depth parameterization using 1/z (where z is depth), often improving numerical stability in optimization; disparity is closely related in stereo/monocular settings. "The set of camera poses and inverse depths are iteratively updated through the differentiable BA layer"
- Keyframe: A selected frame that anchors optimization and mapping, reducing computation while preserving accuracy. "Following DROID-SLAM, we accumulate 12 keyframes with sufficient motion to initialize the SLAM system."
- Mahalanobis distance: A distance metric that weights residuals by their covariance (or confidence), used to downweight noisy measurements. "where denotes Mahalanobis distance that weights the residuals according to the confidence map predicted by DROID-SLAM."
- Metric monodepth: Monocular depth estimates calibrated to metric scale, enabling direct use in geometric optimization. "Thus, we adopt the metric monodepth $\bD_t \in \mathcal{R}^{\frac{H}{8} \times \frac{W}{8}$ predicted by Metric3D \cite{hu2024metric3d} to penalize the disparity and improve accuracy."
- Neural implicit (representation): A continuous scene representation using neural networks (e.g., MLPs) that map coordinates to properties like color and density. "However, these approaches rely on constructing a perfectly static neural implicit~\cite{Mildenhall2020ECCV} or Gaussian Splatting~\cite{kerbl3Dgaussians} map to optimize uncertainty."
- Neural Radiance Fields (NeRF): A neural implicit representation that models view-dependent appearance and density for photorealistic rendering from images. "Recent advances in Neural Radiance Fields (NeRF)~\cite{Mildenhall2020ECCV} have garnered substantial attention for their integration into SLAM systems"
- Optical flow: The pixel-wise motion field between frames; residuals in flow can indicate dynamic regions. "FlowFusion~\cite{zhang2020flowfusion} instead leverages optical flow residuals to highlight dynamic regions."
- Photometric loss: An image reconstruction loss measuring pixel-level differences (e.g., intensity/color) between observed and rendered images. "They utilize a shallow MLP to estimate per-pixel motion uncertainty from DINOv2~\cite{oquab2023dinov2} features, as these features are robust to appearance variations and can represent abundant semantic information. The uncertainty MLP is optimized under the supervision of photometric and depth losses between input and rendered images."
- Pose graph: A graph where nodes are camera poses and edges encode relative constraints, used for global trajectory optimization. "To evaluate full trajectories, we recover non-keyframe poses through SE(3) interpolation followed by a pose graph update."
- RTK (Real-Time Kinematic): A high-precision GNSS technique providing accurate ground-truth trajectories. "whereas the remaining sequences rely on RTK ground truth."
- Rigid-motion correspondence: The pixel-to-pixel mapping between frames induced by a single rigid motion hypothesis (camera pose and depth). "For each pair of images , we can derive the rigid-motion correspondence as:"
- SE(3): The Lie group of 3D rigid body transformations (rotation and translation). "we recover non-keyframe poses through SE(3) interpolation followed by a pose graph update."
- Sim(3) Umeyama alignment: A similarity transform (scale, rotation, translation) estimated via Umeyama’s method to align two point/pose sets. "For all methods, we align the estimated camera trajectory with the ground-truth camera trajectory through Sim(3) Umeyama alignment \cite{umeyama1991least}."
- Softplus activation: A smooth, non-negative activation function Softplus(x)=ln(1+ex), used here to ensure positive uncertainties. "To address this, we learn a local affine mapping followed by the Softplus activation function from DINOv2 features to uncertainties."
- Truncated Signed Distance Function (TSDF): A volumetric representation storing signed distances to the nearest surface, truncated beyond a band around surfaces. "ReFusion~\cite{palazzolo2019iros} adopts a TSDF~\cite{curless1996tsdf} representation and removes uncertain regions with large depth residuals to maintain a consistent background map."
- Uncertainty-aware Bundle Adjustment (UBA): A BA formulation that explicitly models per-pixel uncertainty to downweight dynamic or unreliable observations. "Our approach adapts prior deep visual SLAM DROID-SLAM \cite{teed2021droid} by introducing a differentiable Uncertainty-aware Bundle Adjustment (UBA) that explicitly models per-pixel uncertainty to handle dynamic objects."
- Warping masks: Masks indicating pixels whose correspondences are consistent under warping; used to filter dynamic/unstable regions. "RoDyn-SLAM~\cite{jiang2024rodyn} and DG-SLAM~\cite{xu2024dgslam} combine semantic segmentation with warping masks to improve motion mask estimation."
- Weight decay: An optimization regularization technique that penalizes large parameter values to improve generalization/stability. "To avoid the inverse computation of the large Hessian matrix, we optimize uncertainty using Gradient Descent with weight decay instead of the Newton algorithm."
Collections
Sign up for free to add this paper to one or more collections.

