Data-efficient pre-training by scaling synthetic megadocs
Abstract: Synthetic data augmentation has emerged as a promising solution when pre-training is constrained by data rather than compute. We study how to design synthetic data algorithms that achieve better loss scaling: not only lowering loss at finite compute but especially as compute approaches infinity. We first show that pre-training on web data mixed with synthetically generated rephrases improves i.i.d. validation loss on the web data, despite the synthetic data coming from an entirely different distribution. With optimal mixing and epoching, loss and benchmark accuracy improve without overfitting as the number of synthetic generations grows, plateauing near $1.48\times$ data efficiency at 32 rephrases per document. We find even better loss scaling under a new perspective: synthetic generations from the same document can form a single substantially longer megadocument instead of many short documents. We show two ways to construct megadocs: stitching synthetic rephrases from the same web document or stretching a document by inserting rationales. Both methods improve i.i.d. loss, downstream benchmarks, and especially long-context loss relative to simple rephrasing, increasing data efficiency from $1.48\times$ to $1.80\times$ at $32$ generations per document. Importantly, the improvement of megadocs over simple rephrasing widens as more synthetic data is generated. Our results show how to design synthetic data algorithms that benefit more from increasing compute when data-constrained.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching small LLMs to get smarter using less “real” internet text. The authors show that you can make extra, helpful practice data by having a stronger model rewrite and expand the original documents in clever ways. This synthetic practice not only helps the model do better on the same kind of text it was trained on, but also helps it handle longer documents and do better on simple question-answer tests.
Questions and Goals
The paper asks a few simple questions:
- Can computer‑made practice text (synthetic data) help a model learn the original kind of text better, not just different tasks?
- If we generate many versions of each document, does more synthetic data keep helping?
- Is there a smarter way to organize or create these generations so each original document becomes one long, helpful “megadocument”?
- Do these tricks still help when we combine several models into an ensemble (a group that votes)?
How They Did It (Methods)
Think of training a LLM like training a student to read and write. You have:
- Real homework: actual web text.
- Synthetic homework: extra practice the teacher (a bigger model) creates from the real homework.
Here’s the setup in everyday terms:
The student and the teacher
- The student is a small LLM (300 million parameters).
- The teacher is a stronger model (Llama 3.1 8B Instruct) that can write rewrites and explanations.
- The student has a “page limit” it can read at once (a context window of 4096 tokens; think: how much text fits on its desk at a time).
Measuring progress
- The main score is validation loss: how “surprised” the model is by text it should be familiar with. Lower is better.
- i.i.d. loss means we test on text from the same kind of source as training, without mixing in synthetic data.
- Data efficiency means: how much less real data you would need to reach the same skill. For example, 1.5× data efficiency means you’d need about one‑third less real text to get the same result.
- They also check simple benchmarks (PIQA, SciQ, ARC Easy) to see if lower loss actually means better answers.
Simple rephrasing (first step)
- For each real document, the teacher writes several rephrases (like new Wikipedia‑style versions).
- The student trains on a mix of real documents and these rephrases.
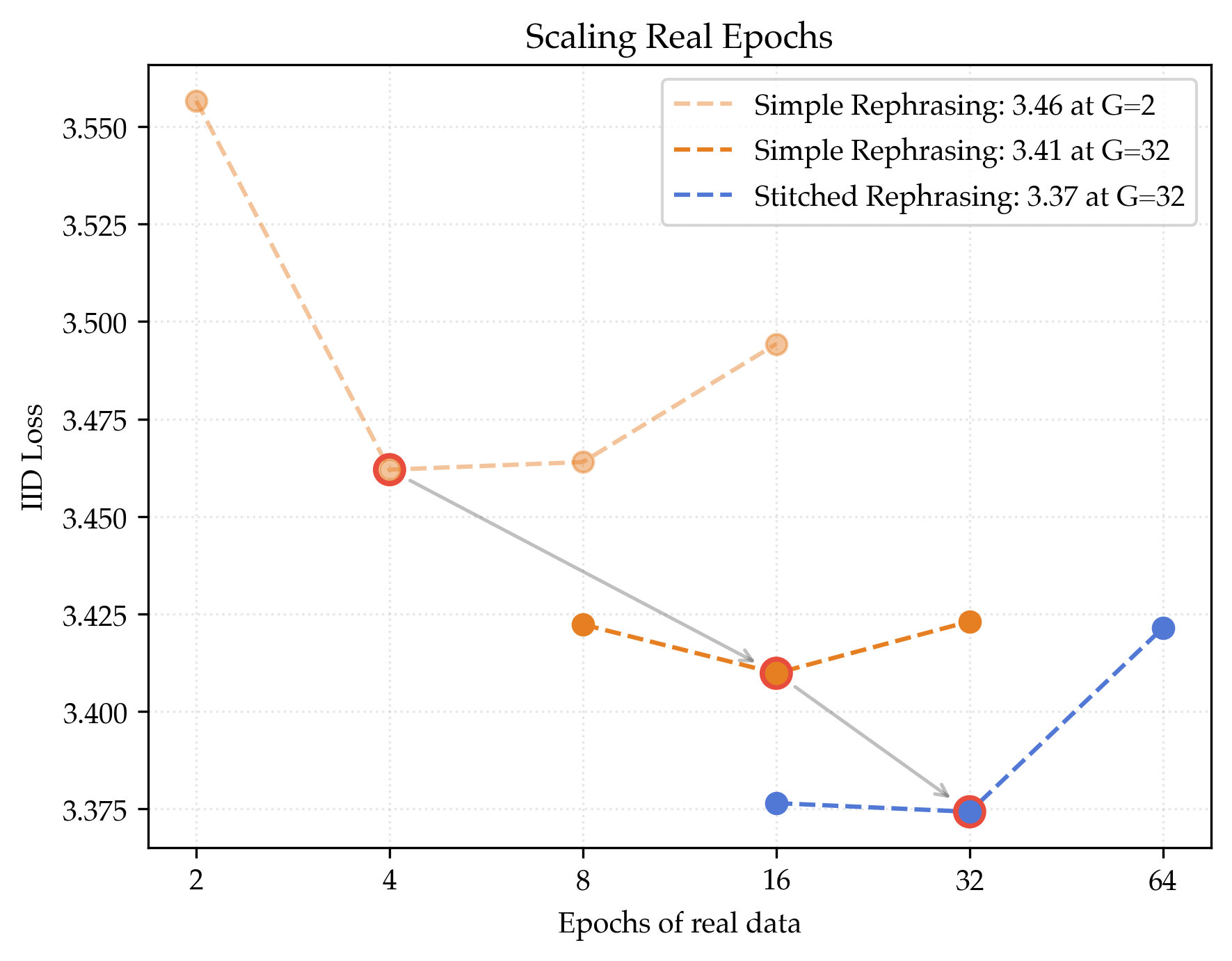
- They carefully tune how much of each to use and how many times to go over the real data (epochs), to avoid overfitting.
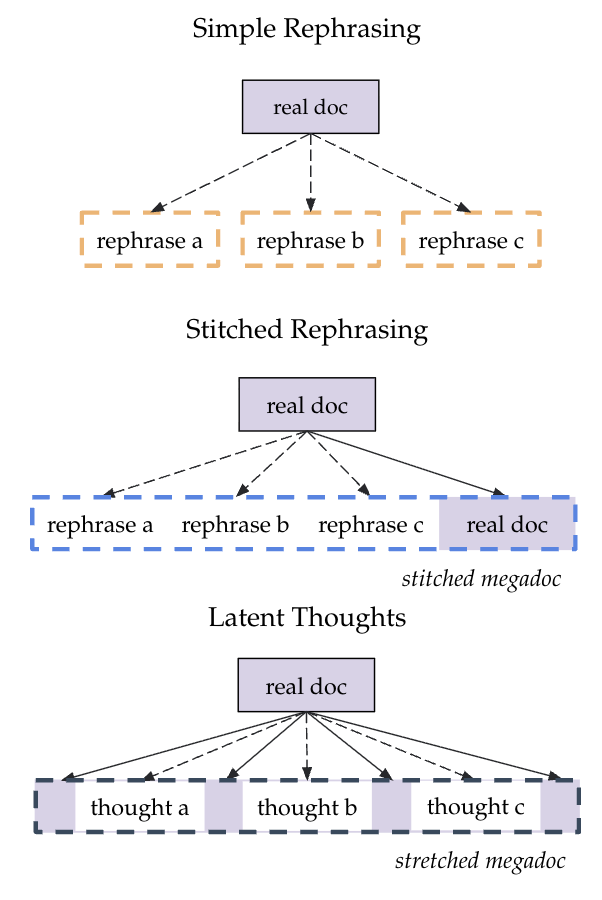
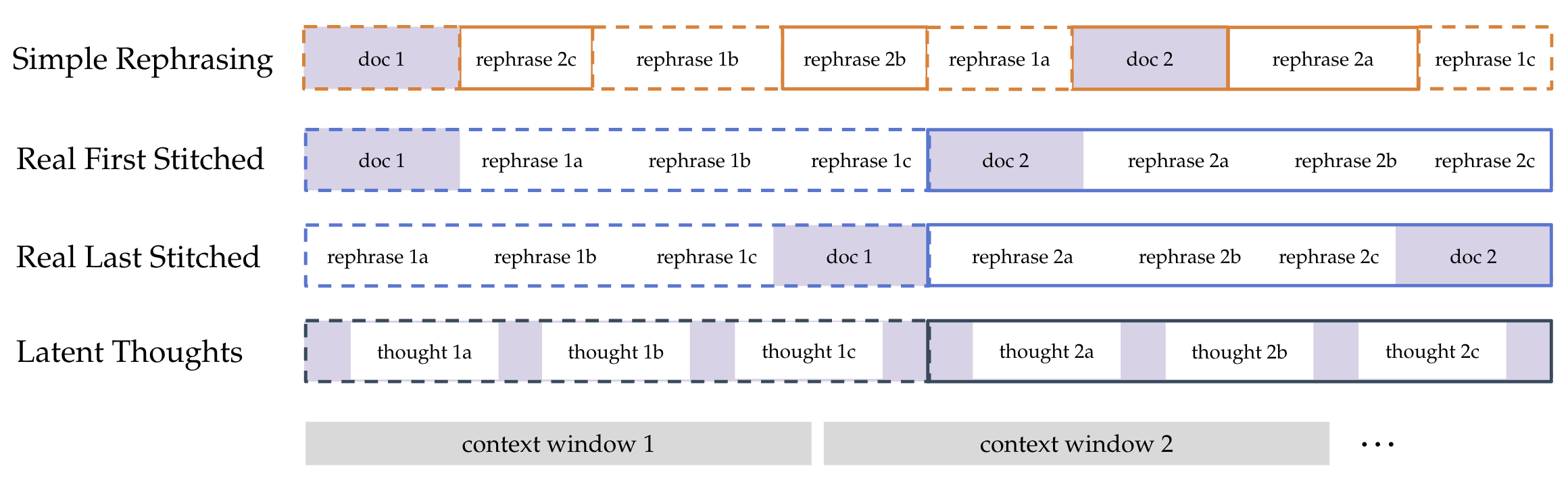
The “megadoc” idea (going beyond shuffling)
Instead of treating each rephrase as a separate tiny document in random order, the authors turn multiple generations related to the same original document into a single longer “megadocument.” Two ways:
- Stitched rephrasing:
- Take all the rephrases of one real document and glue them together, plus the real document itself.
- You can put the real document at the end or at the start. Putting it last works best here.
- Latent thoughts:
- Split the real document into parts.
- Ask the teacher to write short “rationales” explaining how one part leads to the next.
- Insert these explanations between parts, stretching the document with helpful “thoughts” that connect the dots.
Even if these megadocs are longer than the model can read at once, they still help during training because the model sees many helpful connections across chunks over time.
A note on ensembles
- An ensemble is like a team of models that vote. This often boosts accuracy.
- The authors check whether their synthetic data methods still help when models are ensembled.
What They Found (Results)
Here are the most important outcomes, explained simply:
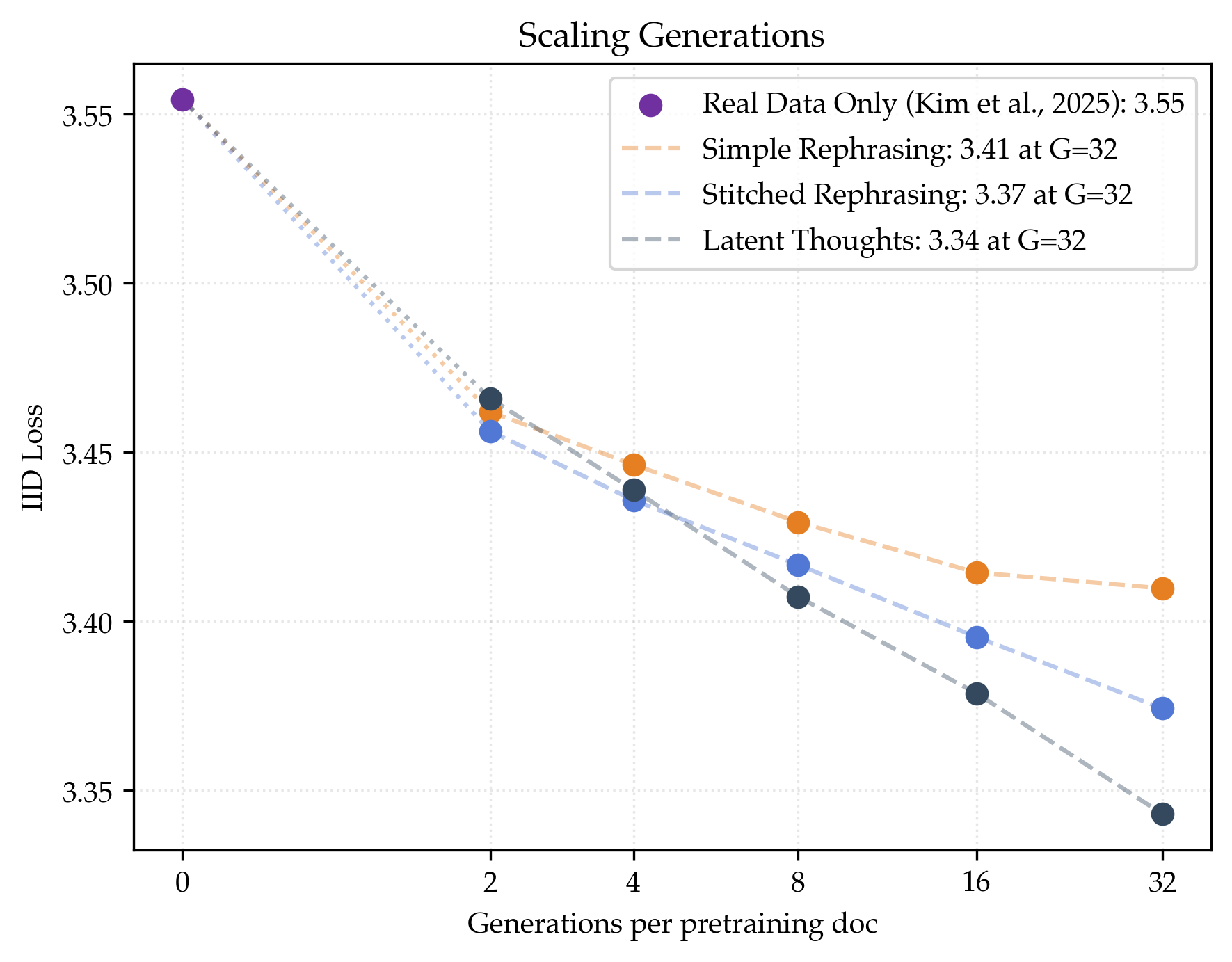
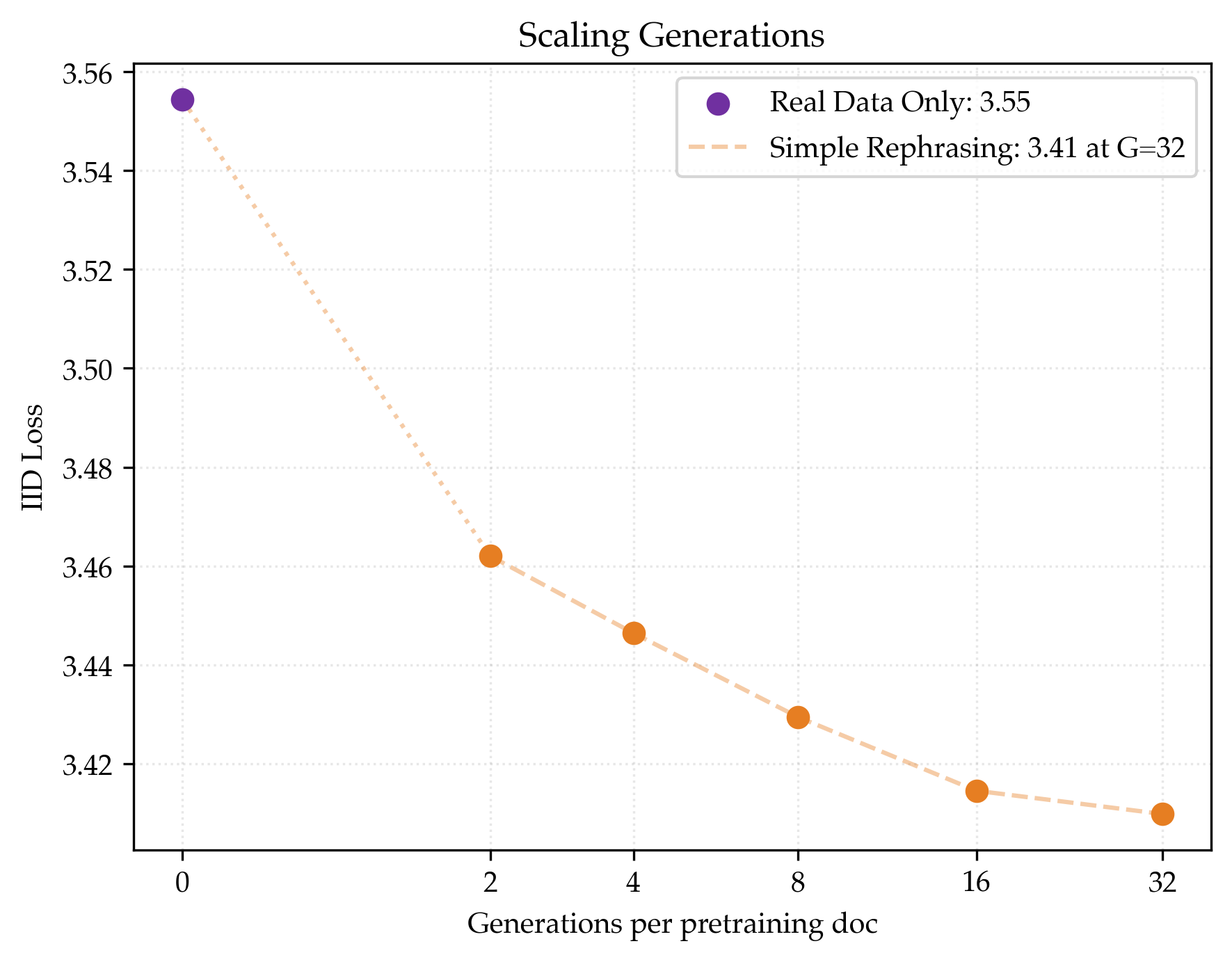
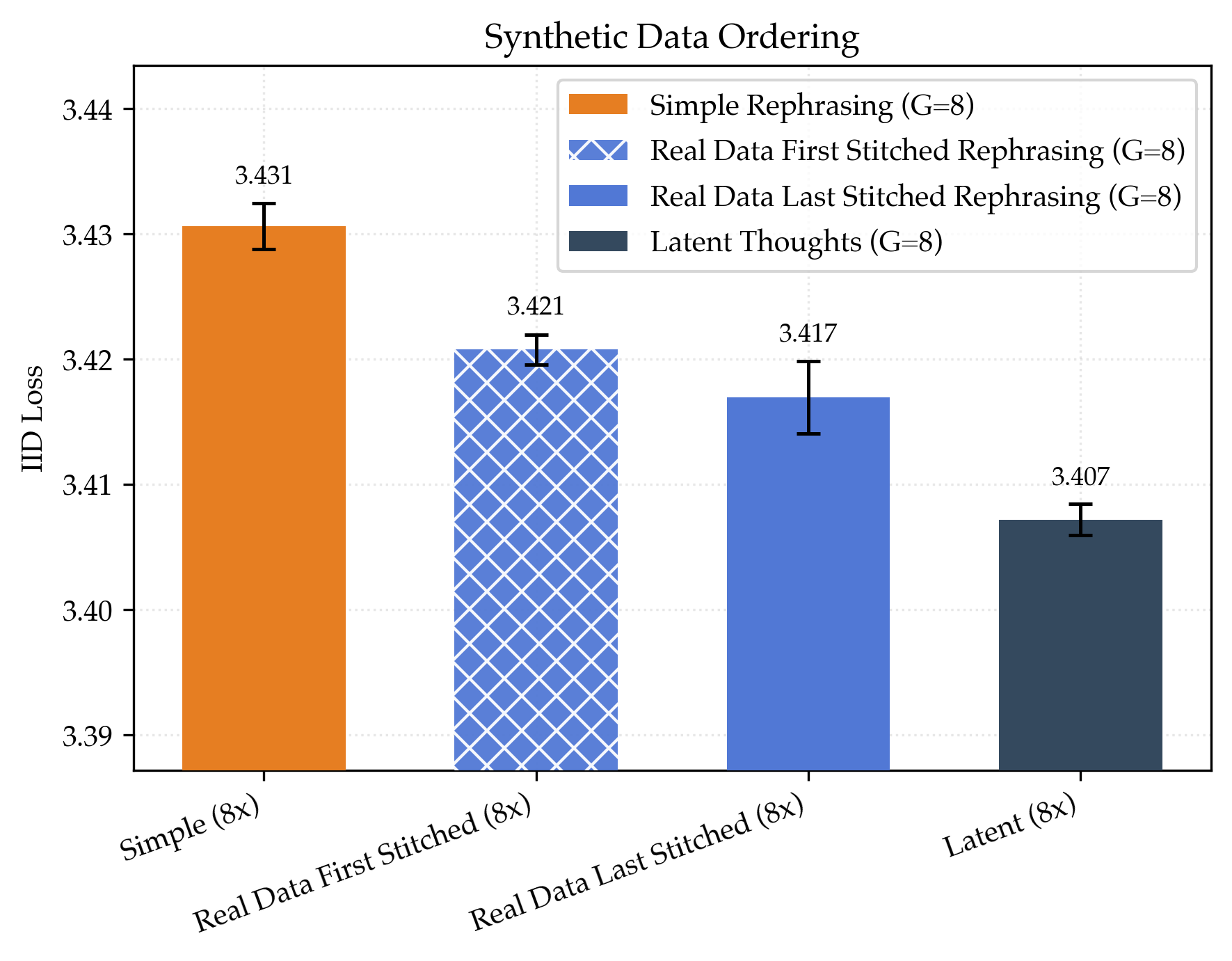
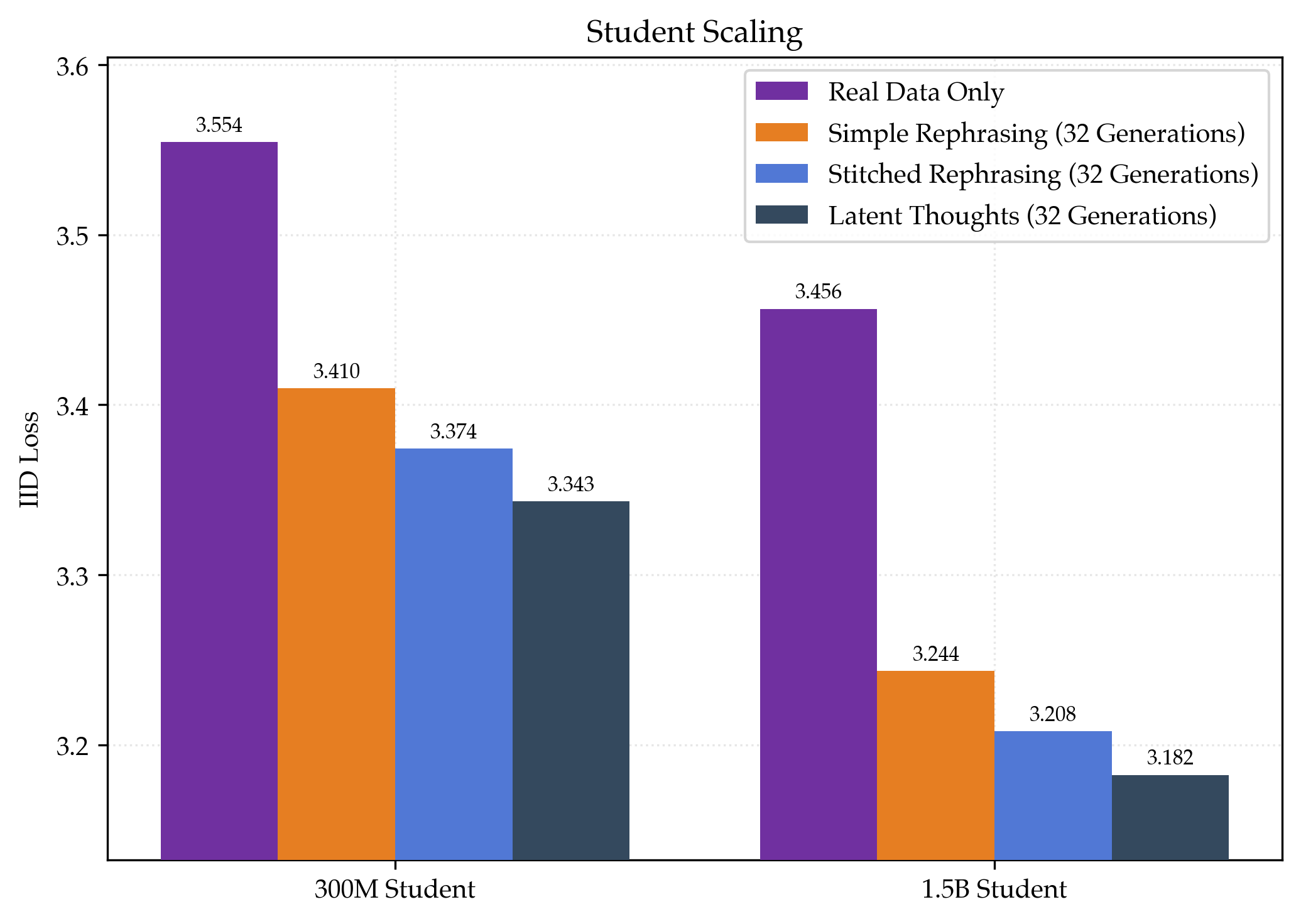
- Simple rephrasing helps a lot:
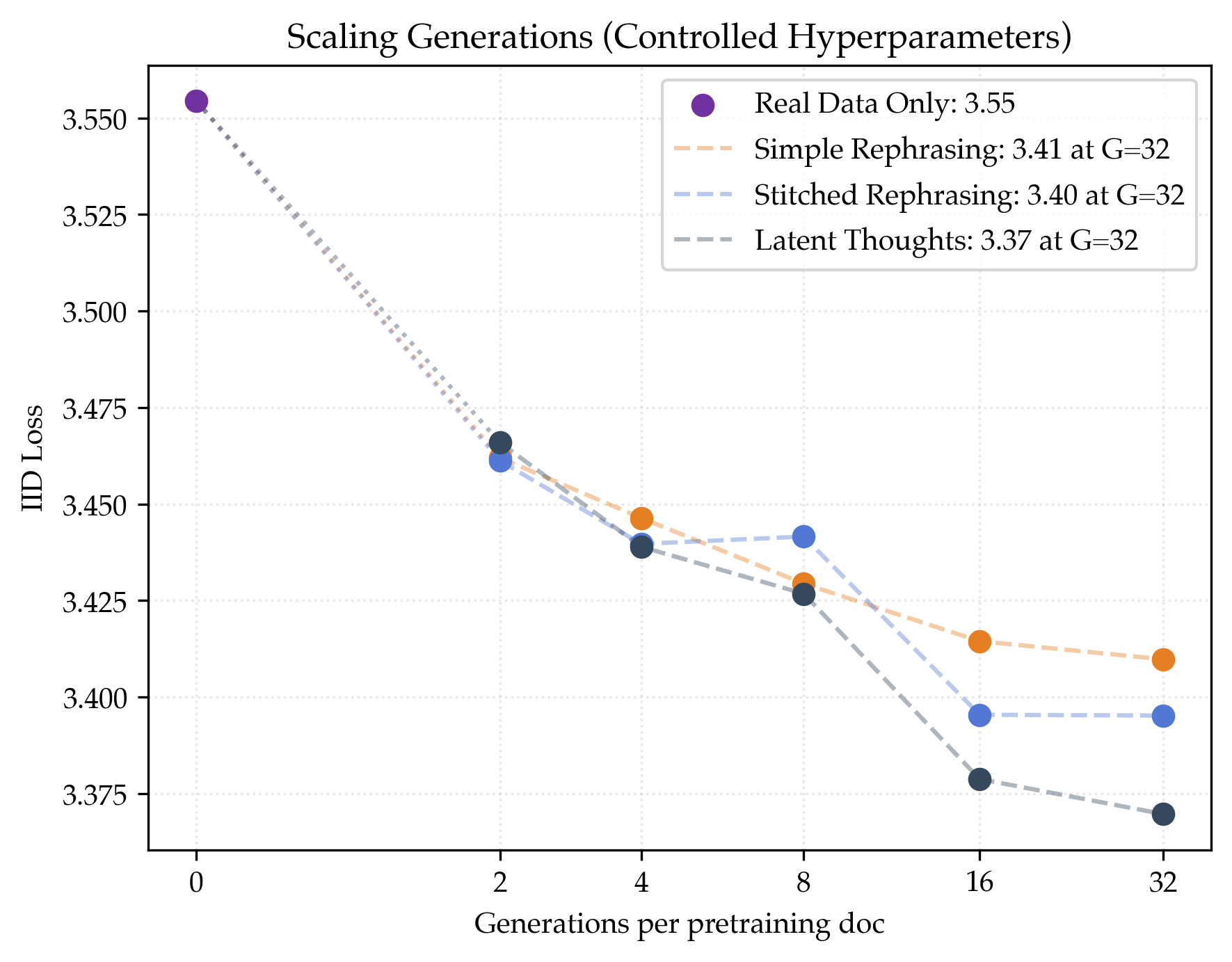
- Baseline (real data only): loss ≈ 3.55.
- With 32 rephrases per document: loss ≈ 3.41.
- That’s about 1.48× data efficiency, meaning you’d need roughly one‑third less real text to reach the same skill.
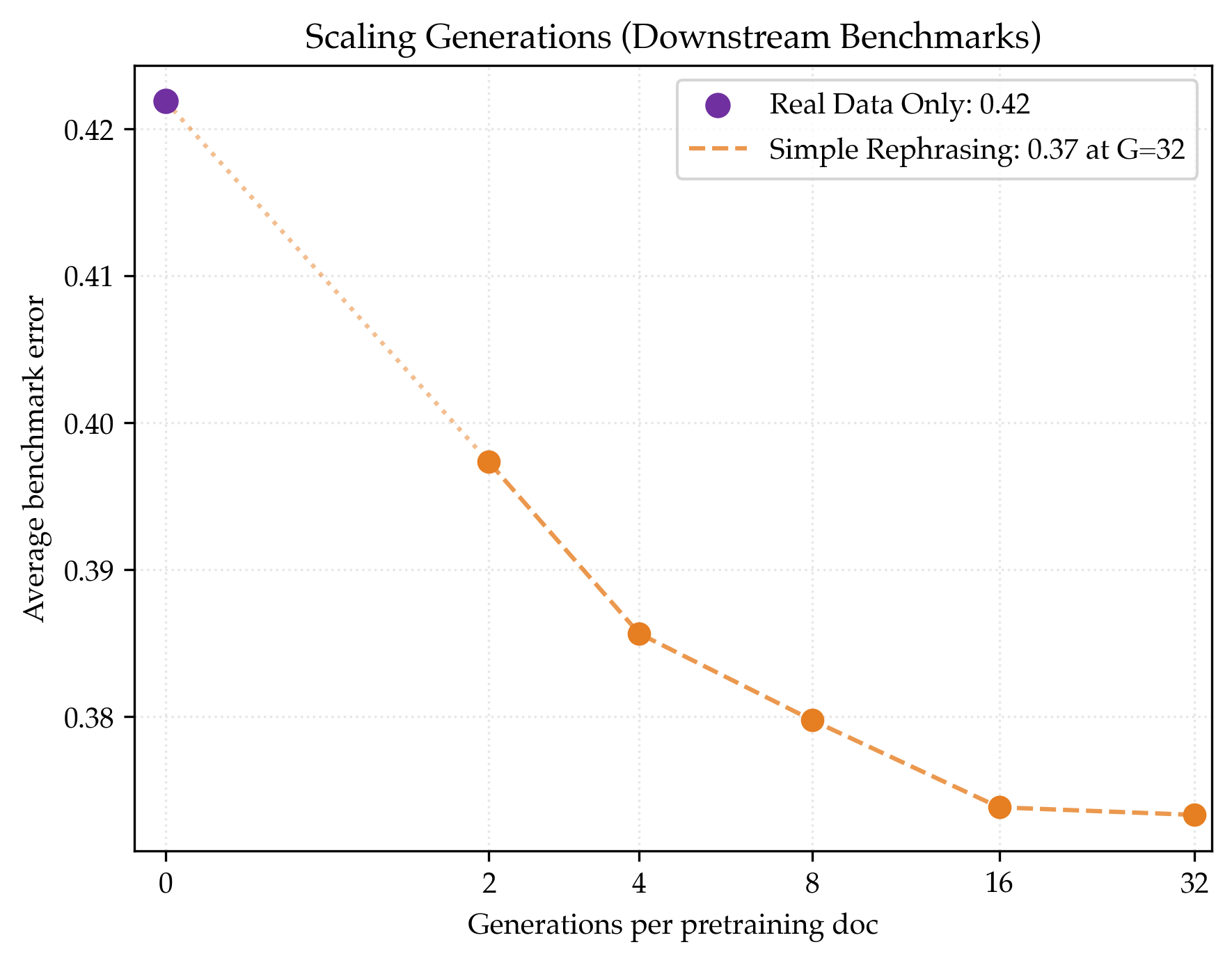
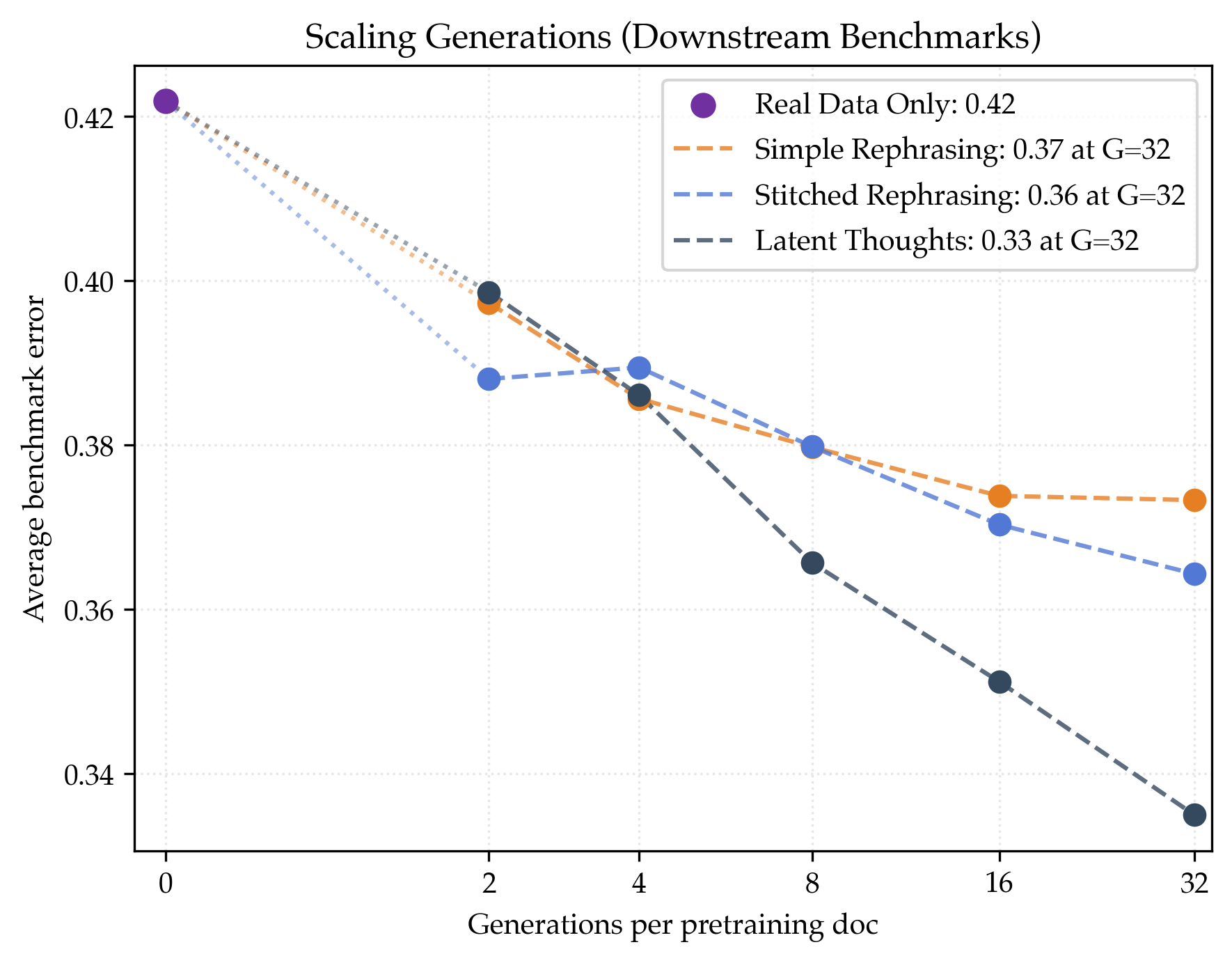
- Benchmarks improve by about 5% on average.
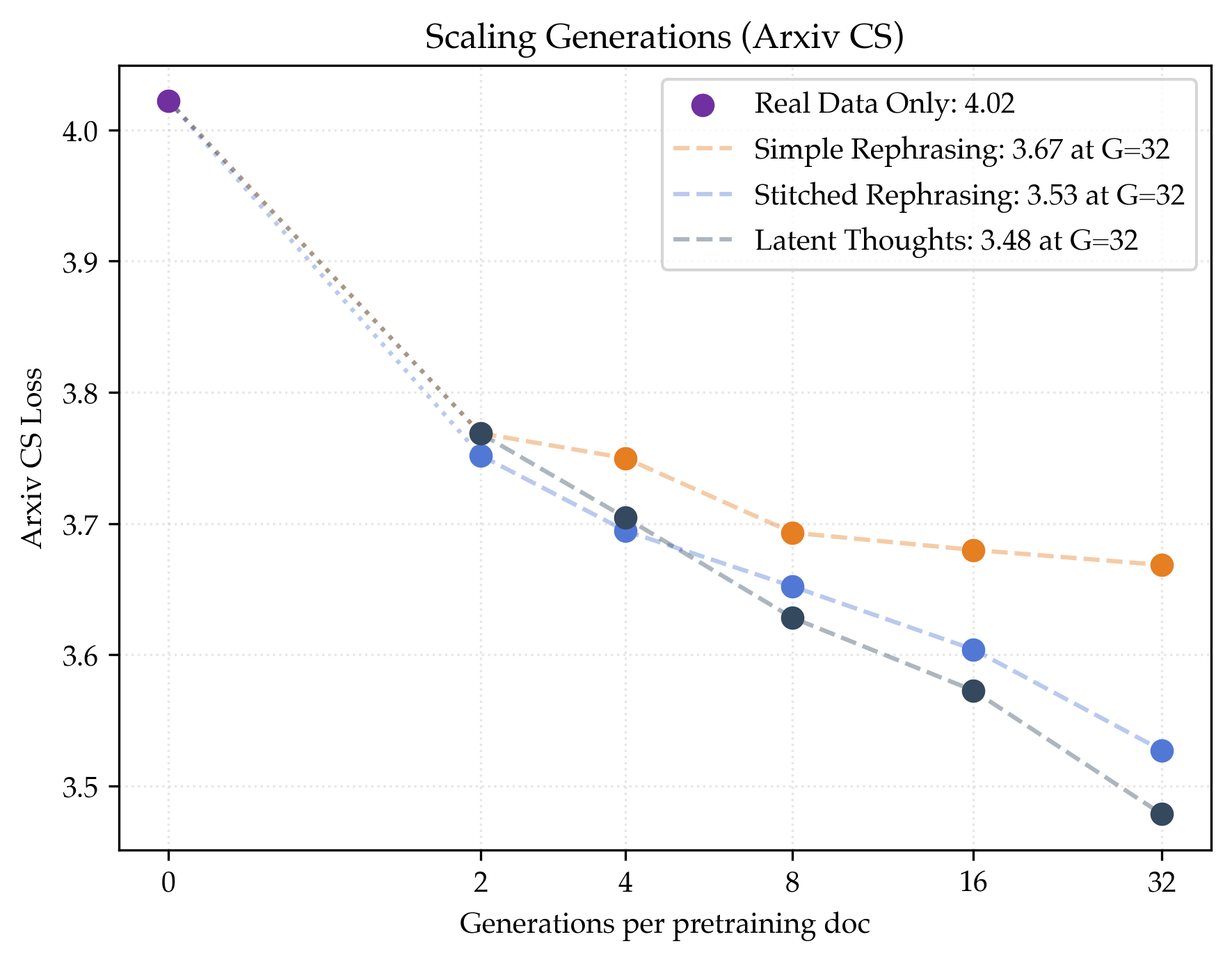
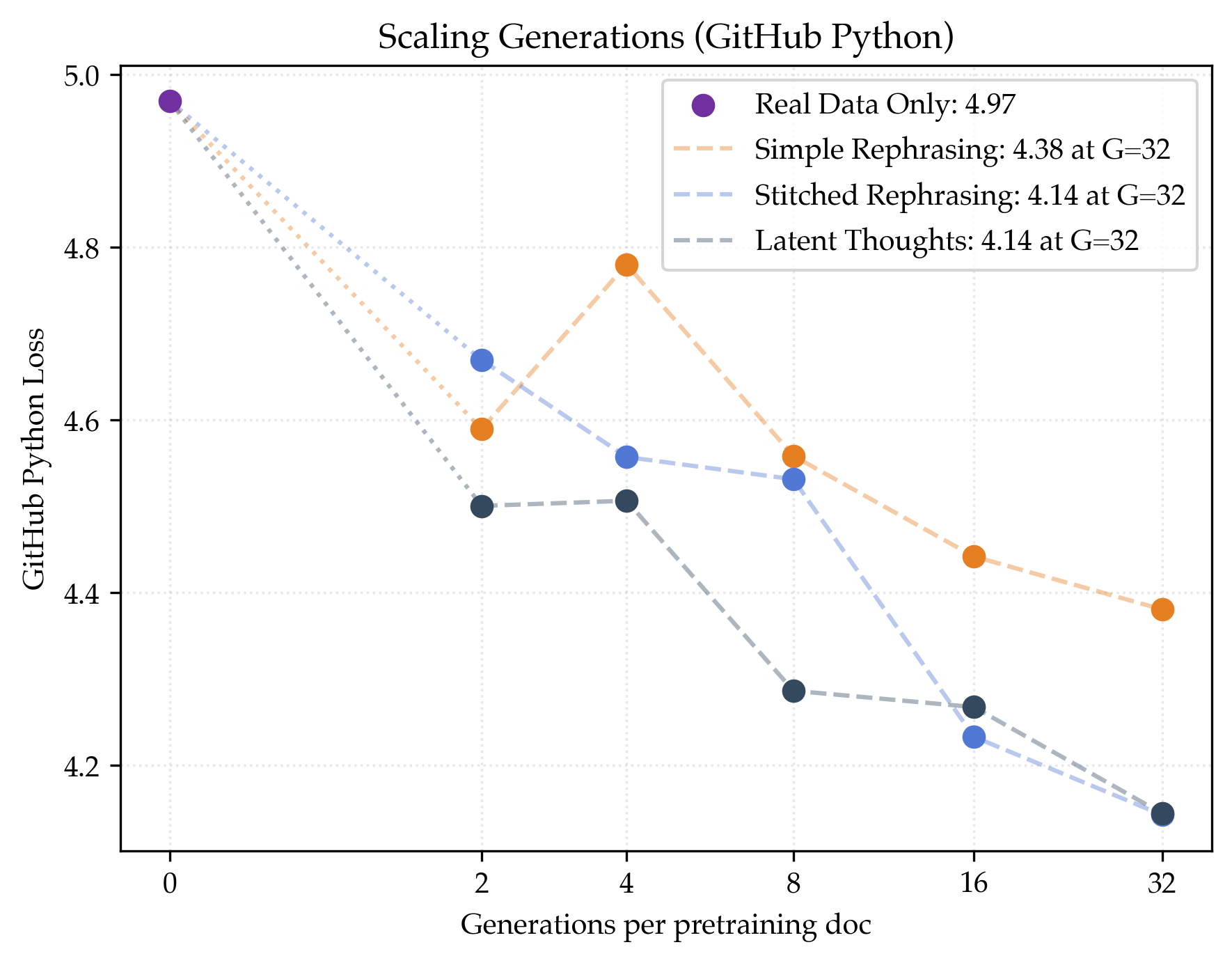
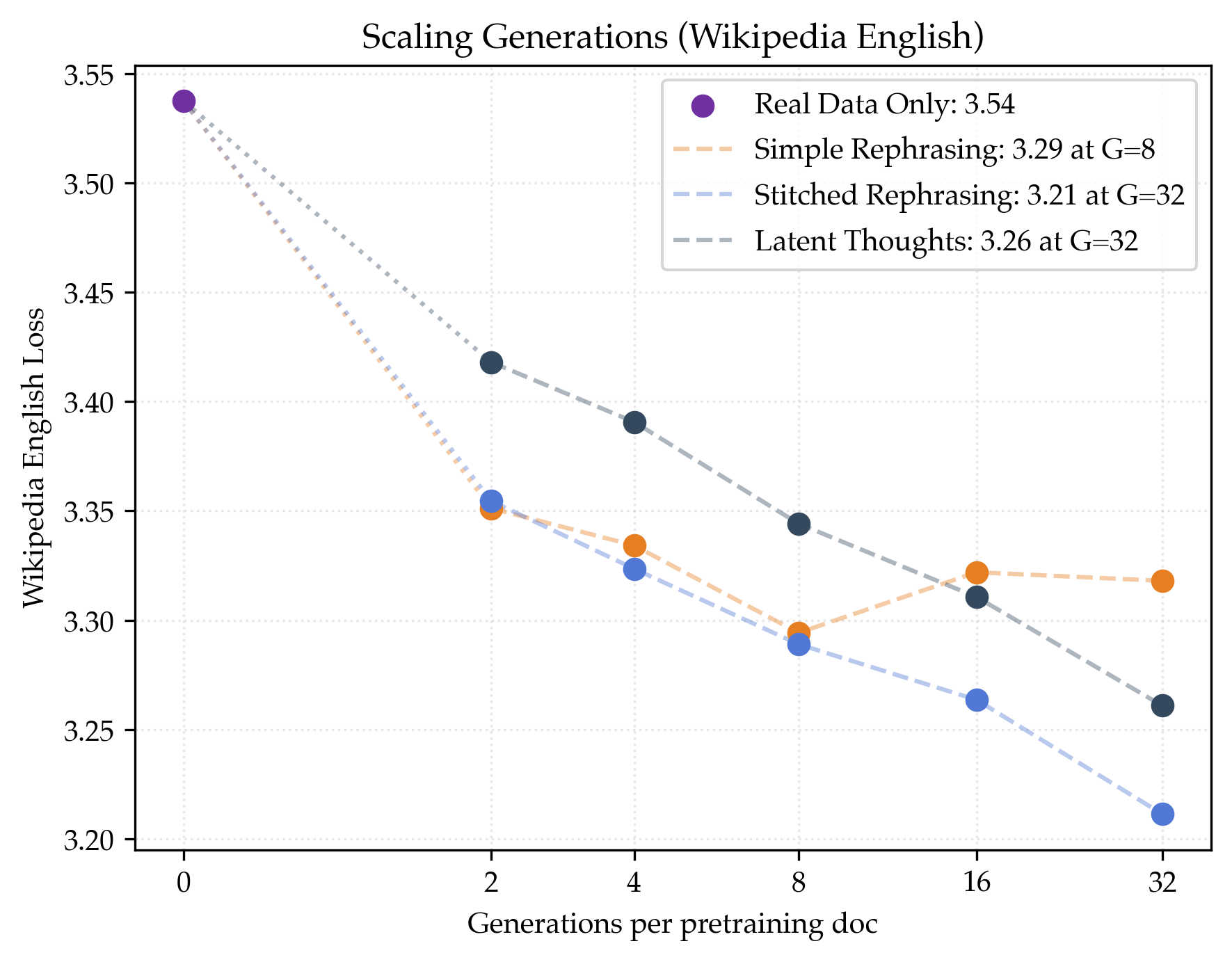
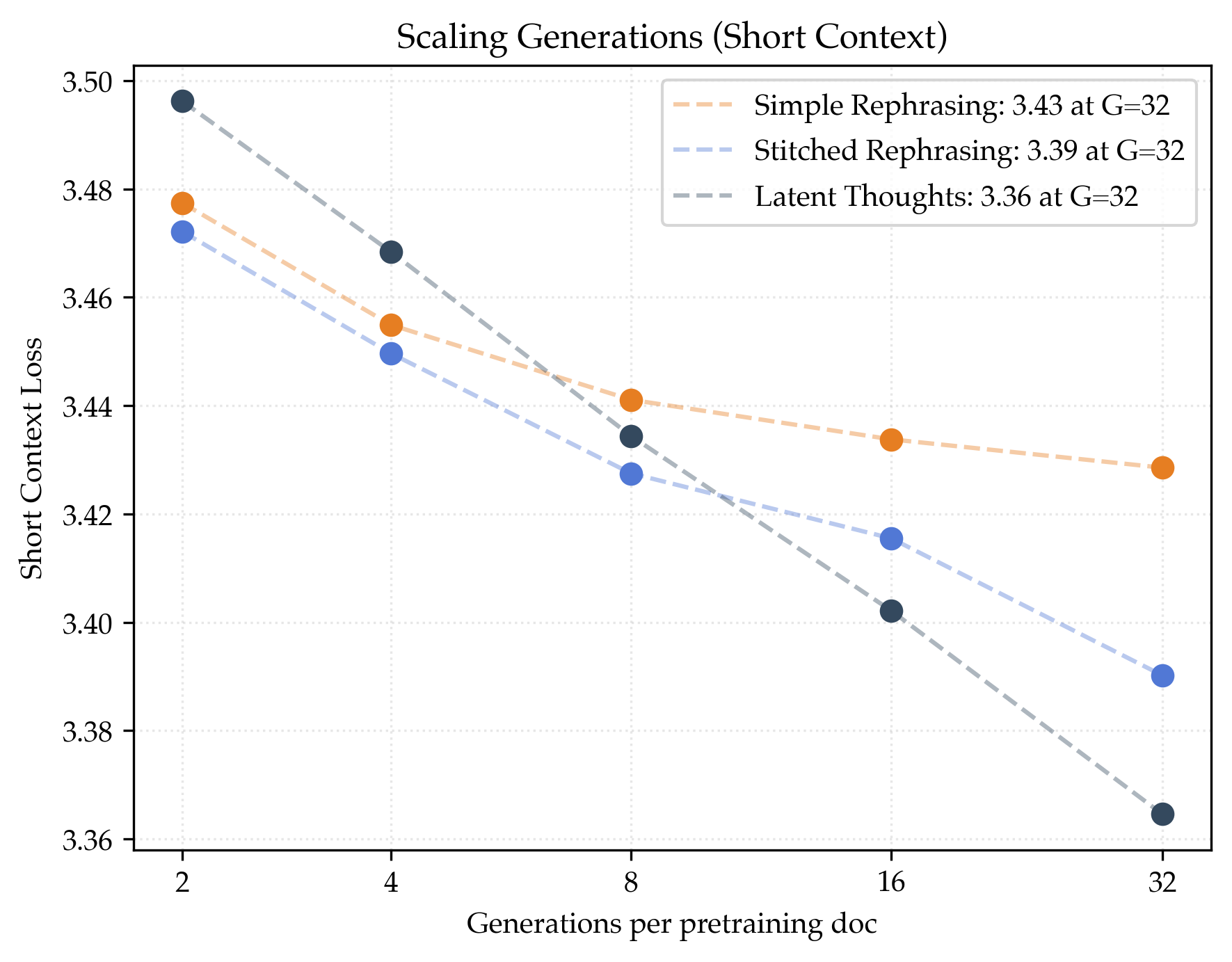
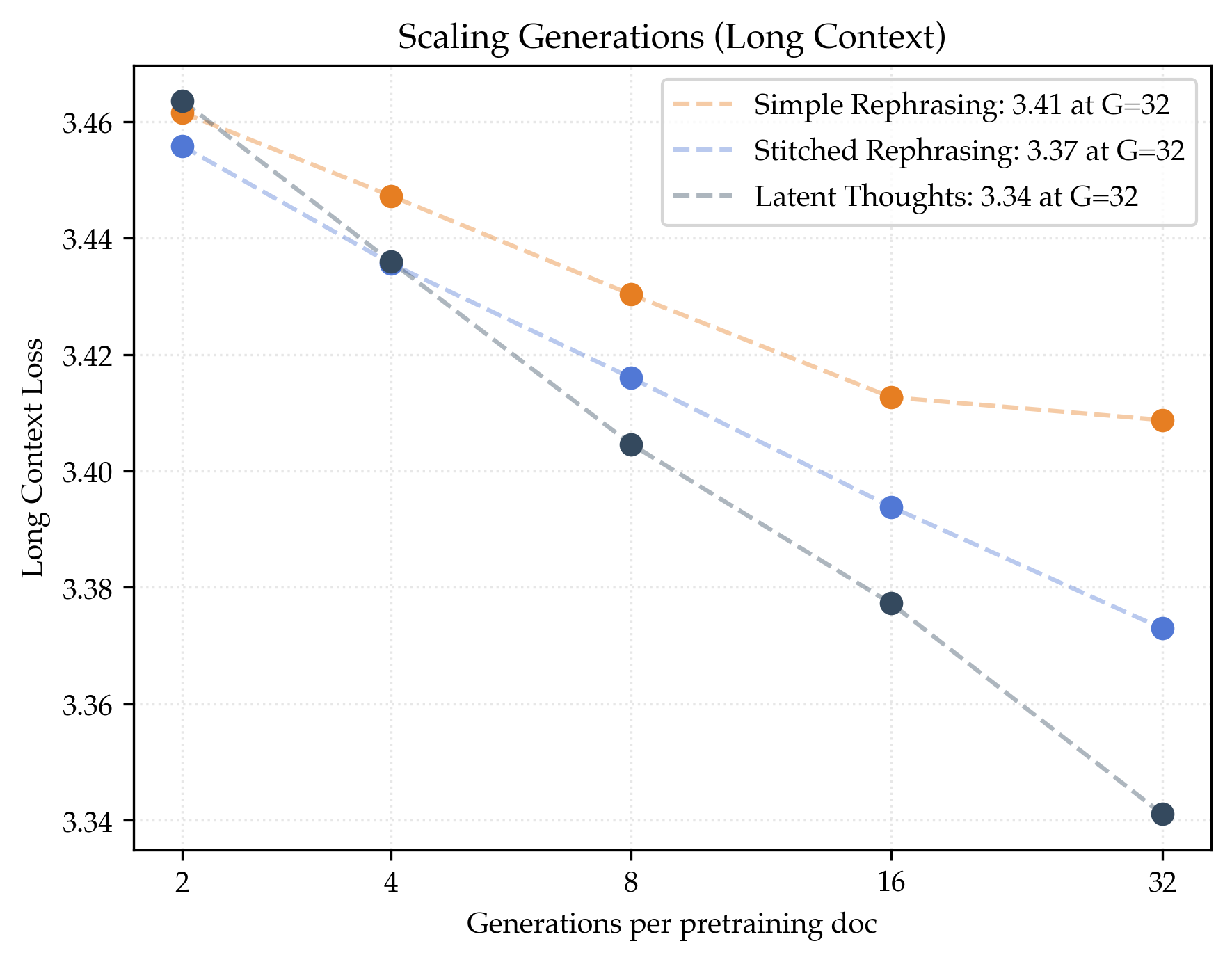
- Megadocs help even more and keep scaling better:
- Stitched rephrasing: about 1.64× data efficiency.
- Latent thoughts: about 1.80× data efficiency (best).
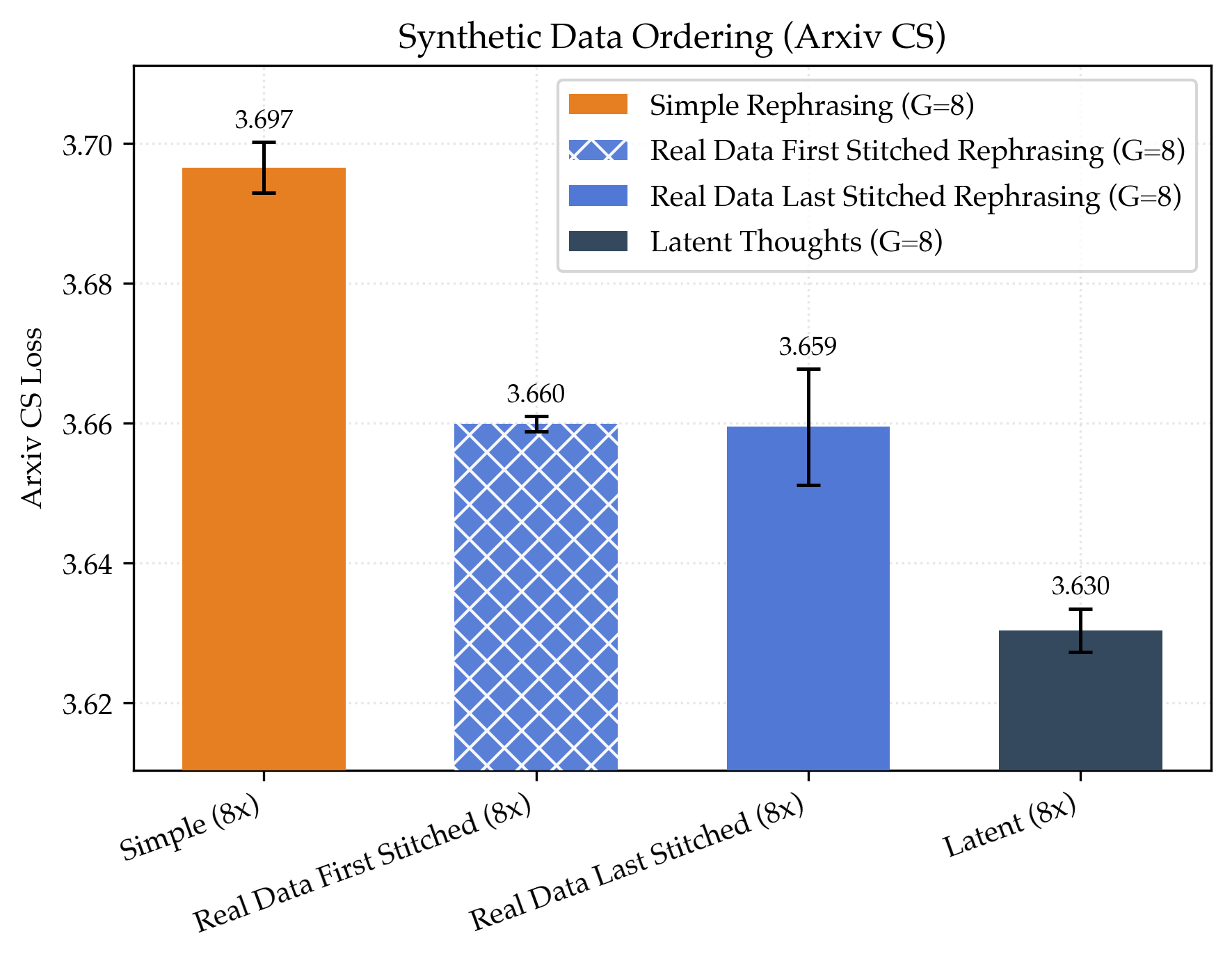
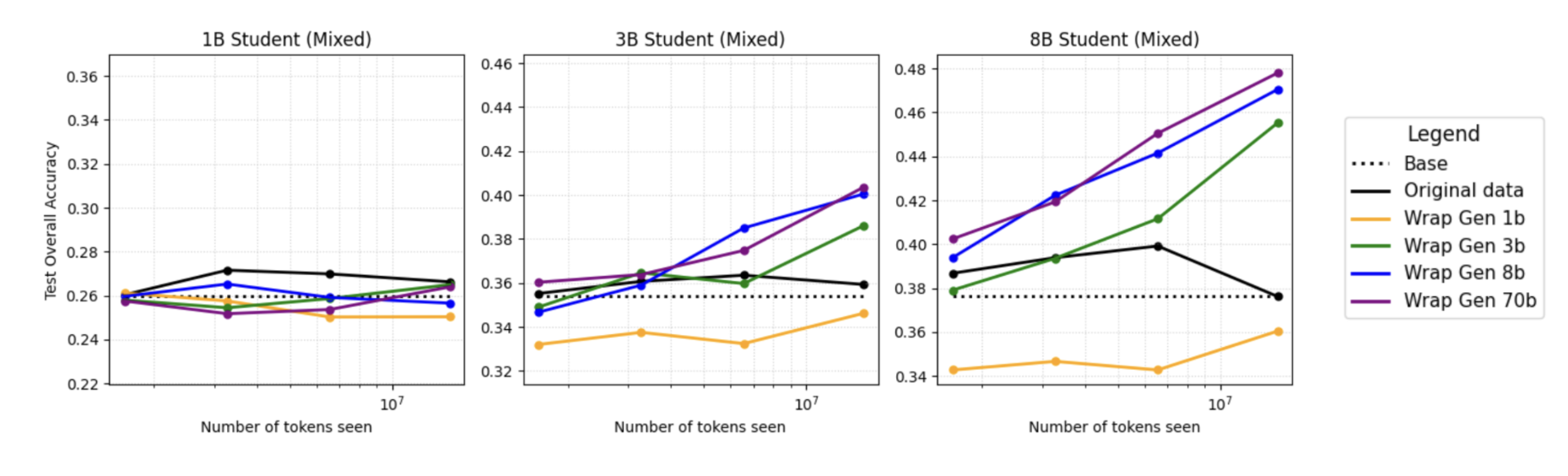
- Both methods improve performance on very long documents (like long research papers), not just short ones.
- Benchmarks improve by about 6% (stitched) and 9% (latent thoughts) over the real‑data‑only baseline.
- These methods show less sign of “plateauing” as you generate more versions per document.
- Why do megadocs work so well?
- They let the model train longer and “harder” without overfitting, because the synthetic data is better organized around each original document.
- Even when controlling for training length, megadocs still give a steady boost.
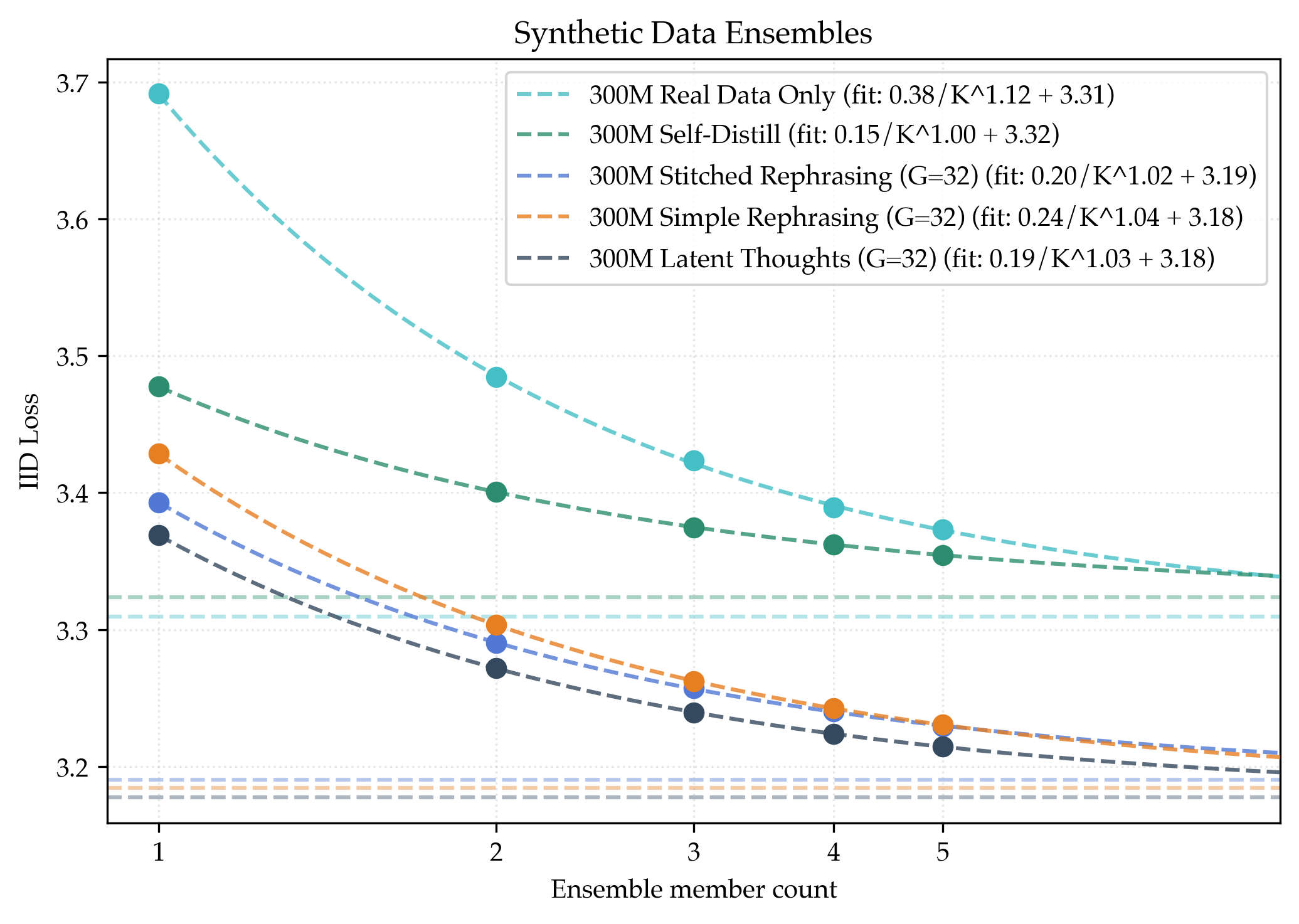
- They also checked ensembling:
- A different synthetic trick called self‑distillation did not improve the ensemble’s ultimate limit.
- But rephrasing, stitched rephrasing, and latent thoughts did lower the ensemble’s loss floor. That means these methods bring genuinely new, useful information that ensembles can use.
Why It Matters (Implications)
- We are running into a problem: computer power is growing faster than high‑quality web text. If we don’t find ways to be more data‑efficient, adding more compute won’t help much.
- This paper shows a practical recipe: generate multiple helpful versions of each document and organize them into megadocs. This makes smaller models learn more from the same real data.
- It also boosts long‑document understanding, which is crucial for technical articles, books, and multi‑step reasoning.
- The methods still help when you combine models into an ensemble, so they’re robust and broadly useful.
- While the paper used a stronger teacher model to create the synthetic data, the authors argue (and give evidence from other work) that these benefits should also appear when the student eventually teaches itself, given enough compute—similar to how data augmentation has long helped in computer vision.
A short glossary of key terms
Here are a few terms used in this paper, explained in everyday language:
- Token: a small piece of text (like a word or part of a word). Models read text as tokens.
- Validation loss: how “surprised” the model is when reading held‑out text. Lower is better.
- i.i.d. loss: the loss measured on the same kind of data the model was trained on, without mixing in synthetic text.
- Data efficiency: how much less real data you need to reach the same performance.
- Context window: how much text the model can process at once.
- Rephrasing: asking a stronger model to rewrite a document in a different way.
- Megadoc: a long document made by merging multiple generations (like rephrases or rationales) connected to the same original text.
- Latent thoughts: short “explanations” added between parts of a document to show how one part leads to the next.
- Ensemble: several models whose outputs are averaged, like a voting team.
Takeaway
By turning many synthetic generations per document into one long, well‑structured “megadoc,” we can train LLMs that:
- Learn more from less real data,
- Handle longer texts better, and
- Keep improving as we generate more helpful synthetic content.
This is a concrete step toward building better models even when high‑quality real text is limited.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up studies:
- Reliance on a stronger external generator: Verify whether the observed gains persist when the generator is trained from scratch on the same corpus as the student (self-improvement), and quantify dependence on teacher–student capability ratios across scales.
- Generalization beyond the studied scale: Test whether monotonic gains and reduced plateauing hold for larger models (e.g., 1B–7B+) and larger real-data budgets (>200M tokens).
- Context-length dependence: Assess how results change with longer training contexts (8k–32k) and without cross-document attention or with strict document-boundary masking.
- Robustness to hyperparameter choices: Systematically map sensitivity to mixing fraction, real-epoch count, weight decay, and learning rate, and identify settings where monotonic scaling breaks.
- Validity of “data efficiency” estimates: Refit scaling laws for mixed real+synthetic corpora rather than importing estimates from prior work; check whether the mapping from loss improvements to “× data” holds under synthetic mixing.
- Generator and prompt diversity: Evaluate rephrasing and thought-generation across prompts (styles beyond Wikipedia), temperatures, and different generators (e.g., GPT-4-class, smaller open models) to quantify dependence on stylistic and model choices.
- Distillation artifacts in latent thoughts: Measure how much of the gain is teacher leakage (e.g., n-gram overlap, rationale reuse) versus genuine learning; test with matched-capability or weaker generators.
- Deduplication and redundancy: Quantify near-duplicate rates across rephrases and between synthetic and real data; assess whether high-G regimes introduce harmful redundancy or data collapse.
- Memorization and privacy risks: Evaluate membership-inference or canary tests to determine whether repeating real documents (plus rephrases) increases memorization.
- Breadth of evaluation: Validate transfer beyond PIQA/SciQ/ARC-E and arXiv-CS perplexity using broader, stronger suites (e.g., MMLU, HellaSwag, NaturalQuestions, LongBench, RULER, L-Eval) and domain-specific tasks (code, math, multilingual).
- Long-context capability vs. long-context loss: Check whether perplexity improvements on long documents translate to end-to-end long-context tasks requiring cross-section retrieval and reasoning.
- Mechanistic understanding: Test the “epiplexity” inversion hypothesis by controlled experiments (e.g., predicting originals from paraphrases vs. the reverse), probe attention patterns, and isolate where predictive gains arise.
- Megadoc construction design space: Explore alternative orderings (e.g., interleaving real and rephrases), separators, metadata signals, and variable-length stitching strategies to find more effective megadoc layouts.
- Effect of including real docs in the synthetic stream: Ablate and quantify how much improvement is driven by cross-attention between real and synthetic tokens vs. the synthetic content itself.
- Tokenization and chunking choices: Evaluate dependence on tokenizer, EOS placement, concat-and-chunk strategy, and context packing; determine whether different packing schemes change the scaling.
- Compute realism: Replicate under fixed compute budgets (FLOPs- or time-limited) to measure practicality and cost-per-0.01-loss improvements, including generation costs for synthetic tokens.
- Scaling the number of generations beyond 32: Determine whether stitched/latent-thought megadocs eventually plateau and identify the point of diminishing returns.
- Cross-model variability and stability: Quantify variance across more seeds and across different generators; assess reliability of gains under realistic training noise.
- Ensembling interactions: Tune ensemble-specific hyperparameters for stitched/latent models, explore bagging across synthetic seeds/generators, and test composition with other data-efficiency techniques (e.g., pruning, diffusion LMs, EBMs).
- Domain and language generalization: Test effectiveness in non-English corpora, specialized domains (code, math, biomedical), and noisy web mixes to assess portability.
- Safety and style drift: Measure whether Wikipedia-style rephrasing homogenizes writing, shifts topical distribution, or affects toxicity/bias; analyze downstream safety impacts.
- Inference-time reasoning behavior: Check whether training with latent thoughts changes dependence on chain-of-thought at inference (with vs. without CoT), and its impact on hallucination and calibration.
- Interaction with architectural choices: Evaluate whether benefits persist under different architectures (e.g., MoE, recurrent memory, retrieval-augmented models) and training curricula.
- Alternative augmentations: Compare against other scalable augmentations (e.g., back-translation, noising, summarization-expansion, question–answer generation, contrastive span corruption) that could form megadocs.
- Data policy and licensing: Clarify legal/ethical constraints when using third-party generators and rephrasing into specific styles; assess implications for open releases of synthetic corpora.
Practical Applications
Overview
This paper introduces practical, scalable methods for data‑efficient LLM pre‑training using synthetic data: (1) simple rephrasing, (2) stitched rephrasing that concatenates multiple generations from the same source into a single “megadoc,” and (3) latent thoughts that stretch documents by inserting model-generated rationales between chunks. These approaches consistently reduce i.i.d. validation loss on the original data distribution, improve long‑context modeling, and compose with ensembling—yielding 1.48× to 1.80× effective data efficiency at constant model size. Below are actionable applications, organized by time horizon.
Immediate Applications
The following can be deployed with current tooling, including the authors’ open-source code and runs.
- Data-efficient pretraining for small/medium labs and startups
- Sector: software/AI
- Use case: Train 100M–1B parameter LMs with limited high-quality data by mixing real tokens with rephrased or megadoc-augmented tokens to reach lower loss without acquiring more data.
- Workflow/tools:
- Build a two-stream dataloader (real stream with finite epochs; synthetic stream with rephrases/megadocs, epoched indefinitely).
- Tune
mixing_fraction, realepoch_count, andweight_decay; implement concat-and-chunk with cross-document attention and no masking across megadoc boundaries. - Optionally ensemble different seeds for additional gains.
- Assumptions/dependencies: Access to a capable and appropriately licensed generator (e.g., Llama 3.1 8B Instruct); adequate compute to generate G rephrases/thoughts per document; careful hyperparameter tuning.
- Continued pretraining (CPT) for domain-specific LMs under data scarcity
- Sectors: healthcare, finance, legal, scientific R&D
- Use case: Improve clinical/legal/financial/science-domain LMs when domain data is limited by augmenting each document with rephrases or latent rationales, then stitching to form megadocs for better long-context modeling.
- Workflow/tools: Domain-tuned prompts for rephrasing/latent-thought generation; megadoc builder placing the real doc last; i.i.d. validation on held-out domain text; long-document validation (e.g., regulatory filings, case law, clinical notes).
- Assumptions/dependencies: Domain-competent generator (may require domain-tuned instruction models); data privacy constraints for sensitive text.
- Long-document assistants with improved comprehension and summarization
- Sectors: enterprise knowledge management, legal, pharma/science, government
- Use case: Improve long-document summarization, contract analysis, and literature review by leveraging models pre-trained with stitched/latent megadocs that reduce long-context loss.
- Workflow/tools: Fine-tune existing RAG or summarization pipelines with the megadoc-pretrained base; evaluate on long-document loss and downstream QA benchmarks.
- Assumptions/dependencies: Availability of long-context validation datasets relevant to the domain; integration with existing retrieval systems.
- Low-resource language/model development via synthetic augmentation
- Sector: education, public sector, NGOs, internationalization
- Use case: Augment small corpora in under-resourced languages by rephrasing and inserting explanatory thoughts to expand texts and improve generalization.
- Workflow/tools: Multilingual generators for rephrasing/thoughts; megadoc concatenation; monitor i.i.d. loss and key downstream tasks (e.g., QA).
- Assumptions/dependencies: Multilingual generator quality; careful prompt design for non-English languages.
- Faster prototyping of open-source models and datasets
- Sector: open-source AI ecosystems
- Use case: Adopt the provided code and W&B runs to reproduce data-efficiency gains and release stronger small models or data recipes (e.g., for OLMo-style initiatives).
- Workflow/tools: Integrate the repository’s mixing and concatenation logic; replicate hyperparameter searches; publish training curves and validation losses.
- Assumptions/dependencies: Compute to run generation and ablations; licensing for redistribution of synthetic data.
- Cost-effective on-device and edge models
- Sectors: mobile, embedded/robotics, IoT
- Use case: Reach target quality with smaller models (e.g., ~300M parameters) via synthetic megadocs, enabling on-device assistants and robotics instruction-following with reduced memory/latency budgets.
- Workflow/tools: Apply rephrasing + stitched/latent augmentation in pretraining; optionally ensemble during training and distill into a single edge model.
- Assumptions/dependencies: Edge deployment constraints; possible trade-off between training-time compute vs inference-time savings.
- Model ensembling that composes with synthetic augmentation
- Sectors: finance, healthcare, safety-critical applications
- Use case: Achieve lower asymptotic ensemble loss by combining independently trained (different seeds/orders) models that used rephrasing/stitched/latent augmentation.
- Workflow/tools: Train N members with varied seeds/data orders; ensemble by averaging logits; monitor ensemble scaling to asymptote.
- Assumptions/dependencies: Higher training compute for multiple members; increased inference cost unless distilled.
- Training data pipeline products/services
- Sector: MLOps/AI tooling
- Use case: Offer “rephrase-and-stitch” and “latent-thought injector” as managed services or SDKs to customers seeking data-efficient pretraining at scale.
- Workflow/tools: Prompt libraries; generation orchestration (temperature, length caps); megadoc assembly; hyperparameter search modules for
mixing_fractionandepoch_count. - Assumptions/dependencies: Generators under enterprise licenses; robust logging/observability (e.g., W&B).
- Educational LMs with improved reasoning flow
- Sector: education/edtech
- Use case: Use latent thoughts to produce guided explanations between sections of textbooks or study guides; pretrain/fine-tune LMs that better produce stepwise reasoning and handle long lessons.
- Workflow/tools: Thought-prompts between chapter subsections; megadoc pretraining; downstream tutoring evaluation.
- Assumptions/dependencies: Quality control for hallucinated explanations; alignment to curricula.
- Privacy-preserving augmentation under data access limits
- Sectors: healthcare, government, regulated industries
- Use case: When real data use is tightly controlled, generate rephrases/latent expansions within secure environments to reduce the need to move or replicate sensitive data.
- Workflow/tools: On-prem generator inference; megadoc construction within secure enclaves; audit trails for synthetic provenance.
- Assumptions/dependencies: Compliance review of generator usage; policies for labeling/storing synthetic text; rigorous privacy threat modeling.
Long-Term Applications
These require further research, scaling, or ecosystem development.
- Self-improving pretraining loops without external teachers
- Sectors: software/AI
- Use case: Co-evolve generator and student via on-policy or alternating cycles of rephrasing and latent thought generation, aiming for sustained improvements without external models.
- Dependencies: Stability of self-improvement; sufficient compute; safeguards against mode collapse or homogenization.
- Foundation models with native long-context competence at lower cost
- Sectors: enterprise AI, scientific discovery, legal/finance
- Use case: Train next-gen base LMs using megadocs to emulate multi-document reasoning and long-horizon coherence without massive raw data increases.
- Dependencies: Architectures that exploit cross-document signals and memory; efficient training on megadocs exceeding context.
- Retrieval-aware pretraining aligned with clustered evidence
- Sectors: search/RAG platforms, enterprise knowledge management
- Use case: Train models on stitched clusters of related documents (akin to retrieval batches) to natively aggregate across sources at inference.
- Dependencies: Joint design of retrieval pipelines and pretraining clusters; evaluation suites for multi-document reasoning.
- Sector-specific longitudinal reasoning
- Sectors: healthcare (patient history), finance (multi-quarter filings), legal (case chains), engineering (maintenance logs)
- Use case: Use latent thoughts to connect time-separated entries into rationalized narratives, improving forecasting and decision support.
- Dependencies: Domain-calibrated generators; strict factuality and provenance controls.
- Curriculum learning via latent thoughts and process supervision
- Sector: education, training/simulation
- Use case: Use rationales as scaffolded curricula that progressively deepen reasoning chains during pretraining and fine-tuning.
- Dependencies: Methods to prevent teaching spurious chains; alignment to human pedagogy.
- Standards and governance for synthetic pretraining data
- Sector: policy/regulation
- Use case: Develop guidelines for labeling, auditing, and validating synthetic megadocs; define metrics for loss-quality trade-offs and factuality.
- Dependencies: Multistakeholder consensus; certification pathways; tooling for audit logs and provenance.
- Synthetic data marketplaces centered on megadocs
- Sector: data economy
- Use case: Commercialize high-quality “rationalized” or “stitched” corpora, with quality metrics and benchmarks (i.i.d./long-context loss).
- Dependencies: IP/licensing clarity for generator outputs; reproducible quality scores; distribution infrastructure.
- Sustainability optimization
- Sector: ESG/green computing
- Use case: Use data-efficient recipes to offset the need for ever-larger real datasets; analyze compute-to-data trade-offs for carbon reductions.
- Dependencies: Lifecycle assessment frameworks; transparency of generation and training energy costs.
- Robustness and bias mitigation in synthetic augmentation
- Sector: safety/reliability
- Use case: Develop methods to diversify rephrasing/thought styles, detect homogenization, and calibrate the balance between real and synthetic streams.
- Dependencies: Bias audits tailored to synthetic corpora; diversity-aware prompting and sampling controls.
- Architecture co-design for megadocs
- Sector: model systems research
- Use case: Build architectures/memory modules optimized for learning across concatenated documents (e.g., cross-document attention variants, retrieval-augmented pretraining).
- Dependencies: Benchmarks isolating cross-document generalization; training stability at very long effective contexts.
- Legal/compliance frameworks for synthetic training data
- Sector: legal/compliance
- Use case: Establish norms around using synthetic expansions of proprietary documents, including privacy-preserving transformations and reuse policies.
- Dependencies: Jurisdiction-specific IP/privacy law interpretations; generator license agreements; watermarking and content labeling.
- Distillation of ensembles into compact production models
- Sectors: consumer apps, embedded AI, robotics
- Use case: Train with synthetic megadocs, ensemble for quality, then distill into a single efficient model for deployment.
- Dependencies: Reliable distillation that preserves long-context gains; evaluation of failure modes post-distillation.
Key Cross-Cutting Assumptions and Dependencies
- Generator capability and licensing: Quality of rephrases/latent thoughts depends on an instruction model with adequate skill in the target domain/language and acceptable commercial/open licenses.
- Hyperparameter sensitivity: Gains rely on tuning
mixing_fraction, realepoch_count, andweight_decay; naïve mixing can underperform. - Training mechanics: Implement concat-and-chunk with cross-document attention and disable masking across megadoc boundaries; manage context overflows gracefully.
- Compute availability: Although methods reduce real data needs, they may increase training steps and require nontrivial generation compute.
- Evaluation validity: i.i.d. loss correlated with benchmarks at this scale; confirm with downstream tasks, especially for long-context use cases.
- Safety, privacy, and bias: Synthetic corpora can propagate or amplify biases and style homogenization; apply audits, diversity controls, and synthetic provenance tracking.
- Domain transfer: For specialized sectors, generators may need domain adaptation; otherwise augmentation quality and factuality can degrade.
These applications translate the paper’s empirical findings into concrete deployments, while highlighting where further engineering or research is needed to operationalize the benefits at scale.
Glossary
- Ablations: Systematic experiments that vary components to understand their effects on performance. "Nonetheless, we are optimistic our findings will hold for self-improvement provided sufficient compute and data to train a generator from scratch. This is due to (1) ablations showing how synthetic data helps even more for more capable students"
- Asymptotically infinite compute regime: A setting assuming essentially unlimited training compute to study best achievable performance given fixed data/model. "We operate under the asymptotically infinite compute regime of \cite{kim2025pre} where we aim to train the best possible 300M parameter model given 200M real tokens"
- Autoregressive transformers: LLMs that predict each token conditioned on previous tokens using transformer architectures. "train over-parameterized 300M parameter autoregressive transformers with 4096 context length and cross-document attention"
- Concat-and-chunk: A data pipeline that concatenates documents and slices fixed-length context windows for training. "Each training sequence is formed by selecting a stream and consuming enough tokens to fill the next context window, commonly known as ``concat-and-chunk''."
- Cross-document attention: Allowing attention across document boundaries so tokens in one document can attend to tokens from others. "with 4096 context length and cross-document attention"
- Data efficiency: How much less real data is needed to reach the same performance compared to a baseline. "Stitched rephrasing and latent thoughts achieve and data efficiency at 32 generations"
- Data processing inequality: A principle stating that processing data cannot increase information about the original source variable. "It is commonly argued that if the generator comes from the same data as the student, synthetic data can not help due to the data processing inequality."
- Downstream benchmarks: Evaluation tasks used to assess whether pre-training improvements transfer to practical performance. "The loss improvements are matched by downstream benchmarks, improving average accuracy by on PIQA, SciQ, and ARC Easy."
- Ensembling: Combining predictions from multiple models (e.g., by averaging logits) to reduce error. "We test whether the benefits of our synthetic data algorithms compose with ensembling"
- Epiplexity: A metric quantifying the learnable structure in a data distribution, relating difficulty of inversion. "This may be related to epiplexity \citep{finzi2026entropyepiplexityrethinkinginformation}, a metric for quantifying the learnable structure in a distribution."
- Epoching: Training over the dataset multiple times, i.e., controlling the number of passes through the data. "we additionally decide whether the real doc goes before or after the rephrases as visualized in Figure \ref{fig:sorting_diagram}. We note that since the average rephrased document is 708 tokens and the average DCLM document is 1243 tokens, the length of the megadocs will quickly exceed the context window of 4096 tokens." (Note: also used as "epoching the synthetic stream indefinitely")
- EOS tokens: Special end-of-sequence markers inserted between documents. "Each stream is constructed by concatenating a random permutation of documents with EOS tokens."
- i.i.d. loss: Validation loss measured on data drawn from the same distribution as training (independent and identically distributed). "we can improve i.i.d.~loss on the original distribution (orange points)"
- In-context Pre-training (ICPT): A method that orders related documents together to improve learning from context. "In this section, inspired by In-context Pre-training (ICPT) \citep{shi2024incontextpretraininglanguagemodeling}, we propose the algorithm of ``stitching''"
- Latent Thoughts: An augmentation inserting model-generated reasoning steps between parts of a document to extend it. "Inspired by Latent Thoughts \citep{ruan2025reasoninglearnlatentthoughts}, we split each real doc into multiple chunks and stretch the document by inserting rationales"
- Logits: Pre-softmax model outputs that can be averaged across models when ensembling. "When ensembling, we average the logits of models trained with different data orders and random initializations"
- Long-context loss: Validation loss measured on datasets requiring modeling of long sequences. "Both megadoc algorithms improve over simple rephrasing for i.i.d.~validation loss, long-context loss, and downstream benchmarks."
- Megadoc: A single long document formed by combining multiple related generations or expansions from a source document. "we consider two synthetic data algorithms that leverage multiple generations to produce a single megadoc"
- Mixing fraction: The proportion of training batches drawn from the synthetic vs. real data streams. "Each training batch follows a specified mixing fraction (e.g. mixing fraction $0$ is only real data)."
- Off-policy: Using data generated by a fixed policy/model rather than the current model being trained. "The latent thoughts augmentation in this paper is an off-policy version of these methods where the thought generator is frozen and not learned."
- On-policy: Generating data using the current model/policy during training. "show that generating latent synthetic data from the student model in an on-policy fashion provides a useful signal"
- Over-parameterized: Models with more parameters than minimally needed, often improving optimization and generalization. "train over-parameterized 300M parameter autoregressive transformers"
- Power law: A functional relationship used to fit how metrics (e.g., ensemble performance) scale with size. "we use the asymptote (horizontal dotted line) of a power law to estimate the loss as the member count approaches infinity."
- Rationale: An explicit intermediate reasoning or explanation inserted between parts of a document. "prompt the generator to generate a rationale deriving the suffix from the prefix"
- Self-distillation: Training a model on data or targets produced by a previous model of similar architecture. "We find that an alternative form of synthetic data via self-distillation does not compose with ensembling"
- Stitched rephrasing: Concatenating all rephrases of the same document (and optionally the original) into one sequence. "Stitched rephrasing and latent thoughts achieve and data efficiency at 32 generations"
- Weight decay: A regularization technique that penalizes large weights to reduce overfitting. "All of our training runs tune the number of epochs on the real data with appropriate regularization via weight decay."
Collections
Sign up for free to add this paper to one or more collections.