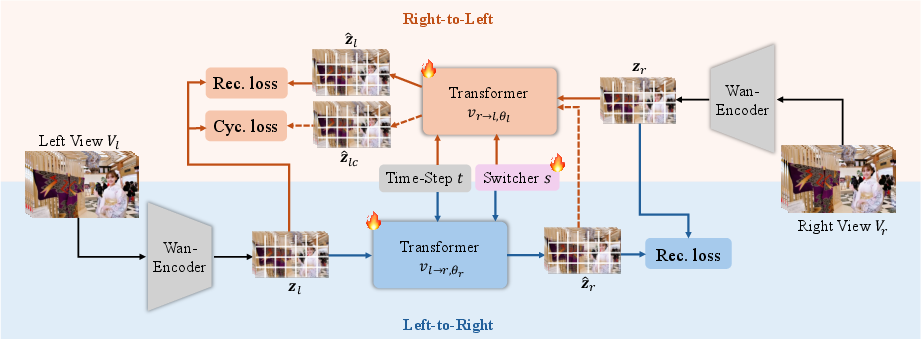
- The paper presents a unified generative approach that leverages a deterministic feed-forward diffusion process and a learnable domain switcher for both parallel and converged stereo formats.
- The model outperforms traditional Depth-Warp-Inpaint pipelines with higher SSIM, PSNR metrics and over 60× faster processing time, ensuring robust stereo synthesis.
- The work establishes the comprehensive UniStereo benchmark to standardize evaluation and foster advancements in mono-to-stereo video conversion techniques.
Unified and Efficient Stereo Video Conversion via Generative Priors
Introduction and Motivation
The proliferation of stereoscopic displays, ranging from VR headsets to 3D cinemas, necessitates scalable, high-fidelity monocular-to-stereo video conversion. Traditional content creation, either by using bespoke stereo filming rigs or manual conversion (e.g., Titanic's >60 week engineering lead time), is prohibitively expensive and labor-intensive. Automatic conversion pipelines, predominantly Depth-Warp-Inpaint (DWI) based, suffer from error propagation, depth ambiguity, and geometric inconsistency, especially when transitioning between parallel and converged stereo formats. The paper "StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors" (2512.16915) introduces both a unified dataset (UniStereo) and a novel feed-forward generative framework (StereoPilot) to address these technical bottlenecks.
Limitations of Prior Art
DWI pipelines first estimate monocular depth, then warp the input image and finally inpaint occluded regions. This three-stage approach incurs error amplification at every step, failing critically in environments with ambiguous or multi-valued depth—such as specular surfaces—where single-valued predictions fundamentally cannot encode the correct geometry or disparity. As illustrated, in reflection scenarios, the correct physical process entails multiple depths per pixel, which current models cannot recover, violating the expected inverse relationship between depth and disparity (Figure 1).
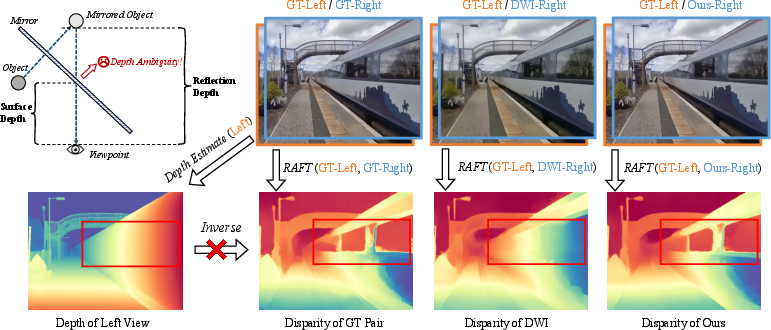
Figure 1: Depth ambiguity in reflection scenes; DWI-type pipelines fail to represent multiple depths per pixel, breaking the depth–disparity relationship and yielding incorrect geometric warping.
Furthermore, geometric assumptions diverge across stereo configurations: the parallel setup admits a simple inverse depth-disparity law, whereas the converged (toe-in) setup, standard in cinematic production, introduces zero-disparity planes and sign-variant disparities (Figure 2). Previous methods are often format-biased, trained and evaluated exclusively on private data of a single configuration.
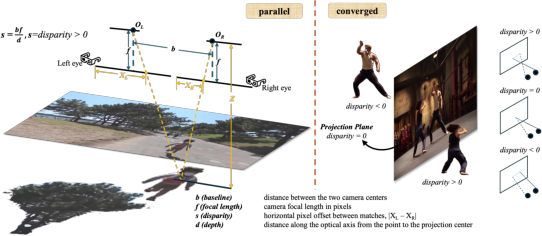
Figure 2: Geometric comparison of parallel and converged stereo setups; converged configurations feature a zero-disparity plane with polarity-dependent disparity, complicating warping.
End-to-end generative approaches (e.g., Deep3D, Eye2Eye) alleviate pipeline error propagation but either lack temporal coherence or are computationally infeasible, since iterative sampling typical of diffusion models incurs substantial latency and risk hallucinations (Figure 3).

Figure 3: Generative sampling can hallucinate non-existent scene content, highlighting the mismatch between stochastic video priors and deterministic stereo mapping.
UniStereo Dataset Construction
To standardize evaluation and facilitate cross-format learning, UniStereo comprises roughly 103,000 stereo video pairs with text captions, integrating both parallel (Stereo4D subset) and converged (3DMovie subset) video sources. For Stereo4D, videos are rectified (hfov = 90∘, resolution 832×480), temporally trimmed to 81 frames, and auto-captioned (Figure 4).
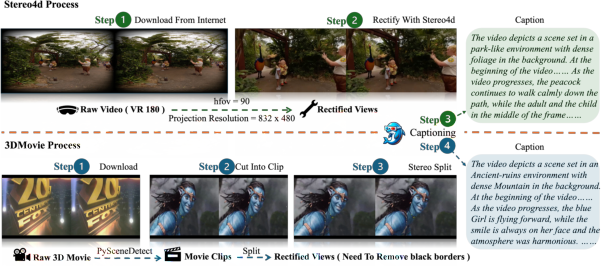
Figure 4: Processing pipeline for assembling the UniStereo dataset: green flow denotes parallel VR180 stereo video processing, blue flow denotes converged 3D movie segment extraction and cleaning.
Converged stereo data is curated from 142 rigorously verified 3D films, segmented, resampled, border-cropped, split into monocular streams, and captioned. The dataset strongly expands coverage for generalization benchmarks and multi-format compatibility.
StereoPilot Model Architecture
StereoPilot leverages a video diffusion transformer backbone, but innovatively reconfigures training and inference to match deterministic stereo conversion:
Experimental Analysis
StereoPilot is evaluated on both subsets of UniStereo, using fidelity metrics (PSNR, SSIM, MS-SSIM, perceptual LPIPS, SIOU) and processing latency; it is compared against state-of-the-art DWI and generative baselines (StereoDiffusion, StereoCrafter, SVG, ReCamMaster, Mono2Stereo, M2SVid).
Numerical results demonstrate strong superiority:
- On Stereo4D (parallel): SSIM $0.861$, MS-SSIM $0.937$, PSNR $27.735$, LPIPS $0.087$, SIOU $0.408$
- On 3DMovie (converged): SSIM $0.837$, MS-SSIM $0.872$, PSNR $27.856$, LPIPS $0.122$, SIOU $0.260$
- Baselines often lag by >15% absolute on structure metrics, and require >60× computational time.
StereoPilot synthesizes an 81-frame video in 11 seconds (vs. minutes for competitive models), supporting practical deployment.
Qualitative inspection confirms superior texture detail, stable and correct disparity—especially in challenging scenes involving mirrors and occlusions (Figure 7). The domain switcher exhibits substantial generalization to synthetic (Unreal Engine) content, resolving domain bias.
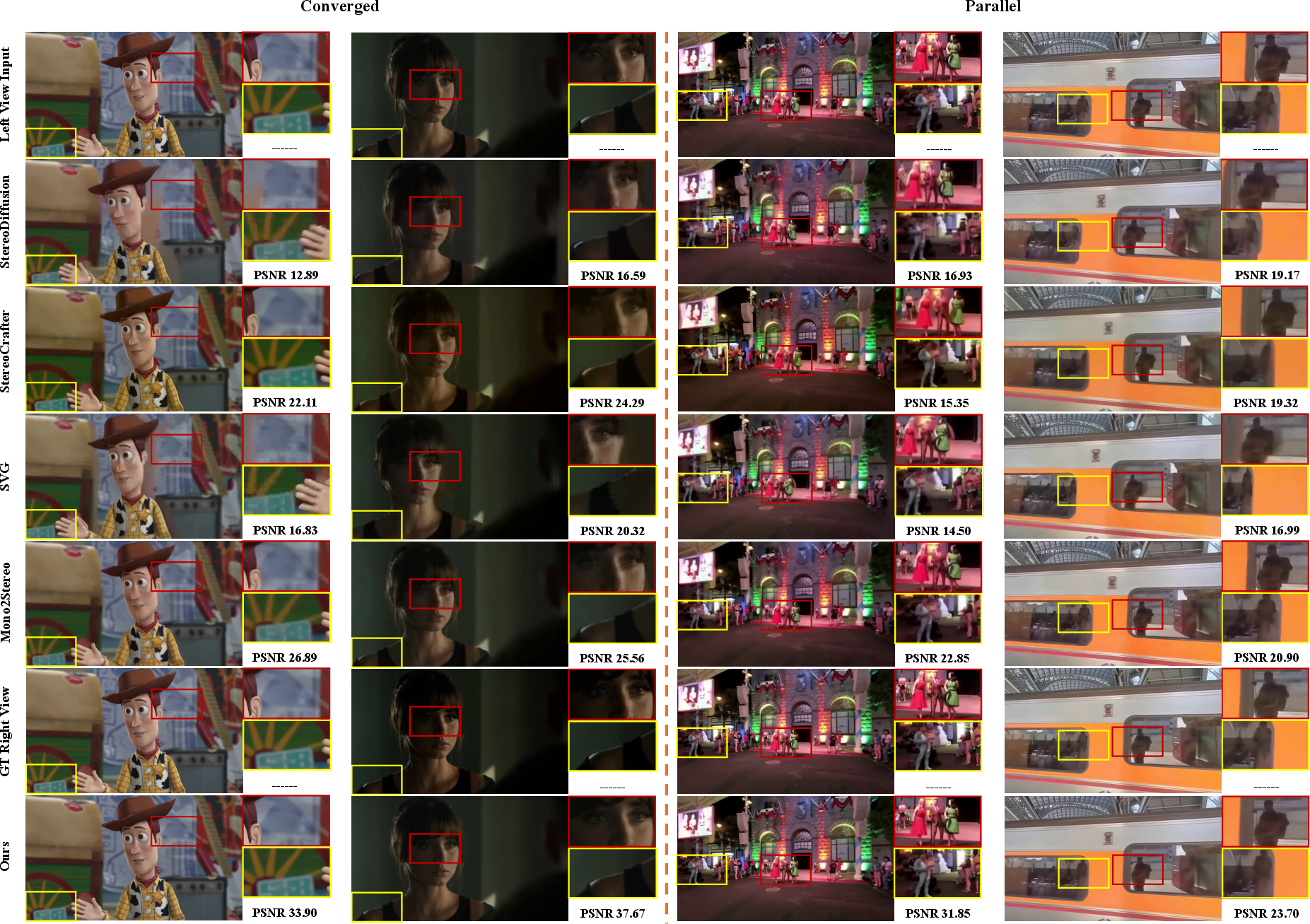
Figure 7: Qualitative comparison showing improved disparity estimation, texture preservation, and reduced artifacts; StereoPilot outputs align closely with ground truth across configurations.

Figure 5: Ablation of domain switcher: generalization performance improves markedly for parallel-style synthetic/anime test content.
Implications and Future Directions
StereoPilot's direct, unified approach overcomes core bottlenecks of the DWI and iterative generative paradigms—specifically error compounding, depth ambiguity, format inflexibility, and computational intractability. By constructing the UniStereo benchmark, the authors effectively standardize the evaluation and foster model comparability for mono-to-stereo conversion. The architecture advances high-fidelity, practical synthesis for both cinematic and real-time stereoscopic media.
Real-time conversion remains a technical challenge, as 11 seconds per 5-second video is insufficient for live streaming; future work may pursue autoregressive, sub-linear inference or efficient incremental feed-forward strategies. There's potential for transfer and application across 3D scene generation, multi-view synthesis, and general geometric vision tasks, especially in domains demanding reliable, temporally-coherent view consistency.
Conclusion
"StereoPilot: Learning Unified and Efficient Stereo Conversion via Generative Priors" (2512.16915) presents a rigorously evaluated, technically robust solution to stereo video synthesis, combining a unified dataset with an efficient, format-adaptive, deterministic pipeline. Its superiority in quality, robustness to scene ambiguity, and computational performance set a new reference for the field, and the dataset contribution is likely to have widespread impact on benchmarking and future generative 3D vision research.