- The paper introduces QueST, which employs difficulty-aware graph sampling and rejection fine-tuning to generate challenging coding problems for training LLMs.
- It introduces a novel difficulty metric, δ, using solution disagreement to select problems that significantly boost downstream model performance.
- Experimental results demonstrate that QueST-8B achieves state-of-the-art performance on benchmarks like LiveCodeBench and USACO, rivaling much larger models.
QueST: Incentivizing LLMs to Generate Difficult Problems
Introduction
The paper introduces QueST, a framework for training LLMs to generate challenging competitive coding problems at scale. The motivation stems from the limitations of existing datasets, which are constrained by the need for expert human annotation and lack sufficient scale and difficulty to advance LLM reasoning capabilities. QueST addresses these bottlenecks by combining difficulty-aware graph sampling and rejection fine-tuning, directly optimizing LLMs to synthesize hard problems that are beneficial for downstream model training.
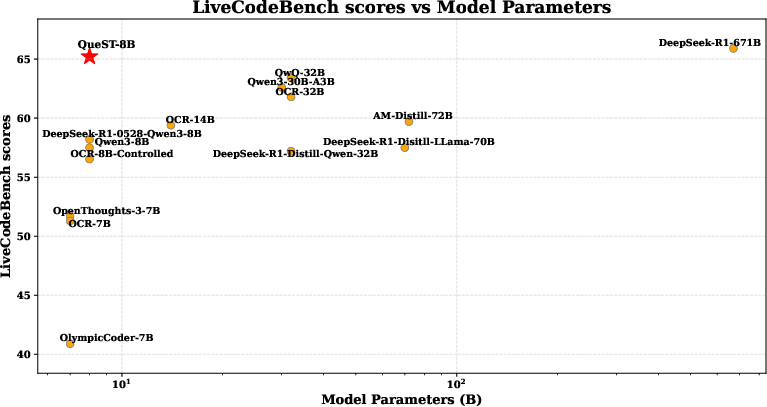
Figure 1: Comparisons of Livecodebench scores and model parameters between LLMs trained using various methods. QueST-8B achieves a new Pareto optimum.
QueST Framework
Scaffolding via Concept Graphs
QueST builds on the MathScale pipeline, extracting fine-grained concepts (topics and knowledge points) from seed problems using LLM prompting. These concepts are used to construct a weighted graph, where nodes represent concepts and edge weights encode co-occurrence statistics. Random walks on this graph sample plausible concept combinations, which are then used to prompt LLMs for new problem generation. Few-shot in-context learning is employed, selecting exemplars based on Jaccard distance in concept space.
Difficulty-aware Sampling and Rejection Fine-tuning
To incentivize the generation of difficult problems, QueST introduces a difficulty estimation metric δ(q), based on the self-consistency of model-generated solutions. For each generated problem, multiple candidate solutions are produced and executed on a set of test cases. The difficulty is quantified as the average disagreement rate among outputs, with higher δ(q) indicating greater challenge.
For each prompt, multiple candidate problems are generated; only the most difficult (highest δ(q)) is retained for fine-tuning the generator. This rejection fine-tuning process iteratively specializes the generator towards producing harder problems.
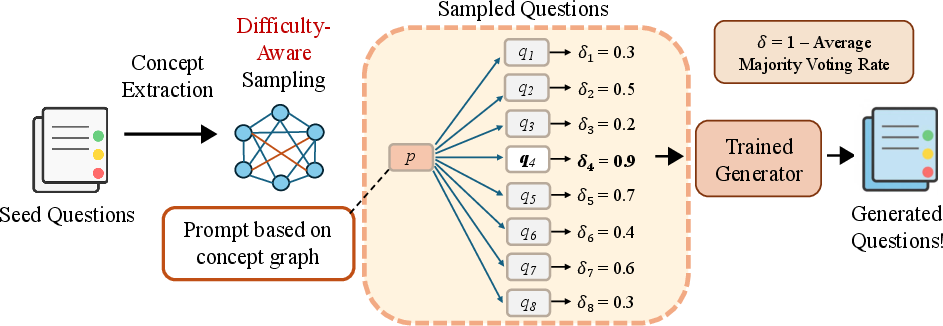
Figure 2: The pipeline of QueST, including concept extraction, difficulty-aware sampling, and rejection fine-tuning.
Difficulty-aware Graph Construction
Edge weights in the concept graph are further refined by incorporating human-annotated difficulty levels from seed datasets. The new edge weight is a convex combination of co-occurrence frequency and average difficulty, controlled by a hyperparameter α. This biases the sampling process towards concept combinations historically associated with harder problems.
Experimental Results
Data Selection and Difficulty Estimation
Empirical analysis demonstrates that selecting problems with the highest estimated difficulty δ yields superior downstream performance compared to random or response-length-based selection. There is a positive correlation between response length and difficulty, but δ is a more efficient and effective proxy.
QueST-generated problems are paired with long chain-of-thought solutions from strong teacher models (e.g., Qwen3-235B-A22B) and used to distill smaller student models. The QueST-8B model, trained on 100K QueST-generated and 112K human-written problems, achieves state-of-the-art results among models of similar size on LiveCodeBench and USACO, matching the performance of much larger models such as DeepSeek-R1-671B.
Reinforcement Learning
QueST data is also leveraged for RLVR, using majority voting as pseudo-labels for verifiable reward. RL experiments show that models trained on QueST data achieve higher performance on hard problems, with training reward curves indicating that QueST-generated datasets are more challenging than both human-written and baseline synthetic datasets.
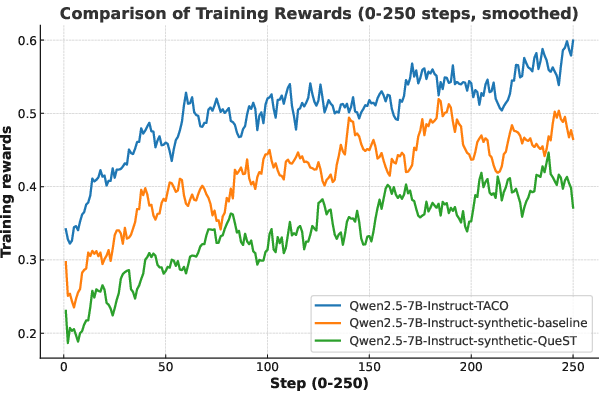
Figure 3: Training rewards comparison in the training process of RL under different datasets.
Ablation Studies
Ablation experiments confirm that both difficulty-aware graph sampling and rejection fine-tuning contribute positively to the generation of difficult problems. Models trained solely on QueST synthetic data outperform those trained on OCR problems, and merging both datasets yields the best overall performance.
Knowledge Point Distribution
Difficulty-aware sampling upweights infrequent, harder knowledge points and downweights common, easier ones, as visualized in the knowledge point frequency analysis.
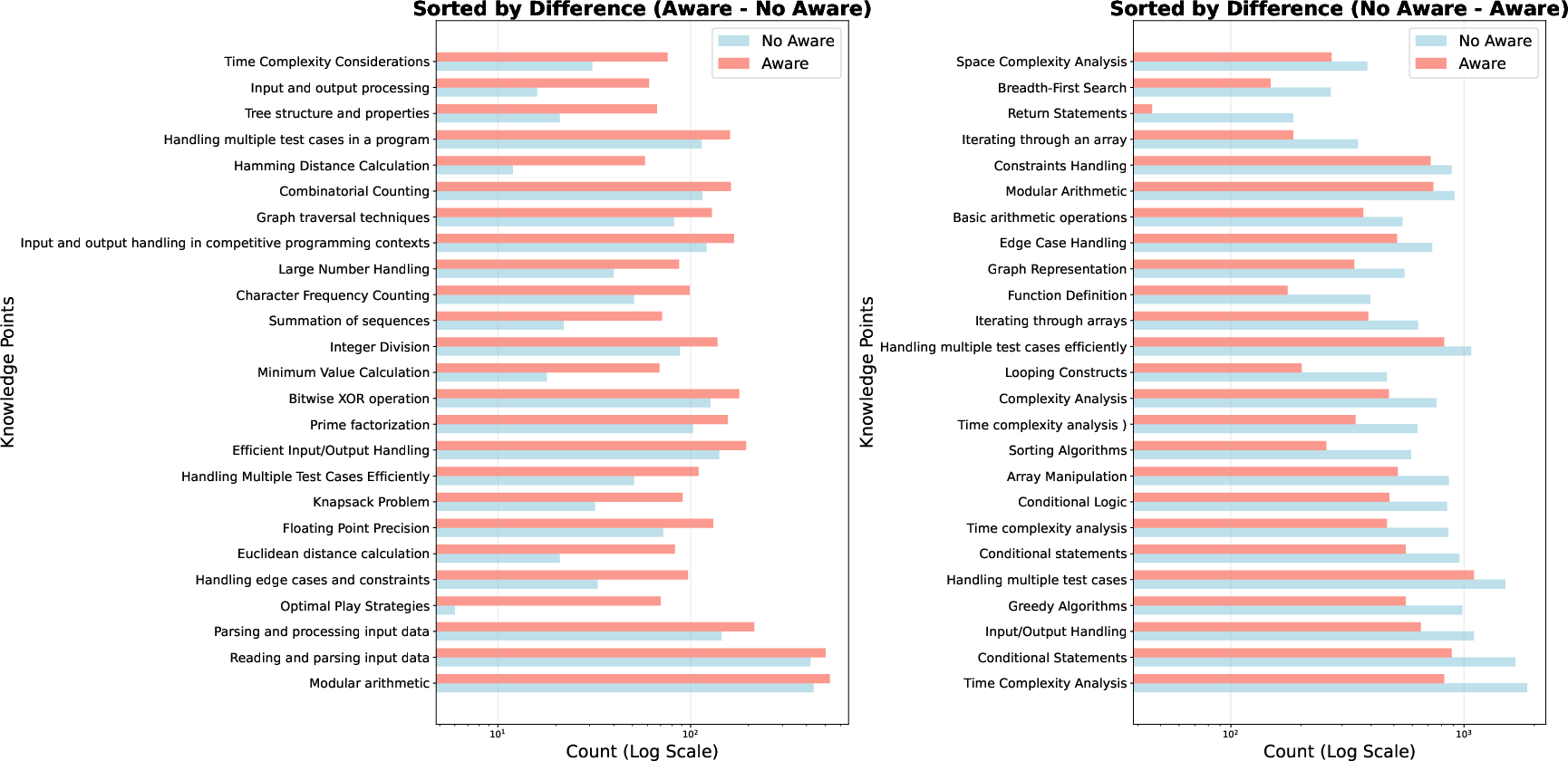
Figure 4: Examples of knowledge points where the count is increased (left) or decreased (right) when using difficulty-aware sampling.
Prompt Engineering
The paper provides detailed prompt templates for concept extraction, problem generation, and test case generation, employing multi-shot in-context learning to guide the LLMs.

Figure 5: 1-shot prompt example for problem generation (simplified; real prompt uses 8-shot).

Figure 6: 1-shot example prompt for testcase generation.
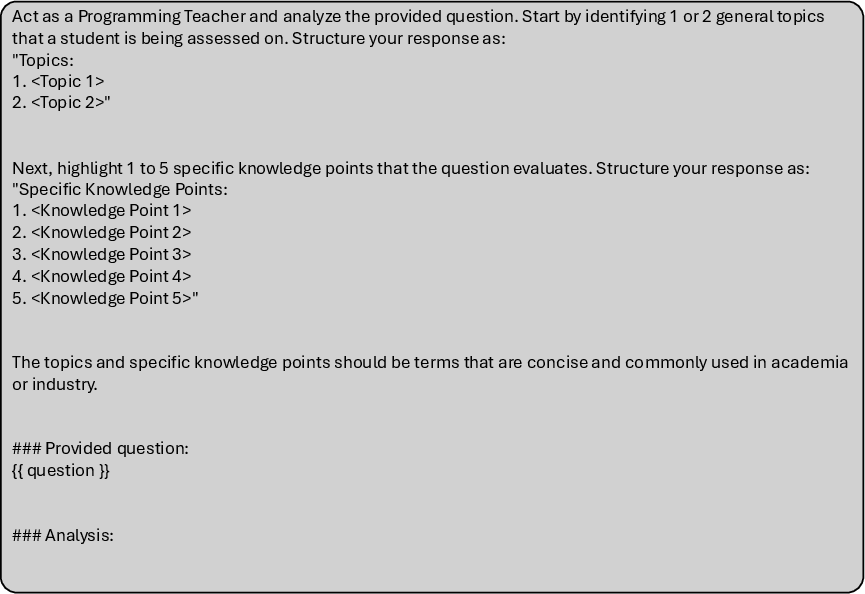
Figure 7: Prompt demonstration for concept extraction.
Implementation Considerations
- Computational Requirements: Difficulty estimation is computationally intensive, requiring multiple solution generations and executions per problem. This limits real-time RL applications.
- Scaling: The framework is scalable for SFT and distillation, but RL integration would require more efficient difficulty proxies or reward models.
- Contamination Analysis: Token-based similarity checks confirm no contamination between generated data and evaluation benchmarks.
Implications and Future Directions
QueST demonstrates that direct optimization of LLMs for difficult problem generation is feasible and effective, enabling smaller models to match or exceed the performance of much larger counterparts. The approach is generalizable to other reasoning domains (e.g., math), provided verifiable solution mechanisms exist.
Future work should focus on integrating real-time difficulty estimation into RL pipelines, potentially via learned reward models, and exploring the transferability of QueST-generated data to broader reasoning tasks.
Conclusion
QueST provides a principled framework for generating challenging synthetic coding problems, combining difficulty-aware sampling and rejection fine-tuning. The resulting data enables efficient distillation and RL training, advancing the capabilities of LLMs in competitive coding and reasoning. The methodology is extensible, and its empirical results suggest that targeted synthetic data generation is a key lever for scaling LLM reasoning performance.

