- The paper introduces a novel inference framework using <memory> and <reason> tokens to distinctly control memory recall and logical reasoning in large language models.
- It demonstrates significant accuracy improvements on benchmarks such as StrategyQA (78.6%), CommonsenseQA (82.3%), and TruthfulQA (86.6%), outperforming traditional methods.
- The method enhances interpretability and robustness by clarifying error sources and paving the way for adaptive memory and reasoning strategies in high-stakes domains.
Disentangling Memory and Reasoning Ability in LLMs
Introduction
This paper presents a methodological advance in the inference process of LLMs, addressing the inherent opacity of current models when separating memory recall from logical reasoning in complex tasks. By introducing a novel inference paradigm, the research delineates these processes with two special tokens: ⟨memory⟩, for knowledge retrieval, and ⟨reason⟩, for reasoning steps. These interventions aim to enhance model interpretability, accuracy, and robustness by clarifying the decision-making process of LLMs, which is often muddled by hallucinations and knowledge forgetfulness.
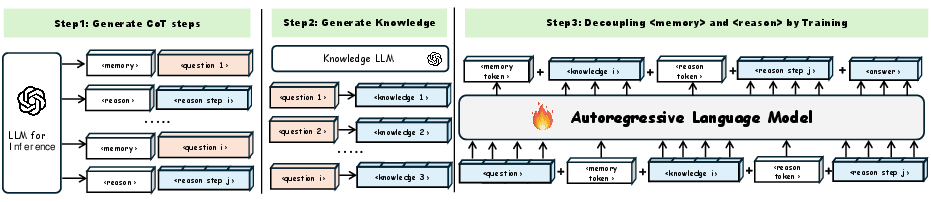
Figure 1: Workflow: The first and second steps are mainly used for training data synthesis, while the third step involves fine-tuning the LLM using data with added ⟨memory⟩ tokens and ⟨reason⟩ tokens.
Methodology
The paper proposes a three-step approach:
- Data Generation: Using a powerful LLM such as GPT-4, the authors generate annotated actions that separate memory from reasoning through designated tokens. This step leverages itemized actions for various question-answering tasks, ensuring structured guidance during training.
- Training with Control Tokens: A custom LLM is trained using data embedded with the special tokens ⟨memory⟩ and ⟨reason⟩. These tokens act as control signals, systematically guiding the model in differentiating between knowledge recall and reasoning, enabling it to resolve complex queries more efficiently.
- Error Analysis: The model is tested on multiple benchmarks—StrategyQA, CommonsenseQA, and TruthfulQA—to evaluate the disentanglement efficacy of memory and reasoning. The analysis identifies where errors stem from, predominantly emphasizing challenges in reasoning rather than memory recall.
Experimental Results
Significant improvement is demonstrated across benchmarks:
- StrategyQA: Achieves 78.6% accuracy with LLaMA-3.1-8B, showcasing a 1.3% improvement over baseline approaches.
- CommonsenseQA: Boasts an 82.3% accuracy, indicating profound enhancement over traditional CoT methods.
- TruthfulQA: Surpasses GPT-4's performance, achieving 86.6% accuracy, which corroborates the utility of the proposed method in high-stakes domains.
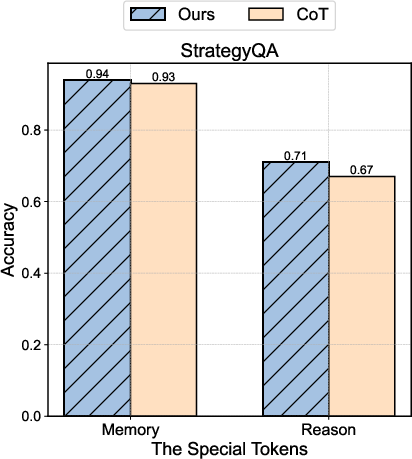
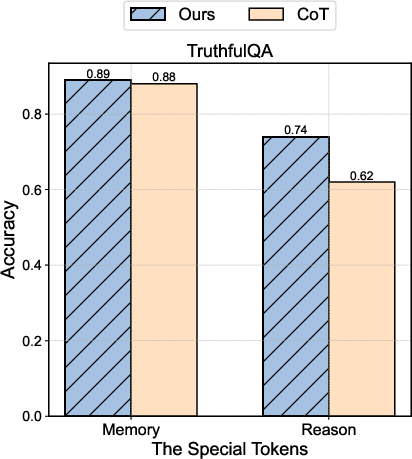
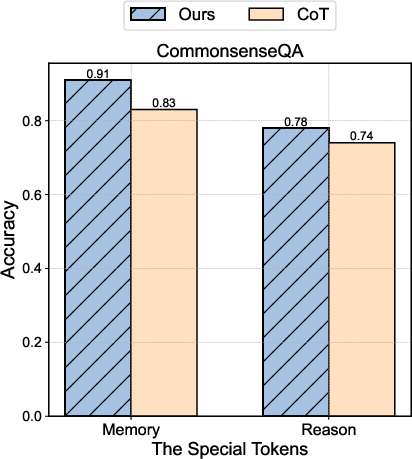
Figure 2: Decoupling Result Comparison Between Our Algorithm and One-Shot CoT prompting on all datasets and both on LLaMA-3.1-8B.
Case Study: Attention Analysis
Attention mechanisms in enhanced LLMs reflect increased focus on specialized tokens during reasoning processes, substantiating the hypothesis that these tokens play critical roles in streamlining knowledge and inference sequences.
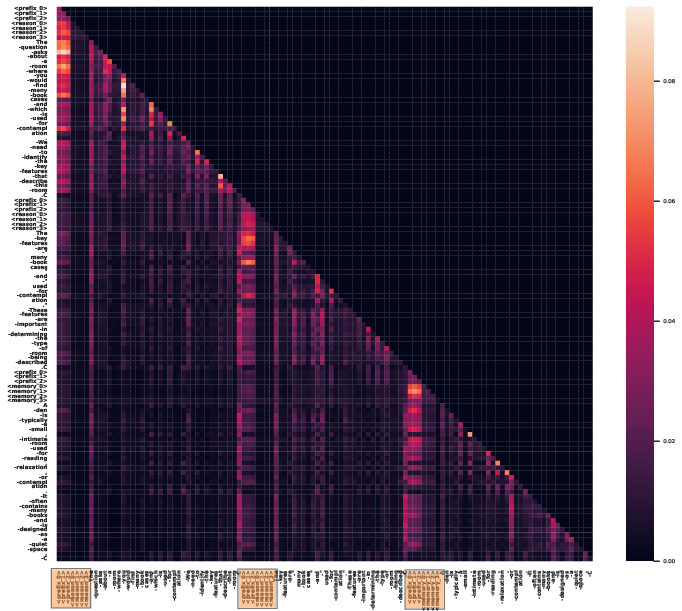
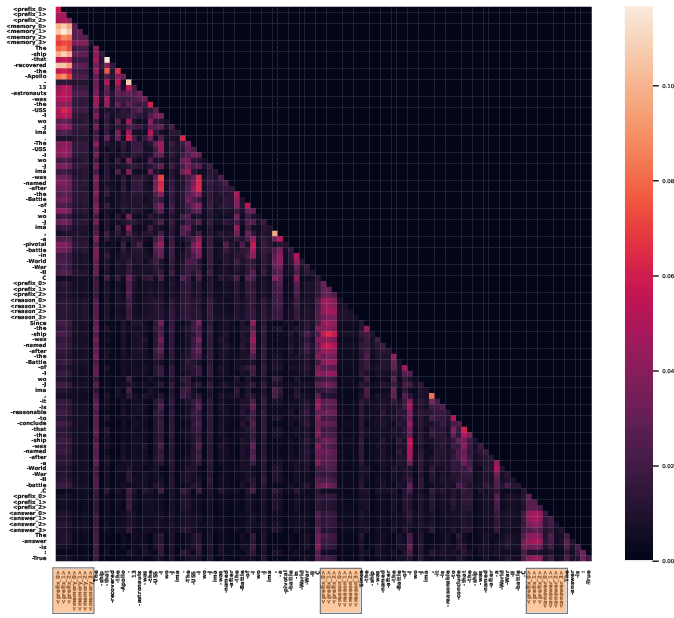
Figure 3: Two test examples' attention Heatmap generated by LLaMA-3.1-8B enhanced with reason and memory control tokens with the same attention head. The highlighted parts are these special tokens.
Limitations and Future Work
The research acknowledges limitations in computational overhead due to increased sequence lengths in inference tasks. Future work aims to explore dynamic memory updating and adaptive reasoning steps to further enhance model capability and efficiency.
Conclusion
The paper successfully introduces a structured framework for LLMs that demarcates memory recall and reasoning, facilitating improved accuracy and interpretability in complex tasks. This paradigm promises substantial applicability in domains requiring transparent inference processes, such as healthcare and finance, paving the way for future research into adaptive and scalable memory-reasoning mechanisms.

Figure 4: Incorrect Sample Showing: The green sections represent the questions, the steps of the answers, and the incorrect answers; the yellow areas indicate the correct answers, and the red highlights the causes of the errors.

