Gym-V: A Unified Vision Environment System for Agentic Vision Research
Abstract: As agentic systems increasingly rely on reinforcement learning from verifiable rewards, standardized ``gym'' infrastructure has become essential for rapid iteration, reproducibility, and fair comparison. Vision agents lack such infrastructure, limiting systematic study of what drives their learning and where current models fall short. We introduce \textbf{Gym-V}, a unified platform of 179 procedurally generated visual environments across 10 domains with controllable difficulty, enabling controlled experiments that were previously infeasible across fragmented toolkits. Using it, we find that observation scaffolding is more decisive for training success than the choice of RL algorithm, with captions and game rules determining whether learning succeeds at all. Cross-domain transfer experiments further show that training on diverse task categories generalizes broadly while narrow training can cause negative transfer, with multi-turn interaction amplifying all of these effects. Gym-V is released as a convenient foundation for training environments and evaluation toolkits, aiming to accelerate future research on agentic VLMs.









Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A Simple Guide to “Gym‑V: A Unified Vision Environment System for Agentic Vision Research”
What is this paper about?
This paper introduces Gym‑V, a “practice gym” for AI systems that look at images and decide what to do. Think of it like a huge collection of visual puzzles and games that an AI can practice on, with clear rules, automatic scoring, and adjustable difficulty. The goal is to make training and testing “vision agents” (AIs that see and act) easier, fairer, and faster for everyone.
What questions are the researchers asking?
- Can we build one simple, standard place where vision AIs can learn and be compared fairly?
- What matters most for helping these AIs learn—fancy training algorithms, or the way we show them the tasks (like adding captions or rules)?
- Do skills learned in one type of visual task carry over to different tasks, or can training on narrow tasks hurt performance elsewhere?
- How much harder do tasks get when an AI must make many moves over time (like playing a game) instead of giving a one‑shot answer?
How did they do it?
The team built Gym‑V, a big platform with many kinds of visual challenges, and used it to run controlled experiments.
- A huge “gym” of tasks:
- 179 visually based environments across 10 categories (like logic puzzles, geometry, board games, navigation, and retro video games).
- Two modes:
- Single‑turn (one‑shot puzzles): the AI looks once and answers.
- Multi‑turn (games and navigation): the AI makes a sequence of moves.
- Difficulty levels you can turn up like a video game (small board → large board, few objects → many objects, etc.).
- Procedural generation (the computer makes fresh, random puzzles), so the AI can’t just memorize answers.
- Simple but powerful interface:
- All tasks share the same basic “reset/step” loop (reset = start a new puzzle; step = make a move and get feedback), like a standard video‑game controller for AI.
- Works for single or multiple agents (e.g., two players), and for both online practice and offline datasets.
- “Wrappers” that control what the AI sees:
- The team can easily add or remove helpful info: game rules, captions that describe the image, or recent history of actions.
- These “wrappers” are like turning on captions, instructions, or a replay window in a game—without changing the game itself. This lets them test how much those supports help learning.
- Easy, consistent scoring:
- For tasks with clear rules (like Sudoku), the platform checks correctness automatically.
- For creative tasks (like rating a generated image), Gym‑V uses a central “evaluation service” so models can be scored fairly and efficiently.
- Experiments:
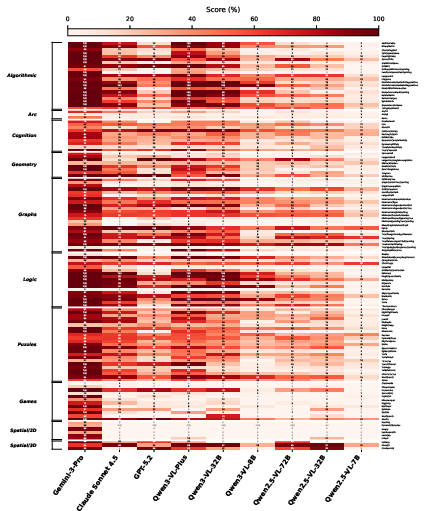
- Tested 9 different vision‑LLMs (AIs that understand both images and text) with no training (“zero‑shot”) to see where they stand.
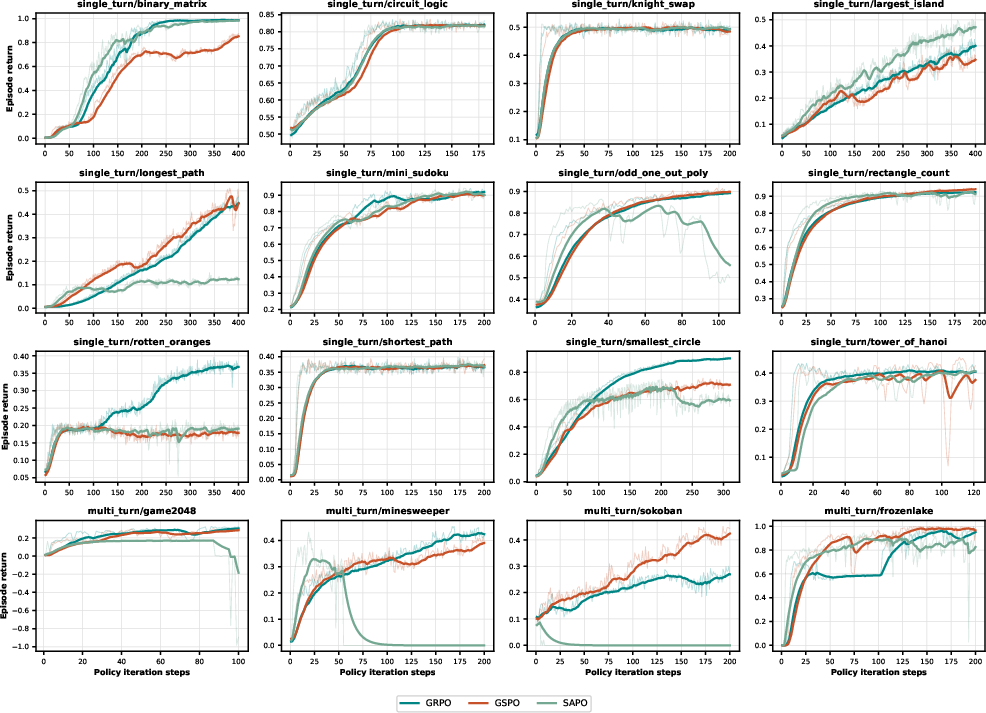
- Trained models with several reinforcement learning (RL) methods (GRPO, GSPO, SAPO). Reinforcement learning is like learning by trial‑and‑error with rewards—think of a player trying moves, getting points, and improving over time.
- Systematically switched on/off extra help like rules, captions, and history to see what really helps.
- Studied “transfer”: training on one set of tasks and testing on others.
What did they find, and why is it important?
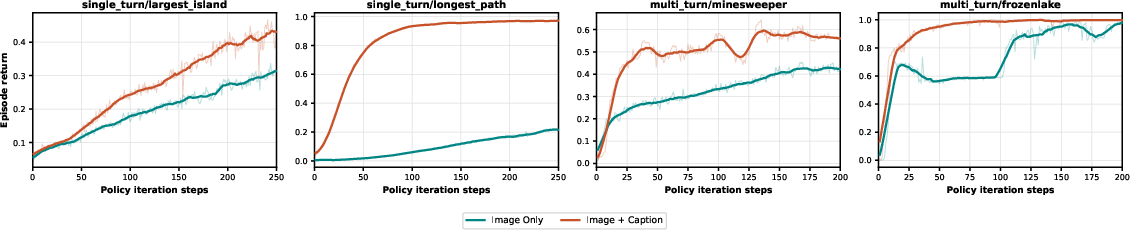
- The way you show the task to the AI matters most.
- Adding captions to images and including the game rules often made the difference between success and failure.
- In plain terms: a brief explanation or label can help the AI learn much faster than just staring at pixels.
- The training algorithm matters—but less than the scaffolding.
- No single RL method (GRPO, GSPO, SAPO) was best everywhere.
- Differences showed up most in long, multi‑turn games. Some methods stayed more stable over many moves; others sometimes “fell apart.”
- Takeaway: pick the RL method to suit the task, but don’t expect one to win everywhere.
- Training on diverse tasks helps you generalize; training too narrowly can backfire.
- Learning across varied categories (with many sub‑skills) transferred well to new tasks.
- Focusing on a narrow type of task could cause “negative transfer”—getting worse at different tasks because you learned shortcuts that don’t apply elsewhere.
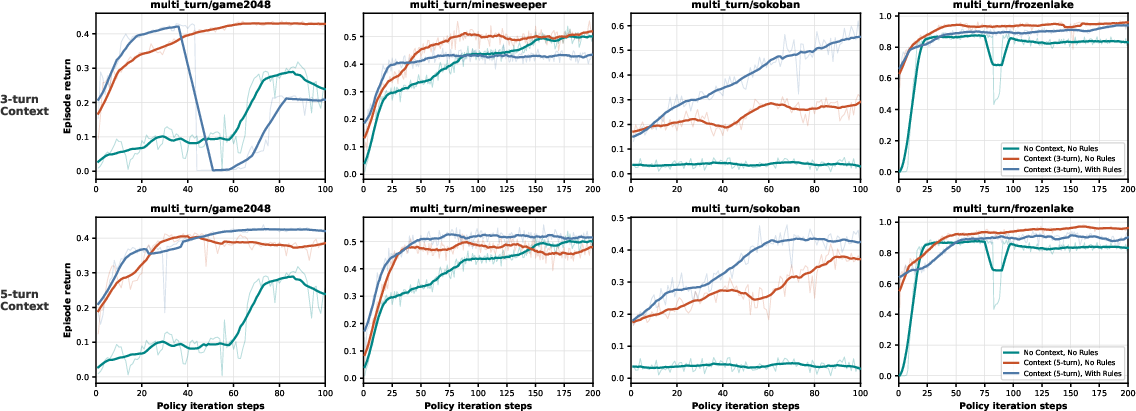
- Multi‑turn tasks are much tougher and amplify everything.
- Longer games made small problems (like poor instructions or weak algorithms) much bigger.
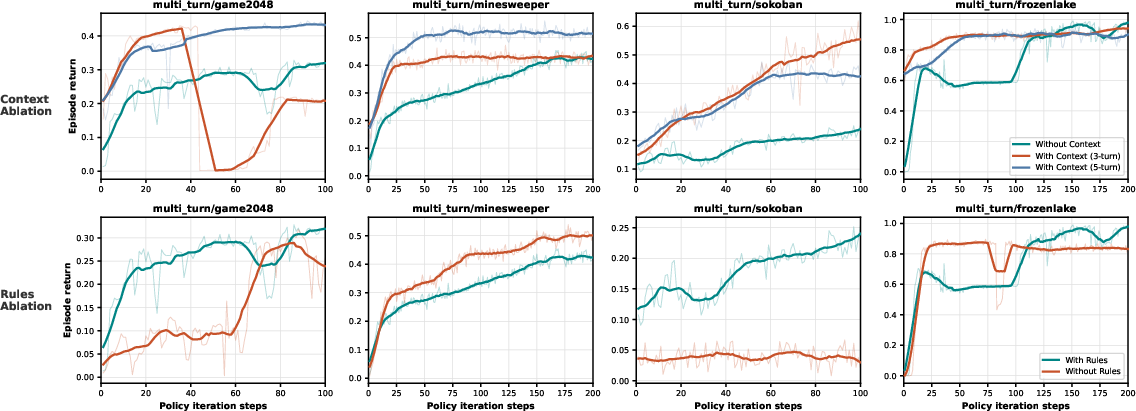
- Giving the AI recent history (a short memory of its past moves and observations) helped a lot, especially in games where a wrong move can trap you.
- Big capability gaps remain.
- Newer, well‑trained models sometimes beat older, larger models.
- Some categories (like ARC‑style abstract pattern tasks) remain hard even for very strong models.
- As difficulty increases, performance can drop sharply (a “difficulty cliff”), showing there’s still lots of room for improvement.
What does this mean for the future?
- A common practice ground for vision AIs:
- Gym‑V makes training and comparing different vision agents much easier and fairer, which should speed up progress for everyone.
- Design the “lesson,” not just the “learner”:
- Clear instructions, captions, and the right amount of history can make learning faster and more reliable than simply swapping algorithms.
- Smarter curricula:
- Training across varied tasks builds more flexible skills and avoids bad habits that hurt elsewhere.
- Better long‑term agents:
- Since multi‑turn tasks amplify weaknesses, Gym‑V helps researchers stress‑test and improve agents for real‑world settings where decisions unfold step by step.
In short, Gym‑V is like a well‑equipped sports complex for AI vision. It offers lots of drills, fair scoring, and adjustable coaching (rules, captions, history). The big lesson: how we present and support the tasks is crucial—often more than which training routine we use. This platform should help researchers build smarter, more general vision agents faster.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of unresolved issues and open directions that future researchers can act on:
- Inconsistent suite specifications: the paper alternately reports 179 vs 202 environments and 10 vs 11 categories; clarify the canonical count, taxonomy, and versioning to ensure reproducibility and consistent comparisons.
- Limited validation of multi-agent claims: despite multi-agent API support, no experiments demonstrate cooperative/competitive training, self-play, or emergent behaviors; add controlled multi-agent studies to validate the interface and learning dynamics.
- Tool-augmented workflow untested: tools (e.g., Python interpreter) are supported via wrappers but no empirical results quantify when/why tool use helps in vision RL; benchmark tool-use vs no-tool baselines across perception-heavy tasks.
- Narrow algorithmic coverage: only GRPO, GSPO, and SAPO are evaluated; compare against standard PPO/A3C, off-policy (e.g., SAC/TD3), model-based/control-variate methods, credit-assignment (e.g., temporal value transport), and hybrid IL+RL to establish broader baselines for long-horizon vision tasks.
- Missing ablations on perception vs reasoning: the paper attributes bottlenecks to perception but does not isolate encoder vs policy/reasoning contributions; run encoder swaps, frozen-encoder vs finetuned, and OCR/structured perception proxies to quantify bottleneck sources.
- Caption/rule scaffolding realism: captions and explicit rules substantially aid learning but may be unavailable at deployment; study (i) performance when scaffolding is removed at test time, (ii) auto-generated vs ground-truth captions, and (iii) minimal sufficient scaffolding to avoid overfitting to textual hints.
- Standardization of captions: the source, quality, and variability of captions are not specified; define a reproducible caption generation protocol (model/version, prompts, noise) and measure sensitivity to caption errors/latency.
- History/context design space: only short fixed windows (0/3/5 turns) are tested; explore retrieval-based memory, episodic summaries, learned state abstraction, and budgeted context policies to trade off token cost vs performance.
- Negative transfer mitigation: the study documents negative transfer but offers no mitigation; investigate curriculum optimization (automatic syllabus, domain mixing, difficulty shaping), regularization to prevent domain-specific shortcuts, and meta-learning for rapid adaptation.
- Skill taxonomy and diagnostics: asymmetries in transfer imply a skill hierarchy, but no analysis maps tasks to latent skills; develop skill probes, factorized evaluation, and representation diagnostics to explain what transfers and why.
- Video/temporal tasks underexplored: “none of the models could complete the video task within a certain cost” is noted but unanalyzed; evaluate streaming encoders, frame selection, temporal abstractions, and cost-aware policies to make video RL tractable.
- Sparse coverage of temporal control in training: retro/temporal tasks are evaluated but not trained; include RL on temporal environments to test stability, latency constraints, and reaction-time tradeoffs.
- Generative EaaS evaluation drift: the reward service aggregates learned evaluators (e.g., CLIP/HPS/VLMs) but no policy for versioning, calibration, or drift control is described; formalize model pinning, semantic versioning, and regression tests to ensure longitudinal comparability.
- Reward model bias and hackability: no robustness tests show whether agents exploit reward quirks (e.g., CLIP bias); add adversarial audits, counterfactual prompts, and mixed-reward ensembles to quantify and harden against reward hacking.
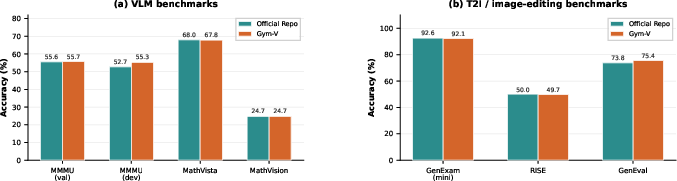
- Fidelity validation scope: evaluation fidelity is shown on a few datasets/models; expand cross-benchmark parity checks (more VLMs/settings, ablations on prompts/scorers) and report disagreement analyses when official pipelines and Gym‑V diverge.
- Action space design and parsing reliability: mapping text outputs to environment actions is abstracted via wrappers, but parsing errors/ambiguity are not measured; report parser error rates, define constrained action schemas, and offer programmatic action spaces for safety-critical tasks.
- Real-world generalization: tasks are predominantly synthetic/procedural; test transfer to natural images, complex layouts (documents/charts/maps), and real-world GUI/web tasks to assess external validity.
- Baselines beyond VLMs: no comparisons to non-VLM agents (e.g., CNN encoders with RL, classical solvers/planners) are provided; include such baselines to calibrate difficulty and identify where vision-language priors help or hurt.
- Evaluation normalization: cross-category averages mix heterogeneous metrics (including negative shaped returns) without normalization; provide per-task normalization or z-scoring and report confidence intervals to avoid aggregation bias.
- Compute and budget reporting: training “under practical budgets” is stated but detailed budgets (steps, tokens, wall-clock, GPUs) and variance over seeds are not reported; standardize reporting for reproducibility.
- Determinism across backends: deterministic seeding is claimed, but retro engines/physics often differ across platforms; document platform dependencies, determinism tests, and CI checks across OS/hardware.
- Multi-turn stability mechanisms: findings show sequence-level stability differences (GSPO>GRPO>SAPO in some games), but no algorithmic remedies are proposed; explore sequence-level clipping, variance reduction, state-dependent baselines, and trajectory-level constraints for long horizons.
- Automatic difficulty adaptation: environments expose three preset difficulty levels; implement continuous or teacher-student difficulty adaptation and study scaling laws of performance vs difficulty.
- Dataset contamination and leakage: integrated offline/benchmark datasets may suffer from prior exposure; add contamination checks and holdout protocols, especially when wrappers surface rules/examples that could leak solution strategies.
- Safety and ethical considerations: the EaaS may call closed APIs and process user data (images/text) but privacy, access control, and audit policies are unspecified; document data handling, logging, and red-team tests for safe deployment.
- Multi-modal scope gap: the platform is described as multimodal, but audio/video/tool grounding beyond images is not empirically validated; add audio-vision tasks and cross-modal tool use to substantiate multimodality claims.
- Coverage of ARC-like abstraction: ARC is extremely challenging but only 3 ARC-style tasks are included; broaden ARC-inspired procedurally generated tasks and report standardized splits to track progress.
- Cross-model RL generality: RL experiments center on Qwen2.5‑VL‑7B; replicate with other open models (e.g., LLaVA, InternVL, Idefics) to test whether conclusions about scaffolding/algorithms generalize across architectures/training recipes.
- Deployment realism for rules: learning without rules often fails, but in the wild rules are implicit; investigate self-discovered rules via interaction (induction from trajectories), and evaluate rule extraction quality vs downstream performance.
- Long-horizon credit assignment: no explicit study of delayed rewards or hierarchical skills; test options/skills discovery, subgoal curricula, and hierarchical RL to reduce compounding errors in multi-turn vision control.
Practical Applications
Overview
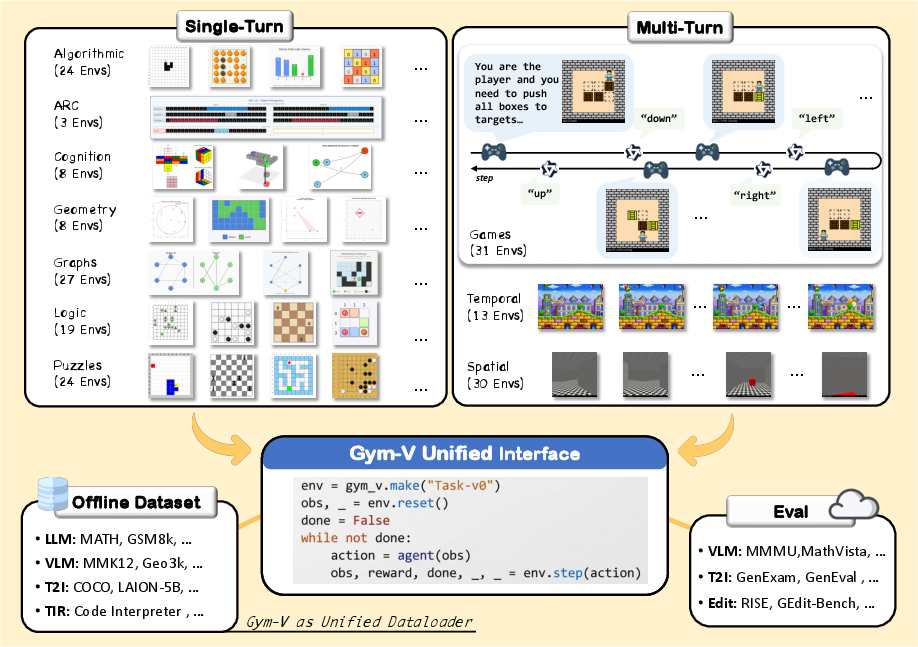
Gym‑V introduces a unified, Gym‑compatible platform for training and evaluating vision agents across 179 procedurally generated environments, with single‑turn and multi‑turn support, multi‑agent interaction, offline datasets, and an evaluation‑as‑a‑service (EaaS) reward server for generative tasks. Its key empirical findings—(1) observation scaffolding (e.g., captions and explicit rules) is more decisive than RL algorithm choice, (2) multi‑turn agents benefit significantly from interaction history, and (3) diverse curricula improve transfer while narrow training can cause negative transfer—translate into concrete practices for building, testing, and deploying vision‑centric agents.
Below are practical applications organized by deployment horizon. Each item notes relevant sectors and likely tools/products/workflows, along with assumptions/dependencies that affect feasibility.
Immediate Applications
These can be deployed with the current Gym‑V release, existing open/closed VLMs, and the included reward/evaluation infrastructure.
- Standardized training and evaluation pipelines for vision agents
- Sectors: software/AI, benchmarking, academia
- What: Use Gym‑V’s Gym/RLlib‑compatible reset/step interface and built‑in verifiers to run apples‑to‑apples benchmarks across 179 visual tasks (single‑turn, multi‑turn, multi‑agent), including unified evaluation wrappers for VLMs and image generators.
- Tools/workflows:
- Integrate Gym‑V environments into RL training loops (e.g., Ray RLlib, custom PPO/GRPO/GSPO/SAPO trainers).
- Automate CI/CD gates with standardized score thresholds and difficulty sweeps.
- Leverage the DIFFICULTY presets for regression testing and capability tiering.
- Assumptions/dependencies: GPU availability for VLMs; stable model APIs (for closed models); organizational agreement on score thresholds.
- Observation scaffolding A/B lab for production agents
- Sectors: software products, robotics, edtech
- What: Rapidly A/B test wrappers that add captions, rules, or history windows to quantify their effect on perception‑heavy and long‑horizon tasks before shipping product agents.
- Tools/workflows:
- Gym‑V wrapper subsystem to toggle captions, rules text, and history length without changing environment dynamics.
- Auto‑reporting dashboards to compare reward curves and convergence speed across scaffolding variants.
- Assumptions/dependencies: Availability of captioners or on‑device summarizers; alignment between proxy tasks and product UX.
- Curriculum composer for vision‑centric RL
- Sectors: AI R&D, education
- What: Construct training curricula that progress from easier to harder procedural instances and from broad to specialized skills, leveraging findings that diverse curricula transfer better.
- Tools/workflows:
- Programmatic difficulty schedules via Gym‑V DIFFICULTY presets.
- Cross‑domain training plans that include varied categories (e.g., Cognition + Puzzles + Algorithmic).
- Assumptions/dependencies: Compute for multi‑stage training; careful monitoring to avoid negative transfer from overly narrow phases.
- Multi‑turn agent prototyping with context windows
- Sectors: consumer apps, web/GUIs, RPA
- What: Prototype long‑horizon visual agents (e.g., GUI navigation, game‑like interfaces) and tune memory windows to improve stability and performance.
- Tools/workflows:
- Evaluate MDP vs recent‑3 vs recent‑5 history settings.
- Pair with rule prompts to stabilize learning in irreversible dynamics (e.g., Sokoban‑like workflows).
- Assumptions/dependencies: Token/latency budget for longer histories; UI telemetry to supply feedback for rules and state summaries.
- Generative image evaluation microservice (EaaS) for creative AI
- Sectors: media/advertising, generative AI startups, platform APIs
- What: Deploy Gym‑V’s Ray Serve‑based scoring service to evaluate text‑to‑image and image‑editing outputs via CLIP/HPSv3/VLM‑based reward models behind a single HTTP API.
- Tools/workflows:
- “/v1/generate” endpoint for batched GPU scoring, swap‑in/out reward backends via config.
- Integrate into model iteration loops and A/B tests; unify GenEval/RISE/GenExam scoring pipelines.
- Assumptions/dependencies: GPU capacity and cost; legal/data governance for hosting reward models; careful selection of reward models to match creative goals.
- Unified benchmark consolidation and leaderboards
- Sectors: evaluation platforms, research consortia
- What: Replace fragmented pipelines with Gym‑V wrappers (VLMEvalKit integration + EaaS for generative) to maintain internal/external leaderboards.
- Tools/workflows:
- One codepath for discriminative and generative evaluations.
- Difficulty sweeps to keep benchmarks non‑saturated.
- Assumptions/dependencies: Version pinning of reward/eval models for comparability; governance on task rotations.
- Teaching labs and coursework for vision+RL
- Sectors: education
- What: Hands‑on assignments on perception, reasoning, and multi‑turn control with adjustable difficulty, fostering reproducible experiments in courses.
- Tools/workflows:
- Starter notebooks with GRPO/GSPO/SAPO baselines.
- Labs on scaffolding ablations and transfer experiments.
- Assumptions/dependencies: Classroom GPU access; simplified configs for student use.
- Pre‑deployment QA and stress testing of vision agents
- Sectors: robotics (simulation), autonomous systems, industrial automation
- What: Use procedurally varied, verifiable tasks to probe agents’ robustness, detect difficulty cliffs, and identify failure modes before field deployment.
- Tools/workflows:
- Run difficulty cliffs and long‑horizon stress tests.
- Log multi‑agent interactions for cooperative/adversarial QA.
- Assumptions/dependencies: Task–domain gap; need to complement with domain‑specific sims.
- Multi‑agent coordination experiments
- Sectors: gaming, multi‑robot systems, operations research
- What: Evaluate cooperative/competitive strategies in vision settings via Gym‑V’s multi‑agent API without changing training code.
- Tools/workflows:
- Use per‑agent observations and verifiable team rewards.
- Assumptions/dependencies: Mapping from toy tasks to real coordination scenarios.
- Safety and compliance evaluation harness
- Sectors: policy/compliance, platform governance
- What: Incorporate safety‑oriented reward models (e.g., content filters, aesthetic/safety trade‑offs) into the EaaS to score generative outputs and detect risky behavior patterns during training.
- Tools/workflows:
- Swap reward backends for safety audits; log wrapper interventions for audit trails.
- Assumptions/dependencies: Availability/quality of safety reward models; organizational buy‑in.
Long‑Term Applications
These require additional research, scaling, domain adaptation, or governance work before broad deployment.
- Sim‑to‑real transfer for embodied and industrial robotics
- Sectors: robotics, manufacturing, logistics
- What: Pre‑train visual reasoning and planning policies with diverse curricula (emphasizing scaffolding and history), then fine‑tune in domain‑specific sims and on hardware.
- Tools/workflows:
- On‑device captioners/rule overlays to replicate “scaffolding” benefits found in Gym‑V.
- Domain randomization and visual grounding bridges.
- Assumptions/dependencies: Robust perception stacks; safe RL protocols; sim‑to‑real gap closure; regulatory and safety approvals.
- Vision‑enabled assistants in AR/VR and consumer devices
- Sectors: consumer tech, accessibility
- What: Generalist vision agents that leverage captions/rules/history to operate apps and physical‑world tasks (e.g., household organization, accessibility descriptions).
- Tools/workflows:
- Memory management and context policy learned from multi‑turn Gym‑V.
- On‑device evaluation hooks using EaaS‑like scoring variants.
- Assumptions/dependencies: Efficient on‑device models; privacy‑preserving context; robust long‑horizon stability.
- Domain‑specific RLVR in regulated sectors (healthcare, finance)
- Sectors: healthcare, finance, insurance
- What: Adapt the RL‑from‑verifiable‑rewards paradigm to vision‑centric workflows (e.g., document analysis, chart/graph reasoning, medical imaging UI support) using domain‑tailored environments and verifiers.
- Tools/workflows:
- Build healthcare/finance‑specific environments with deterministic verifiers.
- Use wrapper‑based rule/caption guidance to lower training variance.
- Assumptions/dependencies: Strong domain reward models; curated, compliant datasets; rigorous validation; regulatory oversight.
- Procurement and standards for fair agent evaluation
- Sectors: public sector, standards bodies, enterprise governance
- What: Adopt gym‑style, verifiable, difficulty‑controlled evaluations (with open configs and wrapper logs) as part of procurement and model certification.
- Tools/workflows:
- Public EaaS endpoints with fixed backends and versioned leaderboards.
- Auditable wrapper configurations and seed controls.
- Assumptions/dependencies: Multi‑stakeholder consensus; reproducibility governance; funding for hosted infrastructure.
- Tool‑augmented, multi‑agent workflow automation
- Sectors: enterprise software, RPA, web automation
- What: Orchestrate multi‑agent VLM systems that use tools (code, retrieval, GUI APIs) and visual observations, with rewards verified through structured tasks.
- Tools/workflows:
- Extend Gym‑V tool wrappers to enterprise toolchains; learn coordination and role specializations.
- Assumptions/dependencies: Reliable tool interfaces; monitoring for long‑horizon drift; security reviews.
- Open evaluation networks and cross‑org EaaS hubs
- Sectors: research consortia, cloud providers
- What: Federated EaaS for scoring VLMs and generators under shared protocols, enabling sustained, evolving benchmarks with difficulty ramping.
- Tools/workflows:
- Ray Serve‑like multi‑backend deployment; SLA‑backed endpoints; versioned reward models.
- Assumptions/dependencies: Cost sharing; privacy guarantees; alignment on reward models and anti‑gaming measures.
- Game AI and edutainment ecosystems with adaptive curricula
- Sectors: gaming, edtech, consumer apps
- What: Build consumer‑facing puzzle/logic apps where content difficulty adapts via Gym‑V presets; agents act as tutors or sparring partners.
- Tools/workflows:
- Human‑in‑the‑loop feedback to tune curricula; explainable “rule/caption” tutoring modes.
- Assumptions/dependencies: Engaging UX; safety filters for generated hints; monetization strategy.
- Robust transfer learning recipes for generalist vision agents
- Sectors: AI foundation model developers
- What: Establish training blueprints prioritizing diverse task mixes and scaffolding strategies to reduce negative Wiring‑in of narrow heuristics and improve robustness to distribution shifts.
- Tools/workflows:
- Systematic transfer matrices; automated detection of negative transfer and curriculum rebalancing.
- Assumptions/dependencies: Large‑scale compute; scalable data/telemetry pipelines; improved algorithmic stability for very long horizons.
Cross‑cutting Assumptions and Dependencies
- Domain gap: Gym‑V tasks are largely abstract or game‑like; successful transfer to real‑world requires domain‑specific environments, sensors, and reward models.
- Reward model fidelity: EaaS outcomes depend on the choice and calibration of reward backends (e.g., CLIP biases, safety filters); swapping/backtesting is essential.
- Compute and cost: Multi‑turn VLM RL is resource‑intensive; scheduling, batching, and mixed precision are needed to control costs.
- Model/API stability: Closed‑source VLM APIs may introduce latency/cost/ToS constraints; open‑weight alternatives require deployment and scaling expertise.
- Governance and reproducibility: Versioning of environments, seeds, wrappers, and reward models is necessary for fair comparison and auditability.
- Safety and ethics: Especially for regulated sectors and consumer products, additional human oversight, red‑teaming, and fail‑safes are required.
By operationalizing Gym‑V’s unified interface, wrapper‑based scaffolding, and EaaS architecture—and by applying the paper’s empirical insights about scaffolding, history, and curricula—teams can build more reliable, testable, and transferable vision agents today, while laying the groundwork for robust real‑world deployments tomorrow.
Glossary
- Agentic LLMs: LLMs designed to act autonomously in interactive settings via iterative decision-making. "Interactive gym-style training is becoming the default for agentic LLMs."
- Agentic VLMs: Vision-LLMs that operate as autonomous agents, perceiving images and taking actions. "aiming to accelerate future research on agentic VLMs."
- Automatic batching: Grouping multiple inference or scoring requests together to improve throughput and efficiency on accelerators. "automatic batching, and horizontal scaling across GPUs"
- Automatic verification: Programmatic checking of task solutions using deterministic rules to provide verifiable rewards. "procedural generation, automatic verification, and standardized interfaces."
- Batched episodes: Treating multiple episodes as a batch within the same training iteration for uniform processing. "Both settings are treated uniformly as batched episodes"
- Batched GPU inference: Running many evaluation or scoring requests simultaneously on GPUs for efficiency. "batched GPU inference"
- Composable wrapper layer: A modular middleware that can alter observation, context, rules, or evaluation without changing environment dynamics. "a composable wrapper layer controls what context the agent receives"
- Cross-domain transfer: Evaluating how training in one task/domain improves or harms performance in different, unseen domains. "Cross-domain transfer experiments further show"
- Curriculum learning: Structuring training by gradually increasing task difficulty to improve learning and generalization. "providing the scale and control for curriculum learning"
- Deterministic seeding: Fixing random seeds so that environment instances and results are exactly reproducible. "with a shared reset/step interface and deterministic seeding."
- Deterministic verification: Checking correctness with deterministic procedures so rewards are unambiguous and reproducible. "all tasks admit deterministic verification"
- Difficulty cliff: A sharp drop in performance when task complexity increases slightly. "The difficulty cliff (degradation rates)."
- Difficulty presets: Predefined, standardized levels of task complexity for consistent comparisons. "with difficulty presets and controllable distribution shifts."
- Distributed reward service: A networked, scalable service that computes rewards (often via learned models) for generative outputs. "Gym-V addresses this with a distributed reward service deployed via Ray Serve"
- Evaluation wrapper: A standardized wrapper that exposes evaluation tasks through a common interface. "Eval: evaluation wrapper"
- Evaluation-as-a-service (EaaS): Providing model evaluation through a hosted service interface rather than local pipelines. "following the evaluation-as-a-service (EaaS) paradigm."
- Generative tasks: Tasks where the agent must synthesize outputs (e.g., images) that are scored by learned evaluators. "generative tasks---such as text-to-image synthesis or image editing---require learned reward models"
- GRPO: A reinforcement learning algorithm for optimizing sequence policies in language or vision-LLMs. "Training reward curves for GRPO, GSPO, and SAPO across 12 single-turn"
- GSPO: Group Sequence Policy Optimization; an RL method emphasizing stable updates for long sequences. "Training reward curves for GRPO, GSPO, and SAPO across 12 single-turn"
- Gym-compatible API: An environment interface conforming to the OpenAI Gym reset/step paradigm for RL. "A Gym-compatible API~\citep{(Brockman et al., 2016)} runs the same loop"
- Heterogeneous reward backends: Multiple different reward models or evaluators served behind a single scoring API. "hosts heterogeneous reward backends behind a unified scoring API."
- Horizontal scaling: Increasing throughput by parallelizing computation across multiple GPUs or machines. "horizontal scaling across GPUs"
- Long-horizon: Tasks requiring many sequential decisions, where errors compound over time. "long-horizon multi-turn stability"
- MDP: Markov Decision Process; a formal framework where the next state depends only on the current state and action. "MDP (current observation only)"
- mean@3: An evaluation metric averaging performance across up to three attempts or samples. "zero-shot mean@3 scores"
- Memoryless setting: An interaction mode where the agent receives only the current observation without history. "under a memoryless setting (context window size\,=\,0, right)"
- Multi-agent: Environments involving multiple agents (cooperative or competitive) interacting simultaneously. "following the Ray RLlib multi-agent convention."
- Multi-turn interaction: Multi-step episodes where the agent observes, acts, and receives feedback across several turns. "with multi-turn interaction amplifying all of these effects."
- Negative transfer: Training on one domain harms performance on another domain. "narrow training can cause negative transfer"
- Observation scaffolding: Auxiliary guidance (e.g., captions, rules) that helps the agent interpret visual observations. "observation scaffolding is more decisive for training success"
- Off-policy gating: Mechanisms that filter or modulate learning updates when data comes from a different policy. "temperature-controlled off-policy gating"
- Policy drift: Large changes in the learned policy that can destabilize training. "under larger policy drift"
- Procedural generation: Algorithmically creating varied instances of tasks to support scalability and generalization. "procedural generation"
- Ray RLlib: A reinforcement learning library providing multi-agent and scalable RL abstractions. "aligned with the multi-agent interface of Ray RLlib"
- Ray Serve: A scalable model serving framework in the Ray ecosystem. "deployed via Ray Serve"
- Reinforcement learning from verifiable rewards (RLVR): RL where the reward signal is derived from deterministic or verifiable checks. "reinforcement learning from verifiable rewards (RLVR)"
- Reward hacking: Exploiting flaws in reward definitions to achieve high scores without truly solving the task. "reducing reward hacking and brittle overfitting."
- Robustness ratio: A measure comparing performance at high difficulty to low difficulty to assess degradation. "We quantify degradation with a robustness ratio as"
- SAPO: Soft Adaptive Policy Optimization; an RL algorithm that adapts optimization based on policy behavior. "Training reward curves for GRPO, GSPO, and SAPO across 12 single-turn"
- Sequence-level importance ratios: Importance-sampling ratios computed over entire output sequences for stable RL updates. "sequence-level importance ratios and clipping"
- Shaped episodic returns: Episode returns augmented with intermediate rewards to guide learning. "Minigrid (Sp./2D) uses shaped episodic returns"
- Tool-augmented interaction: Integrating external tools (e.g., interpreters) into the agent loop to enhance capabilities. "tool-augmented interaction"
- Transition-wise design: Structuring environments with per-step transitions and rewards for fine-grained RL signals. "adopts a transition-wise design"
- vLLM: A high-throughput inference engine for serving large language or vision-LLMs. "served via vLLM"
- VLMs: Vision-LLMs that jointly process visual and textual inputs. "Zero-shot evaluation of nine VLMs reveals"
- VLMEvalKit: A toolkit for standardized evaluation of vision-LLMs. "VLMEvalKit"
- Visual Grounding: Representing and reasoning about tasks directly from visual inputs rather than structured text. "Visual Grounding: all observations are rendered as images"
- Wrappers: Middleware modules that modify inputs/outputs and evaluation at the agent–environment boundary. "Wrappers can rewrite task rules/descriptions, augment observations (e.g., state summaries), control the context provided to the agent via configurable history windows, parse/validate agent outputs before execution"
Collections
Sign up for free to add this paper to one or more collections.