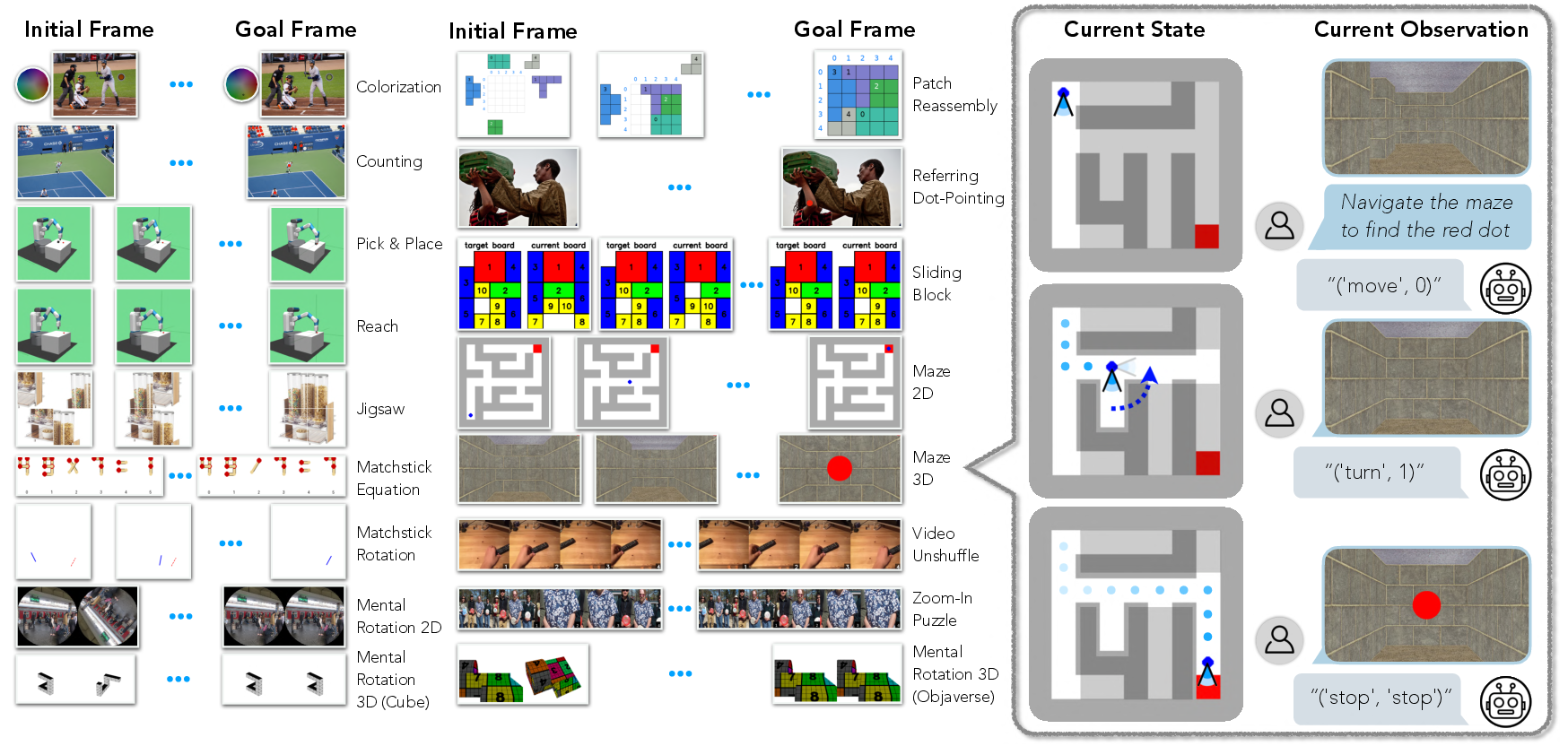
VisGym: Diverse, Customizable, Scalable Environments for Multimodal Agents
Abstract: Modern Vision-LLMs (VLMs) remain poorly characterized in multi-step visual interactions, particularly in how they integrate perception, memory, and action over long horizons. We introduce VisGym, a gymnasium of 17 environments for evaluating and training VLMs. The suite spans symbolic puzzles, real-image understanding, navigation, and manipulation, and provides flexible controls over difficulty, input representation, planning horizon, and feedback. We also provide multi-step solvers that generate structured demonstrations, enabling supervised finetuning. Our evaluations show that all frontier models struggle in interactive settings, achieving low success rates in both the easy (46.6%) and hard (26.0%) configurations. Our experiments reveal notable limitations: models struggle to effectively leverage long context, performing worse with an unbounded history than with truncated windows. Furthermore, we find that several text-based symbolic tasks become substantially harder once rendered visually. However, explicit goal observations, textual feedback, and exploratory demonstrations in partially observable or unknown-dynamics settings for supervised finetuning yield consistent gains, highlighting concrete failure modes and pathways for improving multi-step visual decision-making. Code, data, and models can be found at: https://visgym.github.io/.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
VisGym: A simple explanation
What is this paper about?
This paper introduces VisGym, a collection of 17 “game-like” environments designed to test and train AI models that can both see and read, called vision–LLMs (VLMs). These environments help researchers understand how well these models make decisions step by step using visual information, like solving puzzles, navigating mazes, or moving a robot arm.
What questions are the researchers trying to answer?
The paper asks:
- Why do current AI models struggle when they must look at images and make several decisions in a row?
- Which factors make these tasks harder or easier, across different kinds of problems (puzzles, navigation, manipulation, etc.)?
- How do things like long conversation history, the way information is shown (image vs. text), the presence of feedback, and whether the goal is visible affect performance?
- Can training with good examples (demonstrations) help? What kinds of examples help the most?
How did they do the research?
Think of VisGym as a playground with many levels, each focusing on a different skill:
- The environments include real photos and synthetic (computer-made) images.
- Some tasks let the model see everything; others hide some information to make it trickier (like being in a maze and only seeing your immediate surroundings).
- Actions are given as “function calls,” which is like telling the AI to press specific buttons with certain settings (e.g., “rotate by 30 degrees” or “swap puzzle pieces 1 and 2”).
- Each task comes with clear instructions and textual feedback (“that move hit a wall” or “invalid input”), so models can learn from mistakes.
- There’s also an “expert solver”—a program that knows how to complete each task—used to generate training examples.
They tested 12 modern VLMs in multi-step interactions (like taking several turns), measured success on easy and hard versions, and ran controlled experiments to see how specific changes (like removing feedback or shortening history) affect results. They also fine-tuned some models using solver-generated demonstrations to see how much training helps.
What did they find, and why does it matter?
Here are the main results, explained simply:
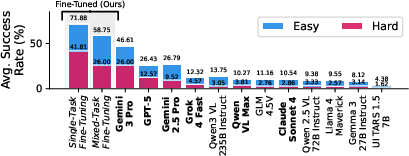
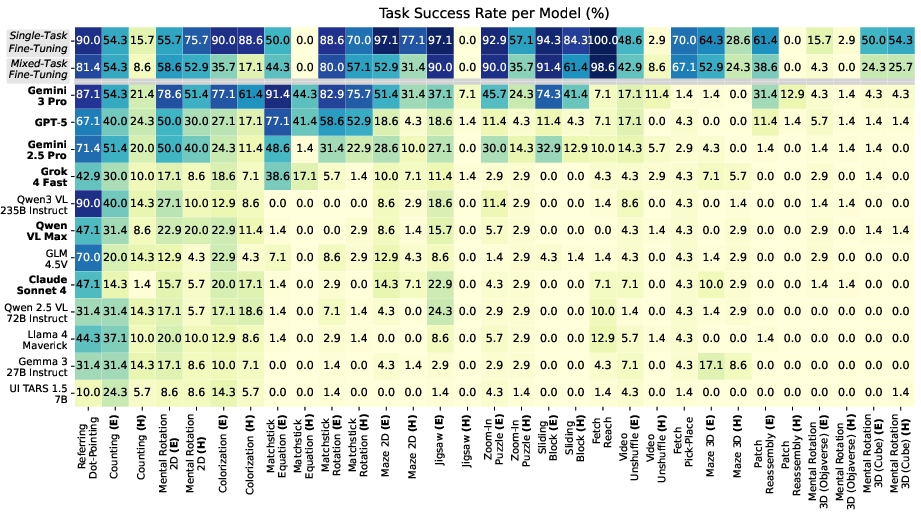
- Overall performance is low:
- Even the best model only solved about 47% of tasks on easy settings and 26% on hard ones.
- This shows these tasks are genuinely challenging for today’s AI.
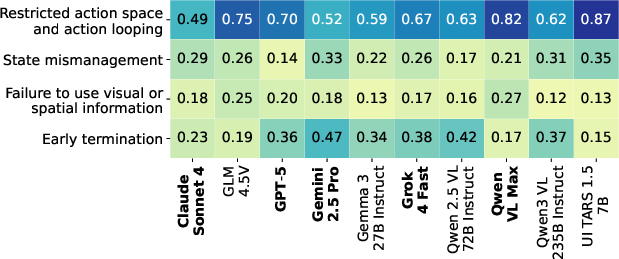
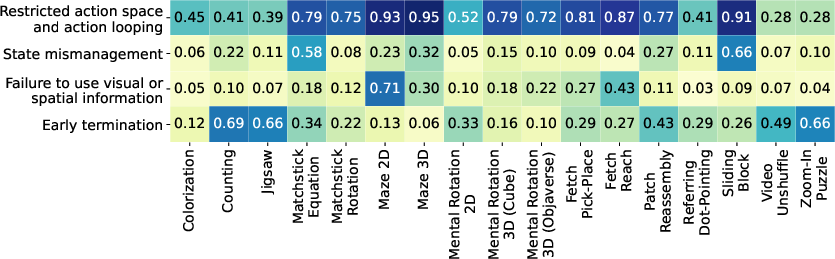
- Common failure patterns appeared across tasks:
- Models get stuck repeating the same action (like turning the same way over and over).
- They forget or mismanage state, ignoring feedback or re-trying illegal moves.
- They quit too early, even when they aren’t done.
- They often fail to use visual details properly (missing alignment, not noticing changes).
- More history isn’t always better:
- Keeping a short recent history improves decisions, but using full, long histories can hurt performance.
- In simple terms: too much old info can distract the model.
- Text representations can be easier than images:
- When tasks were shown using text diagrams (ASCII), some models did much better—suggesting that “seeing” is a major bottleneck.
- But not always: in one task, messy text shapes actually made things worse.
- Removing text feedback hurts:
- Without the text messages (like “you hit a wall”), models were much worse at figuring out what happened from visuals alone.
- This means they rely heavily on verbal hints, not just what they see.
- Showing the final goal at the start helps—except when it doesn’t:
- Giving the target picture up front usually boosts performance.
- But when models misjudge “are these images identical?”, they sometimes stop too soon and do worse than without a goal image.
- Training with good demonstrations helps a lot:
- Models fine-tuned on solver-generated examples reached state-of-the-art performance on most tasks in VisGym.
- Stronger base models (newer versions) generalize better from easy examples to harder ones.
- Both vision and language parts matter:
- Fine-tuning the LLM helps with planning and using history.
- Fine-tuning the vision encoder helps with precise perception (e.g., tiny alignments).
- Most tasks needed improvements in both, but the language/planning side is often the bigger bottleneck.
- The kind of training examples you use matters:
- “Information-revealing” demonstrations—where the model first explores in a way that exposes hidden dynamics or clarifies the 3D structure—can dramatically boost learning.
- It’s not just about more data; it’s about data that helps the model understand the situation.
What is the impact of this research?
VisGym gives researchers a powerful, flexible way to test and improve multimodal AI agents. By showing where and why current models fail—and by offering tools, controlled settings, and training demonstrations—VisGym helps guide the next steps in building better models that can:
- Reliably use visual information over multiple steps,
- Plan and act with limited visibility,
- Understand feedback and adapt,
- Generalize to harder versions of the same task.
This matters for future AI in robotics, computer use, video games, and any real-world job where an agent must look, think, and act repeatedly to reach a goal. VisGym sets a solid foundation for making these agents more capable and trustworthy.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper, framed as concrete directions future researchers can act on.
- Ecological validity of textual feedback: many environments rely on explicit text feedback for action validity; how to design agents that infer constraints purely from visual dynamics in settings where such feedback does not exist (e.g., robotics, real GUIs)?
- Reinforcement learning vs. SFT: although VisGym supports online RL, the paper only reports SFT; how do on-policy RL, offline RL, and hybrid RL+SFT compare in sample efficiency, stability, and asymptotic performance on VisGym tasks?
- Memory utilization beyond truncation: the “reverse-U” effect of history length is shown via naive truncation; can learned summarization, retrieval, external memory, or state-estimation modules mitigate long-context degradation?
- Action-space design sensitivity: actions are exposed as function calls with parameter schemas; how do different API designs (e.g., constrained JSON schemas, programmatic tools, discrete primitives, continuous control) change learning dynamics and success rates?
- Prompt and instruction sensitivity: the paper does not systematically vary task instructions or function descriptions; how sensitive are outcomes to wording, ordering, examples, and tool documentation quality?
- Generalization to unseen tasks: SFT generalization is tested across difficulty variants of the same tasks; what happens when models face entirely novel environments or domains not present during training (true out-of-distribution task generalization)?
- Solver quality and bias: demonstrations come from heuristic solvers; how does solver optimality, stochasticity, and suboptimal behavior affect SFT outcomes, exploration strategies, and the learned state representations?
- Information-revealing demonstrations at scale: the benefits are shown in two tasks; do information-revealing trajectories consistently help across all partial observability and unknown-dynamics tasks, and what systematic principles guide their design?
- Statistical rigor and sample size: results use 70 episodes per task with error bars but no formal significance testing; are observed differences robust across seeds, broader episode counts, and controlled decoding settings?
- Closed-model evaluation reproducibility: proprietary models are accessed via OpenRouter; can replication be guaranteed given unknown server-side settings (e.g., temperature, nucleus sampling), potential updates, or version drift?
- Metrics beyond success rate: evaluation is largely binary success and step counts; can richer metrics (e.g., sample efficiency, alignment error, constraint violations, calibration, recovery from mistakes) yield more diagnostic signal?
- Visual grounding bottlenecks: ASCII variants expose perception vs. planning limitations, but the representation is coarse; what intermediate textual or structured visual encodings (segmentation, keypoints, scene graphs) best bridge perception and reasoning?
- Scaling to longer horizons: tasks cap at 20–30 steps; do the observed failure modes intensify or change qualitatively for much longer horizons (e.g., 100–1000 steps), and what mechanisms stabilize long-run control?
- Partial observability realism: POMDP tasks are relatively constrained; can VisGym incorporate more realistic occlusions, distractors, dynamic lighting, motion blur, multi-view inconsistencies, and sensor noise typical in real environments?
- Multimodal breadth: environments are predominantly visual with textual feedback; how do audio, haptics, depth, language-only hints, or multi-camera streams affect agent grounding and control?
- Robotics transfer: MuJoCo Fetch tasks are simulated; can policies learned in VisGym transfer to real robots, and what sim-to-real gaps (latency, actuation noise, perception lag) need to be addressed?
- Failure analysis reliability: StringSight/GPT-4.1 annotator clusters failures automatically; what is the inter-rater reliability versus human audit, and can failure taxonomies be standardized across labs?
- Model-size and backbone scaling laws: SFT comparisons are limited to specific Qwen variants; how do backbone size, architecture (Mixture-of-Experts, retrieval-augmented), and pretraining data quantitatively affect VisGym performance and generalization?
- Safety and robustness: the paper does not examine adversarial inputs, perturbations, or deceptive feedback; how robust are agents to corrupt frames, partial instruction corruption, or adversarial UI elements?
- Tool-use and external planners: tasks emphasize direct perception-action loops; can integrating planners, program synthesis, search, or domain-specific tools measurably mitigate observed failure modes?
- Goal-observation brittleness: providing final goals sometimes backfires due to misperception; what calibrated comparison mechanisms (e.g., learned similarity, perceptual hashes, differentiable alignment loss) reduce false positives when checking goal attainment?
- History selection policies: the truncation study uses fixed window sizes; can adaptive history selection (e.g., salience scoring, constraint-relevant memories) outperform fixed policies across tasks?
- Curriculum and data composition: SFT training mixes tasks evenly; what curricula (ordering, difficulty ramps, skill decomposition) and data balancing strategies maximize cross-task transfer?
- Environment diversity and coverage: VisGym spans 17 tasks, but excludes complex GUIs, web agents, code-editing with visual contexts, or multi-agent interactions; can the suite be extended to these domains while retaining controlled diagnosis?
- Formal POMDP benchmarking: “partial” vs. “full” observability is labeled qualitatively; can tasks be instrumented with formal latent-state models and identifiability metrics to quantify state inference difficulty?
- Compute and efficiency reporting: inference time, GPU memory, and throughput are not reported; can standardized efficiency metrics be added to contextualize performance trade-offs for practical deployment?
Glossary
- Context window: The maximum number of tokens (text and image embeddings) a model can process in one interaction. "We also ensure that the length of interaction history is within models' context window."
- Environment Feedback: Textual messages emitted by the environment to describe action effects or errors. "the environment provides textual feedback describing the effect of each action (e.g.,
invalid format,"out of bounds," ``executed")." - Function Instructions: Natural-language descriptions of available environment functions and their argument constraints. "To enable zero-shot rollouts, we provide a natural-language description of these functions and their argument constraints as part of the initial prompt before the model takes its first action."
- Function-Conditioned Action Space: An action interface where actions are expressed as parameterized function calls rather than discrete vectors. "we represent actions as function calls with parameters (e.g., ('swap', (1, 2)), ('rotate', (30.5, 20.4, 15.1)))."
- Gymnasium framework: A standardized RL environment library used to build and interface with tasks. "VisGym is built on top of the Gymnasium framework \citep{2016gym, towers2024gymnasium}, the same library underlying MuJoCo \citep{todorov2012mujoco} and Atari \citep{bellemare13arcade}."
- Heuristic: A rule-of-thumb strategy that approximates solutions without guaranteeing optimality. "We implement heuristic multi-step solvers that complete each task using the available actions."
- LLM backbone: The core language-model component of a multimodal system that performs reasoning over text and history. "fine-tuning variants that modify either the vision encoder or the LLM backbone to isolate each moduleâs contribution"
- Long-horizon: Tasks requiring many sequential steps of perception and action to reach a goal. "a highly diverse, scalable, and customizable gymnasium with 17 long-horizon environments designed to isolate what limits interactive decision-making"
- MuJoCo: A physics engine commonly used for simulation in robotics and control tasks. "the same library underlying MuJoCo \citep{todorov2012mujoco} and Atari \citep{bellemare13arcade}."
- Multi-turn: An interactive evaluation setup where the agent takes multiple sequential actions with feedback. "All models are evaluated in a multi-turn manner."
- Online RL: Reinforcement learning performed during ongoing interaction, updating the policy in place. "SFT and Online RL show support for finetuning and reinforcement learning."
- Open-weight models: Models whose parameters are publicly available for local inference and fine-tuning. "open-weight models (Qwen3-VL-235B-Instruct~\citep{yang2025qwen3}, GLM-4.5V~\citep{hong2025glm}, Llama-4-Maverick~\citep{touvron2023llama}, Qwen-2.5-VL-72B-Instruct~\citep{bai2025qwen2}, Gemma~3-27B-Instruct~\citep{team2025gemma});"
- Oracle multi-step solvers: Ground-truth solution generators that can reliably solve tasks, used to produce demonstrations. "equipped with oracle multi-step solvers for supervised finetuning (framework comparison in \cref{tab:framework_comparisons})."
- Out-of-distribution generalization: The ability to perform well on task variants or inputs not seen during training. "This trend highlights that newer VLMs provide stronger out-of-distribution generalization in multi-step visual decision-making despite being finetuned on an identical setup."
- Partial observability: A setting where the agent cannot directly observe the complete environment state. "particularly in tasks with partial observability or unknown environment dynamics."
- Perceptual aliasing: Different environment states producing similar observations, causing ambiguity for the agent. "disambiguate perceptual aliasing are often far more valuable"
- Perceptual grounding: Accurately mapping visual inputs to internal representations or actions. "VLMs struggle with low-level perceptual grounding, a limitation highlighted by symbolic variants of tasks being substantially easier than their visually rendered counterparts;"
- POMDP: Partially Observable Markov Decision Process, a formal model for decision-making under hidden state. "POMDP denotes partial observability with hidden states."
- Reverse scaling: A phenomenon where performance worsens as a resource (such as context length) increases. "Sliding Block exhibits clear reverse scaling for Gemini~2.5~Pro."
- Reversed-U relationship: Performance that first improves then degrades as a variable (e.g., history length) increases. "showing a reversed-U relationship where performance degrades as the context grows unbounded;"
- Solver: A program that computes a sequence of actions to complete a task. "#1{Solver.}"
- Step function: The standard environment API method that executes one action and returns the resulting transition. "the unified step function handles parsing, validation, execution, and feedback (\cref{alg:step} in \cref{appx:interface})."
- Stochasticity: Randomness introduced into processes or policies to diversify behavior or data. "optional stochasticity, enabling the generation of diverse demonstration trajectories for supervised fine-tuning."
- Supervised fine-tuning (SFT): Training a model on labeled demonstrations to improve performance on specific tasks. "SFT and Online RL show support for finetuning and reinforcement learning."
- Temporal integration: Combining information across time to form coherent state estimates and make decisions. "fine-grained visual encoding and temporal integration are jointly necessary for interactive behavior"
- Tool-calling: Invoking external tools or functions from within the model to accomplish subtasks. "shifting the difficulty from reasoning to visual perception and tool-calling."
- Trajectory: A sequence of observations, actions, and feedback over an episode. "An example trajectory for the Maze 3D navigation task illustrates a partially observable environment consisting of non-structured synthetic renderings."
- Unknown dynamics: Environment transition rules that are not known to the agent. "Dyn.: Known vs. Unknown dynamics"
- Vision encoder: The component that converts images into feature representations used by the LLM. "fine-tuning variants that modify either the vision encoder or the LLM backbone to isolate each moduleâs contribution"
- Vision–LLMs (VLMs): Models that jointly process images and text to understand and act. "Foundation VisionâLLMs (VLMs) have made remarkable progress on static visionâlanguage benchmarks"
- Vision–Language–Action models (VLAs): Models that integrate vision, language, and action execution for embodied tasks. "vision-language-action models (VLAs) \citep{black2410pi0, bjorck2025gr00t, team2025gemini, kim2024openvla, octo_2023, huang2025otter, lbmtri2025, zhou2025vision, niu2024llarva, shi2025diversity}"
- Zero-shot rollouts: Executing tasks without task-specific training, relying solely on prior capability and instructions. "To enable zero-shot rollouts, we provide a natural-language description of these functions and their argument constraints as part of the initial prompt before the model takes its first action."
Practical Applications
Immediate Applications
The following items are deployable now, leveraging VisGym’s environments, interfaces, and empirical findings to improve real-world multimodal agents and workflows.
- VisGym-driven agent QA and benchmarking for product releases — sectors: software, robotics, gaming, education
- Use case: Add VisGym to continuous integration (CI) to run nightly regression tests on 17 tasks, track success rates, and gate model rollouts by performance thresholds.
- Tools/products/workflows: Gymnasium-compatible test harness, dashboard for per-task success, automatic failure clustering (e.g., Stringsight/VibeCheck-style annotators).
- Assumptions/dependencies: Access to models via API or local weights, stable prompts/tool APIs, acceptance that benchmark tasks approximate target domain complexity.
- Solver-generated SFT data pipelines to boost agent reliability — sectors: robotics (manipulation, navigation), GUI/RPA automation, gaming
- Use case: Generate diverse, multi-step solver trajectories (including information-revealing behaviors) to fine-tune VLM/VLA agents for long-horizon tasks.
- Tools/products/workflows: LlamaFactory training orchestration, mixed-task finetuning, curated dataset versions that expose hidden states or dynamics before solving.
- Assumptions/dependencies: Compute budget for SFT, access to base models, careful split management to avoid leakage, validation on domain-specific tasks post-SFT.
- Interaction design guidelines that measurably improve agent outcomes — sectors: software, robotics, web automation, education
- Use case: Apply empirically supported tactics: cap conversation history to ~4 turns, include explicit textual environment feedback, provide goal snapshots only when visual judgment is robust, expose function-conditioned action spaces, and show remaining step limits.
- Tools/products/workflows: Context window policies in agent runtime, environment feedback channels (e.g., “executed,” “out of bounds”), function-call schemas, goal verification checks.
- Assumptions/dependencies: Ability to instrument environments/UI to produce structured feedback; developer control over memory buffers and tool policies.
- Runtime guardrails for failure patterns — sectors: enterprise RPA, robotics, finance ops
- Use case: Detect and mitigate “action looping,” early termination, illegal-action repetition, and state mismanagement via telemetry and real-time monitors.
- Tools/products/workflows: Loop counters, invalid-action rate alarms, “visited-state” trackers, automatic intervention policies (e.g., policy reset or human handoff).
- Assumptions/dependencies: Consistent action/state logging; clear operational constraints; policy hooks to interrupt or adjust agent behavior.
- Prefer structured/semantic observation when available (representation switching) — sectors: software (desktop/web agents), robotics (sensor fusion)
- Use case: Feed agents DOM trees, accessibility trees, vector overlays, or ASCII/structured views instead of raw pixels to reduce visual-grounding errors.
- Tools/products/workflows: DOM-to-DSL adapters, UI accessibility APIs, ASCII/diagrammatic renderers; agent prompts that reference structured state fields.
- Assumptions/dependencies: Access to structured representations; mapping fidelity between structure and scene; privacy/security compliance for UI introspection.
- “Goal snapshot” feature in agent products (with verification) — sectors: creative tools, gaming, GUI automation
- Use case: Let users upload a target image/state to guide alignment tasks (colorization, jigsaw-like assembly), and add post-action checks to avoid misjudged “done” states.
- Tools/products/workflows: Goal image provisioning, similarity metrics (perceptual/structural), double-confirm prompts before termination, rollback on misalignment.
- Assumptions/dependencies: Robustness of perception on target domain; clear stopping criteria; user acceptance of verification steps.
- Memory-window policies for long-context stability — sectors: software agents, robotics, web automation
- Use case: Implement a memory scheduler that retains only current + a limited set of previous turns (~4) and prunes stale observations to avoid reverse-scaling failures.
- Tools/products/workflows: Ring buffers, episodic summarization, step-scoped retrieval; A/B telemetry to tune window length per task.
- Assumptions/dependencies: Model context behavior; visibility into task dynamics to not drop critical state; developer control of memory policy.
- Task-driven module finetuning decisions — sectors: MLOps, model providers
- Use case: For partial observability/unknown dynamics, prioritize LLM-side finetuning; for fine-grained perception tasks (e.g., Zoom-In), emphasize vision encoder finetuning.
- Tools/products/workflows: Modular training pipelines; per-task ablations to measure vision vs. LLM gain; model cards reflecting module-specific strengths.
- Assumptions/dependencies: Availability of modular architectures; reliable offline evaluation; careful separation of training and validation tasks.
- University coursework and training labs — sectors: academia
- Use case: Use VisGym tasks to teach perception–action loops, state inference under partial observability, tool-calling, and data curation for multi-step agents.
- Tools/products/workflows: Assignments on solver design, ablations (history, feedback), failure-mode diagnosis exercises; shared grading rubrics.
- Assumptions/dependencies: Course integration, compute access for SFT exercises, alignment with curriculum outcomes.
Long-Term Applications
The following items require further research, scaling, or development to reach robust, regulated, or large-scale deployment.
- Generalist multimodal agent curricula and training programs — sectors: cross-industry (software, robotics, gaming)
- Use case: Build end-to-end curricula using scalable episodes and online RL on top of function-conditioned action spaces to train adaptable visual decision-makers.
- Tools/products/workflows: Curriculum generators, strategy diversity via solver variants, online RL pipelines integrated with VisGym-like interfaces.
- Assumptions/dependencies: Stable sim-to-real transfer; robust reward shaping; ongoing model and toolchain improvements.
- Industrial robotics training with information-revealing teleoperation — sectors: manufacturing, logistics, warehousing
- Use case: Systematically collect human demonstrations that reveal hidden states/dynamics (e.g., deliberate small rotations/moves), then fine-tune agents for reliable manipulation/navigation.
- Tools/products/workflows: Teleop capture systems, curation policies for “state-disambiguating” trajectories, hybrid SFT + RL.
- Assumptions/dependencies: Hardware availability; high-quality sensing; safety protocols; domain gap mitigation.
- Memory and state-management architectures addressing reverse scaling — sectors: foundational model R&D, software agents, robotics
- Use case: Design agent memory modules (recurrent state, external memory, learned summarization) that keep salient state while preventing long-context degradation.
- Tools/products/workflows: Memory-augmented architectures; task-specific retention policies; benchmarks for context-length stress tests.
- Assumptions/dependencies: Research breakthroughs; integration with large context models; rigorous evaluation standards.
- Perception-grounding upgrades and hybrid observation pipelines — sectors: model providers, robotics, AR/VR
- Use case: Develop stronger visual encoders and multi-view fusion to reduce misidentification of goals and strengthen fine-grained spatial alignment.
- Tools/products/workflows: Multi-view datasets; encoders trained with task-aligned losses; hybrid pixel+structure observation channels by default.
- Assumptions/dependencies: Large-scale training data; robust labeling; computational budgets; domain-specific generalization.
- Sector-level certification and procurement standards for visually interactive agents — sectors: policy/regulation, public sector, enterprise procurement
- Use case: Create standardized evaluations (e.g., minimum VisGym-like pass rates, failure-mode profiles) for purchasing or deploying multimodal agents in critical workflows.
- Tools/products/workflows: Certification bodies, public scorecards, reproducible benchmark suites, scenario libraries with partial observability and unknown dynamics.
- Assumptions/dependencies: Stakeholder consensus; legal frameworks; reproducibility and transparency across providers.
- Adaptive feedback design frameworks for complex UIs and instruments — sectors: software platforms, scientific instrumentation, robotics
- Use case: Redesign environments to expose machine-readable textual feedback about action outcomes (constraints violated, success states), improving agent grounding.
- Tools/products/workflows: Instrument APIs with explicit status/error channels; UI-level event schemas; developer tooling for agent-readable feedback.
- Assumptions/dependencies: Willingness to modify product UIs/APIs; backward compatibility; privacy/security considerations.
- Healthcare interactive vision agents (simulation-first) — sectors: healthcare, medical imaging, lab automation
- Use case: Prototype agents that operate imaging/lab devices in sim, relying on rich feedback channels and structured observations before graduating to limited real-world trials.
- Tools/products/workflows: Medical device simulators; task variants mirroring clinical workflows; strict monitoring of failure modes and early termination.
- Assumptions/dependencies: Regulatory approvals; clinical validation; privacy compliance; robust perception in high-stakes environments.
- Education platforms for visual problem-solving and metacognition — sectors: education
- Use case: Build K–12 and higher-ed modules that teach multi-step planning, spatial reasoning, and perception via VisGym-like tasks, with explainable solvers and agent critiques.
- Tools/products/workflows: Interactive curricula, student dashboards, pedagogical solvers demonstrating “why” and “how” actions succeed.
- Assumptions/dependencies: Curriculum alignment; accessibility; teacher training; institutional adoption.
- Compute and energy optimization via context-length policies — sectors: cloud providers, enterprise AI ops
- Use case: Reduce token usage and inference cost by enforcing short memory windows and state summarization while maintaining success rates.
- Tools/products/workflows: Context schedulers, adaptive truncation, cost/performance telemetry; policy tuning per task.
- Assumptions/dependencies: Accurate measurement of cost–quality trade-offs; stable model behavior under truncation.
- Enterprise-scale RPA agents with structured observations and guardrails — sectors: finance, insurance, back-office operations
- Use case: Deploy GUI agents with DOM-based perception, robust feedback channels, and guardrails against looping and illegal actions to improve reliability at scale.
- Tools/products/workflows: Secure UI access, policy engines for early termination prevention, automated error-recovery routines, audit logs for compliance.
- Assumptions/dependencies: IT/security approval for UI introspection; compliance with data governance; integration with legacy systems.
Collections
Sign up for free to add this paper to one or more collections.