V-JEPA 2.1: Unlocking Dense Features in Video Self-Supervised Learning
Abstract: We present V-JEPA 2.1, a family of self-supervised models that learn dense, high-quality visual representations for both images and videos while retaining strong global scene understanding. The approach combines four key components. First, a dense predictive loss uses a masking-based objective in which both visible and masked tokens contribute to the training signal, encouraging explicit spatial and temporal grounding. Second, deep self-supervision applies the self-supervised objective hierarchically across multiple intermediate encoder layers to improve representation quality. Third, multi-modal tokenizers enable unified training across images and videos. Finally, the model benefits from effective scaling in both model capacity and training data. Together, these design choices produce representations that are spatially structured, semantically coherent, and temporally consistent. Empirically, V-JEPA 2.1 achieves state-of-the-art performance on several challenging benchmarks, including 7.71 mAP on Ego4D for short-term object-interaction anticipation and 40.8 Recall@5 on EPIC-KITCHENS for high-level action anticipation, as well as a 20-point improvement in real-robot grasping success rate over V-JEPA-2 AC. The model also demonstrates strong performance in robotic navigation (5.687 ATE on TartanDrive), depth estimation (0.307 RMSE on NYUv2 with a linear probe), and global recognition (77.7 on Something-Something-V2). These results show that V-JEPA 2.1 significantly advances the state of the art in dense visual understanding and world modeling.



































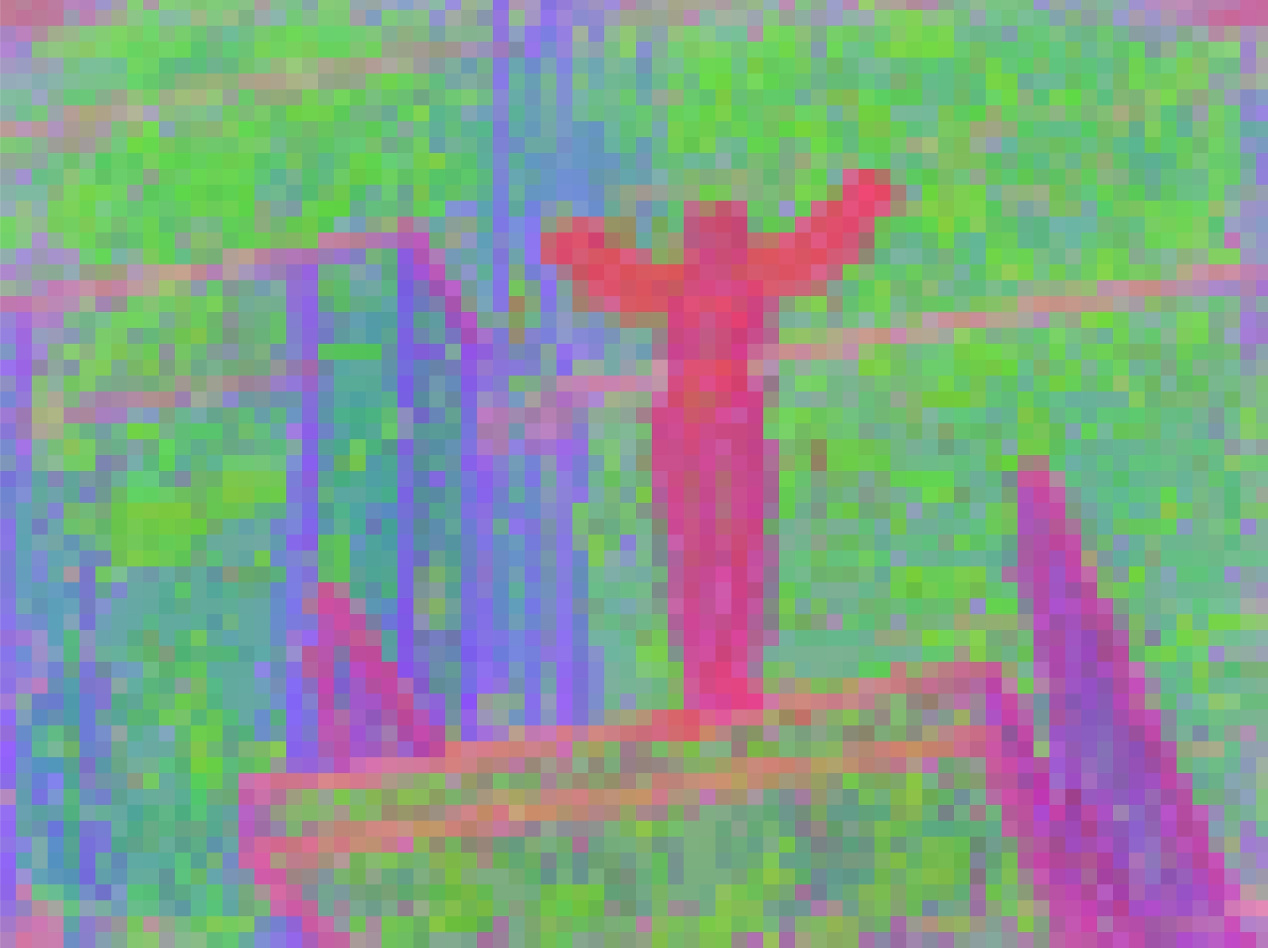













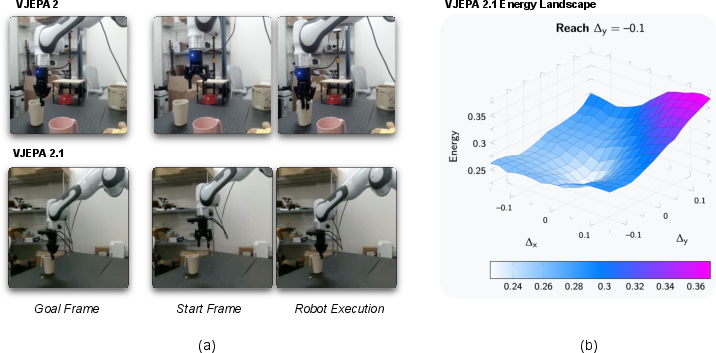




























































































Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
V-JEPA 2.1: A simple guide for teens
What is this paper about?
This paper introduces V-JEPA 2.1, a computer vision model that learns from images and videos without needing labels. Its big goal is to understand both the big picture (what’s happening in a scene) and the fine details (where things are and how they move over time). The authors show how to train the model so it gets really good at both.
What questions does the paper try to answer?
The researchers set out to answer a few key questions:
- How can a model learn detailed, per-pixel information (like object boundaries and depth) and still understand overall actions and events in videos?
- Can we train one model on both images and videos in a smart way?
- What changes to the training process make the model better at “dense” (detailed) understanding without hurting “global” (big-picture) understanding?
- Does making the model and dataset bigger keep improving results?
- Can a large model teach smaller models to be almost as good?
How does it work? (In everyday terms)
To make this easier, think of a video as a flipbook made of many small tiles (patches). The model looks at these tiles and tries to understand what each tile shows and how the tiles change over time.
Here are the four main ideas they use:
1) Dense Predictive Loss: learn from everything, not just the missing parts
- Imagine covering some tiles in a picture and asking the model to guess what’s under them. Earlier methods only graded the model on how well it guessed the hidden tiles.
- The new idea: grade the model on all tiles—both the hidden ones and the visible ones. This pushes the model to pay attention to the exact location and details everywhere, not just to “summarize” the scene.
- To avoid the model taking shortcuts (like copying visible tiles), the loss on visible tiles is carefully weighted so nearby patches matter more, encouraging smooth, local detail.
2) Deep Self-Supervision: give helpful feedback at many layers
- A model is built from many layers. If you only teach the final layer, earlier layers might not learn good details.
- The new approach adds training signals at several layers inside the model, like giving feedback to students at every step, not just at the final exam. This improves both fine details and overall understanding.
3) Multi-Modal Tokenizers: treat images and videos the way they naturally are
- Older setups treated images as short “fake” videos, which is wasteful and confusing.
- This work uses a 2D “patchifier” for images and a 3D “patchifier” for videos, so each kind of input is handled properly. It also adds a small “modality token” to tell the model whether it’s looking at an image or a video.
4) Scale up smartly: more data, bigger models, and higher resolution
- The team mixes a large, curated set of 142 million images with a huge, diverse set of videos to cover both appearance (what things look like) and motion (how things move). They call this mix VisionMix-163M.
- They scale the model up to 2 billion parameters (a very large model) and finish training with a “cool-down” phase at higher resolution and longer videos, which boosts accuracy.
- They also “distill” the giant model into smaller versions that run faster but keep much of the skill.
What did they find? Why is it important?
The paper reports strong results across many different tasks without fine-tuning the base model (they just add simple heads on top):
- Detailed (dense) understanding:
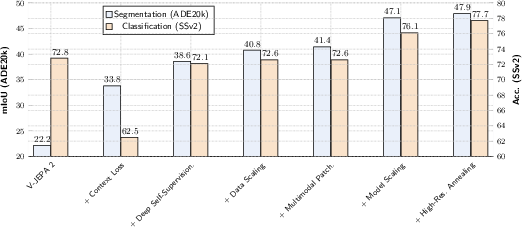
- Depth estimation from a single image (how far things are): best-in-class with a low error (RMSE 0.307 on NYUv2).
- Semantic segmentation (labeling every pixel): strong results (47.9% mIoU on ADE20K with linear probes).
- Video object segmentation: temporally consistent features (72.7 J&F on YouTube-VOS), meaning the model keeps track of objects over time.
- Predicting the future:
- Short-term object-interaction anticipation (Ego4D): state-of-the-art 7.71 mAP. It can predict what object a person will interact with, where it will be, the action type (verb), and how soon it will happen.
- High-level action anticipation (EPIC-KITCHENS): 40.8 Recall@5, predicting upcoming actions from context.
- Real-world robotics:
- Grasping with a real robot arm (Franka): 20% higher success than a previous V-JEPA version, zero-shot in new environments.
- Navigation (Tartan Drive): state-of-the-art accuracy (ATE 5.687) with 10× faster planning than a prior method.
- Global understanding:
- Video action recognition (Something-Something-V2): 77.7% accuracy.
- Image classification (ImageNet): 85.5% accuracy.
Why this matters:
- “Dense” features that are stable over space and time are crucial for tasks like mapping, tracking, depth, and robotics.
- “Global” features are crucial for recognizing actions, objects, and events.
- V-JEPA 2.1 shows you don’t have to choose—you can have both in one model.
What could this lead to?
- Better world models for robots: The model’s detailed and consistent understanding helps robots see, plan, and act more reliably in the real world.
- Smarter video tools: Improved understanding of motion and scene structure could help with video editing, surveillance, sports analysis, and AR/VR.
- More efficient learning: Since the model learns without labels (self-supervised), it can use the huge amount of unlabeled video on the internet to keep improving.
- Practical deployment: Distilling the big model into smaller ones balances accuracy with speed and memory, making the tech more usable in real devices.
In short
V-JEPA 2.1 is a big step toward teaching computers to understand both the fine details and the big picture in images and videos, using a training recipe that:
- learns from all parts of the input,
- gets feedback at many depths,
- respects the differences between images and videos,
- and scales up with more data and bigger models.
This combination sets new performance levels in many benchmarks, especially those that need detailed, time-consistent understanding—exactly what you need for real-world applications like robotics and advanced video understanding.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future work:
- Theoretical understanding: No formal analysis explains why supervising visible (context) tokens improves dense features without collapsing into trivial “copying”; a theory of locality, invariance, and collapse-avoidance for dense JEPA losses is missing.
- Context-loss design: The distance-weighted context loss uses hand-tuned λ and a warm-up schedule; sensitivity to λ, schedules, and per-layer weighting is not systematically studied across datasets and architectures.
- Masking strategy dependencies: The approach inherits the masking strategy from V-JEPA 2; effects of mask ratio, shape (e.g., tubes vs. random), and spatio-temporal distribution on dense/global trade-offs and on the distance-based weighting remain unablated.
- Deep self-supervision choices: The selection of which intermediate layers to supervise, the number of levels, fusion strategy, and their contribution to gains lack principled justification; impact on gradient flow, optimization stability, and compute overhead is not quantified.
- Predictor capacity: The depth/width of the predictor and its effect on encoder learning (e.g., predictor overfitting vs. encoder under-training) are not explored; no ablation on predictor architecture or regularization.
- Loss function alternatives: Only L1 in latent space is used; no comparison to cosine/Huber/perceptual losses or to redundancy-reduction/contrastive regularizers that might balance dense and global learning.
- Positional encoding choices: 3D RoPE is adopted without ablation; sensitivity to alternative positional embeddings, absolute/relative hybrids, and variable-resolution generalization is unknown.
- Multi-modal tokenizer design: Kernel sizes/strides, parameter sharing, and positional encodings for image vs. video patchifiers are not ablated; potential negative transfer or modality bias from the modality token is unexamined.
- Modality expansion: The framework is “multi-modal” only for images/videos; how to extend to audio, text, depth/LiDAR, or language grounding within the same JEPA framework is open.
- Fusion strategy in downstream tasks: In STA, image and video features are fused by simple summation; learned fusion, cross-attention, or gating modules—and pretraining objectives that explicitly align modalities—are not evaluated.
- Scaling and efficiency: Training/inference compute, memory footprint, and energy costs for ViT-G (2B) with high-resolution/long clips are not reported; no study of throughput/latency for real-time robotics, or efficiency techniques (sparsity, windowing, token selection).
- Long-horizon temporal modeling: Pretraining and cooldown reach 64 frames; behavior on much longer sequences, memory mechanisms, and hierarchical temporal modeling for minutes-long contexts remains unexplored.
- Evaluation breadth on dense tasks: Results rely largely on linear/attentive probes; finetuned performance on standard detection/segmentation benchmarks (e.g., COCO instance/semantic, LVIS), optical flow, pose estimation, tracking, and correspondence is not reported.
- Robustness and OOD generalization: No tests under common corruptions, motion blur, camera shake, occlusion, extreme lighting, or domain shifts; robustness diagnostics and calibration are missing.
- Data curation and bias: VisionMix-163M composition and sampling weights are heuristic; dataset bias, geographic/demographic skew, and potential overlaps/near-duplicates with evaluation sets (e.g., ImageNet, ADE20K) are not analyzed.
- Reproducibility and variance: Results are reported without seed variability, confidence intervals, or stability measures; sensitivity to hyperparameters and data mixture ratios is unknown.
- Distillation outcomes: The distillation protocol is described but dense/global performance, latency, and memory for ViT-B/L students—especially on dense tasks—are not comprehensively reported; compression trade-offs (vs. pruning/quantization) remain open.
- Mask–context geometry: The proposed distance-based weighting depends on nearest masked token; how it behaves with sparse masks, structured masks, or different temporal strides—and its effect on very local vs. mid-range dependencies—is unstudied.
- Representation diagnostics: Beyond PCA visuals and a few benchmarks, there is no quantitative measure of spatial locality, temporal consistency (e.g., token matching across frames), equivariance, or part/instance correspondence quality.
- Integration in control loops: Robotics gains are reported, but the interface between representations and planners/controllers, failure modes, sim-to-real transfer, safety, and on-device constraints (latency/power) are not systematically evaluated.
- Negative transfer trade-offs: Context supervision initially harms global tasks and is mitigated by deep supervision; whether such trade-offs persist on other global tasks (e.g., Kinetics-700, long-term recognition, VQA) and how to automatically balance them remains unclear.
- Curriculum/auto-tuning: No exploration of curriculum learning or adaptive weighting (e.g., uncertainty-based, gradient-conflict-aware) to balance masked and context supervision dynamically during training.
- Backbones beyond ViTs: Generality to non-ViT architectures (ConvNets, Mamba/state-space, hybrid models) is untested; architectural biases for dense vs. global understanding are not compared.
- Ethical/privacy considerations: Large-scale web data use lacks details on privacy filtering, content moderation, and auditing for harmful or sensitive content; implications for deployment are not addressed.
Practical Applications
Immediate Applications
Below are deployable use cases that can be built now by leveraging the released code, pretrained weights, and the paper’s frozen-backbone evaluation results.
- Robotic grasping and manipulation — Sectors: robotics, manufacturing, logistics, retail | What: Use V-JEPA 2.1 as a perception backbone to improve grasp success (+20% over V-JEPA-2 AC) and enable zero-shot deployment on new objects/environments. | Tools/workflows: Integrate frozen V-JEPA 2.1 features into existing actor-critic or diffusion policy stacks; ROS nodes for perception; depth/segmentation heads via linear/attentive probes; inference on workstation GPUs or Jetson-class devices via distilled ViT-L/B. | Dependencies/assumptions: Calibrated RGB cameras; real-time inference budget; safe robot control stack; domain shift handling for non-industrial scenes.
- Robotic navigation and local planning — Sectors: robotics, autonomous systems, warehousing | What: Use dense, temporally consistent features and stronger depth cues for localization/trajectory planning, with reported 10× faster planning and SOTA ATE on Tartan Drive. | Tools/workflows: Plug features into SLAM/VIO stacks; monocular depth heads for obstacle distance; trajectory scoring with predictive features; C++/CUDA inference, TensorRT/ONNX for deployment. | Dependencies/assumptions: Synchronized camera streams; motion model integration; latency limits for closed-loop control; careful validation in safety-critical settings.
- Monocular depth estimation and 3D understanding — Sectors: AR/VR, mapping, inspection (energy/industrial), drones | What: Linear-probe depth (0.307 RMSE NYUv2) for occlusion handling, scene understanding, and light-weight 3D reconstruction from video. | Tools/workflows: Add depth heads over frozen encoder; fuse with visual-inertial estimates; export depth to AR engines (Unity/Unreal) for occlusion and physics proxies. | Dependencies/assumptions: Camera intrinsics/extrinsics known or estimated; domain adaptation for outdoor/low-light; accuracy vs speed trade-offs.
- Video object segmentation and tracking — Sectors: media production, sports analytics, retail analytics, security | What: Use temporally consistent dense features for robust, drift-resistant segmentation/rotoscoping and tracking across frames. | Tools/workflows: Lightweight segmentation heads; integration in video editing suites for automatic, consistency-aware masks; online multi-object trackers using JEPA features. | Dependencies/assumptions: Proper resizing/cropping alignment with the tokenizer; long-clip memory handling; privacy compliance for surveillance/de-identification.
- Action recognition and video understanding — Sectors: safety/compliance, sports tech, retail, content moderation | What: High-accuracy action classification (e.g., 77.7% on SSv2) with frozen backbone and attentive probe for downstream analytics and moderation. | Tools/workflows: Deploy attentive probes for classification; combine with event detection pipelines to trigger alerts or analytics dashboards. | Dependencies/assumptions: Acceptable false-positive/negative trade-offs; balanced datasets for target domain; robust handling of occlusion and crowded scenes.
- Short-term action and object-interaction anticipation — Sectors: human-robot collaboration (HRC), industrial safety, assistive tech | What: Predict next-active object, verb, and time-to-contact (SOTA mAP on Ego4D STA) for proactive assistance or risk alerts. | Tools/workflows: Anticipation probe using predictor outputs; bounding-box and noun/verb heads; on-device warnings (e.g., AR overlays) or robot pre-grasp pose preparation. | Dependencies/assumptions: Clear viewpoint on hands/objects; latency budget <300–500 ms for utility; safe human-in-the-loop protocols.
- Labeling acceleration and pseudo-labeling for dense tasks — Sectors: data annotation services, ML operations, academia | What: Use frozen features with linear heads to pre-annotate segmentation/depth, reducing labeling cost and improving active learning loops. | Tools/workflows: Batch inference over unlabeled pools; confidence filtering; human-in-the-loop correction; DVCs (data version control) for iteration tracking. | Dependencies/assumptions: QA pipelines for label quality; domain adaptation or subset fine-tuning; clear IP/legal review for large-scale mining.
- Content indexing and retrieval for large video libraries — Sectors: media, security, enterprise knowledge management | What: Index video by actions, objects, and scenes using dense + global features; improve search and compliance audits. | Tools/workflows: Embedding extraction + FAISS/ScaNN; action/head detectors; time-localized retrieval via anticipation heads. | Dependencies/assumptions: Storage and privacy controls; customizable ontologies; thresholding for enterprise precision/recall targets.
- AR/VR occlusion, scene understanding, and interaction cues — Sectors: AR/VR, gaming, training simulators | What: Reliable depth and segmentation for occlusion; anticipate next interactions for guidance or UI adaptations in immersive experiences. | Tools/workflows: Integrate with XR SDKs; streaming inference on headset or edge server; temporal smoothing for stable overlays. | Dependencies/assumptions: On-device compute (use distilled models); thermal constraints; user consent for video processing.
- Surgical/clinical video perception (research use) — Sectors: healthcare (research), medical device R&D | What: Tool tracking, step recognition, and short-term anticipation from endoscopic/bodycam video; support quality assurance and workflow analytics. | Tools/workflows: Frozen backbone + task-specific heads; weakly supervised training with limited annotations; on-prem inference for privacy. | Dependencies/assumptions: Strict regulatory and privacy requirements; dataset shift across procedures/hospitals; validation under clinical governance.
- Sports analytics and coaching — Sectors: sports tech, broadcasting | What: Player/object tracking, action recognition, and anticipation for highlights or tactical insights. | Tools/workflows: Broadcast integration; model distillation for edge capture kits; near real-time analytics overlays. | Dependencies/assumptions: Multi-camera synchronization; handling motion blur/occlusions; licensing/rights management.
- Distilled edge deployment — Sectors: embedded systems, drones, mobile | What: Deploy ViT-L/B distilled variants as general-purpose video perception backbones on constrained devices. | Tools/workflows: Quantization-aware export; TensorRT/NNAPI; asynchronous capture/inference pipelines. | Dependencies/assumptions: Throughput vs accuracy trade-offs; memory budgets; battery/thermal ceilings.
- Academic baselines and curriculum — Sectors: academia, education | What: Use V-JEPA 2.1 as a strong frozen baseline for dense and global tasks; teach self-supervised video learning and world-modeling concepts. | Tools/workflows: Reproducible scripts; ablation-friendly recipes (context loss, deep self-supervision); dataset curation methods (VisionMix-163M). | Dependencies/assumptions: Compute access for fine-tuning/ablation; licensing adherence for data subsets.
Long-Term Applications
The following applications are promising but will likely require further research, scaling, integration, or validation before wide deployment.
- General-purpose world models for embodied AI — Sectors: robotics, autonomous vehicles, smart infrastructure | What: Unified perception-prediction backbones that support planning across manipulation, locomotion, and navigation with minimal task-specific tuning. | Tools/workflows: Closed-loop planners conditioned on JEPA features; differentiable simulation; safety monitors and uncertainty estimation. | Dependencies/assumptions: Robustness under long horizons; cross-sensor fusion (LiDAR, tactile); certification for safety-critical use.
- Proactive hazard and accident prevention via anticipation — Sectors: industrial safety, mobility, construction | What: Anticipate risky actions (slips, collisions) seconds ahead to trigger interventions or warnings. | Tools/workflows: Multi-stream video ingestion; anomaly and anticipation fusion; operator feedback loops. | Dependencies/assumptions: Very low false positives; clear operational policies; worker privacy and acceptance.
- Household generalist robots with predictive assistance — Sectors: consumer robotics, eldercare, accessibility | What: Anticipate user intentions (handovers, next-object use) to assist; robust dense perception for cluttered, changing homes. | Tools/workflows: Continual self-supervised updates; multi-camera rigs; voice/multimodal instruction grounding. | Dependencies/assumptions: Strong generalization across homes; safety and trust; affordable hardware.
- Multimodal integration with LLMs for grounded planning — Sectors: software, robotics, education | What: Combine V-JEPA 2.1 video features with LLM reasoning for instruction-following and chain-of-thought planning grounded in the physical scene. | Tools/workflows: VLM architectures with JEPA backbones; temporal grounding and memory modules; tool-use affordance prediction. | Dependencies/assumptions: Stable alignment between representations; reasoning reliability; compute efficiency.
- Privacy-preserving on-device self-supervised learning — Sectors: mobile, IoT, healthcare | What: Continuous adaptation to user environments without labels or raw data leaving device. | Tools/workflows: Federated/distillation loops; energy-aware training; lightweight predictors and context losses on-device. | Dependencies/assumptions: Secure enclaves; catastrophic forgetting safeguards; regulatory compliance.
- City-scale video understanding for traffic and infrastructure management — Sectors: smart cities, transportation, energy | What: Dense and global features for understanding flows, near-misses, and maintenance needs (e.g., detecting pole tilt, surface wear) at scale. | Tools/workflows: Edge-camera inference with centralized indexing; anticipation for proactive signal control; integration with GIS/digital twins. | Dependencies/assumptions: Data governance and public consent; bias and fairness auditability; robust performance across weather/lighting.
- High-fidelity 4D scene reconstruction and digital twins from monocular video — Sectors: AEC (architecture/engineering/construction), industrial inspection, entertainment | What: Use dense features + depth to produce temporally consistent 4D reconstructions for simulation, monitoring, and effects. | Tools/workflows: Mesh/NeRF pipelines seeded by JEPA features; loop-closure and temporal consistency constraints. | Dependencies/assumptions: Long-range consistency and scale recovery; compute/storage requirements; calibration quality.
- Standardization and policy frameworks for predictive video AI — Sectors: public policy, enterprise governance | What: Define benchmarks and auditing tools for anticipation tasks (e.g., error costs, fairness, explainability). | Tools/workflows: Shared evaluation suites; incident-reporting templates; documentation for training data curation. | Dependencies/assumptions: Cross-stakeholder consensus; transparency about internet-scale pretraining data; evolving regulations.
- Autonomous driving perception augmentation — Sectors: automotive | What: Use dense video representations and short-term anticipation to augment existing sensor stacks for cut-in prediction, vulnerable road user detection, and occlusion reasoning. | Tools/workflows: Fusion with radar/LiDAR; uncertainty-aware predictors; domain-adapted training on driving datasets. | Dependencies/assumptions: ISO 26262 and similar safety certifications; rigorous real-world validation; low-latency integration.
- Self-supervised perception for low-resource domains — Sectors: agriculture, wildlife conservation, emerging markets | What: Reduce dependence on labeled data for niche tasks (crop monitoring, species tracking) by adapting JEPA features with minimal supervision. | Tools/workflows: Few-shot heads; domain-tailored augmentations; semi-automatic labeling pipelines. | Dependencies/assumptions: Handling of extreme shifts (spectral bands, aerial views); community data governance.
Notes on Enablers and Constraints
- Tooling and availability: Code and pretrained models are released by the authors; distilled variants (ViT-L/B) ease deployment on constrained hardware.
- Data and bias: VisionMix-163M blends curated images and internet-scale video; applications must assess licensing, representativeness, and bias.
- Compute and latency: The 2B-parameter ViT-G is compute-heavy; consider distillation, quantization, and hardware acceleration.
- Safety and ethics: Anticipation-driven systems must include human oversight, robust calibration, and clear accountability in high-stakes settings.
Glossary
- Absolute Trajectory Error (ATE): A metric for quantifying localization accuracy by measuring the difference between estimated and ground-truth trajectories. "5.687 ATE on Tartan Drive"
- Action anticipation: Predicting future actions from partial video context before they occur. "40.8 Recall@5 on EPIC-KITCHENS for high-level action anticipation"
- Attentive probe: A lightweight attention-based head trained on top of frozen features to evaluate representations on downstream tasks. "we use an attentive probe trained on top of the frozen V-JEPA 2.1 encoder and predictor"
- Average Precision (AP): An evaluation metric summarizing precision–recall trade-offs across confidence thresholds. "we report different Top-5 Average Precision (AP) and mean Average Precision (mAP) metrics"
- Cool-down phase: A late training phase with decayed learning rate and increased input resolution to refine representations. "we explore the effect of applying a cool-down phase"
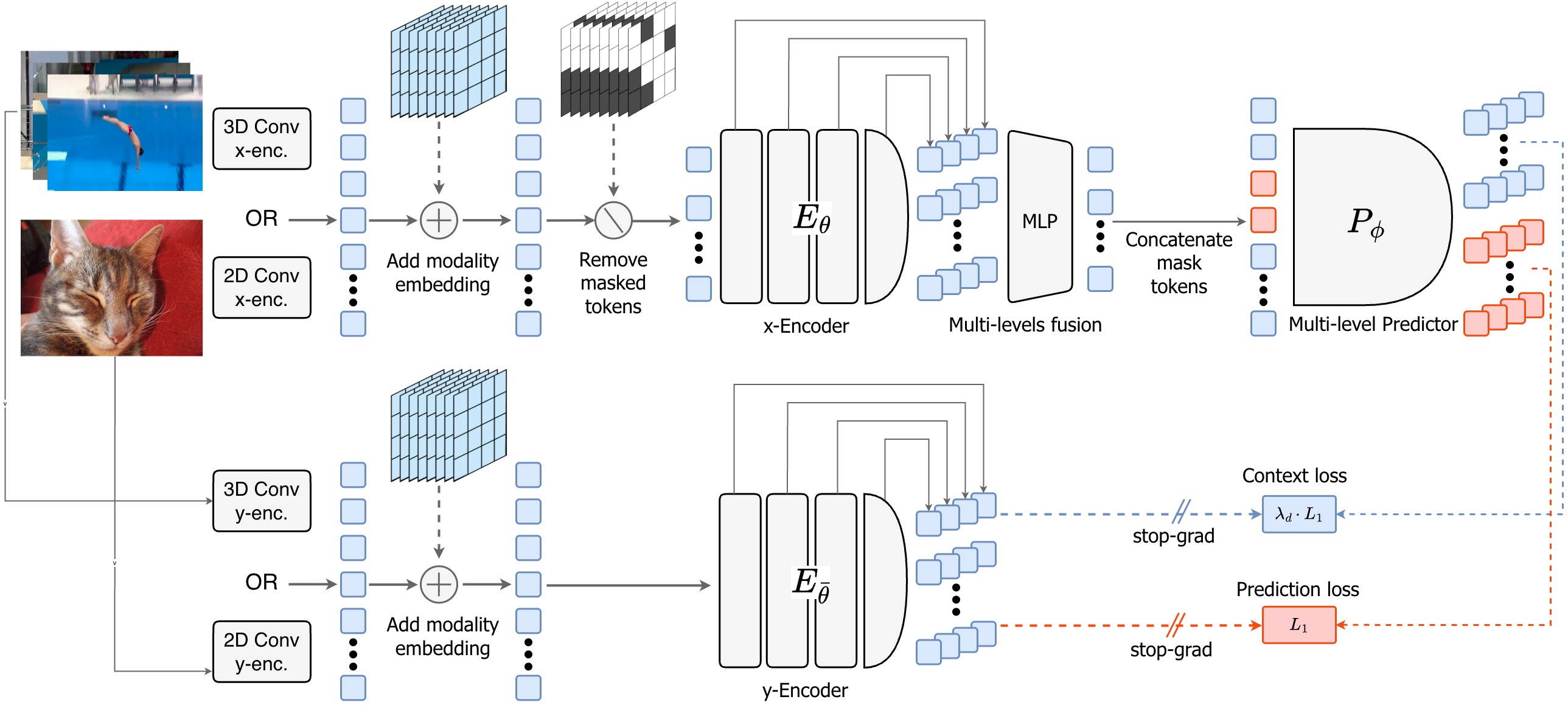
- Context loss (L_ctx): An auxiliary loss applied to unmasked (visible) tokens to encourage local spatial–temporal structure. "we propose to self-supervise both the mask and context patches and introduce a context loss $\mathcal{L}_{\text{ctx}$"
- Context tokens: Tokens corresponding to visible (unmasked) patches used as conditioning context in prediction. "The predictor outputs one token for each input, i.e., for both context and masked tokens."
- Deep Self-Supervision: Applying self-supervised objectives at multiple intermediate encoder layers to improve representations. "Deep Self-Supervision, which applies the self-supervised objective hierarchically at multiple intermediate encoder layers"
- Dense Predictive Loss: A masking-based objective where both visible and masked tokens contribute to the loss to enforce spatial–temporal grounding. "a Dense Predictive Loss, a masking-based objective in which all tokens—visible context and masked tokens alike—contribute to the training loss"
- Distance-weighted L1 loss: A variant of L1 loss that weights context-token supervision by proximity to masked regions. "a distance-weighted L1 loss on nearby context tokens"
- Distillation: Transferring knowledge from a large (teacher) model to a smaller (student) model to compress capability. "enable effective compression of the model through distillation"
- Ego-centric: A first-person viewpoint in video data capturing actions from the subject’s perspective. "predicting future object interaction in a ego-centric scenario"
- Exponential Moving Average (EMA): A parameter update technique that averages model weights over time to stabilize training. "an exponential moving average of is used to update the weight of the encoder"
- Frozen-backbone evaluation: Assessing pretrained features by training only lightweight heads while keeping the main encoder fixed. "Tasks where V-JEPA 2.1 ViT-G obtains SOTA in frozen-backbone evaluation are \underline{underlined}."
- Frozen encoder: Using a pretrained encoder without updating its weights during downstream training. "we employ V-JEPA 2.1 as a frozen encoder"
- Frame-guided temporal pooling: A module that aggregates temporal features into a frame-aligned spatial map for detection or recognition. "the frame-guided temporal pooling module from \cite{mur2024aff}"
- Intersection over Union (IoU): A metric for bounding-box overlap used to match predictions to ground truth. "using IoU > 0.5"
- Joint-Embedding Predictive Architecture (JEPA): A framework that predicts clean representations from corrupted ones in latent space. "Joint-Embedding Predictive Architecture (JEPA)~\citep{lecun2022path} is a self-supervised learning framework"
- L1 loss: The mean absolute error loss used here to supervise predictions in representation space. "an L1 loss on masked-token predictions"
- Latent mask-denoising objective: Predicting masked content directly in representation space rather than pixel space. "self-supervised learning with a latent mask-denoising objective"
- Linear probing: Evaluating representation quality by training a single linear layer on frozen features. "using a linear probing protocol"
- Mean Average Precision (mAP): The mean of Average Precision across classes, often used for detection/anticipation. "Top-5 mean Average Precision (mAP) metrics"
- Mean Intersection over Union (mIoU): The average IoU across classes, commonly used for semantic segmentation. "85.0 mIoU on Pascal VOC"
- Monocular depth estimation: Predicting scene depth from a single RGB image. "linear-probe monocular depth estimation (0.307 RMSE on NYUv2)"
- Multi-Modal Tokenizer: Modality-specific patch embeddings (2D for images, 3D for videos) to process each input natively. "Multi-Modal Tokenizers that support unified training over images and videos"
- Multi-level predictor: A predictor that outputs at several encoder depths to apply supervision across layers. "Deep Self-Supervision of the encoder intermediate layers via a multi-level predictor"
- PCA (Principal Component Analysis): A dimensionality-reduction technique used to visualize feature structure. "We compute PCA on patch features"
- Predictor network: The module that maps corrupted-input representations to clean-target representations. "A predictor network is then trained to predict the representation of the clean input"
- Recall@5: The fraction of examples where the correct label is among the top 5 predictions, averaged appropriately. "40.8 Recall@5 on EPIC-KITCHENS"
- Register tokens: Special tokens used to encourage global aggregation in transformer models. "similarly to register tokens~\citep{darcet2023vision}."
- RMSE (Root Mean Square Error): A regression error metric; lower values indicate better accuracy. "0.307 RMSE on NYUv2"
- Rotary Positional Encoding (RoPE): A positional encoding method enabling flexible relative position handling in attention. "3D Rotational Positional Encoding (RoPE)"
- Self-Supervised Learning (SSL): Learning representations from unlabeled data using auxiliary objectives. "Self-Supervised Learning (SSL) from video has recently emerged"
- Short-Term object-interaction Anticipation (STA): Forecasting imminent object interactions, including location, noun, verb, and time-to-contact. "Short-Term object-interaction Anticipation (STA)"
- SOTA (state of the art): The best reported performance to date on a given task/benchmark. "state-of-art performances"
- Stop-gradient operator: An operation that blocks gradient flow to prevent collapse or trivial solutions. "The loss use a stop-gradient operator, "
- Something-Something-v2 (SSv2): A video dataset focused on fine-grained object–action interactions used for action recognition. "77.7\% on Something-Something-v2"
- Vision Transformer (ViT): A transformer architecture operating on image/video patches as tokens. "Both encoder and predictor are parametrized with Vision Transformer"
- VisionMix-163M: A large curated mixture of image–video data for pretraining. "VisionMix 163M dataset"
- Warmup-constant learning rate schedule: A training schedule with a gradual increase (warmup) followed by a constant learning rate. "We follow the warmup-constant learning rate schedule"
- World models: Models that capture environment dynamics and structure for perception, prediction, and planning. "World models hold the promise of enabling agents to perceive, predict, and plan effectively in the physical world"
- YT-1B: A large-scale YouTube video dataset used as a diverse pretraining source. "increase the contribution of YT-1B"
- YouTube-VOS: A benchmark for video object segmentation evaluating temporal consistency and segmentation quality. "YouTube-VOS"
Collections
Sign up for free to add this paper to one or more collections.