Understanding the Emergence of Seemingly Useless Features in Next-Token Predictors
Abstract: Trained Transformers have been shown to compute abstract features that appear redundant for predicting the immediate next token. We identify which components of the gradient signal from the next-token prediction objective give rise to this phenomenon, and we propose a method to estimate the influence of those components on the emergence of specific features. After validating our approach on toy tasks, we use it to interpret the origins of the world model in OthelloGPT and syntactic features in a small LLM. Finally, we apply our framework to a pretrained LLM, showing that features with extremely high or low influence on future tokens tend to be related to formal reasoning domains such as code. Overall, our work takes a step toward understanding hidden features of Transformers through the lens of their development during training.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper asks a simple but surprising question: If a LLM is trained only to guess the next word, why does it often learn extra facts and patterns that don’t help with the very next word? The authors show where, during training, the “push” to learn those extra features comes from. They break down the training signal into three parts and demonstrate how these parts can make “seemingly useless” features appear and stick around inside Transformer models.
Key questions
The paper focuses on three easy-to-understand questions:
- Why do next-token predictors learn features that don’t help with the immediate next word (or token)?
- What parts of the training process create these features?
- Can we measure how much each part of training contributed to each feature?
How they studied it (methods and analogies)
First, some plain-language ideas:
- A Transformer model reads a sequence and tries to predict the next token after each position.
- Inside the model, “features” are like small notes it writes to itself about what it has seen (for example, “this sentence has a verb here” or “we’re in the middle of a list”). These notes live in the model’s hidden layers and can be read out with simple tests.
- A “gradient” is the training signal that tells the model how to change to get better. You can think of it like a coach giving feedback after each guess.
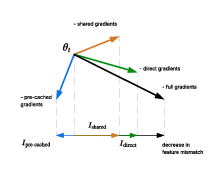
The authors show that gradients reach a feature through three pathways:
- Direct learning: The feature helps predict the very next token. Think: “I need this note right now.”
- Pre-caching: The feature is stored early so future positions can use it. Think: “I’ll leave breadcrumbs now because I know I’ll need them in a few steps.”
- Circuit sharing: The model uses the same building blocks at every position, so features learned at one position show up at others. Think: “Everyone in the class uses the same toolkit; if one student learns a trick, the same tool can repeat that trick anywhere.”
To study these, they did two kinds of experiments:
- Turning parts off during training:
- Myopic training blocks pre-caching by stopping cross-token training signals, so positions can’t learn to help future positions.
- m-untied training splits the model’s parameters into “before” and “after” a certain position, which weakens circuit sharing.
- Measuring who did the work:
- They train a model, identify a feature, and then replay training to estimate how much direct, pre-cached, and shared gradients contributed to that feature. They do this by checking how a small step in each gradient direction would shrink the gap between an earlier and the final model’s version of that feature. Think of it like asking, “Which coach’s advice moved this skill forward the most?”
For large models where retraining is too expensive, they use a different trick:
- Knock out a single feature during a forward pass and measure how much the model’s prediction changes for the immediate next token vs. later tokens. The ratio of “later-token change” to “next-token change” (they call it Q(w)) tells you if a feature is more “pre-cached” (affects future tokens) or more “direct” (affects the next token immediately).
Main findings
Here are the main discoveries, with short explanations and why they matter.
- Three training pathways explain “useless” features
- Even if a feature isn’t needed for the next token, it can be learned because:
- It helps future tokens (pre-caching).
- It’s learned at other positions and shows up everywhere (circuit sharing).
- This explains why next-token training can still produce rich, abstract knowledge.
- Toy tasks: without pre-caching and circuit sharing, “useless” features don’t appear
- In simple synthetic tasks (like finding the most common token so far), features that don’t help the immediate next token only emerge if pre-caching or circuit sharing is allowed.
- Some multi-step attention patterns (like induction heads) need pre-caching to form at all. Blocking pre-caching stops those patterns from developing.
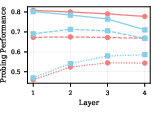
- OthelloGPT: why its “world model” is fragile
- In Othello, some board squares matter for the next legal move (NTP-useful); others don’t (NTP-useless). Probes read the model’s “board state” features.
- Results:
- NTP-useful square features are learned more strongly by direct learning.
- NTP-useless squares still get learned, but mainly via pre-caching and circuit sharing, so they’re weaker.
- This helps explain why the model’s internal “board understanding” can be brittle: it focuses more on what impacts the next move and less on the rest.
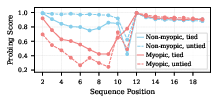
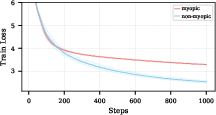
- Small LLMs on stories: pre-caching is needed for coherent text, but basic grammar is mostly direct
- Blocking pre-caching (myopic training) makes the model much worse at generating sensible stories.
- Yet many syntactic features (like part-of-speech tags and dependency labels) are learned mostly via direct learning, not pre-caching.
- A higher-level “positional” feature (where you are in the story) leans more on pre-caching, especially later in training. That suggests pre-caching helps with bigger-picture structure, not just local grammar.
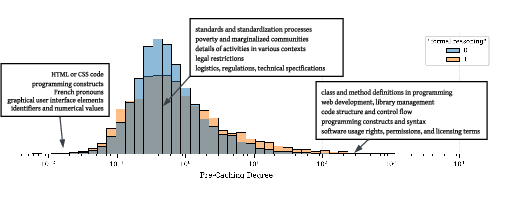
- Large model (Gemma 2): code-related features often look highly pre-cached (or the opposite—extremely not)
- Using a feature dictionary (Sparse Autoencoders), they measure Q(w), the ratio that indicates how “future-affecting” a feature is.
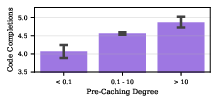
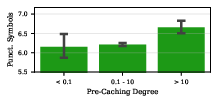
- Features tied to formal reasoning (like code) show up more often at the extreme tails of Q(w). This suggests that formal tasks rely on features that either strongly affect future tokens or strongly affect immediate ones in a distinctive way.
- When they steer the model by activating high-Q(w) features, the generations include more code-like content and punctuation, reinforcing the link between high Q(w) and formal structure.
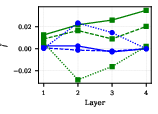
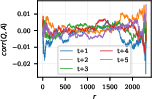
- Look-ahead is not the same as pre-caching
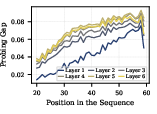
- “Look-ahead” means you can decode some future tokens from the model’s current hidden state.
- The authors find that high-Q(w) (pre-cached) features are not the main drivers of look-ahead. In fact, the correlation is negative.
- This supports the “breadcrumbs” idea: look-ahead often comes from shared features across positions (similar patterns being useful again), not from the model explicitly planning ahead.
Why this is important
This work shifts the view from “what the trained model does” to “how it learned to do it.” It shows that:
- Even if you train only for next-token prediction, the training process naturally builds extra internal notes that help later tokens or spread across positions.
- Understanding which pathway created a feature helps explain odd model behaviors, like OthelloGPT’s fragile “world model.”
- Pre-caching seems especially relevant for building multi-step reasoning and long-range structure, which may explain why blocking it harms coherent text generation.
- In large models, features tied to code and formal structure often have strong “future impact” signatures, which could guide better tools for interpretability, safety, and controllable generation.
Overall, the paper provides a practical framework for tracing where features come from during training, helps explain puzzling behaviors, and points to how we might better shape models in the future—either by allowing the right kinds of “breadcrumbs” to form, or by carefully limiting them when needed.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to guide concrete follow-up work:
- Formalize “NTP-useless” features
- Provide a precise, testable definition (beyond the informal notion) and practical procedures to label features as NTP-useful/useless across tasks; quantify labeling error and ambiguity in natural language.
- Prove and generalize the gradient decomposition
- Give a rigorous proof of the direct/pre-cached/shared gradient decomposition under standard training setups with regularization (weight decay, dropout), label smoothing, gradient clipping, etc.
- Extend the decomposition to other architectures (e.g., MoE, state-space models, RWKV, rotary vs ALiBi positional bias), multi-query attention, and non-causal or bidirectional settings.
- Finer-grained “shared” component
- Split the “shared” term by source positions (past vs future, near vs far) and by module (attention vs MLP vs embeddings) to disentangle cross-position transfer mechanisms.
- Measure how much feature transfer occurs from positions where a feature is NTP-useful to positions where it is NTP-useless, and which heads/MLPs carry it.
- Validity and stability of influence attribution
- Quantify sensitivity of the influence estimates to optimizer hyperparameters, schedules (e.g., warmup, decay), batch size, seed, and nondeterminism; report variance and confidence intervals systematically.
- Assess the error of the first-order (Taylor) approximation and path dependence; test second-order corrections or Hessian-free variants.
- Compare influence-based attributions to controlled ablation studies to validate causal interpretations.
- Scalability to large models without retraining
- Develop practical approximations to integrated influence that do not require replaying training (e.g., using training logs, influence functions, Fisher/K-FAC preconditioners, low-rank curvature, checkpoint interpolation).
- Evaluate how close such approximations track true integrated influence on small models where ground truth is computable.
- Myopic and m-untied training artifacts
- Characterize unintended side effects of gradient blocking and parameter untying on optimization stability, representation quality, and generalization (beyond the intended ablation).
- Explore alternative, less invasive ablations (e.g., loss shaping, attention masking schedules) that isolate pre-caching/circuit sharing while preserving training realism.
- Expressivity claims of pre-caching
- Provide a formal characterization of tasks/circuits (e.g., induction heads, algorithmic compositions) that are provably unreachable under myopic training and reachable otherwise; derive necessary/sufficient conditions by layer depth.
- Generalization beyond toy tasks and TinyStories
- Replicate findings on larger, more diverse corpora (e.g., multilingual, long-form, code, math), longer context windows, and larger models; test whether syntactic features remain predominantly direct in realistic settings.
- Linearity assumption and probe confounds
- Test whether conclusions hold with nonlinear probes, causal mediation analysis, or representational similarity methods; control for probe capacity and selectivity to avoid overestimation of linear recoverability.
- Othello world model: from diagnosis to mitigation
- Design and test training objectives (e.g., multi-token prediction, auxiliary state-prediction heads) that explicitly promote NTP-useless state features; measure whether this reduces fragility on equivalence classes with identical legal moves.
- Extend analysis to other deterministic environments (e.g., chess, Go, formal languages) to test generality.
- Position-wise causality and teacher forcing
- Disentangle effects of pre-caching from teacher-forcing dynamics (e.g., future ground-truth availability); analyze if and how gradients from future positions causally drive earlier features in different data regimes.
- Head- and layer-level mapping of influences
- Attribute direct/pre-cached/shared influence to specific attention heads and MLPs over training; identify concrete circuits responsible for feature emergence and transfer.
- The Q(w) proxy: theory and calibration
- Rigorously validate the intervention-based Q(w) against ground-truth integrated influences on small models; study dependence on intervention magnitude, feature scaling, and nonlinearity; quantify bias from feature superposition and SAE reconstruction error.
- Feature semantics and tail analysis in SAE
- Replace heuristic “formal” labels with audited annotations (human review + automated detectors); correct for multiple comparisons; quantify false discovery rates for tail-enriched categories.
- Steering evaluation rigor
- Evaluate steering effects with stronger metrics (e.g., code detectors, AST validity, syntax complexity, human evaluation), across multiple layers and coefficients; include negative controls to rule out generic “style” shifts.
- Look-ahead vs pre-caching
- Expand look-ahead tests to larger k, different layers, and nonlinear future predictors; run causal ablations of high- and low-Q(w) features during probing to directly test their necessity for look-ahead.
- Tokenization and dataset artifacts
- Assess how tokenizer granularity and domain-specific token distributions (e.g., code vs prose) affect pre-caching prevalence, Q(w), and the emergence of formal features.
- Training dynamics timelines
- Systematically track when features transition from pre-cached to direct (or vice versa) across many feature types, layers, and datasets; relate to known capability-emergence phases.
- Optimization and regularization effects
- Study how weight decay, dropout, gradient clipping, and label smoothing redistribute influence among components; test whether certain regularizers suppress or amplify pre-caching/circuit sharing.
- Alternative objectives and fine-tuning
- Examine how multi-token prediction, sequence-level objectives, masked LM, RLHF, or supervised fine-tuning alter the gradient decomposition and the emergence of NTP-useless features.
- Inference-time implications
- Test whether selectively amplifying/suppressing pre-cached subspaces improves long-range coherence or planning in generation; evaluate automatic and human metrics across tasks.
- Robustness and statistical power
- Report systematic seed variability, sample sizes, and power analyses for influence and probing metrics; ensure conclusions are not driven by small-sample or seed effects.
- Context-length scaling
- Quantify how the magnitude and distribution of direct vs pre-cached vs shared components scale with longer contexts; identify thresholds where pre-caching becomes dominant.
- Asymmetry in cross-position transfer
- Measure whether feature transfer via circuit sharing is symmetric across positions or biased by positional encodings/content; analyze how this interacts with attention patterns.
- Measuring “usefulness” in language rigorously
- Develop task-agnostic measures (e.g., conditional mutual information with the next token) to quantify a feature’s NTP usefulness in natural language and validate against probe-based proxies.
- Component interactions and non-additivity
- Test whether component influences combine additively or exhibit synergy/interference (e.g., via Shapley-style decompositions); identify cases where one component’s presence unlocks the utility of another.
Practical Applications
Immediate Applications
Below are concrete ways you can apply the paper’s findings and methods today, with suggested sectors, tools/workflows, and key dependencies.
- Training-time diagnostics for feature emergence
- Sectors: software (ML/AI), academia
- What: Integrate the paper’s gradient decomposition (direct, pre-cached, shared/circuit-sharing) into your training loop to monitor which components are driving specific features and capabilities.
- How: Implement per-batch stop-gradient routing for attention-mediated flows to compute the three gradient components; maintain separate Adam moments per component to compute integrated influences over training.
- Tools/workflows: PyTorch/TF training hooks; logging dashboards showing integrated influences per feature/layer/position.
- Assumptions/dependencies: Requires access to training code, gradients, and compute to store/aggregate per-component moments; assumes a causal Transformer with standard attention.
- Myopic training as an ablation for controlled experiments
- Sectors: academia, software
- What: Temporarily enable “myopic training” (blocking cross-position gradients through K/V except at current position) to test whether a task truly needs pre-caching.
- How: Add stop-gradient after K/V computations for non-current positions during backprop.
- Tools/workflows: A/B runs on the same seed with/without myopic mode to assess loss impact and feature reliance.
- Assumptions/dependencies: Performance may drop on tasks requiring long-range dependencies; best used for diagnosis or specialized training, not general-purpose LMs.
- Position untying (m-untied training) for circuit-sharing audits
- Sectors: academia
- What: Split parameters for positions ≤m and >m to isolate cross-position feature transfer via shared weights.
- How: Maintain two parameter sets for the same architecture; allow attention across partitions but stop gradient sharing as per design.
- Tools/workflows: Controlled runs to identify features that exist due to circuit sharing rather than direct utility.
- Assumptions/dependencies: Non-standard training setup; compute overhead; suited to small/medium models and research experiments.
- World-model fragility audits using NTP-useful vs NTP-useless partitions
- Sectors: academia, safety/governance, software (evaluation)
- What: Probe and compare feature linearity for NTP-useful vs NTP-useless states (e.g., Othello or similar environments) to diagnose brittleness and source of gradients.
- How: Train linear probes per layer/position; compute integrated influence per component to explain gaps in representation.
- Tools/workflows: Probing pipelines; interpretability notebooks.
- Assumptions/dependencies: Requires labeled task states (which squares matter for next move, etc.); probes reflect linear features and may miss non-linear structure.
- Lightweight LLM interpretability via Q(w) without retraining
- Sectors: software, academia, safety
- What: Use the proposed Q(w) intervention ratio to classify features as pre-cached-like vs direct-like around a final checkpoint.
- How: With an SAE or other feature basis, ablate features at activation time, compute KL deltas across positions, and estimate Q(w).
- Tools/workflows: SAE libraries (e.g., Gemma-Scope); intervention tooling; evaluation scripts.
- Assumptions/dependencies: Quality of SAE feature directions matters; Q(w) estimates local (post-training) influence ratios, not full training-time dynamics.
- Generation-time steering of “formal reasoning mode”
- Sectors: software (developer tools, code assistants), education
- What: At inference, steer features with high Q(w) to increase code/formal-structure fluency; de-steer to reduce it.
- How: Add/subtract scaled feature directions at selected layers/positions during decoding.
- Tools/workflows: Inference-time feature steering modules; UI toggles for “formalize text” or “code-first” modes.
- Assumptions/dependencies: Requires a usable feature basis (SAE) for the deployment model; safety guardrails needed to prevent undesired style/content shifts.
- Curriculum and data design for small models
- Sectors: academia, education, software
- What: Design curricula to exploit the finding that simple syntax is largely direct (can be learned without pre-caching), while longer-range coherence needs pre-caching.
- How: Stage training: early phases emphasize local syntactic signals; later phases introduce longer contexts to promote pre-cached features.
- Tools/workflows: Data pipeline scheduling; per-phase myopic/non-myopic toggles.
- Assumptions/dependencies: Benefits strongest for small models and simpler domains (e.g., TinyStories-scale); general-purpose LMs still need pre-caching for coherence.
- KV-cache and context management informed by pre-cached features
- Sectors: software (serving/inference infra)
- What: Prioritize preserving tokens/layers where high-Q(w) features activate to maintain future-token utility; safely drop low-impact cache entries.
- How: Online feature activity scoring; cache retention policies biased toward high Q(w) activations.
- Tools/workflows: Serving middleware that monitors feature activations (if feasible); cache-trimming policies.
- Assumptions/dependencies: Requires access to internal activations and feature basis at inference; latency/overhead trade-offs.
- Safety and red-teaming for formal/structured outputs
- Sectors: safety/governance, software
- What: Use high-Q(w) features as indicators for modes that produce code or highly structured outputs; trigger extra checks or moderation.
- How: Monitor activations; when high-Q(w) features are active, adjust decoding constraints or invoke policy checks.
- Tools/workflows: Policy routing frameworks; activation-based risk detectors.
- Assumptions/dependencies: Correlation with code/formal structure holds best for tested models; false positives/negatives must be evaluated.
Long-Term Applications
These opportunities require further research, scaling studies, or engineering investment.
- Objective and optimizer design that shapes pre-cached vs direct learning
- Sectors: software (foundation models), academia
- What: Create training objectives (e.g., multi-token targets, auxiliary losses) or optimizer schedules that modulate the balance between pre-cached and direct features for domain fit.
- Potential outcomes: More reliable long-range coherence where needed; reduced overfitting to NTP-useful-only partitions in structured domains.
- Assumptions/dependencies: Extensive retraining and ablation studies; potential trade-offs with perplexity and generalization.
- Scalable influence attribution for LLMs without full retraining logs
- Sectors: software, academia
- What: Develop efficient approximations to training-time influence decomposition (e.g., curvature-aware replays, influence functions, synthetic re-training on sketches).
- Potential outcomes: Training dashboards for billion-scale models; routine interpretability audits at training time.
- Assumptions/dependencies: New algorithmic advances to reduce memory/compute overhead; robust approximations validated against small-model ground truth.
- Building robust world models by reinforcing NTP-useless-but-semantic features
- Sectors: academia, safety, robotics (planning), healthcare (clinical pathways), finance (stateful forecasting)
- What: Strengthen representations of semantically critical but NTP-useless features using auxiliary supervision, multi-step prediction, or contrastive objectives.
- Potential outcomes: Less brittle internal state tracking under distribution shifts; better performance on planning/stateful tasks.
- Assumptions/dependencies: Requires careful task design and labels for latent state or multi-step supervision; possible conflicts with pure NTP efficiency.
- Architecture-level channels for feature pathways
- Sectors: software (model architecture)
- What: Introduce explicit architectural pathways for pre-cached vs direct signals (e.g., separate attention streams, gating, or position-tied/untied submodules).
- Potential outcomes: Easier control over coherence vs immediacy; improved debuggability and safety controls.
- Assumptions/dependencies: Significant research and engineering to maintain performance while adding structure; careful regularization to avoid collapse.
- Standardized Q(w)-style interpretability benchmarks
- Sectors: academia, policy/governance
- What: Establish benchmark suites where models are evaluated on the distribution of Q(w) across features and its relation to task domains (e.g., code vs prose).
- Potential outcomes: Comparable “formal reasoning circuitry” profiles; procurement or compliance requirements around interpretability metrics.
- Assumptions/dependencies: Agreement on feature extraction standards (SAE quality); cross-model comparability.
- Task-aware cache and compute allocation driven by feature semantics
- Sectors: software (cloud inference), finance, healthcare
- What: Dynamically allocate compute and memory to inputs predicted to engage high pre-caching (e.g., formal documents, code, legal text) for improved quality.
- Potential outcomes: Cost-quality trade-off controls at inference-time; better latency for low-complexity inputs.
- Assumptions/dependencies: Reliable predictors of high-Q(w) activation given prompt metadata; infra support for dynamic scaling.
- Safer training via controlled circuit sharing
- Sectors: safety/governance
- What: Regulate circuit sharing to mitigate unintended cross-position transfer (e.g., reducing leakage of sensitive context patterns or over-generalization).
- Potential outcomes: Reduced memorization/transfer risks; clearer provenance of learned capabilities.
- Assumptions/dependencies: Clear causal links between circuit sharing and undesirable behaviors; viable training procedures (partial untying, gating) that preserve utility.
- Domain-specific “reasoning-mode” adapters
- Sectors: software (enterprise AI), education, robotics
- What: Train small adapters/LoRA modules that amplify pre-cached circuits when operating on formal domains (code, math, verification) and attenuate them in others.
- Potential outcomes: Reliable domain switching; improved performance without full model finetuning.
- Assumptions/dependencies: Stable mapping between adapters and high-Q(w) features; risk of mode collapse if overused.
- Data governance and reporting standards
- Sectors: policy/governance
- What: Require model developers to document pre-caching/circuit-sharing diagnostics, Q(w) distributions, and world-model partition performance (NTP-useful vs useless).
- Potential outcomes: Better transparency for critical deployments (e.g., healthcare decision support); comparability across vendors.
- Assumptions/dependencies: Industry consensus; practical and privacy-preserving ways to expose diagnostics.
- Cross-domain sequential modeling beyond text
- Sectors: finance (time series), energy (grid control), robotics (control policies)
- What: Apply decomposition and control of pre-cached/direct features to non-text sequential models (e.g., Transformers for control or forecasting) to balance immediate vs long-horizon signals.
- Potential outcomes: More stable controllers and forecasters; interpretable long-horizon planning behavior.
- Assumptions/dependencies: Careful adaptation to non-text modalities; verification that causal masking and attention pathways mirror language-model assumptions.
Glossary
- Adam: An adaptive gradient-based optimizer commonly used to train neural networks. "the optimizer commonly used to train models is Adam"
- AST (Abstract Syntax Tree): A tree-structured representation of source code’s syntactic structure. "e.g., AST for code parsing"
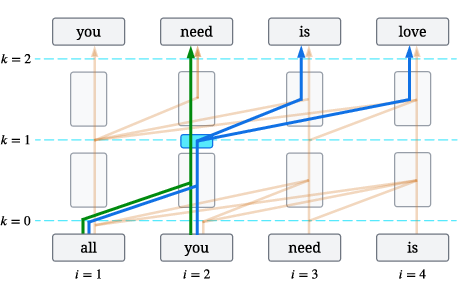
- causally masked Transformers: Transformers that mask future positions so each token attends only to earlier tokens. "Based on the structure of information flow in causally masked Transformers,"
- circuit sharing: A gradient pathway where shared parameters across positions cause features learned at one position to also appear at others. "We call this phenomenon circuit sharing"
- cross-entropy loss: A standard loss function measuring the difference between predicted and true token distributions. "for NTP using cross-entropy loss."
- direct learning: Gradient signal arising from predicting the immediate next token at the same position. "Firstly, a gradient signal can come from the immediate next-token prediction (direct learning)."
- feature direction: A vector in activation space that defines a linear feature to be read out from the residual stream. "where a vector defines the feature direction."
- feature mismatch: A scalar measuring how projections onto a feature differ between two model checkpoints. "We call a feature mismatch the value"
- induction head: An attention pattern that copies or continues sequences by linking occurrences across positions. "Even constructions as simple as an induction head require at least two layers of attention interacting with each other."
- inductive bias: The predispositions of a model and training setup that favor certain learned solutions. "the modelâs inductive bias toward next-token partitions of state"
- influence (gradient influence): The first-order effect of a parameter update direction on reducing a feature mismatch. "we call the influence of G the value"
- information-flow decomposition: The breakdown of training gradients into direct, pre-cached, and shared components. "An illustration of the information-flow decomposition"
- integrated influence: The cumulative contribution of a gradient component to a feature’s emergence across training. "obtaining the integrated influences for each feature"
- intervention: Modifying activations during a forward pass to test a feature’s causal effect on predictions. "The standard way of estimating the causal role of a feature in a Transformer is an intervention"
- K and V matrices: The Key and Value matrices computed by attention that enable cross-token information flow. "it is sufficient to stop gradients after computing the K and V matrices"
- KL-divergence: A measure of how one probability distribution diverges from another. "records the KL-divergence between the predictions"
- KV-cache: Stored keys and values from previous tokens used by attention for efficient inference/training. "attends to the KV-cache of the first one."
- linear probes: Trained linear models used to read specific features from hidden representations. "we train layer- and position-specific linear probes"
- look-ahead: The phenomenon where internal representations encode information useful for predicting future tokens beyond the next one. "the look-ahead in LLMs"
- m-untied training: A setup that uses separate parameter sets before and after position m to prevent cross-position parameter sharing. "we use a technique that we call -untied training."
- myopic training: Training that blocks gradients across positions, preventing features from being learned for future use via attention. "proposed myopic training -- a way to train an LLM that prevents pre-caching."
- next-token prediction (NTP): The objective of predicting the next token given all previous tokens. "LLMs are usually pretrained with the objective of next-token prediction (NTP)."
- OthelloGPT: A Transformer trained on Othello move sequences, used to study learned board-state representations. "reporting that the implicit world model of OthelloGPT is fragile"
- Pearson correlation: A measure of linear correlation used to evaluate probe predictions against ground truth. "evaluate the probes using Pearson correlation"
- pre-caching: Learning features at earlier positions so later tokens can attend to and use them during prediction. "The term pre-caching is borrowed from \cite{wu2024language}"
- residual stream: The main vector pathway in a Transformer that carries information across layers at each position. "are the values of the residual stream"
- Sparse Autoencoder (SAE): An autoencoder with sparse activations used to extract interpretable latent features from model activations. "we use a Sparse Autoencoder from the Gemma-Scope suite"
- Spearman correlation: A rank-based correlation metric used to relate feature geometry to utility. "We report the Spearman correlation between and "
- split brain experiments: A neuroscience paradigm used as an analogy for models with separated parameter sets across positions. "as in the split brain experiments in neuroscience"
- steering: Adding a feature direction to hidden states during generation to control model outputs. "we examine how steering features with different values of affects samples from the model."
- stop-gradient operator: A mechanism that blocks gradient flow through a node during backpropagation. "after a stop-gradient operator is applied"
- teleological perspective: An interpretation approach that explains features by their role in a model’s final algorithmic behavior. "teleological perspective: that is, features are viewed in the context of their role in the algorithms implemented by a trained model"
- unembedding layer: The final linear mapping from hidden states to vocabulary logits in a LLM. "embedding and unembedding layers"
- Wilcoxon test: A nonparametric statistical test used to compare paired or related samples. "one-sided Wilcoxon tests"
- world model: An internal representation of latent structure or state of the data-generating process. "the origins of the world model in OthelloGPT"
Collections
Sign up for free to add this paper to one or more collections.